Spark Connect in Apache Spark 3.4 verfügbar
Spark-Anwendungen überall ausführen
von Allan Folting, Hyukjin Kwon, Xiao Li, Herman van Hövell, Stefania Leone, Martin Grund, Reynold Xin und Kris Mo
Letztes Jahr wurde Spark Connect auf dem Data and AI Summit eingeführt. Als Teil des kürzlich veröffentlichten Apache SparkTM 3.4 ist Spark Connect jetzt allgemein verfügbar. Wir haben auch kürzlich Databricks Connect neu konzipiert, um auf Spark Connect zu basieren. Dieser Blogbeitrag erklärt, was Spark Connect ist, wie es funktioniert und wie man es verwendet.
Benutzer können jetzt IDEs, Notebooks und moderne Datenanwendungen direkt mit Spark-Clustern verbinden
Spark Connect führt eine entkoppelte Client-Server-Architektur ein, die eine Fernverbindung zu Spark-Clustern von jeder Anwendung aus ermöglicht, die überall läuft. Diese Trennung von Client und Server ermöglicht modernen Datenanwendungen, IDEs, Notebooks und Programmiersprachen den interaktiven Zugriff auf Spark.
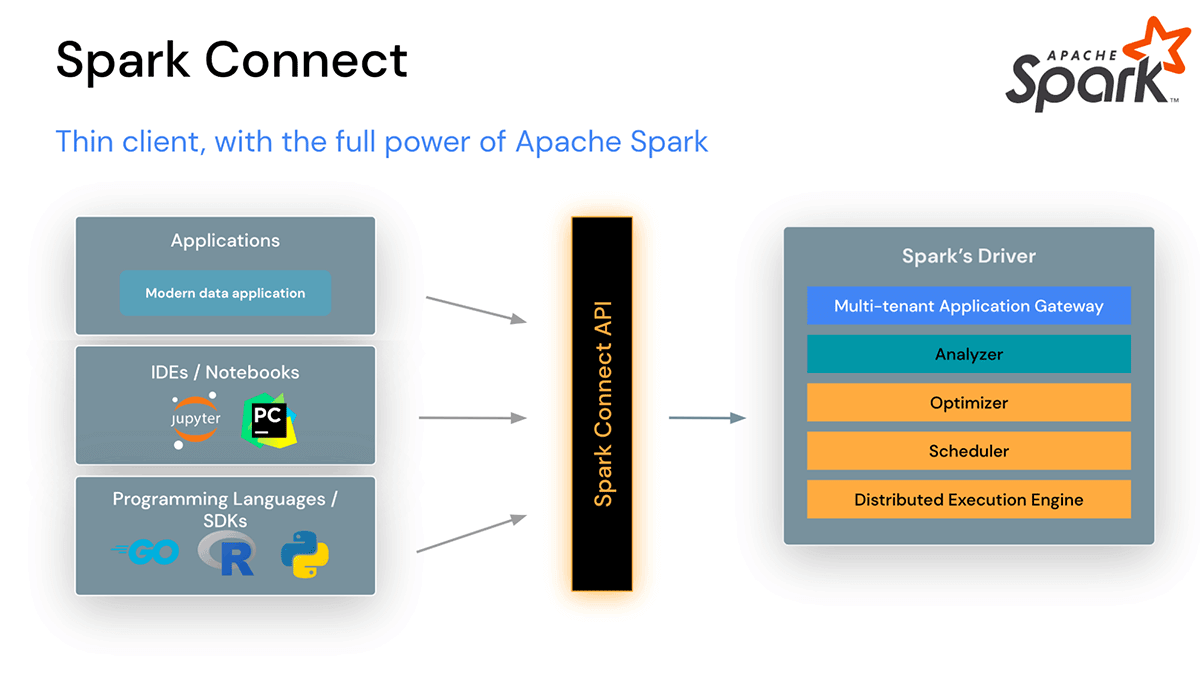
Spark Connect verbessert Stabilität, Upgrades, Debugging und Beobachtbarkeit
Mit dieser neuen Architektur mildert Spark Connect auch häufige Betriebsprobleme:
Stabilität: Anwendungen, die viel Speicher benötigen, beeinträchtigen nun nur noch ihre eigene Umgebung, da sie in ihren eigenen Prozessen außerhalb des Spark-Clusters laufen können. Benutzer können ihre eigenen Abhängigkeiten in der Client-Umgebung definieren und müssen sich keine Gedanken über mögliche Abhängigkeitskonflikte auf dem Spark-Treiber machen.
Wenn Sie beispielsweise eine Client-Anwendung haben, die einen großen Datensatz aus Spark für Analysen oder Transformationen abruft, läuft diese Anwendung nicht mehr auf dem Spark-Treiber. Das bedeutet, dass die Anwendung, wenn sie viel Speicher oder CPU-Zyklen verbraucht, nicht um Ressourcen mit anderen Anwendungen auf dem Spark-Treiber konkurriert, was möglicherweise dazu führt, dass diese anderen Anwendungen langsamer werden oder fehlschlagen, da sie jetzt in einer eigenen, separaten, dedizierten Umgebung läuft.
Aufrüstbarkeit: In der Vergangenheit war es äußerst mühsam, Spark aufzurüsten, da alle Anwendungen im selben Spark-Cluster gleichzeitig mit dem Cluster aufgerüstet werden mussten. Mit Spark Connect können Anwendungen dank der Trennung von Client und Server unabhängig vom Server aufgerüstet werden. Dies erleichtert das Aufrüsten erheblich, da Unternehmen keine Änderungen an ihren Client-Anwendungen vornehmen müssen, wenn sie Spark aufrüsten.
Debugbarkeit und Beobachtbarkeit: Spark Connect ermöglicht interaktives schrittweises Debugging während der Entwicklung direkt von Ihrer bevorzugten IDE aus. Ebenso können Anwendungen mit den nativen Metrik- und Protokollierungsbibliotheken des Anwendungs-Frameworks überwacht werden.
Sie können beispielsweise eine Spark Connect-Client-Anwendung in Visual Studio Code interaktiv durchlaufen, Objekte inspizieren und Debug-Befehle ausführen, um Probleme in Ihrem Code zu testen und zu beheben.
So funktioniert Spark Connect
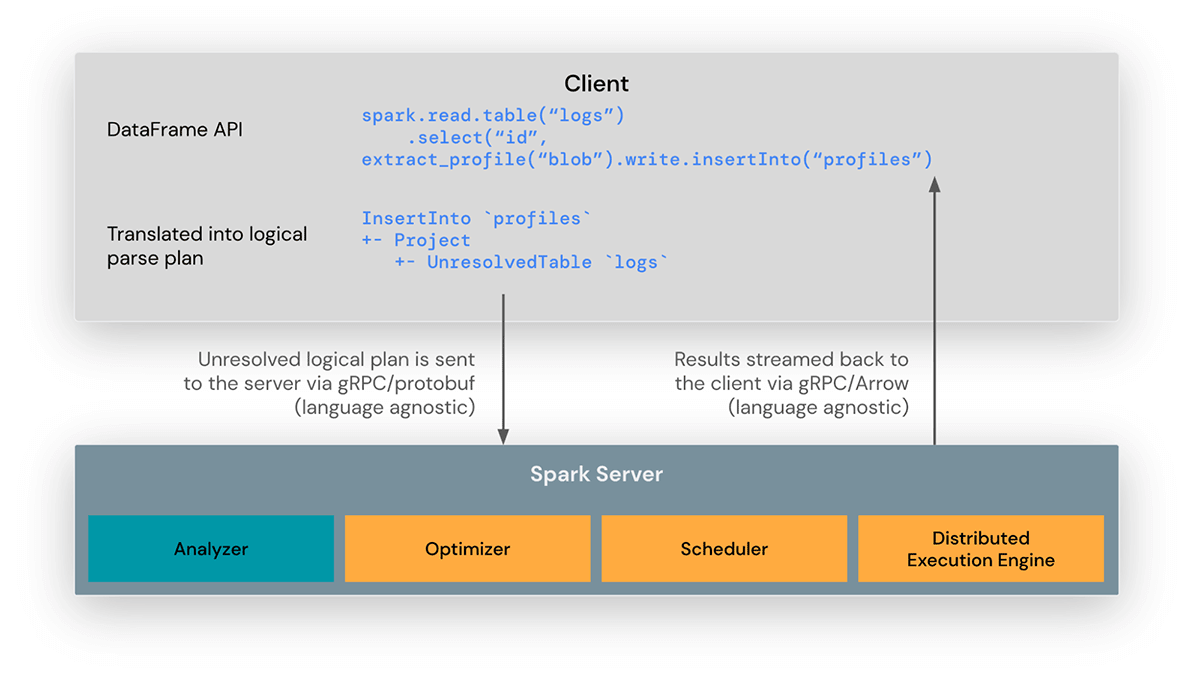
Die Spark Connect-Client-Bibliothek wurde entwickelt, um die Entwicklung von Spark-Anwendungen zu vereinfachen. Es ist eine dünne API, die überall eingebettet werden kann: in Anwendungsservern, IDEs, Notebooks und Programmiersprachen. Die Spark Connect-API baut auf der DataFrame-API von Spark auf und verwendet nicht aufgelöste logische Pläne als sprachunabhängiges Protokoll zwischen Client und Spark-Treiber.
Der Spark Connect-Client übersetzt DataFrame-Operationen in nicht aufgelöste logische Abfragepläne, die mit Protocol Buffers kodiert werden. Diese werden über das gRPC-Framework an den Server gesendet.
Der im Spark-Treiber eingebettete Spark Connect-Endpunkt empfängt und übersetzt nicht aufgelöste logische Pläne in die logischen Planoperatoren von Spark. Dies ähnelt dem Parsen einer SQL-Abfrage, bei der Attribute und Relationen geparst und ein anfänglicher Parse-Plan erstellt wird. Von dort aus greift der Standard-Spark-Ausführungsprozess, um sicherzustellen, dass Spark Connect alle Optimierungen und Verbesserungen von Spark nutzt. Ergebnisse werden über gRPC als Apache Arrow-kodierte Ergebnisstapel zurück an den Client gestreamt.
So verwenden Sie Spark Connect
Ab Spark 3.4 ist Spark Connect verfügbar und unterstützt PySpark- und Scala-Anwendungen. Wir werden ein Beispiel für die Verbindung zu einem Apache Spark-Server mit Spark Connect von einer Client-Anwendung aus mit der Spark Connect-Client-Bibliothek durchgehen.
Beim Schreiben von Spark-Anwendungen ist der einzige Zeitpunkt, an dem Sie Spark Connect berücksichtigen müssen, wenn Sie Spark-Sitzungen erstellen. Der Rest Ihres Codes ist genau derselbe wie zuvor.
Um Spark Connect zu verwenden, können Sie einfach eine Umgebungsvariable (SPARK_REMOTE) für Ihre Anwendung festlegen, ohne Codeänderungen vorzunehmen, oder Sie können Spark Connect explizit in Ihren Code aufnehmen, wenn Sie Spark-Sitzungen erstellen.
Werfen wir einen Blick auf ein Jupyter-Notebook-Beispiel. In diesem Notebook erstellen wir eine Spark Connect-Sitzung mit einem lokalen Spark-Cluster, erstellen einen PySpark DataFrame und zeigen die Top 10 Musik-Künstler nach Anzahl der Hörer.
In diesem Beispiel geben wir explizit an, dass wir Spark Connect verwenden möchten, indem wir die Remote-Eigenschaft festlegen, wenn wir unsere Spark-Sitzung erstellen (SparkSession.builder.remote...).
Jupyter-Notebook-Code mit Spark Connect
Sie können den im Beispiel verwendeten Datensatz hier herunterladen: Music artists popularity | Kaggle
Wie im folgenden Beispiel gezeigt, erleichtert Spark Connect auch den Wechsel zwischen verschiedenen Spark-Clustern, zum Beispiel bei der Entwicklung und beim Testen auf einem lokalen Spark-Cluster und später beim Verschieben Ihres Codes in die Produktion auf einem Remote-Cluster.
In diesem Beispiel legen wir die Umgebungsvariable TEST_ENV fest, um zu steuern, welchen Spark-Cluster und welchen Datenspeicherort unsere Anwendung verwendet, sodass wir keine Codeänderungen vornehmen müssen, um zwischen unseren Test-, Staging- und Produktionsclustern zu wechseln.
Wechsel zwischen verschiedenen Spark-Clustern mithilfe einer Umgebungsvariable
Um mehr darüber zu erfahren, wie Sie Spark Connect verwenden, besuchen Sie die Seiten Spark Connect Overview und Spark Connect Quickstart.
Databricks Connect basiert auf Spark Connect
Seit Databricks Runtime 13.0 basiert Databricks Connect auf dem Open-Source-Spark Connect. Mit dieser „v2“-Architektur wird Databricks Connect zu einem dünnen Client, der einfach zu bedienen ist. Er kann überall eingebettet werden, um eine Verbindung zu Databricks herzustellen: in IDEs, Notebooks und jeder Anwendung, sodass Kunden und Partner neue (interaktive) Benutzererlebnisse auf Basis Ihres Databricks Lakehouse aufbauen können. Es ist sehr einfach zu bedienen: Benutzer binden einfach die Databricks Connect-Bibliothek in ihre Anwendungen ein und verbinden sich mit ihrem Databricks Lakehouse.
APIs, die in Apache Spark 3.4 unterstützt werden
PySpark: In Spark 3.4 unterstützt Spark Connect die meisten PySpark-APIs, einschließlich DataFrame, Functions und Column. Unterstützte PySpark-APIs sind in der API-Referenz als „Supports Spark Connect“ gekennzeichnet, sodass Sie prüfen können, ob die von Ihnen verwendeten APIs verfügbar sind, bevor Sie vorhandenen Code zu Spark Connect migrieren.
Scala: In Spark 3.4 unterstützt Spark Connect die meisten Scala-APIs, einschließlich Dataset, functions und Column.
Die Unterstützung für Streaming wird bald verfügbar sein, und wir freuen uns darauf, mit der Community an der Bereitstellung weiterer APIs für Spark Connect in zukünftigen Spark-Releases zusammenzuarbeiten.
Spark Connect in Apache Spark 3.4 eröffnet den Zugriff auf Spark von jeder Anwendung aus, die auf DataFrames/DataSets in PySpark und Scala basiert, und legt den Grundstein für die Unterstützung anderer Programmiersprachen in der Zukunft.
Mit vereinfachter Entwicklung von Client-Anwendungen, verringerter Speicherüberlastung auf dem Spark-Treiber, separatem Abhängigkeitsmanagement für Client-Anwendungen, unabhängigen Client- und Server-Upgrades, schrittweisem IDE-Debugging und Thin-Client-Logging und -Metriken macht Spark Connect den Zugriff auf Spark allgegenwärtig.
Weitere Informationen zu Spark Connect und erste Schritte finden Sie auf den Seiten Spark Connect Overview und Spark Connect Quickstart.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.