Agentic AI-Sicherheit: Neue Risiken und Kontrollen im Databricks AI Security Framework (DASF v3.0)
35 neue Risiken für Agentic AI und 6 Kontrollmaßnahmen für Agenten, die auf Daten zugreifen, Tools aufrufen und Aktionen ausführen
von David Veuve, Omar Khawaja, Arun Pamulapati, Nishith Sinha und Caelin Kaplan
- Das Databricks AI Security Framework (DASF) deckt jetzt Agentic AI als 13. Systemkomponente ab und fügt 35 neue technische Sicherheitsrisiken und 6 neue Kontrollmaßnahmen hinzu, damit Unternehmen autonome Agenten vertrauensvoll einsetzen können.
- Diese Erweiterung befasst sich mit den einzigartigen Risiken von Agentenspeicher, -planung und -werkzeugnutzung, einschließlich Bedrohungen, die durch das Model Context Protocol (MCP) eingeführt werden, dem aufkommenden Standard für die Verbindung von Agenten mit Unternehmenswerkzeugen.
- Das Whitepaper zur DASF Agentic AI Extension und das aktualisierte Kompendium sind jetzt verfügbar. Laden Sie sie herunter, um Ihre Agentenarchitekturen zu bewerten, Ihre Werkzeugökosysteme abzubilden und speziell für Autonomie entwickelte Defense-in-Depth-Kontrollen zu implementieren.
Wir freuen uns, die Veröffentlichung des Whitepapers zum Databricks AI Security Framework (DASF) Agentic AI Extension bekannt zu geben! Databricks-Kunden setzen bereits KI-Agenten ein, die Datenbanken abfragen, externe APIs aufrufen, Code ausführen und mit anderen Agenten koordinieren. Wir hören ständig von den Teams, die für diese Einsätze verantwortlich sind, dass sie sich wichtige Fragen stellen: Was passiert, wenn die KI Dinge tun kann, nicht nur sagen? Deshalb haben wir DASF erweitert.
Mit diesem Update führen wir neue Anleitungen für die Sicherung autonomer KI-Agenten ein:
- 35 neue Risiken für agentische KI, die das Schlussfolgern, den Speicher und die Tool-Nutzung von Agenten abdecken
- 6 neue Minderungsmaßnahmen, einschließlich des Prinzips der geringsten Rechte, Sandboxing und menschlicher Aufsicht
- Sicherheitsrichtlinien für Model Context Protocol (MCP) Tool-Server und -Clients
- Abdeckung von Risiken in Multi-Agenten-Systemen und Bedrohungen der Agentenkommunikation
Zusammen helfen diese Ergänzungen Unternehmen, KI-Agenten sicher einzusetzen und dabei Governance-, Beobachtbarkeits- und Defense-in-Depth-Sicherheitskontrollen beizubehalten.
Damit umfasst das vollständige Framework 97 Risiken und 73 Kontrollen. Wir haben das DASF-Compendium (Google Sheet, Excel) aktualisiert, um diese neuen Risiken und Kontrollen aufzunehmen und sie an Industriestandards anzupassen, um eine sofortige Operationalisierung zu ermöglichen. Diese Ergänzungen sind als DASF v3.0 in der Spalte „DASF Revision“ katalogisiert.
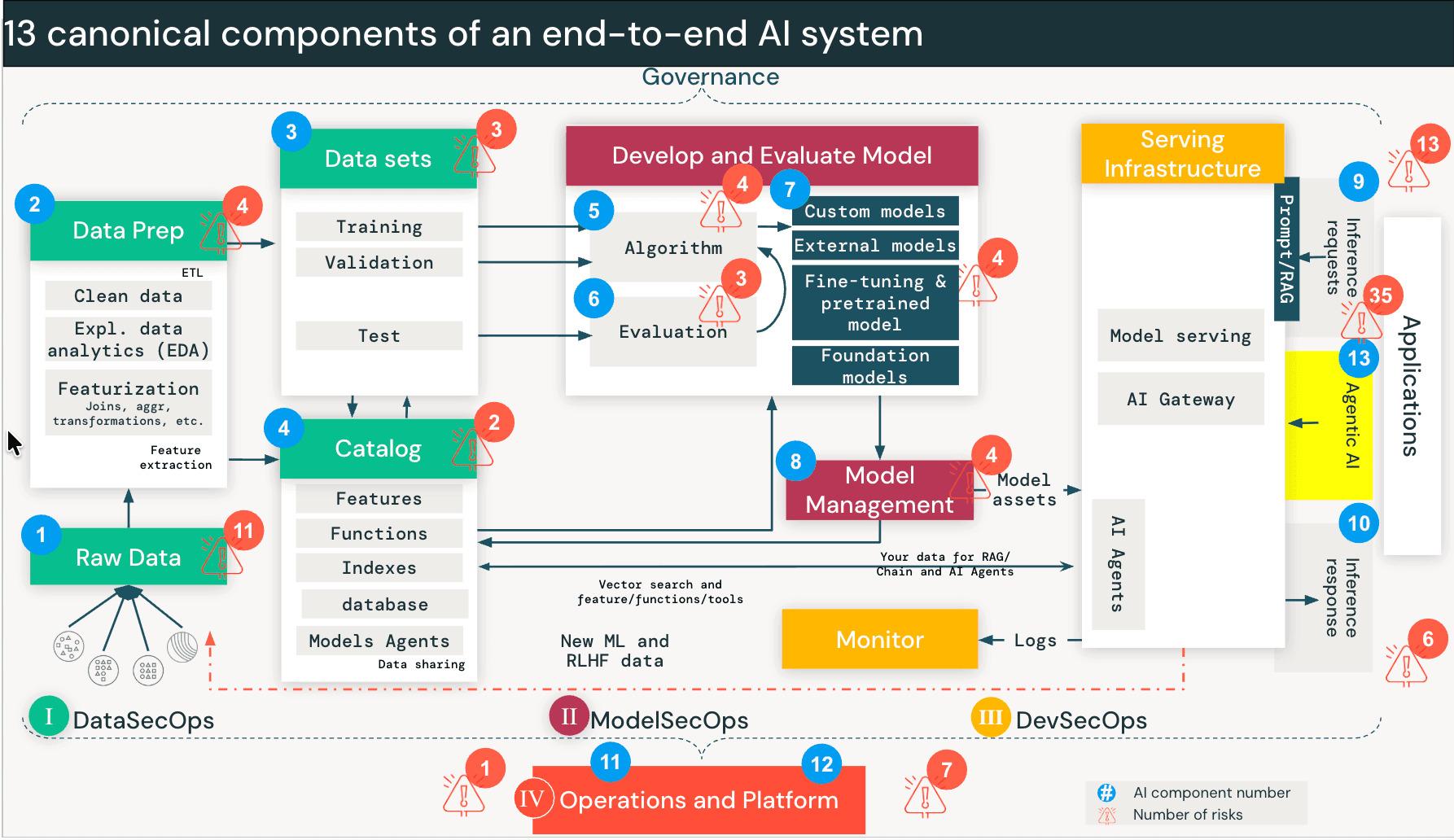
{kind=link}
Sicherheitsrisiken, wenn KI-Agenten Aktionen ausführen können
Traditionelle KI-Systeme wie RAG arbeiten hauptsächlich im schreibgeschützten Modus. KI-Agenten können jedoch Aktionen ausführen, wie z. B. Datenbanken abfragen, APIs aufrufen, Code ausführen und mit externen Tools interagieren.
Agenten arbeiten anders. Wenn ein Benutzer mit einem Agenten interagiert, startet das Modell eine Schleife: Es zerlegt die Anfrage in Teilaufgaben, wählt ein Tool aus (z. B. „Sales-Datenbank abfragen“), führt es aus, wertet die Ausgabe aus und entscheidet, welches Tool als Nächstes aufgerufen werden soll. Dies wird fortgesetzt, bis die Aufgabe erledigt ist. Der Agent trifft Echtzeitentscheidungen darüber, auf welche Daten zugegriffen und welche Tools aufgerufen werden sollen – Entscheidungen, die früher von Menschen getroffen oder in die Anwendungslogik einprogrammiert wurden.
Das schafft eine neue Risikoklasse, die wir Discovery and Traversal nennen. Ein Agent, der darauf ausgelegt ist, Lösungen zu finden, durchläuft Datenpfade und Tool-Schnittstellen, die nie für den anfragenden Benutzer bestimmt waren. Er nutzt keinen Fehler aus. Er tut genau das, wofür er gebaut wurde. Aber ohne entsprechende Kontrollen erbt der Benutzer effektiv die Berechtigungen des Agenten und nicht seine eigenen.
Das tödliche Trifecta. Jüngste Branchenforschung, einschließlich Metas „Agents Rule of Two“ und ähnlicher Modelle wie Simon Willisons „Lethal Trifecta“, hebt die Bedingungen hervor, unter denen dies gefährlich wird. Das Risikoprofil steigt, wenn drei Bedingungen gleichzeitig vorliegen:
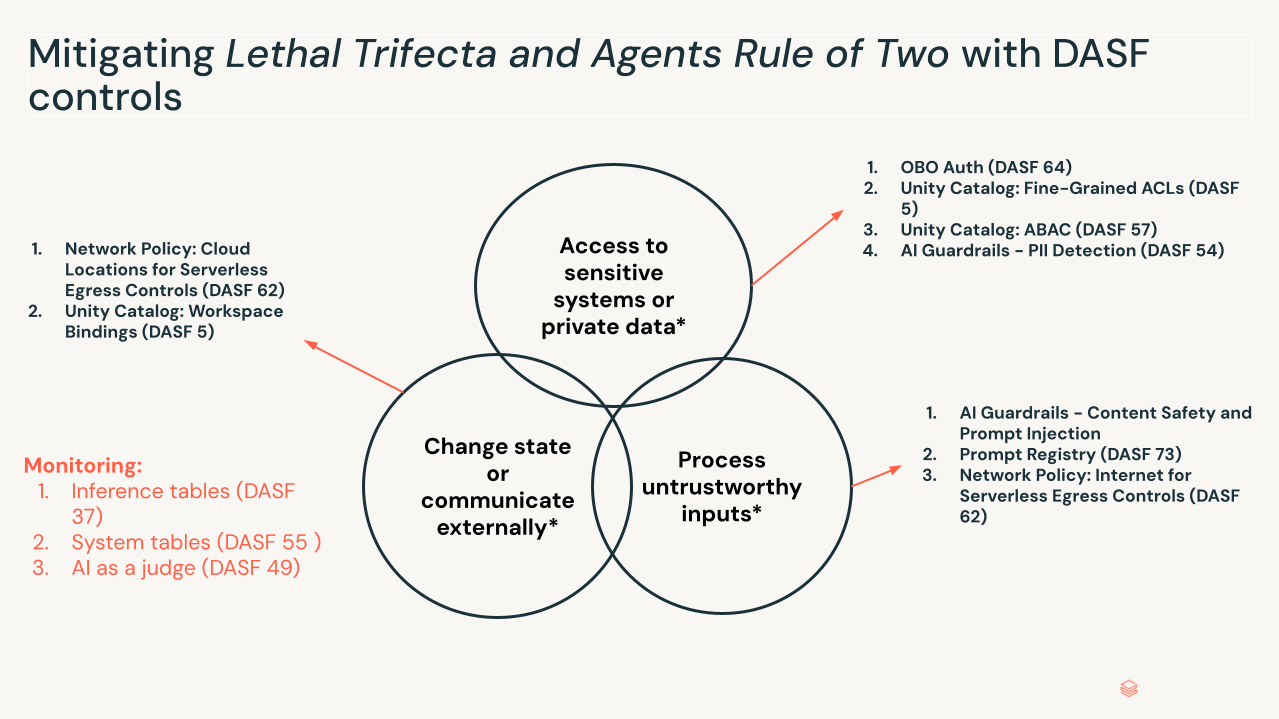
- Zugriff auf sensible Systeme oder private Daten: Der Agent kann private oder eingeschränkte Daten abrufen.
- Verarbeitung nicht vertrauenswürdiger Eingaben: Der Agent verarbeitet Daten von außerhalb der Vertrauensgrenze – Benutzer-Prompts, externe Websites, eingehende E-Mails.
- Zustandsänderung oder externe Kommunikation: Der Agent kann den Zustand durch Tools oder MCP-Verbindungen ändern – Senden von E-Mails, Ausführen von SQL, Ändern von Code.
Wenn alle drei vorhanden sind, kann eine indirekte Prompt-Injection, die in nicht vertrauenswürdigen Daten eingebettet ist, den gesamten Fähigkeitssatz des Agenten kapern und ihn zu einem „confused deputy“ machen, der autorisierte Aktionen mit böswilliger Absicht ausführt. Entfernen Sie ein beliebiges Bein, indem Sie die Berechtigungen einschränken, einen menschlichen Kontrollpunkt hinzufügen, die Absicht vor der Tool-Auswahl validieren und die Angriffskette unterbrechen.
Wie die Erweiterung organisiert ist
Die 35 neuen Risiken und 6 Kontrollen sind um drei Unterkomponenten organisiert, die abbilden, wie Agenten tatsächlich funktionieren:
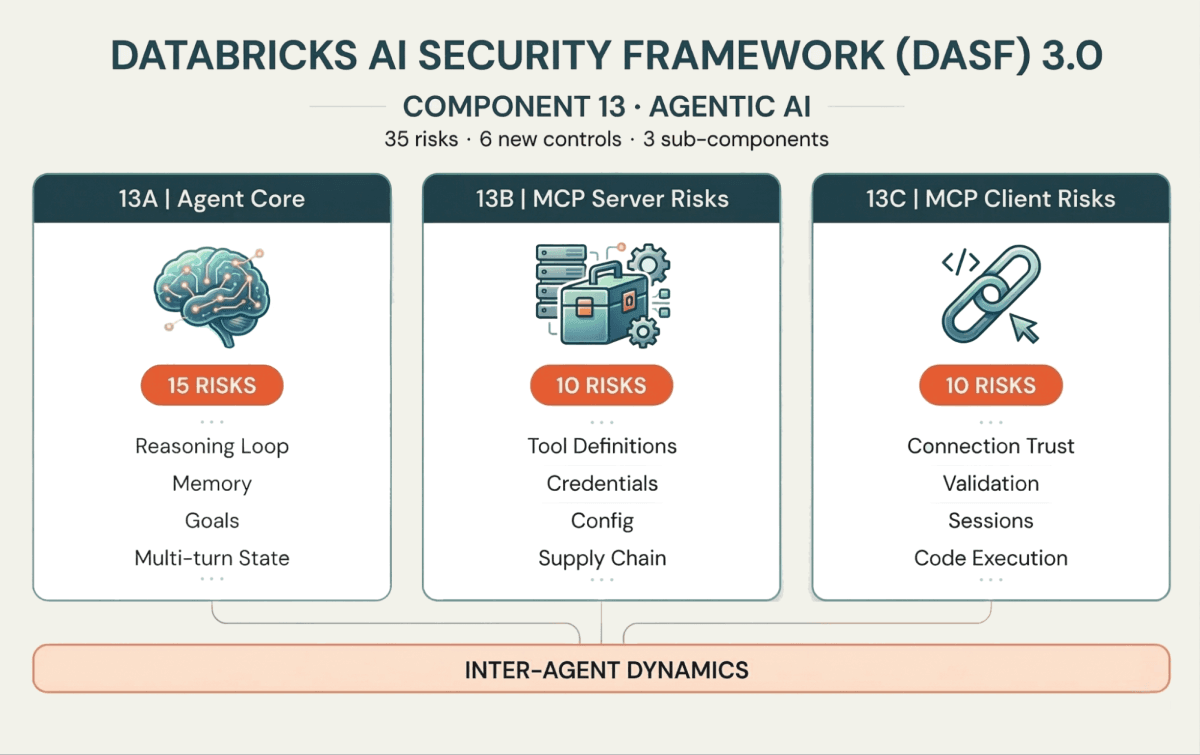
13A: Der Agent Core (Gehirn und Speicher)
Diese Risiken zielen auf die Schlussfolgerungsschleife des Agenten ab. Memory Poisoning (Risiko 13.1) führt falsche Kontexte ein, die aktuelle oder zukünftige Entscheidungen verändern. Intent Breaking & Goal Manipulation (Risiko 13.6) zwingt den Agenten, von seinem Ziel abzuweichen. Und da Agenten in Multi-Turn-Schleifen arbeiten, können Cascading Hallucination Attacks (Risiko 13.5) einen kleinen Fehler über Iterationen hinweg zu einer destruktiven Aktion verstärken.
13B: MCP Server-Risiken (die Tool-Schnittstelle)
Agenten interagieren über Tools mit externen Systemen, die zunehmend über das Model Context Protocol (MCP) standardisiert werden. Auf der Serverseite können Angreifer Tool Poisoning (Risiko 13.18) einsetzen – bösartiges Verhalten in Tool-Definitionen einschleusen – oder Prompt Injection (Risiko 13.16) innerhalb von Tool-Beschreibungen ausnutzen, um Sicherheitskontrollen zu umgehen.
13C: MCP Client-Risiken (die Verbindungsebene)
Auf der Client-Seite, wenn der Agent eine Verbindung zu einem Malicious Server (Risiko 13.26) herstellt oder die Serverantworten nicht validiert, riskiert er Client-Side Code Execution (Risiko 13.32) oder Data Leakage (Risiko 13.30). Mit zunehmender MCP-Akzeptanz ist die Sicherung der Client-Server-Grenze genauso wichtig wie die Sicherung der Agentenlogik.
Inter-Agenten-Dynamik
Agenten werden zunehmend mit anderen Agenten kommunizieren. Das schafft Risiken wie Agent Communication Poisoning (Risiko 13.12) und Rogue Agents in Multi-Agent Systems (Risiko 13.13) – Agenten, die außerhalb von Überwachungsgrenzen agieren, ein Problem, das mit zunehmender Skalierung wächst.
Kontrollen zur Sicherung von KI-Agenten und autonomen Systemen
DASF befasst sich schon immer mit Defense-in-Depth. Aber wenn ein KI-System Aktionen ausführen kann, reichen schreibgeschützte Zugriffskontrollen nicht mehr aus. Die neuen Kontrollen adressieren dies direkt:
- Least Privilege für Tools (DASF 5, DASF 57, DASF 64): Agenten benötigen granulare Berechtigungen, die auf ihre unmittelbare Aufgabe zugeschnitten sind, und begrenzen den Schadensradius so, wie RBAC und ABAC die eines Menschen begrenzen. Nur weil ein Agent das HR Metrics Tool aufrufen kann, heißt das nicht, dass er es tun sollte, wenn er eine Vertriebsanfrage beantwortet.
- Human-in-the-loop-Überwachung (DASF 66): Für kritische Aktionen ist eine menschliche Überprüfung vor der Tool-Ausführung erforderlich. Das Kontrolldesign berücksichtigt Genehmigungsmüdigkeit – wenn Sie den menschlichen Prüfer überfordern, haben Sie eine neue Schwachstelle geschaffen, keine gelöst.
- Sandboxing und Isolierung (DASF 34, DASF 62): Vom Agenten generierter Code wird in temporären, isolierten Umgebungen ausgeführt. Wenn ein Agent entscheidet, ein Skript zu schreiben und auszuführen, sollte diese Ausführung keinen Zugriff auf das breitere System und die ausgehenden Verbindungen zu unbekannten Zielen haben.
- KI-Gateway und Guardrails (DASF 54): Agenten benötigen Schutz vor Szenarien, in denen ein Agent manipuliert wird, um Daten preiszugeben, die er nicht preisgeben sollte. Die Interaktionen von Agenten über Gateways und Guardrails wie Überwachung, Sicherheitsfilterung und PII-Erkennung müssen angewendet werden. Diese Guardrails können entweder auf die Eingabe oder die Ausgabe eines Agenten (oder beides) angewendet werden. Außerdem ist es ebenso wichtig zu überwachen, was tatsächlich vom Agenten zurückgegeben wird.
- Beobachtbarkeit des Denkprozesses (DASF 65): Standard-Logging sagt Ihnen, was passiert ist. Agentic Tracing erfasst warum – die Planungsschritte, die Begründung für die Tool-Auswahl, die Gedankenkette, die zu einer Aktion geführt hat. Ohne dies können Sie die Entscheidungen eines Agenten nicht überprüfen oder erkennen, wann seine Logik kompromittiert wurde.
Für Databricks-Kunden ordnet das Kompendium diese Kontrollen Plattformfunktionen zu, darunter Unity Catalog-Governance für den Agentendatenzugriff, das Agent Bricks Framework, AI Gateway-Schutzmechanismen und AI Search-Sicherheitseinstellungen.
Mit der Community entwickelt
Diese Erweiterung spiegelt das Feedback von Gutachtern und Mitwirkenden aus Databricks und der Sicherheits-Community wider, einschließlich Teams von Atlassian, Experian und ComplyLeft. Wir haben uns auch stark auf die Arbeit von MITRE ATLAS, OWASP, NIST und der Cloud Security Alliance gestützt – das aktualisierte Kompendium ordnet alle 97 Risiken und 73 Kontrollen diesen Industriestandards zu.
Erste Schritte
Laden Sie das DASF Agentic AI Extension Whitepaper für die vollständige Behandlung aller 35 neuen agentischen KI-Risiken und 6 neuen Kontrollen herunter und greifen Sie auf das aktualisierte Kompendium (Google Sheet, Excel) zu, das nun agentische Risiken und Kontrollen neben dem ursprünglichen DASF abbildet. Nutzen Sie diese Ressourcen, um:
- Ihre aktuellen Agentenarchitekturen anhand des Agent-KI-Risikomodells zu bewerten.
- Ihre Tool-Ökosysteme – einschließlich MCP-Servern und -Clients – den identifizierten Bedrohungsvektoren zuzuordnen.
- Die empfohlenen Kontrollen zu implementieren, um sicherzustellen, dass Ihre Agenten innerhalb sicherer, gesteuerter Grenzen arbeiten.
Für tiefergehende Einblicke lesen Sie das vollständige DASF Whitepaper und erkunden Sie die Dokumentation zum Agent Bricks Framework, um zu sehen, wie diese Kontrollen auf der Plattform funktionieren.
Wenden Sie sich mit Feedback an Ihr Databricks-Account-Team oder senden Sie uns eine E-Mail an dasf@databricks.com – dieses Framework gehört der Community genauso wie uns.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.