KI-Serving-Plattform, die sich an Ihr Modell anpasst
Eine Plattform für alle KI-Modelle – klassisches ML, Deep Learning und Agenten – über 300K QPS, unter 10 ms, ohne Tuning
von Anshul Gupta
- Was es ist: Eine vollständig verwaltete Plattform, die jedes Modell in der Produktion ausführt – von einem 2 MB großen scikit-learn-Klassifikator auf einem CPU-Kern bis hin zu einem feinabgestimmten 70B LLM auf acht GPUs, ganz ohne Konfigurationsaufwand.
- Die gelöste Herausforderung: Benutzerdefinierte Modelle weisen stark unterschiedliche Ressourcenprofile und Datenverkehrsmuster auf, sodass keine einzelne statische Konfiguration für alle passt. Stattdessen passt sich die Plattform an, hält die Latenz niedrig und sorgt gleichzeitig dafür, dass jeder Knoten effizient bleibt.
- Die Ergebnisse: Über 300K QPS bei einer p99-Latenzverzögerung von <10 ms und bis zu 90 % geringere Infrastrukturkosten für Kunden, die von selbstverwalteten Stacks migrieren.
Herausforderungen beim Ausführen von benutzerdefinierten Modell-Inferenzen
Wenn Sie ein Machine-Learning-Modell in der Produktion bereitstellen, gehen Sie eine Verpflichtung ein: Jede Anfrage wird unabhängig von Traffic-Spitzen innerhalb weniger Millisekunden abgeschlossen, und Ihre Kosten bleiben niedrig, wenn der Traffic gering ist. Model Serving ist die Infrastruktur, die diese Verpflichtung einhält, und in der bisherigen Geschichte der Branche war die Einhaltung dieser Verpflichtung ebenso schwierig wie die Erstellung des Modells selbst.
Benutzerdefinierte Modelle unterscheiden sich grundlegend von Foundation Models. Eine Plattform, die ein Foundation Model (Llama, Mistral, eine CLIP-Variante) hostet, weiß genau, was sie ausführt: die Architektur, den Speicherbedarf, die Inferenzmerkmale, und kann tiefgehend für dieses eine Modell optimieren. Plattformen für benutzerdefinierte Modelle sind das genaue Gegenteil. Dieselbe Plattform muss einen 2 MB großen scikit-learn-Klassifikator auf einem einzelnen CPU-Kern und ein feinabgestimmtes 70B LLM auf acht GPUs bereitstellen; einen Ranker mit geringer Latenz, der keine Warteschlangen toleriert, und ein Embedding-Modell, das von aggressivem Batching profitiert. Eine Plattform, die jede Art von Modell bedienen kann, wobei keine zwei Modelle das gleiche Ressourcenprofil, die gleiche Traffic-Form oder das gleiche Latenzbudget aufweisen.
Herkömmliche Plattformen verlagern diese Komplexität zurück auf den Kunden: Replikatanzahl, Gleichzeitigkeit pro Replikat, Schwellenwerte für die automatische Skalierung. Das ist immer noch DIY, nur auf einer höheren Abstraktionsebene. Und es hört nie auf: Jedes neue Modell und jede Traffic-Verschiebung erfordert eine erneute Profilerstellung und Feinabstimmung. So müssen Ihre besten Ingenieure vor und nach dem Release Brände in der Produktion löschen, und die Bereitstellung wird zum Bremsklotz, der jeden Start verlangsamt. Das Ergebnis sind die Kosten, auf die es am meisten ankommt – in der Entwicklung bewährte Modelle liegen wochenlang herum, bevor sie die Produktion erreichen.
Unsere Mission: Die ML-Stack-Steuer abschaffen
Die manuelle Feinabstimmung der Serving-Infrastruktur ist eine Steuer auf jedes Modell, das ein Unternehmen ausführt. Bei entsprechender Skalierung wird dies strukturell, da Teams dedizierte Serving-Gruppen einrichten, deren einzige Aufgabe darin besteht, Modelle in der Produktion aktiv und leistungsfähig zu halten. Wir nennen das die ML-Stack-Steuer.
Databricks Custom Model Serving ist eine vollständig verwaltete Echtzeit-Inferenzplattform für jedes in MLflow gepackte Modell. Unsere Mission ist es, diese Steuer in drei Phasen des Lebenszyklus eines Modells zu eliminieren, damit sich die Serving-Teams unserer Kunden auf anspruchsvollere Wertschöpfungen konzentrieren können:
- Die Vorproduktion vereinfachen. Ein in Databricks trainiertes Modell lässt sich mit einem einzigen Klick bereitstellen – wir passen die Umgebung exakt an, ohne Überraschungen bei der Laufzeit, und optimieren die Bereitstellungszeit, damit Iteration und Rollback schnell bleiben.
- Die Produktion zuverlässig, skalierbar und kosteneffizient gestalten. Die Infrastruktur passt sich zur Laufzeit an jedes Modell und dessen Traffic an, wodurch die Latenz niedrig und die Kosten gering gehalten werden, ohne dass Einstellungen vorgenommen werden müssen. (Der Schwerpunkt dieses Beitrags.)
- Die Nachproduktion vereinfachen. Jeder Endpunkt überträgt standardmäßig Telemetriedaten in den Unity Catalog (Metriken, OTel-native Protokolle und Traces, sofortige Inferenztabellen, die jede Anfrage an Delta und MLflow Tracing erfassen). Genie Code setzt auf all dem auf, um eine neuartige, agentenbasierte betriebliche Observability zu bieten. Observability für AI ist ein Kontextproblem, und der gesamte Kontext befindet sich auf einer einzigen Plattform.
Dies funktioniert, weil Custom Model Serving nativ in Databricks integriert ist: Daten, Features, Training, MLflow-Paketierung, Serving und Agenten sind ein einziger, kontrollierter Stack und keine separat zusammengeschusterten Systeme.
Dieser Beitrag befasst sich mit der zweiten Phase und zeigt, wie wir über 300K+ QPS bei geringer Latenz für eine Vielzahl von Modellen mit einem ansatzfreien Ansatz (ohne Regler) erreichen. Das ist es, was die Steuer verschwinden lässt.
Architektur
Drei Einschränkungen prägen jede Entscheidung in der Architektur: geringe Latenz, hohe Skalierbarkeit und Kosteneffizienz. Sie wirken gegeneinander (der einfache Weg zur Verringerung der Latenz ist Überbereitstellung, der einfache Weg zur Kostensenkung ist Unterbereitstellung), und alle drei gleichzeitig für jede Art von Modell ohne Ressourcenverschwendung einzuhalten, ist das eigentliche technische Problem.
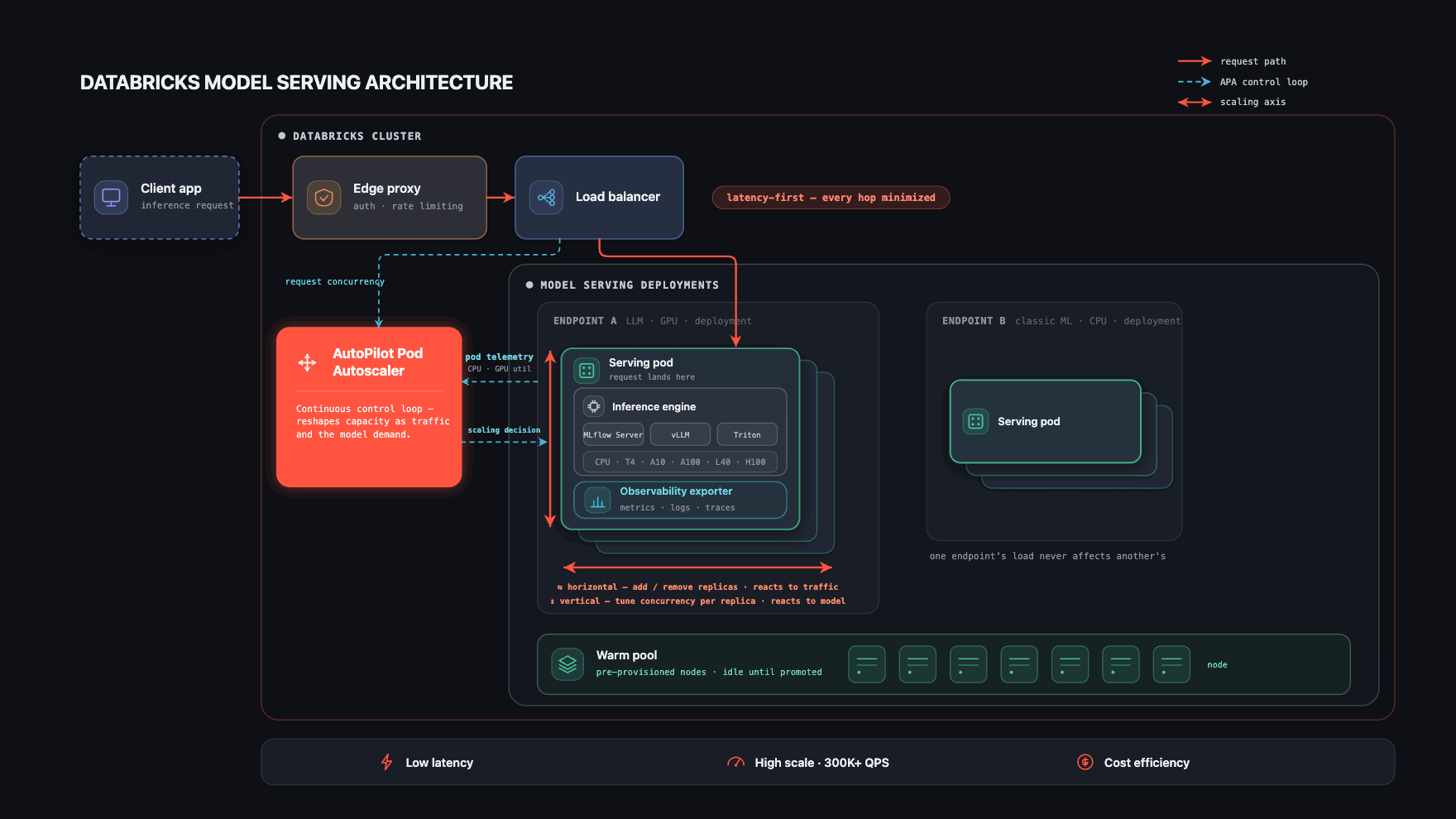
Drei Dinge sorgen dafür, dass es funktioniert.
- Ein kurzer, isolierter Pfad für Anfragen, der den Latenz-Overhead bei jedem Hop minimal hält.
- Automatische Laufzeitauswahl – jedes Modell wird auf der Inferenz-Engine bereitgestellt, die am besten dafür geeignet ist.
- Das Herzstück der Plattform – ein Autoscaler, der sich in Echtzeit sowohl an das Modell als auch an dessen Traffic anpasst, wodurch die Latenz niedrig und die Skalierbarkeit hoch gehalten wird, während die Kosten sinken.
Die ersten beiden sorgen dafür, dass eine einzelne Anfrage schnell bleibt. Der dritte Punkt hält das gesamte System schnell und kosteneffizient, wenn sich Modelle und Traffic ändern. Der größte Teil dieses Abschnitts befasst sich mit dem dritten Punkt.
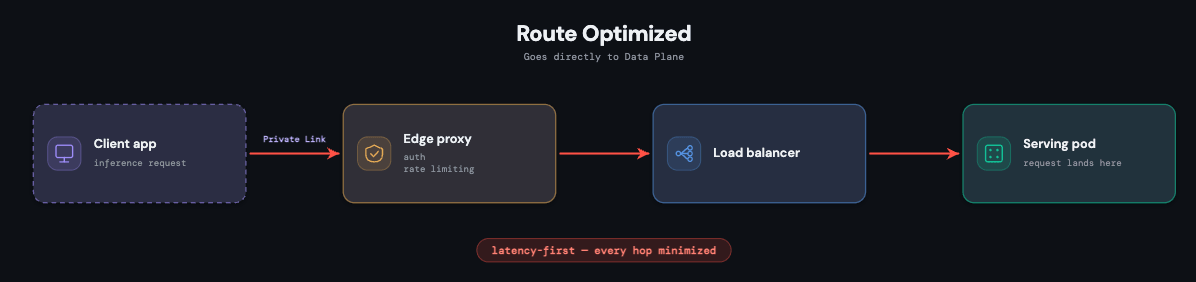
Kurzer, isolierter Pfad für Anfragen
Jeder Serving-Endpunkt ist ein vollständig isoliertes Kubernetes-Deployment mit eigenen Pods und einem für die Modellversion spezifischen Container-Image. Diese Isolation ist beabsichtigt: Der Traffic, Ausfälle oder der Ressourcendruck eines Endpunkts können einen anderen nicht beeinflussen, und benutzerdefinierte Workloads bleiben sicher.
Der Pfad selbst wird so kurz wie möglich gehalten, da Latenz auf jeder Ebene eine Einschränkung erster Klasse darstellt. Eine Anfrage geht über einen PoP-Proxy ein. Nach der Authentifizierung durchläuft sie einen gemeinsam genutzten Load Balancer für das Verbindungsmanagement und landet sofort auf dem Pod, der sie bedient. Jeder Pod führt außerdem ein Observability-Sidecar aus, das Metriken, Protokolle, Payload-Protokolle und Traces sowohl für die Plattformüberwachung als auch für kundenorientierte Dashboards exportiert.
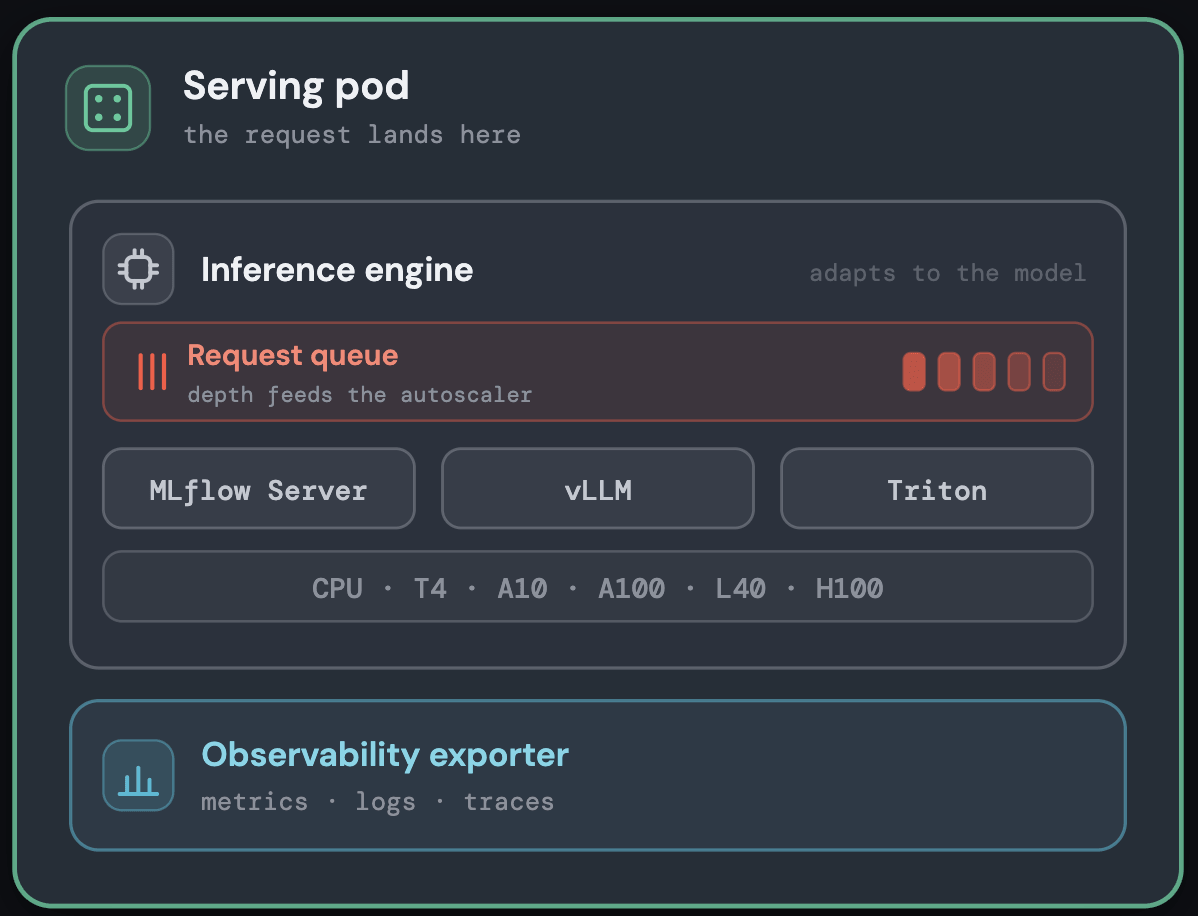
Effiziente Auswahl der Modell-Laufzeit
Innerhalb jedes Pods wird das Modell auf der Inferenz-Engine ausgeführt, die am besten für seinen Typ geeignet ist – ein asynchroner Gunicorn-MLflow-Server für klassische ML-Modelle und GPU-optimierte Engines für große Modelle mit Unterstützung für vLLM, Triton oder die eigene Laufzeit des Kunden – alles hinter einer einheitlichen Serving-Schnittstelle.
Jedem Modell die richtige Laufzeit zuzuweisen, hält den Overhead pro Anfrage ohne manuelle Abstimmung gering. Die Einzelheiten sind im folgenden Diagramm dargestellt.
Der Autoscaler: Anpassung an Modell und Traffic
Ein von uns entwickelter benutzerdefinierter Kubernetes-Controller – der AutoPilot Pod Autoscaler (APA) – bildet das Zentrum der Plattform. Er sammelt kontinuierlich Signale vom Load Balancer (aktive Gleichzeitigkeit, Warteschlangentiefe) und von den Pods selbst (CPU-Auslastung, GPU-Auslastung, GPU-Speicher und viele andere) und wandelt sie in Skalierungsentscheidungen um.
Der Autoscaler existiert, um zwei Arten von Unvorhersehbarkeit gleichzeitig abzufangen:
- Das Modell ist unvorhersehbar. Sie kennen das Ressourcenprofil eines benutzerdefinierten Modells nicht im Voraus. Ein CPU-intensives xgboost-Modell bedient möglicherweise nur 1 Anfrage pro Kern, ein Agent kann Hunderte von Anfragen pro Kern ausführen, während ein feinabgestimmtes 13B LLM von mehreren zusammengefassten Anfragen profitiert. APA lernt das Limit jedes Modells zur Laufzeit und stimmt ab, wie viele Anfragen jedes Replikat akzeptieren sollte: modellbewusste vertikale Skalierung.
- Der Traffic ist unvorhersehbar. Er weist Spitzen auf, bricht aus und fällt ohne Vorwarnung auf Null. Ein Betrugserkennungs-Endpunkt kann zu Beginn eines Ausverkaufs in Sekundenschnelle um das Zehnfache ansteigen; ein regionalspezifischer Anwendungsfall läuft eine Stunde lang auf Hochtouren und ist dann über Nacht inaktiv. APA reagiert im selben Moment, in dem sich die Nachfrage verschiebt: anfragebasierte horizontale Skalierung.
Aus diesem Grund ist der Autoscaler das Herzstück des Systems: Er ist die einzige Komponente, die alle drei Einschränkungen – Latenz, Skalierbarkeit und Kosten – gleichzeitig für jedes Modell auf der Plattform einhält.
Zwei Achsen der Elastizität
Herkömmliche Autoscaler führen entweder eine anfragebasierte oder eine ressourcenbasierte automatische Skalierung durch, aber beide haben eine Schwachstelle. Die anfragebasierte Skalierung reagiert schnell, ist aber ineffizient – sie behandelt jede Anfrage identisch, unabhängig davon, wie ausgelastet das jeweilige Replikat ist, sodass Sie entweder eine Überbereitstellung vornehmen oder die Replikatanzahl unnötig hin- und herwechselt. Die ressourcenbasierte Skalierung (CPU-, GPU-Auslastung) ist effizient, hinkt jedoch hinterher – Auslastungsmetriken folgen dem Traffic verzögert. Bis der Autoscaler reagiert, ist der Schaden für p99 bereits entstanden.
APA nutzt beide Signale gleichzeitig, wobei jedes das tut, was es am besten kann – und genau das sind die beiden Achsen.
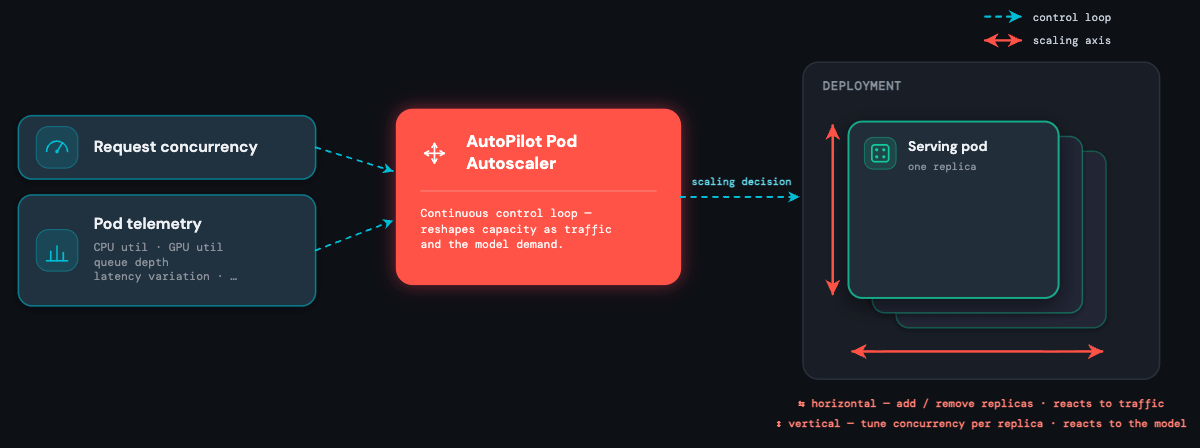
Die horizontale Skalierung reagiert auf Anfragen. Sie überwacht die aktiven gleichzeitigen Anfragen pro Endpunkt und fügt Replikate hinzu oder entfernt sie, sobald sich die Nachfrage verschiebt. Die Formel folgt dem Kubernetes Horizontal Pod Autoscaler:
Modellbewusste vertikale Skalierung reagiert auf Modelleigenschaften. In regelmäßigen Abständen analysiert der Autoscaler eine Reihe von Metriken, um zu ermitteln, wie viel Last ein einzelnes Replikat tatsächlich bewältigen kann, und passt die target_concurrency in der obigen Formel entsprechend an. Dies unterscheidet sich grundlegend von der herkömmlichen vertikalen Skalierung, bei der der Hardwaretyp geändert wird. Hier bleibt die Hardware dieselbe: Was sich ändert, ist die Anzahl der gleichzeitigen Anfragen, die jeder Pod akzeptiert, abgestimmt auf das Ressourcenprofil des darauf ausgeführten Modells.
Zu den Metriken, auf die wir uns stützen, gehören unter anderem:
- Hardware-Metriken — CPU- und GPU-Auslastung, Speicherauslastung, I/O-Wartezeit
- Aktuelle Latenz und Profil der Warteschlangentiefe
- GPU-spezifische Metriken — Speicherbandbreite, FP16/BF16-FLOPS-Auslastung
Schutzmaßnahmen. Änderungen der Gleichzeitigkeit pro Knoten sind sensibel, und große oder häufige Schwankungen können die Systemleistung beeinträchtigen. Pod-Metriken können bei kurzen Traffic-Schwankungen schwanken oder wenn die Kosten pro Anfrage für ein Modell stark variieren. Wir schützen uns vor diesem Metrik-Rauschen. Eine kurze CPU-Spitze sollte das Limit für die Gleichzeitigkeit nicht sofort senken, nur um es Sekunden später wieder zu erhöhen. Dazu unternehmen wir drei Schritte:
Die Gleichzeitigkeit wird nur angepasst, wenn eine Metrik einen stabilen Schwellenwert überschreitet, und die Schwellenwerte werden pro Metrik optimiert.
- Wir begrenzen die maximale Änderung der Gleichzeitigkeit pro Entscheidungszyklus
- Wir erzwingen immer minimale/maximale Limits für die Gleichzeitigkeit eines Workloads
- Änderungen der Gleichzeitigkeit erfolgen in einer geringeren Frequenz (alle 30 s) im Vergleich zur horizontalen Skalierung. Dies ist auch deshalb wichtig, weil sie im Gegensatz zum aktuellen Traffic wie beim HPA auf historischen Metriken basieren.
Die beiden Achsen sind gekoppelt: Das Gleichzeitigkeitsergebnis der vertikalen Skalierung fließt über den Nenner target_concurrency in die Berechnung der horizontalen Skalierung ein. Die horizontale Skalierung sorgt für Verfügbarkeit und geringe Latenz, sobald sich der Traffic verschiebt. Die modellbewusste vertikale Skalierung stellt sicher, dass jeder Knoten effizient genutzt wird, und passt die Gleichzeitigkeit an, wenn sich das Modellverhalten weiterentwickelt. Zusammen verhindern sie die falsche Entscheidung zwischen „schnell, aber verschwenderisch“ und „effizient, aber langsam“.
Schwellenwerte für Scale-Up und Scale-Down
Die reine HPA-Formel allein reicht nicht aus: Sie ist nicht robust gegenüber Traffic-Spitzen. Eine kurze 10-fache Spitze berechnet eine 10-fache Erhöhung der Replikate; ein kurzer Rückgang um 95 % berechnet eine Verringerung um 95 %. Beides ist gefährlich, entweder für die Kosten oder für die Latenz und Verfügbarkeit.
Das horizontale Hochskalieren (Scale-Up) ist aggressiv In der Produktion kann eine hohe Latenz massive negative Auswirkungen auf das Geschäft haben. Viele Anwendungsfälle weisen naturgemäß stark schwankende Traffic-Muster auf, deren Unterstützung geschäftskritisch ist. Um Spitzen abzufangen, erfassen wir eingehende Anfragen jede Sekunde, und APA trifft alle 5 Sekunden eine Entscheidung zum Hochskalieren basierend auf dem Traffic der letzten 20 Sekunden. Dies reduziert Warteschlangen und 429er-Fehler bei Spitzen erheblich — viele Kunden stellten einen bis zu 5-fachen Unterschied fest. Wir begrenzen auch, wie stark wir in einem einzelnen Zyklus im Verhältnis zur aktuellen Last hochskalieren können. Insgesamt gilt: Wir können in 60 Sekunden von 10 auf 10.000 QPS hochskalieren (abhängig von der Ladezeit des Modells)
Das Herunterskalieren (Scale-Down) ist konservativ. Eine Spitze signalisiert oft, dass weiterer Traffic folgt. Beim Herunterskalieren entscheidet APA weiterhin alle 5 Sekunden, berücksichtigt jedoch den Traffic der letzten ca. 5 Minuten, bevor Replikate entfernt werden.
Die Asymmetrie ist beabsichtigt. Spitzen treten plötzlich auf; Rückgänge sind oft vorübergehend. Die Kosten für ein vorzeitiges Herunterskalieren (ein Kaltstart im ungünstigsten Moment) überwiegen die Kosten für das vorübergehende Bereithalten einiger inaktiver Replikate.
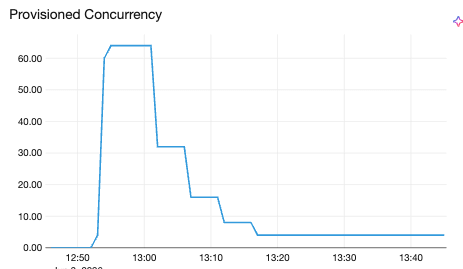
Vertikales Scale-Up und Scale-Down der Gleichzeitigkeit. Dieselbe asymmetrische Philosophie gilt für die vertikale Skalierung: Schnelles Reduzieren der Gleichzeitigkeit, wenn ein Pod Überlastung anzeigt (das Weiterleiten weniger Anfragen an ein bereits ausgelastetes Replikat schützt die Latenz), aber niemals unter ein Minimum. Diese Entscheidungen werden in einem Intervall von 30 Sekunden getroffen, also langsamer als die 5-Sekunden-Schleife der horizontalen Skalierung. Dies ist beabsichtigt: Die vertikale Skalierung ist eine Optimierung des eingeschwungenen Zustands, die sich im Laufe der Zeit an das Ressourcenprofil eines Modells anpasst, und keine Echtzeitreaktion auf Spitzen.
Minimierung der Kaltstartzeit
Ein Kaltstart ist das schlimmste Latenzereignis in einem Serving-System; man kann sich nicht mehr herausoptimieren, sobald er auftritt. Wir gehen das Problem an zwei Fronten an: So viel wie möglich vorwärmen und die unvermeidbaren Schritte so schnell wie möglich machen.
Warme Knoten-Pools. Ein prädiktiver Algorithmus verwaltet einen Pool von vorab bereitgestellten Knoten pro Databricks-Cluster, die bereits mit dem Basis-Runtime-Image geladen sind. Wenn der Autoscaler ein Replikat hinzufügt, wählt er aus diesem Pool: Der Knoten ist bereits aktiv, das Basis-Image wurde bereits geladen, und die einzige verbleibende Aufgabe ist das Herunterladen des Modells. Wir berechnen unseren Kunden keine Gebühren für die Kapazität des warmen Pools. Das ist ein direkter Mehrwert, den sie von Databricks erhalten.
Schneller Modell-Download. Modell-Container-Images werden in einem Hot-Cache-Layer im Cloud-Speicher gespeichert und beim Pod-Start in parallelen Blöcken geladen, was die Image-Ladezeit für große Modell-Container erheblich verkürzt. Konfigurationsänderungen, die sich nicht auf das Modell oder seine Abhängigkeiten auswirken (Updates von Endpunkt-Metadaten, Änderungen von Routing-Regeln), werden ganz ohne Neustart des Pods angewendet, da ein vermiedener Neustart der beste Start von allen ist.
Bereitgestellte Gleichzeitigkeit (Provisioned Concurrency). Für latenzkritische Endpunkte, die keinen Kaltstart tolerieren können, konfigurieren Benutzer eine minimale Untergrenze für die Gleichzeitigkeit. Dadurch bleibt eine Basislinie von Pods vollständig bereit, auf denen das Modell geladen ist und sofort einsatzbereit ist, ohne dass es bei der ersten Anfrage zu Warteschlangen kommt.
Updates und Wartung ohne Ausfallzeiten (Zero-Downtime). Updates und Wartungsarbeiten erfolgen völlig ohne Ausfallzeiten. Alle Pods mit der neuen Modellversion sind aktiv und bereit, bevor der Traffic von den alten Pods abgezogen wird.
Was wir in der Praxis gelernt haben
Kunden haben Vorteile in jeder Dimension festgestellt:
- Kosten: Wir haben Kunden, die im Vergleich zu ihren eigenen Workloads (DIY) Kosteneinsparungen von über 90 % erzielt haben.
- Latenz: Die p99- und p50-Latenz hat sich bei vielen Kunden um das Doppelte verbessert.
- Skalierung: Kunden haben im Produktivbetrieb auf über 100.000 QPS skaliert, und das bei minimalem bis gar keinem Wartungsaufwand.
- Wir halten eine Verfügbarkeit von 99,99 % im Produktivbetrieb aufrecht.
Die zweiachsige Autoskalierung lässt sich auf alle Modelltypen übertragen. Wir waren uns nicht sicher, ob der horizontale und vertikale Ansatz für alles geeignet ist, von CPU-Klassifikatoren bis hin zu GPU-LLMs. Das tut er: Die horizontale Achse verarbeitet den Traffic für jedes Modell auf dieselbe Weise, während sich die vertikale Achse bei leichtgewichtigen Modellen auf eine höhere Gleichzeitigkeit und bei GPU-intensiven Modellen auf eine niedrigere Gleichzeitigkeit einstellt. Derselbe Controller, dieselbe Logik, das richtige Verhalten für jedes Modell.
Die meisten Modelle sind homogen. Wir dachten, dass die Limits für die Gleichzeitigkeit mit dem Traffic ständig schwanken würden. In der Praxis bleibt das Ressourcenprofil eines Modells unter derselben Last jedoch meist ähnlich. Die vertikale Achse bewährt sich beim Onboarding und verhält sich danach ruhig.
Kaltstarts lassen sich nicht wegoptimieren. Wir hatten erwartet, dass warme Pools, paralleles Laden von Images und die Wiederverwendung von Deployments die Kaltstarts auf nahezu null reduzieren würden. Sie helfen enorm — aber die Physik setzt Grenzen: Das Hochfahren eines Pods erfordert Zeit, die mit der Modellgröße zunimmt, bei großen GPU-Modellen sogar Minuten. Jenseits dieser Grenze besteht die einzige Lösung darin, eine Mindestkapazität vollständig bereitzuhalten, und genau dafür gibt es die minimale bereitgestellte Gleichzeitigkeit.
Traffic ist berechenbarer, als es aussieht. Das richtige Minimum ist nicht statisch: B2C-Apps werden über Nacht ruhiger, Batch-Pipelines laufen nach Zeitplan. Diese Muster sind erlernbar, und wir entwickeln eine Traffic-Prognose, um die minimale Gleichzeitigkeit vor dem Bedarf zu erhöhen, anstatt ihm hinterherzulaufen. Seien Sie gespannt.
Fazit
Unser Ziel war es, die ML-Stack-Steuer abzuschaffen: das endlose Nachjustieren und das dafür erforderliche dedizierte Serving-Team. Für die gesamte Vielfalt der Modelle, die heute auf Custom Model Serving ausgeführt werden, tun der zweiachsige Autoscaler, warme Pools und Deployments ohne Ausfallzeiten genau das. Die Infrastruktur passt sich dem Modell an und nicht umgekehrt. Sie bringen ein Modell mit, legen einen Bereich für die Gleichzeitigkeit fest, und die Plattform kümmert sich um den Rest.
Das Bereitstellen von Modellen (Model Serving) ist jedoch kein gelöstes Problem. Größere Modelle, neue Hardware und agentenbasierte Workloads verschieben die Skalierung und Komplexität immer weiter über das hinaus, wofür herkömmliche Serving-Infrastrukturen ausgelegt waren. Die offenen Probleme sind real und die Ambitionen hoch: kürzere Kaltstartzeiten, Traffic-Prognosen für prädiktive Skalierung, über 1 Mio. QPS pro Endpunkt und über 10 Mio. QPS pro Cluster, intelligenteres Bin-Packing heterogener GPU-Workloads und die Senkung der p99-Latenz auf unter 5 ms.
Und das ist ein Problem, für dessen Lösung Databricks einzigartig aufgestellt ist. Die Anpassung der Infrastruktur an ein Modell setzt voraus, dass man das Modell kennt: wie es trainiert wurde, wovon es abhängt und wie es sich unter Last verhält. Bei Databricks befindet sich all das auf einer einzigen governed Plattform: Daten und Features, Training, MLflow-Paketierung, Serving, Agents und die Telemetrie, die sie überwacht. Ein eigenständiger Serving-Layer sieht nur einen Container; wir sehen den gesamten Lebenszyklus. Dieser Kontext ermöglicht es der Plattform, sich automatisch auf jedes Modell abzustimmen, und ist der Grund, warum kein nachträglich angebundenes Serving-Produkt die ML Stack Tax ebenso effektiv beseitigen kann.
Wenn Sie diese Art von Infrastrukturproblemen interessiert, wir stellen ein.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.