Ankündigung der allgemeinen Verfügbarkeit von Lakehouse Federation
Entdecken, abfragen, verwalten Sie alle Ihre Daten – egal wo sie liegen
von Andrew Li, Ivan Mitic, Milan Stefanovic, Can Efeoglu, Sachin Thakur, Amy Jiang und Alex Lee
Heute freuen wir uns, die allgemeine Verfügbarkeit (GA) von Lakehouse Federation in Unity Catalog für AWS, Azure und GCP bekannt zu geben! Lakehouse Federation ermöglicht es Ihnen, alle Ihre Daten an einem Ort zu entdecken, abzufragen und zu verwalten. Mit dieser GA-Version können Sie verbesserte Stabilität, Sicherheit und Unternehmensbereitschaft für Ihre föderierten Workloads erwarten.
In diesem Blogbeitrag gehen wir auf die GA-Funktionen von Lakehouse Federation ein, untersuchen, wie sie agile Analysen bei den weltweit führenden Unternehmen ermöglicht, und diskutieren, was als Nächstes kommt.
Lakehouse Federation – Eine Einführung
Unternehmen weltweit, unabhängig von Größe oder Branche, nutzen Daten und KI, um Innovationen voranzutreiben. Aus historischen, organisatorischen oder technologischen Gründen bleiben Daten jedoch oft über mehrere operative und analytische Systeme verteilt. Diese Fragmentierung führt zu mehreren Herausforderungen:
- Schwierigkeiten bei der Entdeckung und dem Zugriff auf alle Daten
- Langsame Ausführung aufgrund von Engineering-Engpässen
- Schwache Compliance über isolierte Systeme hinweg
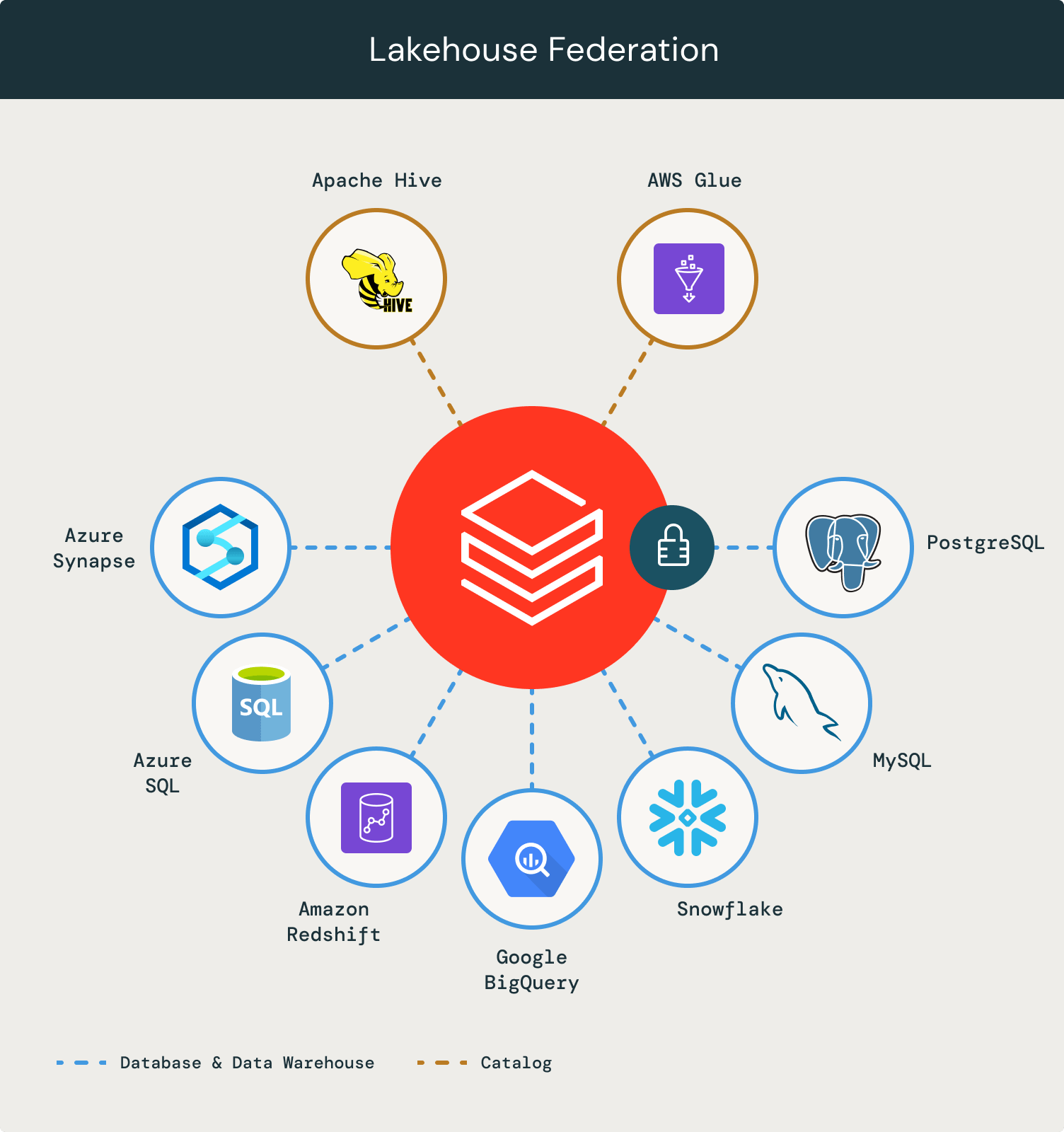
Lakehouse Federation adressiert diese kritischen Schwachstellen und macht es für Unternehmen einfach, isolierte Datensysteme als Erweiterung ihres Lakehouse bereitzustellen, abzufragen und zu verwalten. Mit diesen neuen Funktionen können Sie:
- Erstellen Sie eine einheitliche Ansicht Ihrer Datenlandschaft: Klassifizieren und entdecken Sie automatisch alle Ihre strukturierten und unstrukturierten Daten an einem Ort und ermöglichen Sie jedem in Ihrem Unternehmen, sicher auf alle verfügbaren Daten zuzugreifen und diese zu erkunden – egal wo sie liegen.
- Fragen Sie alle Daten mit einer einzigen Engine effizient ab und kombinieren Sie sie: Beschleunigen Sie Ad-hoc-Analysen und Prototyping über alle Ihre Daten-, Analyse- und KI-Anwendungsfälle hinweg mit den vollständigsten Daten – ohne Datenaufnahme erforderlich – mit einer einzigen Engine. Fortschrittliche Abfrageplanung über Quellen hinweg und Caching sorgen für optimale Abfrageleistung, selbst beim Zugriff auf und der Kombination von Daten aus mehreren Plattformen mit einer einzigen Abfrage.
- Schützen Sie Daten über Datenquellen hinweg: Verwenden Sie ein einziges Berechtigungsmodell, um Zugriffsregeln festzulegen und anzuwenden und alle Ihre Daten über Datenquellen hinweg zu schützen. Wenden Sie Regeln wie Zeilen- und Spaltenebenen-Sicherheit, tagbasierte Richtlinien, zentralisierte Überwachung konsistent über Plattformen hinweg an, verfolgen Sie die Datennutzung und erfüllen Sie Compliance-Anforderungen mit integrierter Datenherkunft und Auditierbarkeit.
Über 5.000 Databricks-Kunden nutzen Lakehouse Federation, um ihre Datenlandschaften zu vereinheitlichen und eine konsistente Datenentdeckung und -verwaltung zu gewährleisten.
„Lakehouse Federation hat es uns ermöglicht, alle unsere Datenbestände über mehrere Data Warehouses und Datenbanken hinweg unter Unity Catalog zu kombinieren, was die Datenentdeckung und die Zugriffsverwaltung vereinfacht. Dies eröffnet eine Vielzahl von Anwendungsfällen, einschließlich Datenaufnahme und Ad-hoc-Abfragen, wodurch unsere Analysen einfacher denn je werden.“ —Alexander Booth, Assistant Director of Research bei den Texas Rangers
Allgemeine Verfügbarkeit
Wir freuen uns, die allgemeine Verfügbarkeit für die Konnektoren für MySQL, PostgreSQL, Amazon Redshift, Snowflake, Azure SQL Database, SQL Server und Azure Synapse bekannt zu geben.
Diese Version markiert einen wichtigen Meilenstein in mehreren Bereichen:
- Verbesserte Leistung: Mit dieser Version haben wir die Abdeckung von Ausdrücken und Operatoren, die wir an SQL Server-, Postgres-, MySQL-, Snowflake-, Redshift- und Synapse-Verbindungen weiterleiten (d. h. an die zugrunde liegende Datenbank delegieren) können, erheblich erhöht. In der Praxis bedeutet dies geringere Latenzzeiten bei Abfragen und schnellere Erstellung von Materialized Views (MV), ohne dass Benutzer ihre Abfragen ändern müssen.
- Verbesserte Stabilität und Beobachtbarkeit: Wir haben unser Föderations- und Pushdown-Framework aktualisiert, um widerstandsfähiger zu sein und Fehlerszenarien zu bewältigen, ohne die Benutzer-Workloads zu beeinträchtigen.
Wir haben auch verbesserte Query Profiles eingeführt, um föderationsspezifische Metadaten und Statistiken zu unterstützen, was Administratoren bessere Möglichkeiten zur Überwachung und Prüfung bietet. - Neue Sicherheitsoptionen: Beginnend mit Quellen aus dem Azure-Ökosystem und Snowflake fügen wir Unterstützung für passwortlose Authentifizierungsoptionen, Azure AD/Entra ID-Unterstützung für Azure SQL und OAuth-Unterstützung für Snowflake hinzu. In den kommenden Monaten werden wir ähnliche Funktionen für die AWS- und Google-Ökosysteme entwickeln.
„Lakehouse Federation hat uns geholfen, unsere Datenlandschaft mit konsistenter Verwaltung an einem Ort zu konsolidieren und erhebliche operative Effizienzgewinne zu erzielen. Dateneinblicke und -qualität sind nun nahtlos integriert, sodass wir uns darauf konzentrieren können, unseren Kunden die besten Einblicke zur Maximierung des Werts aus ihren Werbeinvestitionen zu bieten.“ —Bob Wuisman, Global Head of Production bei Ebiquity plc.
Was kommt als Nächstes?
Catalog Federation
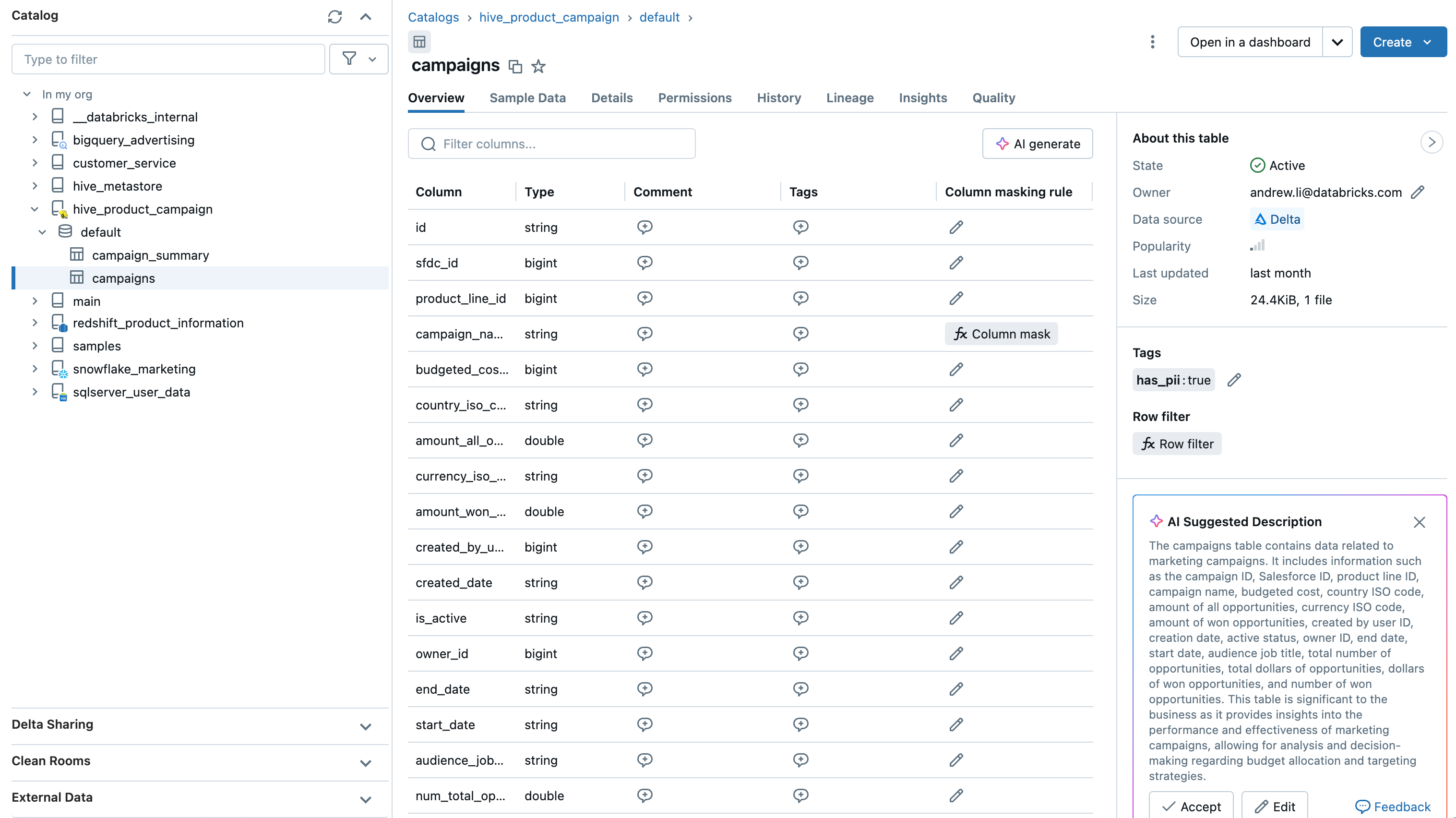
Entdecken, verwalten und greifen Sie mit Lakehouse Federation auf Daten aus Hive Metastore (HMS) und AWS Glue zu. Mit Catalog Federation können Sie jeden externen (oder internen Databricks) HMS einfach als fremden Katalog in Unity Catalog einbinden.
Für Benutzer von Databricks HMS (intern) ist dies eine einfache und unkomplizierte Möglichkeit, mit Unity Catalog zu beginnen und von den einheitlichen Verwaltungsfunktionen von Unity Catalog zu profitieren.
Für Benutzer von externen HMS und AWS Glue bietet es eine eng integrierte Möglichkeit, auf externe Metastore-Daten direkt aus Unity Catalog zuzugreifen, ohne Ihre Arbeitsabläufe zu ändern.
Catalog Federation befindet sich derzeit in der privaten Vorschau.
Neue Konnektoren
Die Erweiterung der Liste unterstützter Datenquellen für Lakehouse Federation bleibt eine Top-Priorität in unserer Mission, Kunden bei der Vereinheitlichung ihrer Datenlandschaften zu unterstützen. Wir freuen uns, Ihnen mitteilen zu können, dass die Konnektoren für Google BigQuery, die die Föderationsunterstützung für Data Warehouses über alle drei großen Cloud-Anbieter hinweg vervollständigen, und für Salesforce Data Cloud jetzt in der öffentlichen Vorschau verfügbar sind.
Konnektoren für Oracle und Teradata werden bald als Vorschau verfügbar sein.
Hohe Durchsatz-Data-Warehouse-Verbindungen
Um eine schnellere Abfrageerfahrung für Data Warehouses zu ermöglichen, die tendenziell größere Tabellen enthalten, fügen wir Funktionen für automatische High-Throughput-Datentransfers hinzu.
In Zukunft, beginnend mit den Konnektoren für Amazon Redshift & Snowflake, können Sie Tabellen aus Data Warehouses schnell abfragen und materialisieren. Im Hintergrund nutzt Lakehouse Federation schnellere/Bulk-APIs (z. B. Auslagerung in Objektspeicher oder Staging-Speicherort parallel) und ruft diese Ergebnisse parallel ab (kein Treiber-Engpass). Alles ohne Benutzereingriff!
Freigabe für Lakehouse Federation
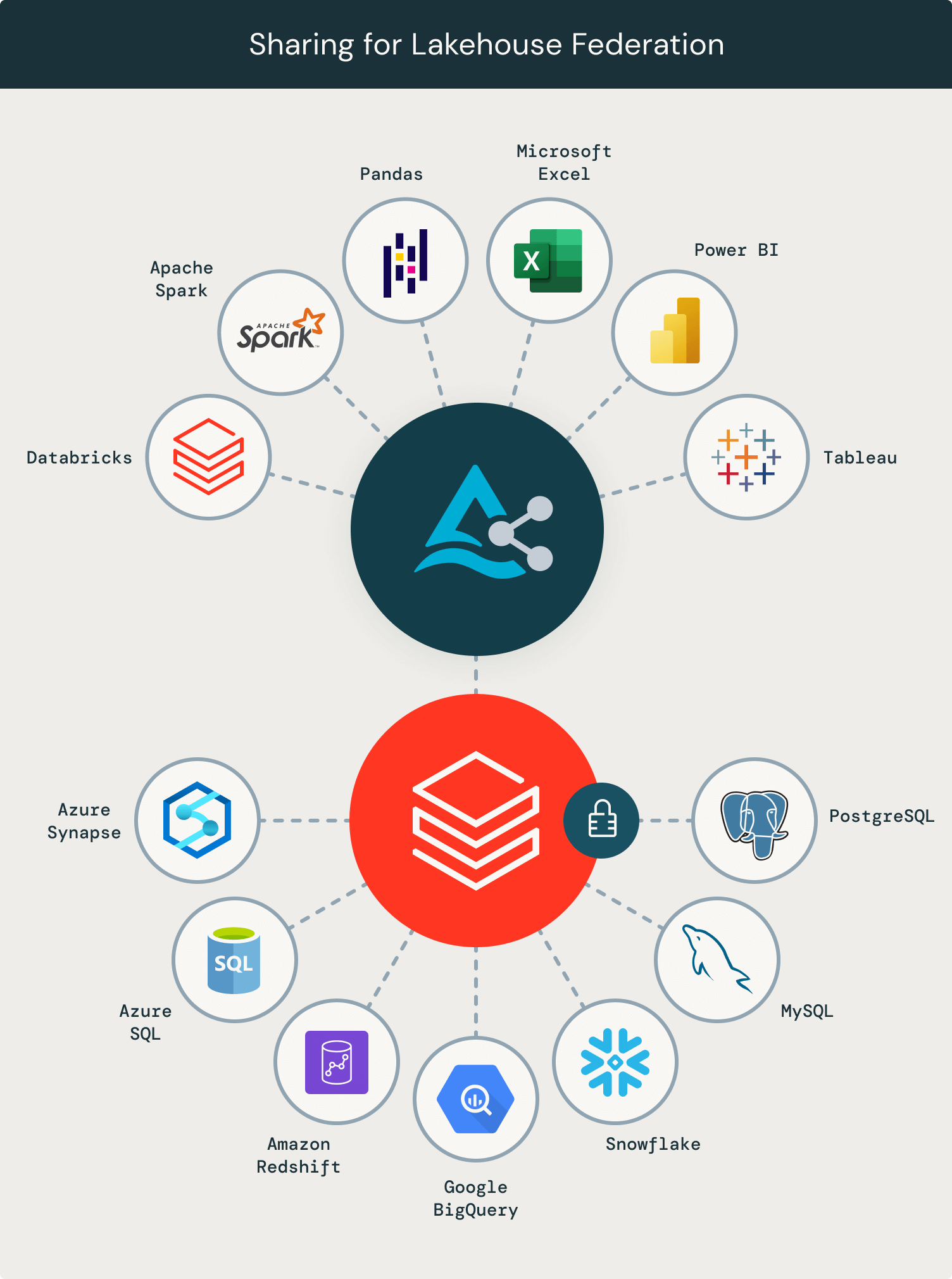
Schließlich wird die Freigabe von Lakehouse Federation-Daten viel einfacher. Die kommende Delta Sharing-Integration wird es Kunden ermöglichen, federierte Tabellen extern freizugeben, ohne dass die Empfänger Zugriff auf Databricks oder das zugrunde liegende Datensystem benötigen. Dies wird die Datenfreigabe optimieren, indem die Notwendigkeit redundanter Kopien über verschiedene Systeme hinweg entfällt.
Erste Schritte
- Lesen Sie unsere Dokumentation (AWS, Azure, GCP), um mit Lakehouse Federation zu beginnen
- Sehen Sie sich die Lakehouse Federation-Sitzung vom Data and AI Summit 2024 für eine detaillierte Betrachtung von Lakehouse Federation an
- Sehen Sie sich an, wie Matei Zaharia, Mitbegründer und Chief Technology Officer bei Databricks, die Keynote auf dem Data+AI Summit 2023 hielt, um mehr über die neuesten Ankündigungen in Unity Catalog zu erfahren!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.