Ankündigung des Lakebase Change Data Feed (CDF)
Öffnung der OLTP-Datenbank für andere Engines
von Pranav Aurora, Cheng Chen und Hristo Stoyanov
- Der Lakebase Change Data Feed (Public Preview) eliminiert die Pipeline-Verbreitung aus operativen Datenbanken. Aktivieren Sie CDF einmal pro Lakebase-Projekt, um die Änderungen jeder Tabelle über Unity Catalog Managed Tables für den direkten Lesezugriff durch jede Engine, jedes Modell oder jeden Agenten verfügbar zu machen.
- Native CDC, durchgängig verwaltet ohne Sidecar-Infrastruktur: keine Datenbank-Konnektoren, keine Überwachung des Replikationsstatus, keine separaten Extraktionsjobs; nachgelagerte Consumer wie SDP-Streaming-Pipelines, DBSQL-materialisierte Ansichten und Agent Bricks-Embeddings abonnieren denselben isolierten Feed, ohne die primäre Arbeitslast zu beeinträchtigen.
- Operative Daten fungieren nun als native Bronze-Schicht in der Medaillon-Architektur. Lakebase Synced Tables stellen bereits Gold-Daten für Anwendungen bereit; Lakebase CDF schließt den Kreis mit vollständiger Unity Catalog-Governance und Lineage über den gesamten Datenlebenszyklus.
Das Verschieben von Daten aus Ihrer operativen Datenbank bedeutete traditionell die Einrichtung und Überwachung einer Pipeline für jede Quelle zu jedem Ziel. Für die meisten Teams ist dies ein fehleranfälliger, ungeregelter und O(n) menschlicher Aufwand.
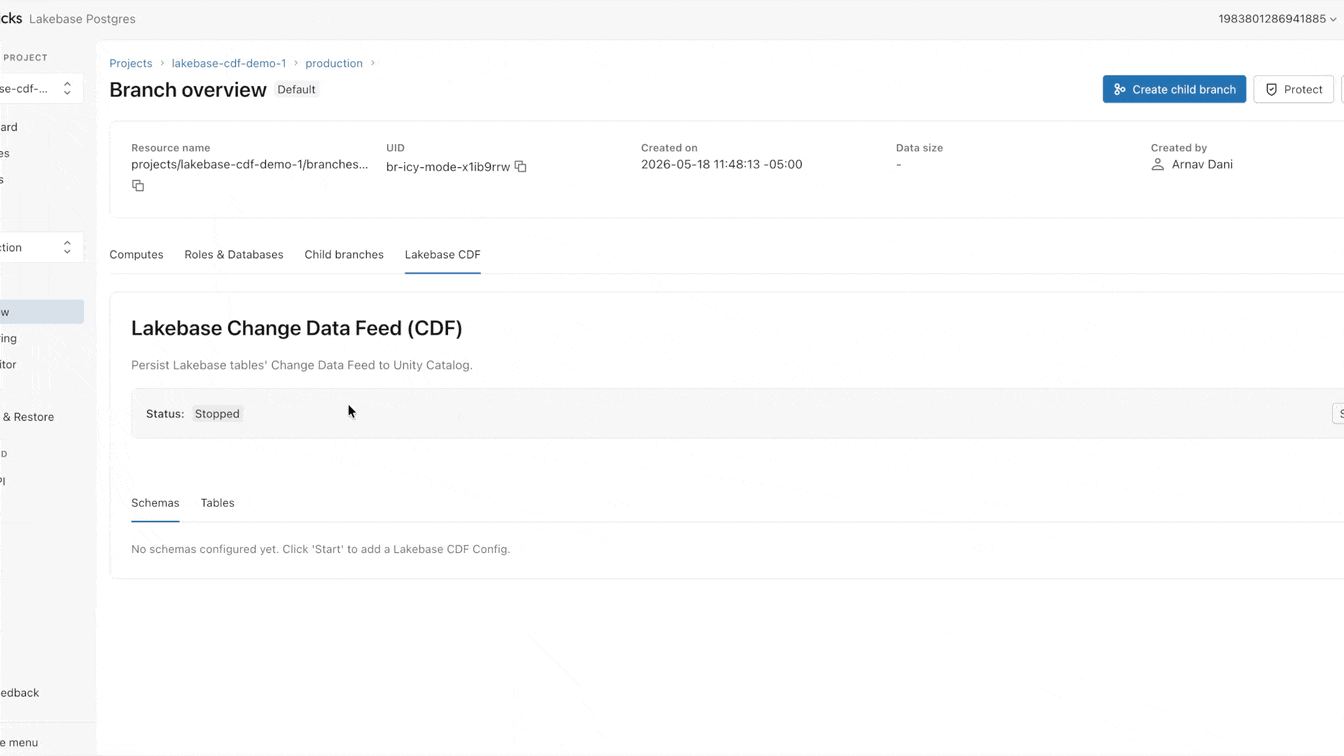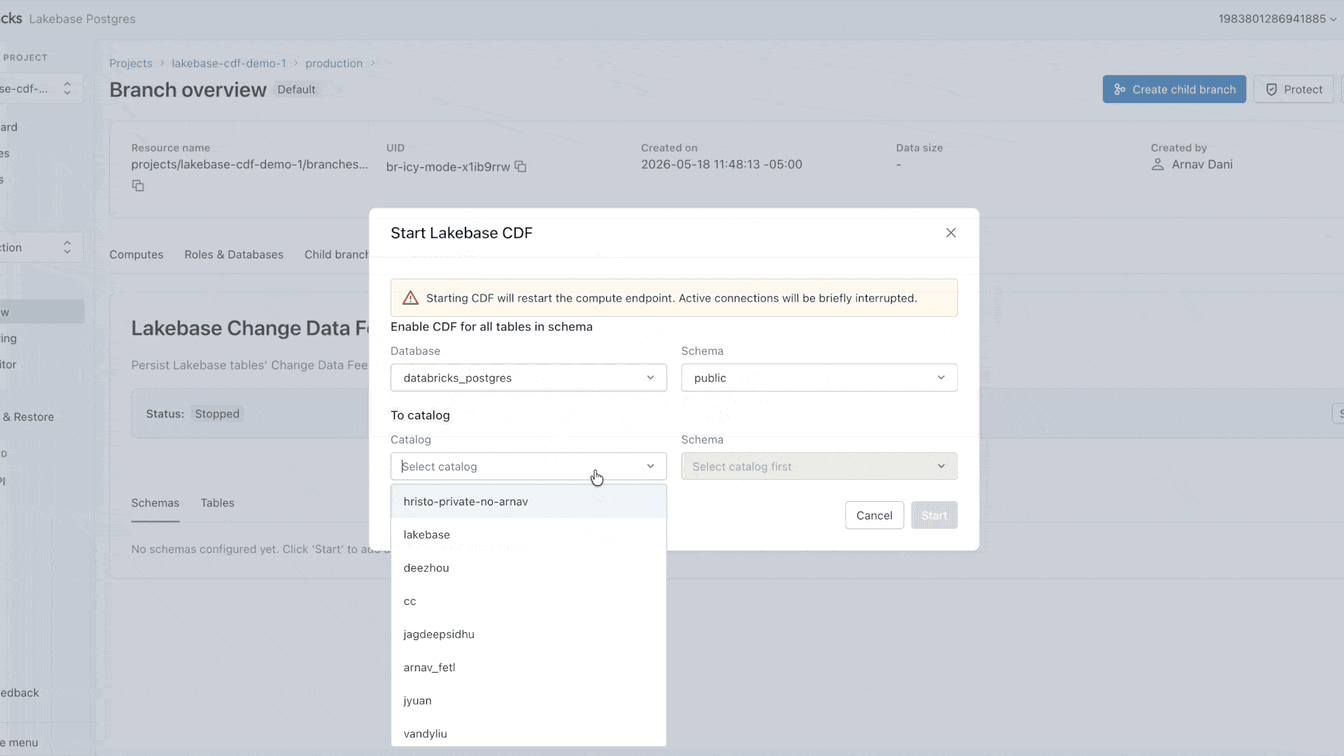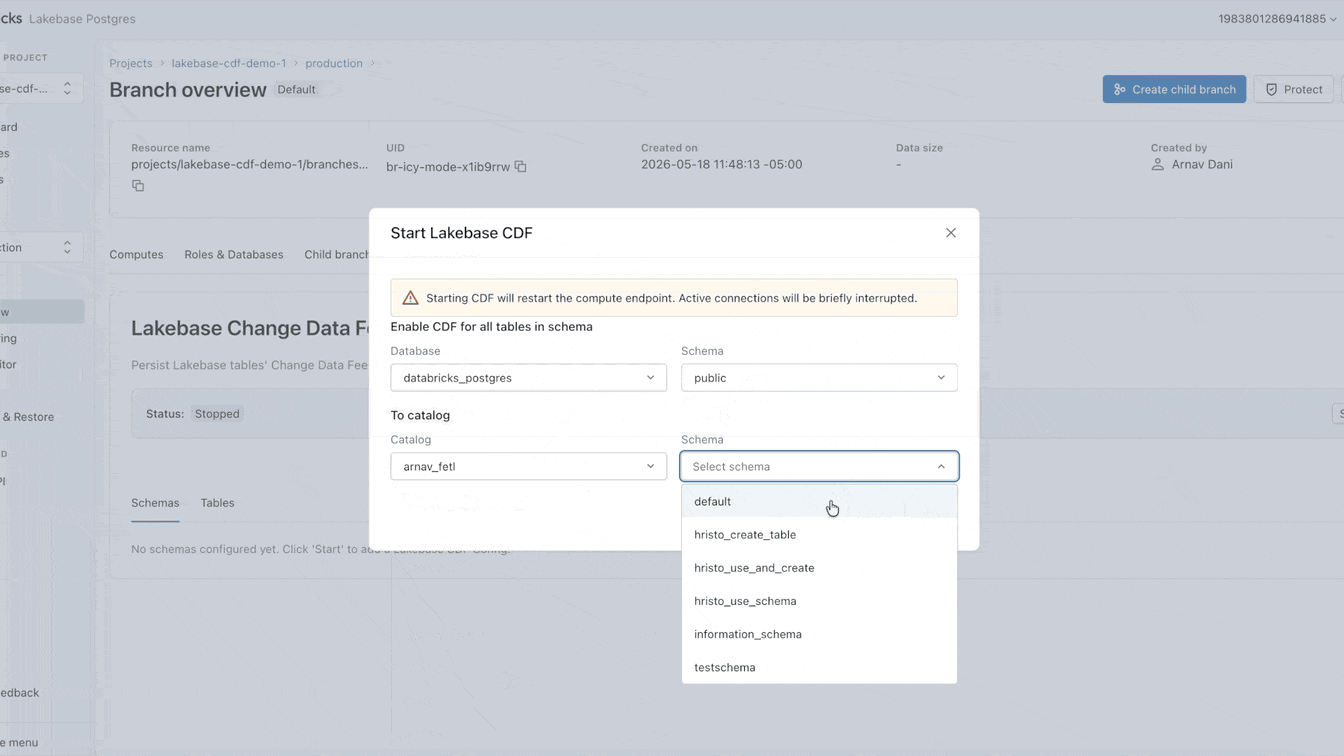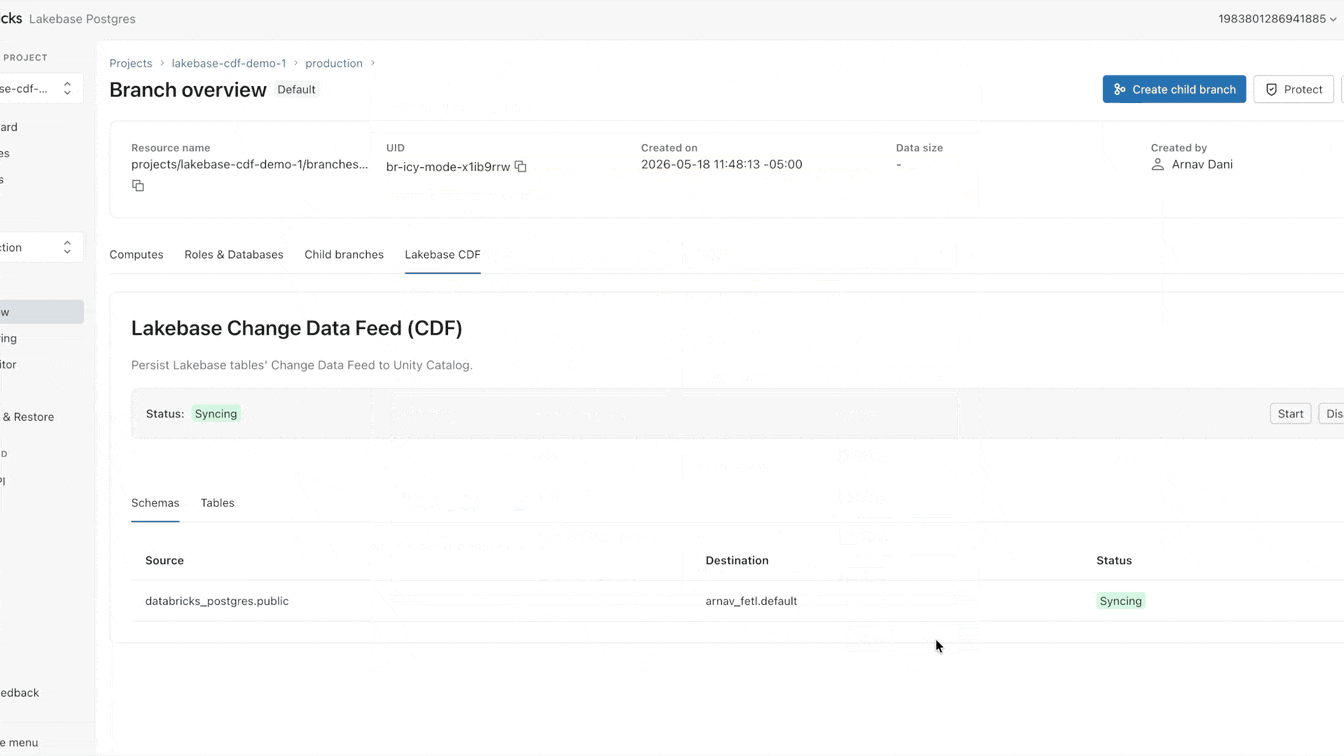
Heute ändern wir diesen Ansatz. Ab sofort in der Public Preview verfügbar, bietet Lakebase einen Change Data Feed (CDF), der in Unity Catalog Managed Tables gespeichert und verwaltet wird. Aktivieren Sie den Feed einmal und lassen Sie alle Engines, Modelle und Agenten direkt darauf zugreifen.
Warum ist das Landen operativer Daten in den Lake immer noch so schwierig?
Während Lakeflow Connect die Aufnahme von Daten in das Lakehouse trivial gemacht hat, bleibt das Abrufen von Daten aus der OLTP-Datenbank ein manueller und reibungsintensiver Prozess. Das Extrahieren von Change Data Capture (CDC) zwingt Teams, Datenbank-Konnektoren zu konfigurieren, Replikationszustände zu überwachen, Auswirkungen auf die Leistung zu mildern und Fehler über getrennte Tools hinweg zu verfolgen. Dieses Modell bricht bei der agentenbasierten Entwicklung zusammen, die auf schnelles Daten-Branching angewiesen ist. Die Wartung komplexer, ungeregelter Extraktionspipelines für jeden neuen Branch zu jedem Ziel ist nicht nachhaltig.
Wir haben das im Lakehouse gelöst. Jetzt bringen wir es zu Lakebase.
Das Lakehouse eliminierte Extraktionspipelines für Analysen, indem Daten einmal in offenen Formaten (Apache Iceberg™, Delta Lake) gespeichert wurden. Es etablierte den Change Data Feed (CDF) als Standard für die nachgelagerte Replikation und ermöglichte ETL-, Streaming-Workflows und Audit-Protokolle.
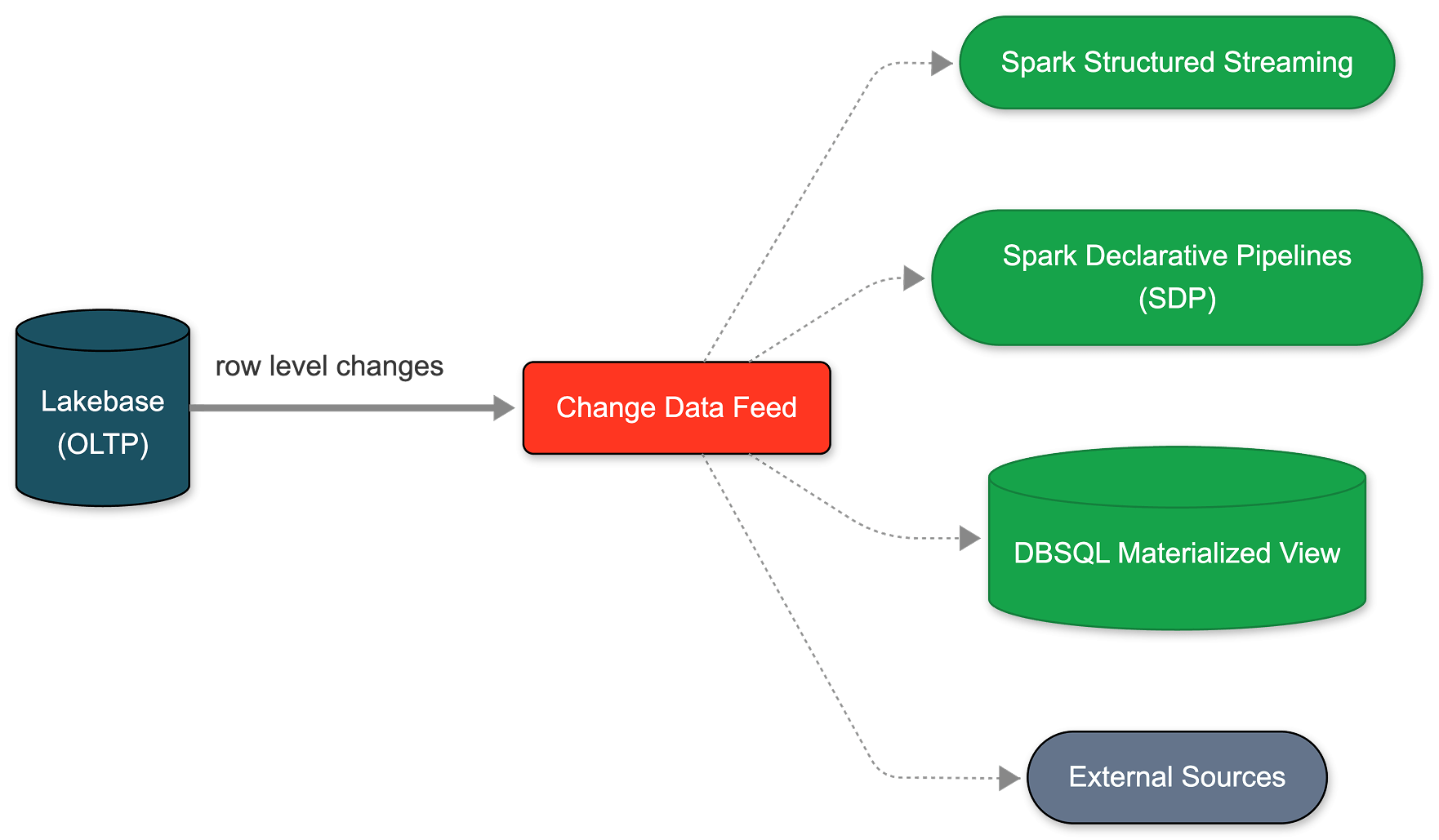
Sie können diesen CDF jetzt nativ auf Lakebase einrichten. Die Aktivierung dauert weniger als eine Minute und gilt für alle Tabellen innerhalb eines Projekts. Von diesem einzigen Feed aus können Sie Streaming-Pipelines mit SDP erstellen, materialisierte Ansichten mit DBSQL generieren oder Embeddings mit Agent Bricks berechnen und speichern. Jeder nachgelagerte Consumer abonniert exakt denselben Feed, vollständig isoliert von Ihrer primären operativen Arbeitslast.
Operative Datenbanken gehören in die Medaillon-Architektur
Mit Lakebase sind Ihre operativen Daten nicht mehr vom Lakehouse isoliert. Lakebase bietet bereits Synced Tables, die das Muster der direkten Bereitstellung von Gold-Datensätzen für Anwendungen etablieren. Lakebase CDF vervollständigt die Architektur. Ihre operative Datenbank ist nun Ihre native Bronze-Schicht, die die Notwendigkeit separater Pipelines oder Extraktionsjobs zur Landung von Daten im Lakehouse eliminiert. Stattdessen erhalten Sie vollständige Governance und Lineage über den gesamten Datenlebenszyklus durch Unity Catalog.
Dies ist erst der Anfang. Wir bringen die Offenheit, die Sie vom Lakehouse lieben, direkt zu Lakebase. Bleiben Sie dran für den Data and AI Summit und nehmen Sie an unserer Breakout-Session über diese Architektur teil.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.