Aufbau eines semantischen Lakehouse mit AtScale und Databricks
Erfahren Sie, wie eine universelle semantische Schicht Ihr Databricks Lakehouse demokratisieren und Self-Service-BI ermöglichen kann
von Kieran O’Driscoll, Kyle Hale und Soham Bhatt
Dies ist ein gemeinsamer Beitrag von AtScale und Databricks. Wir danken Kieran O'Driscoll, Technology Alliances Manager, AtScale, für seine Beiträge.
Kyle Hale, Solution Architect bei Databricks, prägte vor einigen Monaten den Begriff "Semantic Lakehouse" in seinem Blog. Es ist ein guter Überblick über das Potenzial zur Vereinfachung des BI-Stacks und zur Nutzung der Leistung des Lakehouse. Da AtScale und Databricks immer mehr zusammenarbeiten, um unsere gemeinsamen Kunden zu unterstützen, hat sich das Potenzial zur Nutzung der semantischen Layer-Plattform von AtScale mit Databricks zur schnellen Erstellung eines Semantic Lakehouse herausgebildet. Ein Semantic Lakehouse bietet eine Abstraktionsschicht über den physischen Tabellen und eine geschäftsfreundliche Sicht auf den Datenkonsum, indem die Daten nach verschiedenen Themenbereichen definiert und organisiert werden und die Entitäten, Attribute und Joins definiert werden. All dies vereinfacht den Datenkonsum für Business Analysten und Endbenutzer.
Die meisten Unternehmen kämpfen immer noch mit der Demokratisierung von Daten
Daten für Entscheidungsträger verfügbar zu machen, ist eine Herausforderung, vor der die meisten Organisationen heute stehen. Je größer die Organisation, desto schwieriger wird es, einen einheitlichen Standard für den Konsum und die Aufbereitung von Analysen durchzusetzen. Über die Hälfte der Unternehmen berichtet, dass sie drei oder mehr BI-Tools verwenden, wobei über ein Drittel vier oder mehr verwendet. Zusätzlich zu den BI-Nutzern haben Data Scientists ihre eigenen Präferenzen, ebenso wie Anwendungsentwickler.
Diese Tools arbeiten auf unterschiedliche Weise und sprechen unterschiedliche Abfragesprachen. Konfliktierende Analyseergebnisse sind fast garantiert, wenn mehrere Geschäftsbereiche Entscheidungen treffen, indem sie auf verschiedene isolierte Datenkopien oder herkömmliche OLAP-Cubing-Lösungen wie Tableau Hyper Extracts, Power BI Premium Imports oder Microsoft SQL Server Analysis Services (SSAS) für Excel-Benutzer zurückgreifen.
Die Speicherung von Daten in verschiedenen Data Marts und Data Warehouses, Extrakte in verschiedenen Datenbanken und extern zwischengespeicherte Daten in Reporting-Tools ergeben keine einheitliche Wahrheit für das Unternehmen und erhöhen Datenbewegungen, ETL, Sicherheit und Komplexität. Es wird zu einem Albtraum für die Data Governance und bedeutet auch, dass die Organisationen ihre Geschäfte auf potenziell veralteten Daten aus verschiedenen Datensilos in den BI-Schichten betreiben und nicht die volle Leistung des Databricks Lakehouse nutzen.
Die Notwendigkeit einer universellen semantischen Schicht
Die AtScale Semantic Layer sitzt zwischen all Ihren Analyse-Konsum-Tools und Ihrem Databricks Lakehouse. Durch die Abstraktion der physischen Form und des Speicherorts von Daten macht die semantische Schicht die in Delta Lake gespeicherten Daten analysebereit und für die Tools der Business-Benutzer leicht konsumierbar. Konsum-Tools können sich über eines der folgenden Protokolle mit AtScale verbinden:
- Für SQL erscheint die AtScale-Engine als Hive SQL Warehouse.
- Für MDX oder DAX erscheint AtScale als SQL Server Analysis Services (SSAS) Cube.
- Für REST- oder Python-Anwendungen erscheint AtScale als Web-Service.
Anstatt Daten lokal zu verarbeiten, leitet AtScale eingehende Abfragen als optimiertes SQL an Databricks weiter. Das bedeutet, dass die Abfragen der Benutzer direkt gegen Delta Lake ausgeführt werden, wobei Databricks SQL für Rechenleistung, Skalierbarkeit und Performance genutzt wird.
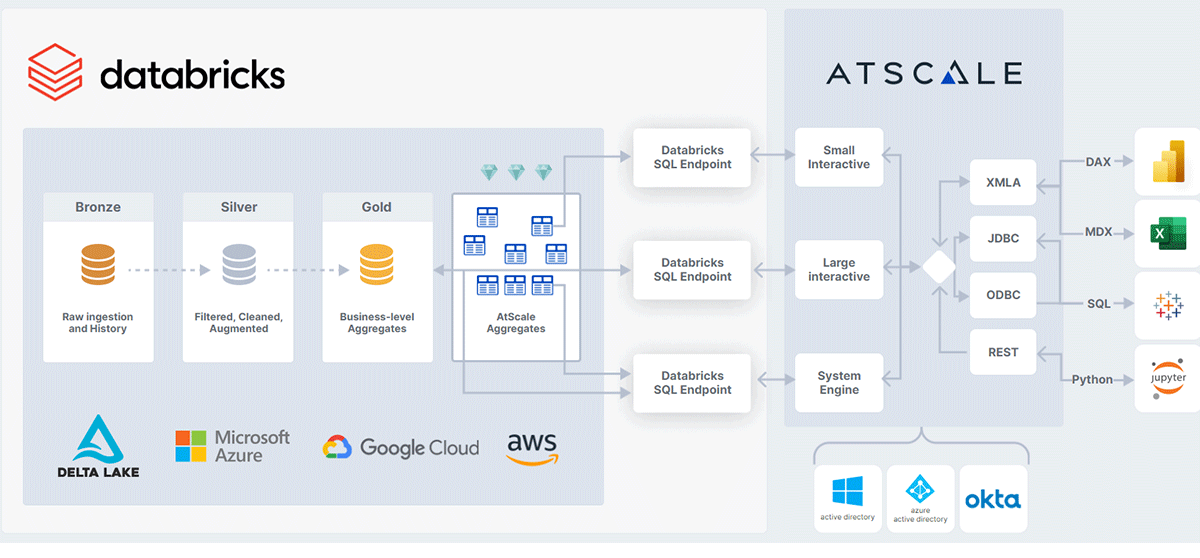
Der zusätzliche Vorteil der Verwendung einer Universal Semantic Layer ist, dass die autonome Performance-Optimierungstechnologie von AtScale Benutzerabfragemuster erkennt, um die Erstellung und Wartung von Aggregaten automatisch zu orchestrieren, genau wie es das Data Engineering-Team tun würde. Jetzt muss niemand mehr Entwicklungszeit und -aufwand für die Erstellung und Wartung dieser Aggregate aufwenden, da sie von AtScale für optimale Leistung automatisch erstellt und verwaltet werden. Diese Aggregate werden in Delta Lake als physische Delta-Tabellen erstellt und können als "Diamond Layer" betrachtet werden. Diese Aggregate werden vollständig von AtScale verwaltet und verbessern die Skalierbarkeit und Leistung Ihrer BI-Berichte auf dem Databricks Lakehouse, während sie gleichzeitig die Analyse-Datenpipelines und das zugehörige Data Engineering radikal vereinfachen.
Erstellung eines Tool-agnostischen Semantic Lakehouse
Die Vision der Databricks Lakehouse Platform ist eine einzige, einheitliche Plattform zur Unterstützung all Ihrer Daten-, Analyse- und KI-Workloads. Kyles Beschreibung des "Semantic Lakehouse" ist ein gutes Modell für einen vereinfachten BI-Stack.
AtScale erweitert diese Idee eines Semantic Lakehouse, indem es BI-Workloads und KI/ML-Anwendungsfälle über unsere Tool-agnostische Semantic Layer unterstützt. Die Kombination von AtScale und Databricks bedeutet, dass die Semantic Lakehouse-Architektur auf jede Präsentationsschicht erweitert wird – egal ob Tableau, Power BI, Excel oder Looker. Sie alle können dieselbe semantische Schicht in AtScale nutzen.

Mit dem Aufkommen des Lakehouse arbeiten die BI- und KI/ML-Teams von Organisationen nicht mehr isoliert. Die Universal Semantic Layer von AtScale hilft Organisationen, konsistenten Zugriff auf all ihre Unternehmensdaten zu erhalten, unabhängig davon, ob es sich um einen Business-Benutzer in Excel oder einen Data Scientist handelt, der ein Notebook verwendet, und nutzt dabei die volle Leistung ihrer Databricks Lakehouse Platform.
Zusätzliche Ressourcen
Sehen Sie sich unsere Podiumsdiskussion an mit Franco Patano, Lead Product Specialist bei Databricks, um weitere Informationen zu erhalten und zu erfahren, wie diese Tools Ihnen helfen können, eine agile, skalierbare Analyseplattform zu erstellen.
Wenn Sie Fragen zu AtScale oder zur Modernisierung und Migration Ihres Legacy EDW-, BI- und Reporting-Stacks zu Databricks und AtScale haben, wenden Sie sich gerne an kieran.odriscoll@atscale.com oder kontaktieren Sie Databricks.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.