Databricks Lakehouse und Data Mesh, Teil 1
von Sharon Richardson, Bernhard Walter, Pawarit Laosunthara, Guillermo Schiava D'Albano, Fran Medina Castro und Amr Ali
Dies ist der erste Blogbeitrag einer zweiteiligen Serie. In diesem Beitrag stellen wir das Data-Mesh-Konzept und die Databricks-Funktionen vor, die zur Implementierung eines Data Mesh verfügbar sind. Der zweite Blogbeitrag untersucht verschiedene Data-Mesh-Optionen und liefert Details zur Implementierung eines Data Mesh, das auf dem Databricks Lakehouse basiert.
Data Mesh ist ein Paradigma, das eine Reihe von Prinzipien und eine logische Architektur zur Skalierung von Datenanalyseplattformen beschreibt. Ziel ist es, mehr Wert aus Daten als Vermögenswert in großem Maßstab zu ziehen. Der Begriff „Data Mesh“ wurde 2019 von Zhamak Dehghani eingeführt und in ihrem Artikel von 2020 Data Mesh Principles and Logical Architecture weiter ausgeführt.
Im Kern der logischen Architektur des Data Mesh stehen vier Prinzipien:
- Domain Ownership: Übernahme einer verteilten Architektur, bei der Domänenteams – Datenerzeuger – die volle Verantwortung für ihre Daten während ihres gesamten Lebenszyklus behalten, von der Erfassung über die Kuratierung bis hin zur Analyse und Wiederverwendung
- Data as a Product: Anwendung von Produktmanagementprinzipien auf den Datenanalyse-Lebenszyklus, um sicherzustellen, dass qualitativ hochwertige Daten an Datenkonsumenten geliefert werden, die sich innerhalb und außerhalb der Domäne des Erzeugers befinden können
- Self-Service-Infrastrukturplattform: Verfolgung eines domänenunabhängigen Ansatzes für den Datenanalyse-Lebenszyklus unter Verwendung gemeinsamer Tools und Methoden zum Erstellen, Ausführen und Warten interoperabler Datenprodukte
- Federated Governance: Sicherstellung eines Datenökosystems, das durch Standardisierung die Organisationsregeln und Branchenvorschriften einhält
Datenprodukte sind ein wichtiges Konzept für das Data Mesh. Sie sollen nicht nur Datensätze sein, sondern Daten, die wie ein Produkt behandelt werden: Sie müssen auffindbar, vertrauenswürdig, selbsterklärend, adressierbar und interoperabel sein. Neben Daten und Metadaten können sie Code, Dashboards, Features, Modelle und andere Ressourcen enthalten, die zur Erstellung und Wartung des Datenprodukts erforderlich sind.
Viele Kunden fragen: „Können wir mit Databricks Lakehouse ein Data Mesh erstellen?“ Die Antwort lautet ja! Mehrere der größten Kunden von Databricks weltweit haben Data Mesh unter Verwendung des Lakehouse als technologische Grundlage übernommen.
Databricks Lakehouse ist eine Cloud-native Daten-, Analyse- und KI-Plattform, die die Leistung und Funktionen eines Data Warehouse mit der kostengünstigen, flexiblen und skalierbaren Natur eines modernen Data Lake kombiniert. Für eine Einführung lesen Sie bitte Was ist ein Lakehouse?
Das Lakehouse adressiert ein grundlegendes Problem von Data Lakes, das zu den Prinzipien eines Data Mesh geführt hat – dass ein monolithischer Data Lake zu einem unüberschaubaren Data Swamp werden kann. Das Databricks Lakehouse ist eine offene Architektur, die Flexibilität bei der Organisation und Strukturierung von Daten bietet und gleichzeitig eine einheitliche Managementinfrastruktur für alle Daten- und Analyse-Workloads bereitstellt.
Die primäre Organisationseinheit innerhalb der Databricks Lakehouse-Plattform, die dem Konzept von Domänen in einem Data Mesh entspricht, ist der „Workspace“. Ein Databricks Lakehouse kann einen oder mehrere Workspaces haben, wobei jeder Workspace die lokale Datenverantwortung und Zugriffskontrolle ermöglicht.
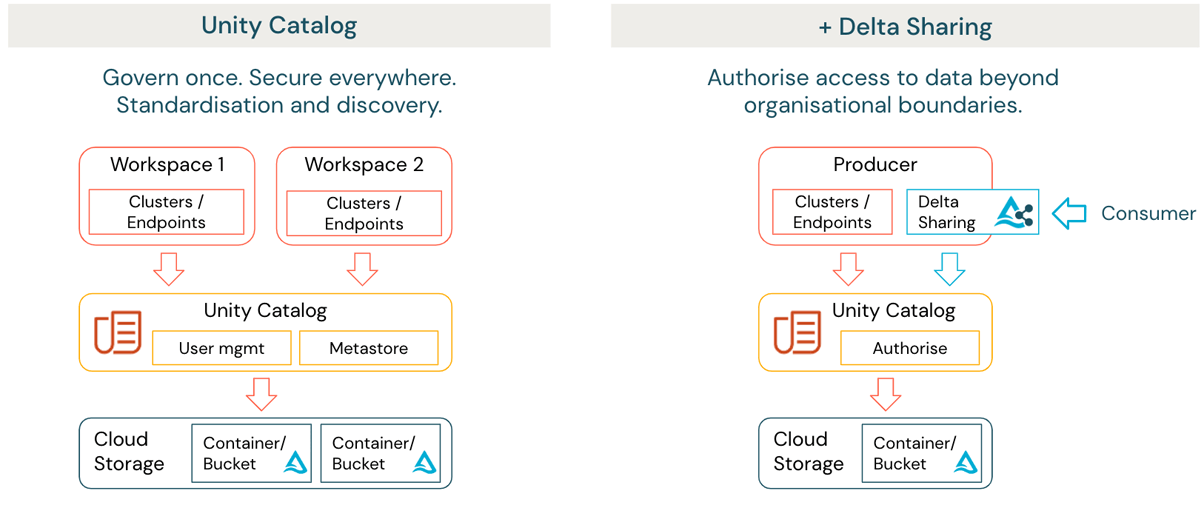
{kind=link}
Jeder Workspace kapselt eine oder mehrere Domänen, dient als Zentrum für die Zusammenarbeit und ermöglicht es der/den Domäne(n), ihre Datenprodukte mithilfe einer gemeinsamen, selbstbedienten, domänenunabhängigen Infrastruktur zu verwalten. Dies kann die Automatisierung bei der Bereitstellung der Umgebung und die Orchestrierung von Datenpipelines mithilfe integrierter Dienste wie Databricks Workflows sowie die Bereitstellungsautomatisierung mithilfe des Databricks Terraform Providers umfassen. Unity Catalog bietet föderierte Governance, Discovery und Lineage als zentralisierten Dienst auf Kontoebene der Organisation, die Databricks ausführt. (Abbildung 1 linke Seite).
Für viele Organisationen ist es notwendig zu überlegen, wie Daten sicher mit externen Parteien über eine Governance-Grenze hinweg geteilt werden können. Dies kann auch für interne Domänen gelten, die auf verschiedenen Cloud-Anbietern und Regionen gehostet werden. Databricks Lakehouse bietet hierfür eine Lösung in Form von Delta Sharing (Abbildung 1 rechte Seite). Delta Sharing ermöglicht es Organisationen, Daten sicher mit externen Parteien zu teilen, unabhängig von der Computing-Plattform. Die Daten müssen nicht dupliziert werden, und der Zugriff wird automatisch auditiert und protokolliert.
Delta Sharing bildet auch die Grundlage für eine breitere Palette externer Datenfreigabeaktivitäten. Dazu gehören die Veröffentlichung oder der Erwerb von Daten über einen Marktplatz wie den Databricks Marketplace sowie die sichere Zusammenarbeit an Daten über organisatorische und technische Grenzen hinweg, ermöglicht innerhalb der Databricks-Plattform als Databricks Clean Rooms.
Die Kombination aus Unity Catalog und Delta Sharing bedeutet, dass die Databricks Lakehouse-Plattform Flexibilität bietet, wie eine Organisation Daten und Analysen in großem Maßstab organisieren und verwalten möchte, einschließlich Bereitstellungen, die mehrere Cloud-Anbieter, verschiedene geografische Regionen umfassen, und Bereitstellungen, die die Möglichkeit erfordern, Datenbestände mit externen Entitäten zu teilen. Mit Databricks Lakehouse können Daten in einem Data Mesh organisiert werden, aber auch mit jeder geeigneten Architektur, von vollständig zentralisiert bis vollständig verteilt.
Der zweite Teil dieses Blogbeitrags wird verschiedene Data-Mesh-Optionen untersuchen und Details zur Implementierung eines Data Mesh auf Basis des Databricks Lakehouse liefern.
Um mehr über die in diesem Beitrag erwähnten Funktionen des Databricks Lakehouse zu erfahren:
- Was ist ein Lakehouse
- Was ist das Databricks Lakehouse
- Einführung in Databricks Unity Catalog
- Einführung in Databricks Delta Sharing
- Einführung in Databricks Clean Rooms
- Einführung in Databricks Marketplace
- Databricks Terraform Provider
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.