Databricks arbeitet mit OpenAI an GPT-5.5 zusammen
GPT-5.5 erzielt Spitzenleistungen im Databricks OfficeQA-Benchmark
von Hanlin Tang, Ahmed Bilal, Arnav Singhvi, Ivan Zhou und Harish Gaur
- Databricks arbeitet mit OpenAI an GPT-5.5 zusammen
- GPT-5.5 reduziert Fehler im OfficeQA Pro um fast die Hälfte
- OpenAI GPT-5.5 und Codex sind bald auf Databricks verfügbar und werden über das Unity AI Gateway gesteuert
Databricks freut sich über die Partnerschaft mit OpenAI an GPT-5.5, ihrem neuesten Frontier-Modell. GPT-5.5 ist das leistungsstärkste Frontier-Modell von OpenAI für agentenbasierte Aufgaben im Unternehmen, die Analyse komplexer Dokumente und Coding-Agenten mit langer Ausführungszeit. GPT-5.5 treibt auch Codex, den Coding-Agenten von OpenAI, an.
GPT-5.5 Funktionen und Vorteile
GPT-5.5 ist das bisher intelligenteste Frontier-Modell und der nächste Schritt hin zu einer neuen Art, Arbeit zu erledigen. Es versteht schneller, was Sie tun möchten, und kann mehr Arbeit selbst übernehmen. Codex, der Coding-Agent von OpenAI, wird jetzt von GPT-5.5 angetrieben und bietet verbesserte Reasoning- und Ausführungsfähigkeiten für Entwickler-Workflows.
Die gleichen Stärken, die GPT-5.5 beim Codieren auszeichnen, machen es auch für alltägliche Computerarbeiten leistungsstark. Da das Modell die Absicht besser versteht, kann es sich natürlicher durch den gesamten Zyklus der Wissensarbeit bewegen: Informationen finden, Wichtiges verstehen, Tools nutzen, die Ergebnisse überprüfen und Rohmaterial in etwas Nützliches verwandeln.
Es kann Code schreiben und debuggen, online recherchieren, Daten analysieren, Dokumente und Tabellenkalkulationen erstellen, Software bedienen und über Tools hinweg arbeiten, bis eine Aufgabe abgeschlossen ist. Anstatt jeden Schritt sorgfältig zu verwalten, können Sie GPT-5.5 eine unordentliche, mehrteilige Aufgabe geben und darauf vertrauen, dass es plant, Tools verwendet, seine Arbeit überprüft, mit Mehrdeutigkeiten umgeht und weitermacht.
GPT-5.5 erzielt Spitzenleistungen
Um zu verstehen, wie sich diese Verbesserungen auf reale Unternehmens-Workloads auswirken, haben wir GPT-5.5 auf OfficeQA evaluiert, dem Benchmark von Databricks für dokumentenintensive, mehrstufige analytische Aufgaben, die Kunden täglich ausf�ühren. OfficeQA, das aus 89.000 Seiten von U.S. Treasury Bulletins besteht, misst die Fähigkeit eines Modells, Informationen über Dokumente hinweg abzurufen, komplexe Tabellen zu interpretieren und präzise Berechnungen durchzuführen, die auf realen Unternehmensdaten basieren.
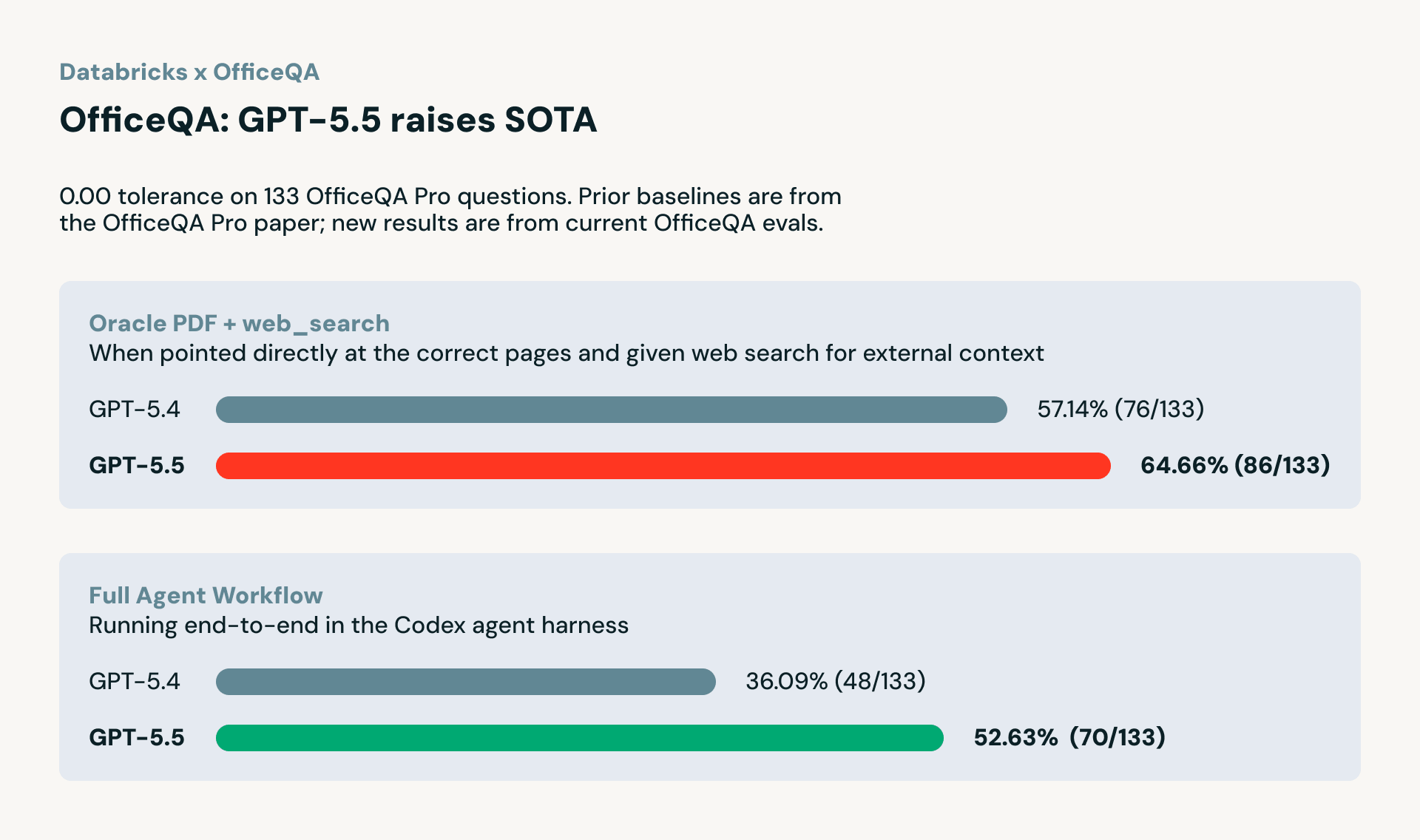
Wenn die richtigen Dokumente bereitgestellt werden (OfficeQA Pro LLM mit Oracle PDF + Web Search), erzielte GPT-5.5 64,66 %, ein deutlicher Sprung von den 57,14 % von GPT-5.4, was einer Verbesserung von ~13 % und einem neuen Spitzenwert in diesem Benchmark entspricht. Dies testet die Grenzen dessen, was das Modell tun kann, wenn die Abfrage bereits abgeschlossen ist.
In einer vollständigen Agenten-Workflow-Evaluierung (OfficeQA Pro Agent Harness), bei der das Modell die richtigen Dokumente finden, parsen und Antworten selbst berechnen muss, indem es das Codex-Agenten-Harness verwendet, erzielte GPT-5.5 52,63 %, gegenüber 36,10 % bei GPT-5.4. Das ist eine Reduzierung der Fehler um 46 %, was zeigt, dass die Fortschritte von GPT-5.5 nicht nur theoretisch sind; sie bewähren sich in realistischen, End-to-End-Unternehmens-Workflows.
GPT-5.5 ist bald auf Databricks verfügbar. Nutzen Sie Frontier Reasoning sicher und in großem Maßstab für Ihre Unternehmensdaten.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.