Bereitstellung generativer Marketinginhalte für Kunden
Kombination von Kundendaten und Generative AI, um Kunden besser zu erreichen, Teil 2
von Camden Clark, Joyce Gordon, Ally Hepp, Alex Rees, Tristen Wentling und Bryan Smith
- Skalierbare Personalisierung: Generative AI automatisiert die Erstellung maßgeschneiderter Marketinginhalte mithilfe von Kundendaten aus Databricks und Amperity.
- Nahtlose Integration: Amperity synchronisiert Zielgruppendaten mit Braze und ermöglicht so eine präzise Bereitstellung von Inhalten über Cloud Data Ingestion.
- Dynamische E-Mail-Zustellung: Liquid-Templating in Braze personalisiert E-Mail-Betreffzeilen und -Inhalte, was das Engagement und die Conversions steigert.

Marketing-Verantwortliche träumen schon lange von einer personalisierten Kundenansprache im Eins-zu-eins-Format. Doch die Erstellung der enormen Menge an Nachrichten, die für eine personalisierte Interaktion auf diesem Niveau erforderlich ist, war bisher eine große Herausforderung. Viele Unternehmen streben zwar ein personalisierteres Marketing an, richten sich aber oft an große Gruppen von Tausenden oder Millionen von Kunden, in denen immer noch eine enorme Vielfalt herrscht. Das ist zwar besser als ein allgemeiner Einheitsansatz, aber Unternehmen würden gerne präziser vorgehen – wenn sie nur die Kapazitäten hätten, auf einer granulareren Ebene zu interagieren.
Wie in unserem vorherigen Blogbeitrag erwähnt, kann generative AI dazu beitragen, die Erstellung hochgradig maßgeschneiderter Marketinginhalte zu erleichtern. Auch wenn eine echte Eins-zu-eins-Ansprache aufgrund einiger Einschränkungen der Technologie im heutigen Zustand noch schwierig sein mag, lassen sich durch die Kombination von Kundendetails mit Beispielinhalten und cleverem Prompt Engineering kostengünstig eine überschaubare Anzahl maßgeschneiderter Varianten erstellen. Der Einsatz unabhängiger Modelle zur Bewertung der generierten Inhalte, bevor diese einer abschließenden Prüfung durch Marketing-Experten unterzogen werden, trägt entscheidend dazu bei, dass diese feingranularen Inhalte den Unternehmensstandards entsprechen und gleichzeitig präziser auf die Bedürfnisse und Vorlieben eines bestimmten Teilsegments abgestimmt sind.
Aber wie machen wir daraus einen zuverlässigen Workflow? Und vor allem: Wie bringen wir all diese Inhaltsvarianten mit unseren bestehenden Marketingtechnologien tatsächlich an die gewünschten Kunden? In diesem Beitrag bauen wir auf dem im vorherigen Blog vorgestellten Szenario für einen Feiertags-Geschenkführer auf und zeigen einen End-to-End-Workflow für die E-Mail-basierte Bereitstellung von Inhalten mit Amperity und Braze, zwei weit verbreiteten Plattformen im Enterprise-MarTech-Stack.
Inhalte generieren
In unserem vorherigen Blogbeitrag haben wir uns damit befasst, wie man einen Prompt erstellt, der ein generatives AI-Modell dazu veranlasst, eine Marketing-E-Mail zu erstellen, die auf die Interessen eines bestimmten Zielgruppensegments zugeschnitten ist. Der Prompt nutzte eine Beispiel-E-Mail als Orientierung und beauftragte das Modell dann damit, den Inhalt so anzupassen, dass er eine Zielgruppe mit bestimmten Preissensibilitäten und Aktivitätspräferenzen besser anspricht (Abbildung 1).
Abbildung 1. Der für die Erstellung eines personalisierten Feiertags-Geschenkführers entwickelte Prompt
Um diesen Prompt in großem Maßstab anzuwenden, müssen wir kundenspezifische Elemente (wie in diesem Beispiel die Produktunterkategorie und die Preispräferenzen) entfernen und Platzhalter einfügen, an denen diese Elemente bei Bedarf eingefügt werden können, um eine Prompt-Vorlage zu erstellen. Kundenspezifische Details können dann in den als Vorlage dienenden Prompt (der in der Databricks-Umgebung gehostet wird) eingefügt werden, wobei die Kundendetails in der Customer Data Platform (CDP) gespeichert sind.
Da wir Amperity für unsere Demo-CDP verwenden, ist die Integration ein recht einfacher Prozess. Mithilfe der Funktion Amperity Bridge, die auf dem von der Databricks-Umgebung unterstützten Open-Source-Protokoll Delta Sharing basiert, stellen wir einfach eine Verbindung zwischen den beiden Plattformen her und geben die entsprechenden Informationen frei (Abbildung 2). (Die detaillierten Schritte zur Einrichtung der Bridge-Verbindung finden Sie hier.)
Abbildung 2. Eine Video-Anleitung zur Verbindung mit Databricks über die Amperity Bridge
Unser nächster Schritt besteht darin, die in der CDP gespeicherten Daten abzufragen, auf die wir in Databricks zugreifen können, um Details für jedes Teilsegment zu erfassen. Sobald diese definiert sind, können wir die jeweils zugehörigen Informationen an unseren Prompt übergeben, um maßgeschneiderte Nachrichten zu generieren. Sobald diese gespeichert sind, können wir die Ausgabe iterieren und jede generierte Nachricht anhand verschiedener Kriterien bewerten, bevor diese Inhalte und die Bewertungsergebnisse einem Marketing-Verantwortlichen zur endgültigen Prüfung und Freigabe vorgelegt werden (Abbildung 3).
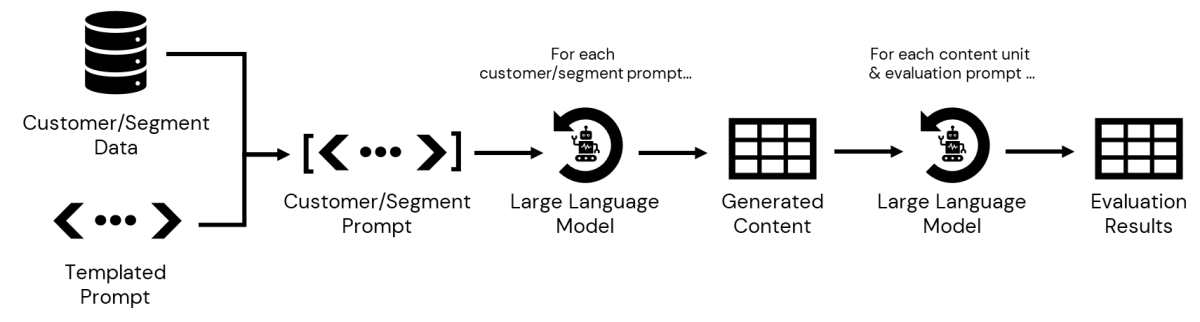
{kind=link}
Das Endergebnis dieses Prozesses ist eine Tabelle mit Inhaltsvarianten – eine für jede Kombination aus bevorzugter Preisklasse und Produktunterkategorie – sowie eine Tabelle mit Bewertungsergebnissen für jeden Bewertungsschritt. Die Daten sind nun bereit für die Überprüfung durch das Marketing.
HINWEIS: Eine detaillierte, technische Implementierung des Workflows in Abbildung 3 finden Sie in diesem Notebook.
Inhalte bereitstellen
Nachdem unsere Inhaltsvarianten erstellt wurden, können wir uns der Bereitstellung widmen. Die genauen Details für diesen Schritt hängen von der von Ihnen verwendeten Bereitstellungsplattform ab. In unserer Demonstration sehen wir uns an, wie diese Inhalte mit Braze bereitgestellt werden können, einer führenden Customer Engagement Platform, die in vielen Marketingorganisationen weit verbreitet ist.
Grob zusammengefasst umfasst die Bereitstellung dieser Inhalte über Braze folgende Schritte:
- Inhaltsvarianten an Braze übertragen
- Zielgruppenmitglieder identifizieren, die die Inhalte erhalten sollen
- Zielgruppenmitglieder mit bestimmten Inhaltsvarianten verknüpfen
Inhaltsvarianten an Braze übertragen
In Braze werden die im Rahmen einer Kampagne verwendeten Inhalte als Braze Catalog definiert. Mithilfe von Braze Cloud Data Ingestion können diese Inhalte aus Databricks ausgelesen werden, sofern sie in einer Tabelle oder Ansicht bereitgestellt werden, die eine eindeutige Kennung (ID), ein Datums-/Uhrzeitfeld für die letzte Aktualisierung des Inhalts (UPDATED_AT) und ein JSON-Payload (PAYLOAD) mit Title- und Body-Elementen enthält, die zur Erstellung des bereitgestellten Inhalts verwendet werden.
Um zu veranschaulichen, wie dieser Datensatz aufgebaut sein könnte, nehmen wir an, dass das Ergebnis unseres Workflows zur Inhaltsgenerierung (wie in Abbildung 4 dargestellt) eine Inhaltstabelle mit der folgenden Struktur liefert, wobei preferred_price_point und holiday_preferred_subcategory die für jeden Datensatz in der Tabelle eindeutigen Teilsegmentdetails darstellen:
Wir können eine View für diese Tabelle definieren, um sie für die Bereitstellung als Braze-Katalog wie folgt zu strukturieren:
In Braze können wir nun einen Katalog für diesen Inhalt definieren (Abbildung 3).
Abbildung 3. Der Braze-Katalog, der unsere generierten Inhalte aufnehmen soll
Anschließend konfigurieren wir eine Cloud Data Ingestion (CDI)-Synchronisierung, die die Databricks-View mit der Braze-Katalogstruktur verbindet, und richten sie für die Synchronisierung ein, um sicherzustellen, dass sie auf dem neuesten Stand bleibt (Abbildung 4).
Abbildung 4. Die Cloud Data Ingestion (CDI)-Synchronisierung, die den Braze-Katalog der Databricks-Inhalts-View zuordnet
Die Zielgruppenmitglieder identifizieren
Wir benötigen nun die Details der Personen, an die wir diese Inhalte senden möchten. Da es unser Ziel ist, diese Inhalte per E-Mail bereitzustellen, benötigen wir die E-Mail-Adressen der Zielpersonen. Elemente wie Vor- und Nachname werden möglicherweise ebenfalls benötigt, um den Empfänger persönlicher ansprechen zu können. Zudem brauchen wir Informationen darüber, wie die Personen den Produktunterkategorien und Preispräferenzen zugeordnet sind. Dieses letzte Element ist entscheidend, um die Zielgruppenmitglieder mit den spezifischen Inhaltsvarianten im Braze-Katalog zu verknüpfen.
Da wir Amperity als unsere CDP verwenden, ist das Übertragen dieser Informationen an Braze ganz einfach: Wir definieren den Empfängerpool als Zielgruppe und nutzen den Amperity-Connector, um diese Details zu übertragen (Abbildung 5).
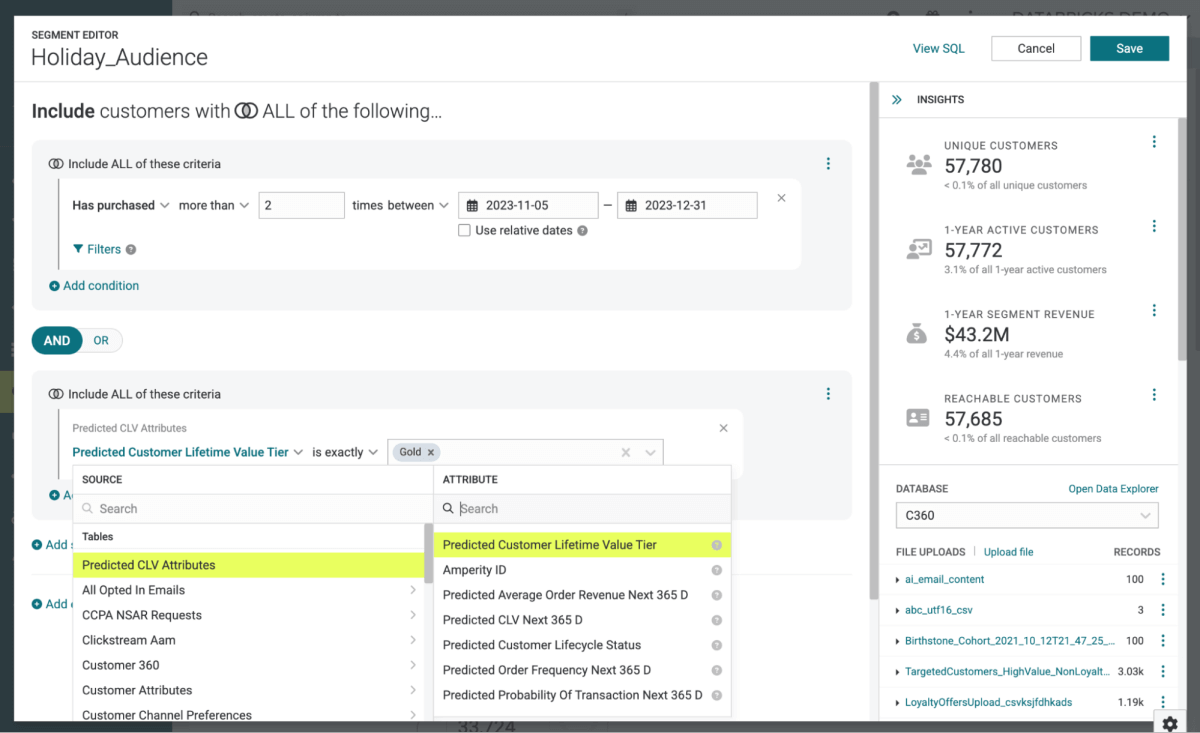
{kind=link}
Zielgruppenmitglieder mit Inhaltsvarianten verknüpfen
Sobald alle Elemente in Braze eingerichtet sind, können wir die Zielgruppenmitglieder mit bestimmten Inhaltsvarianten verknüpfen und den Versand planen. Dies geschieht in Braze mithilfe von Liquid-Templating, einer von Shopify entwickelten Open-Source-Vorlagensprache, die in Ruby geschrieben ist. Diese Sprache ist für Marketingexperten leicht zugänglich und ermöglicht es ihnen, anpassbare Inhalte für die Verteilung in großem Umfang zu definieren.
Erste Schritte
Databricks wird in Unternehmen zunehmend als zentraler Hub für Daten- und Analysefunktionen genutzt. Mit integrierten und hochgradig erweiterbaren Funktionen für generative AI sowie der tiefen Integration in eine Vielzahl komplementärer Plattformen wie der Amperity-CDP und der Braze Customer Engagement Platform erstellen Unternehmen eine breite Palette von Anwendungen – wie die in diesem Blog gezeigte – mit Databricks im Mittelpunkt.
Wenn Sie mehr darüber erfahren möchten, wie Databricks Ihren Marketingteams dabei helfen kann, personalisiertere Inhalte für Ihre Kunden zu erstellen und bereitzustellen, kontaktieren Sie uns. Lassen Sie uns die vielfältigen Möglichkeiten zur Entwicklung von Lösungen auf unserer Plattform besprechen.
Dieser Prozess nutzt mehrere Schlüsselkomponenten und basiert auf dem folgenden Workflow:
- Inhaltsstruktur & -erfassung
- Aus der Tabelle der Inhaltsvarianten wird eine View erstellt, die für die Verwendung durch die Braze Cloud Data Ingestion strukturiert ist
- Ein Braze-Katalog wird als Repository für die Inhaltsvarianten erstellt
- Eine Cloud Data Ingestion-Synchronisierung wird konfiguriert, und Braze synchronisiert die Inhaltsvarianten aus der View in den Katalog
- Amperity-Zielgruppenaktivierung – Amperity synchronisiert die Zielgruppe der Benutzer, für die der Inhalt erstellt wurde, mit Braze für ein präzises Targeting.
- Kampagnenerstellung & Liquid-Templating
- Die Liquid-Vorlagensprache wird verwendet, um auf die entsprechende Zeile im Katalog der Inhaltsvarianten zu verweisen.
- Liquid füllt Betreff und Text der E-Mail dynamisch aus, personalisiert für jeden Benutzer.
Schritt 3: Kampagnenerstellung und Liquid-Templating
Die letzte Phase umfasst die Erstellung der Braze-Kampagne.
Liquid-Templating spielt hier eine entscheidende Rolle, da es das dynamische Einfügen der generierten Inhalte basierend auf den in den Braze-Profilen gespeicherten Benutzerattributen ermöglicht. Auf diese Attribute, die über die Amperity-Aktivierung synchronisiert werden, wird verwiesen, um eine passende Katalogzeilen-ID zu erstellen. Diese ID wird dann verwendet, um die generierte Betreffzeile und den E-Mail-Text abzurufen und in die E-Mail einzufügen.
3a. Email Subject LineUsing Liquid filters, we combine the `preferred_price_point` and `holiday_preferred_subcategory` attributes, separated by an underscore, to create a local `identifier` variable:
Dieser dynamisch generierte `identifier` wird dann verwendet, um auf die entsprechende ID im HolidayGenAI-Katalog zu verweisen:
Abbildung 5. Screenshot der Sendeeinstellungen mit Liquid
Für einen Benutzer mit einem `preferred_price_point` von „high“ und einer `holiday_preferred_subcategory` von „Hiking“ wird die resultierende Liquid-Ausgabe in der Betreffzeile der E-Mail aus dem Titel des passenden Katalogeintrags abgeleitet:
Abbildung 6. Katalogeintrag mit der relevanten Zeile
3b. E-Mail-Text
Wir können denselben Ansatz verwenden, um den generierten Inhalt in den Text der E-Mail zu übernehmen.
Das Endergebnis ist eine E-Mail, die den generierten E-Mail-Inhalt dynamisch abruft, personalisiert auf die bevorzugte Preisklasse und Unterkategorie des jeweiligen Benutzers, was zu einer besseren Interaktion und höheren Konversionsraten führt.
Abbildung 7. E-Mail-Screenshot
Dieser Anwendungsfall könnte noch erweitert werden, um beispielsweise generative Bilder hinzuzufügen oder sogar Connected Content zu nutzen, um einen Databricks-Endpunkt direkt zum Sendezeitpunkt abzufragen.
Eine detaillierte, technische Implementierung des Workflows in Abbildung 3 finden Sie in diesem Notebook.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.