Effizientes Fine-Tuning mit LoRA: Ein Leitfaden zur optimalen Parameterauswahl für große Sprachmodelle
Mit den rasanten Fortschritten bei neuronalen Netzen und der Forschung zu Large Language Models (LLMs) sind Unternehmen zunehmend an KI-Anwendungen zur Wertschöpfung interessiert. Sie setzen verschiedene Machine-Learning-Ansätze ein, sowohl generative als auch nicht-generative, um textbezogene Herausforderungen wie Klassifizierung, Zusammenfassung, Sequenz-zu-Sequenz-Aufgaben und gesteuerte Textgenerierung zu bewältigen. Organisationen können sich für Drittanbieter-APIs entscheiden, aber das Fine-Tuning von Modellen mit proprietären Daten liefert domänenspezifische und relevante Ergebnisse, was kostengünstige und unabhängige Lösungen ermöglicht, die sicher in verschiedenen Umgebungen eingesetzt werden können.
Die Gewährleistung einer effizienten Ressourcennutzung und Kosteneffizienz ist entscheidend bei der Wahl einer Fine-Tuning-Strategie. Dieser Blogbeitrag untersucht die wohl beliebteste und effektivste Variante solcher parameter-effizienten Methoden, Low Rank Adaptation (LoRA), mit besonderem Schwerpunkt auf QLoRA (einer noch effizienteren Variante von LoRA). Der Ansatz besteht darin, ein offenes Large Language Model zu nehmen und es so zu fine-tunen, dass es fiktive Produktbeschreibungen generiert, wenn es mit einem Produktnamen und einer Kategorie aufgefordert wird. Das für diese Übung gewählte Modell ist OpenLLaMA-3b-v2, ein offenes Large Language Model mit einer permissiven Lizenz (Apache 2.0), und der gewählte Datensatz ist Red Dot Design Award Product Descriptions, die beide von der HuggingFace Hub unter den angegebenen Links heruntergeladen werden können.
Fine-Tuning, LoRA und QLoRA
Im Bereich der Sprachmodelle ist das Fine-Tuning eines bestehenden Sprachmodells für eine bestimmte Aufgabe mit spezifischen Daten eine gängige Praxis. Dies beinhaltet das Hinzufügen eines aufgabenspezifischen Kopfes, falls erforderlich, und die Aktualisierung der Gewichte des neuronalen Netzes durch Backpropagation während des Trainingsprozesses. Es ist wichtig, die Unterscheidung zwischen diesem Fine-Tuning-Prozess und dem Training von Grund auf zu beachten. Im letzteren Fall werden die Gewichte des Modells zufällig initialisiert, während beim Fine-Tuning die Gewichte bereits während der Vortrainingsphase bis zu einem gewissen Grad optimiert sind. Die Entscheidung, welche Gewichte optimiert oder aktualisiert und welche eingefroren werden sollen, hängt von der gewählten Technik ab.
Full Fine-Tuning beinhaltet die Optimierung oder das Training aller Schichten des neuronalen Netzes. Obwohl dieser Ansatz typischerweise die besten Ergebnisse liefert, ist er auch der ressourcenintensivste und zeitaufwändigste.
Glücklicherweise gibt es parameter-effiziente Ansätze für das Fine-Tuning, die sich als effektiv erwiesen haben. Obwohl die meisten dieser Ansätze weniger Leistung erbracht haben, hat LoRA diesem Trend widersprochen und in einigen Fällen sogar das vollständige Fine-Tuning übertroffen, da katastrophales Vergessen vermieden wird (ein Phänomen, das auftritt, wenn das Wissen des vortrainierten Modells während des Fine-Tuning-Prozesses verloren geht).
LoRA ist eine verbesserte Fine-Tuning-Methode, bei der anstatt aller Gewichte, die die Gewichtsmatrix des vortrainierten Large Language Models bilden, zwei kleinere Matrizen feinabgestimmt werden, die diese größere Matrix approximieren. Diese Matrizen bilden den LoRA-Adapter. Dieser feinabgestimmte Adapter wird dann auf das vortrainierte Modell geladen und für die Inferenz verwendet.
QLoRA ist eine noch speichereffizientere Version von LoRA, bei der das vortrainierte Modell als quantisierte 4-Bit-Gewichte (im Vergleich zu 8-Bit bei LoRA) in den GPU-Speicher geladen wird, während die Effektivität ähnlich wie bei LoRA erhalten bleibt. Die Untersuchung dieser Methode, der Vergleich der beiden Methoden, wenn nötig, und die Ermittlung der besten Kombination von QLoRA-Hyperparametern zur Erzielung optimaler Leistung bei schnellster Trainingszeit stehen hier im Fokus.
LoRA ist in der Hugging Face Parameter Efficient Fine-Tuning (PEFT) Bibliothek implementiert und bietet Benutzerfreundlichkeit. QLoRA kann mithilfe von bitsandbytes und PEFT gemeinsam genutzt werden. Die HuggingFace Transformer Reinforcement Learning (TRL) Bibliothek bietet einen praktischen Trainer für supervised Fine-Tuning mit nahtloser Integration für LoRA. Diese drei Bibliotheken bieten die notwendigen Werkzeuge, um das ausgewählte vortrainierte Modell zu fine-tunen und kohärente und überzeugende Produktbeschreibungen zu generieren, sobald es mit einer Anweisung aufgefordert wird, die die gewünschten Attribute angibt.
Vorbereitung der Daten für supervised Fine-Tuning
Um die Effektivität von QLoRA für das Fine-Tuning eines Modells zur Befolgung von Anweisungen zu untersuchen, ist es unerlässlich, die Daten in ein Format zu transformieren, das für supervised Fine-Tuning geeignet ist. Supervised Fine-Tuning trainiert im Wesentlichen ein vortrainiertes Modell weiter, um Text zu generieren, der auf einer bereitgestellten Eingabeaufforderung basiert. Es ist supervised, da das Modell auf einem Datensatz feinabgestimmt wird, der Prompt-Antwort-Paare in einem konsistenten Format enthält.
Eine Beispielbeobachtung aus unserem gewählten Datensatz vom Hugging Face Hub sieht wie folgt aus:
|
Produkt |
Kategorie |
Beschreibung |
Text |
|
"Biamp Rack Products" |
"Digital Audio Processors" |
"Hoher Wiedererkennungswert, einheitliche Ästhetik und praktische Skalierbarkeit – dies wurde mit der Biamp-Markensprache eindrucksvoll umgesetzt …" |
"Produktname: Biamp Rack Products; Produktkategorie: Digital Audio Processors; Produktbeschreibung: „Hoher Wiedererkennungswert, einheitliche Ästhetik und praktische Skalierbarkeit – dies wurde mit der Biamp-Markensprache eindrucksvoll umgesetzt …
|
So nützlich dieser Datensatz auch ist, er ist nicht gut für das Fine-Tuning eines Sprachmodells zur Befolgung von Anweisungen auf die oben beschriebene Weise formatiert.
Der folgende Codeausschnitt lädt den Datensatz vom Hugging Face Hub in den Speicher, transformiert die notwendigen Felder in eine konsistent formatierte Zeichenfolge, die die Eingabeaufforderung darstellt, und fügt die Antwort (d. h. die Beschreibung) unmittelbar danach ein. Dieses Format ist in Fachkreisen der Large Language Models als „Alpaca-Format“ bekannt, da es das Format war, das zum Fine-Tuning des ursprünglichen LLaMA-Modells von Meta verwendet wurde, um das Alpaca-Modell zu erstellen, eines der ersten weit verbreiteten Large Language Models zur Befolgung von Anweisungen (obwohl nicht für die kommerzielle Nutzung lizenziert).
Die resultierenden Eingabeaufforderungen werden dann in einen Hugging Face Datensatz für supervised Fine-Tuning geladen. Jede solche Eingabeaufforderung hat das folgende Format.
Um schnelle Experimente zu ermöglichen, wird jede Feinabstimmungsübung auf einer Teilmenge von 5000 Beobachtungen dieser Daten durchgeführt.
Testen der Modellleistung vor der Feinabstimmung
Bevor Sie mit der Feinabstimmung beginnen, ist es ratsam zu prüfen, wie das Modell ohne Feinabstimmung abschneidet, um eine Baseline für die Leistung des vortrainierten Modells zu erhalten.
Das Modell kann wie folgt in 8-Bit geladen und mit dem im Modell-Card auf Hugging Face angegebenen Format aufgefordert werden.
Die erhaltene Ausgabe ist nicht ganz das, was wir wollen.
Der erste Teil des Ergebnisses ist eigentlich zufriedenstellend, aber der Rest ist eher ein wirres Durcheinander.
Wenn das Modell mit dem Eingabetext im „Alpaca-Format“ aufgefordert wird, wie zuvor besprochen, ist die Ausgabe erwartungsgemäß ebenso suboptimal:
Und tatsächlich ist es das:
Das Modell leistet, wofür es trainiert wurde: Es sagt das nächste wahrscheinlichste Token voraus. Der Sinn der überwachten Feinabstimmung in diesem Kontext besteht darin, den gewünschten Text auf kontrollierbare Weise zu generieren. Bitte beachten Sie, dass in den folgenden Experimenten QLoRA zwar ein Modell verwendet, das in 4-Bit geladen wurde und dessen Gewichte eingefroren sind, der Inferenzprozess zur Untersuchung der Ausgabequalität jedoch einmal durchgeführt wird, nachdem das Modell zu Konsistenzzwecken wie oben gezeigt in 8-Bit geladen wurde.
Die einstellbaren Parameter
Bei der Verwendung von PEFT zum Trainieren eines Modells mit LoRA oder QLoRA (beachten Sie, dass der Hauptunterschied zwischen den beiden darin besteht, dass bei letzterer die vortrainierten Modelle während des Feinabstimmungsprozesses in 4-Bit eingefroren sind), können die Hyperparameter des Low-Rank-Adaptionsprozesses in einer LoRA-Konfiguration definiert werden, wie unten gezeigt:
Zwei dieser Hyperparameter, r und target_modules, beeinflussen empirisch nachweislich die Anpassungsqualität erheblich und werden im Mittelpunkt der folgenden Tests stehen. Die anderen Hyperparameter werden der Einfachheit halber konstant auf die oben angegebenen Werte gehalten.
r repräsentiert den Rang der Matrizen mit niedrigem Rang, die während des Feinabstimmungsprozesses gelernt werden. Wenn dieser Wert erhöht wird, steigt die Anzahl der Parameter, die während der Low-Rank-Adaption aktualisiert werden müssen. Intuitiv kann ein niedrigeres r zu einem schnelleren, weniger rechenintensiven Trainingsprozess führen, kann aber die Qualität des so erzeugten Modells beeinträchtigen. Das Erhöhen von r über einen bestimmten Wert hinaus liefert jedoch möglicherweise keine erkennbare Verbesserung der Qualität der Modellausgabe. Wie sich der Wert von r auf die Anpassungsqualität (Feinabstimmung) auswirkt, wird in Kürze getestet.
Beim Feinabstimmen mit LoRA ist es möglich, bestimmte Module in der Modellarchitektur anzuzielen. Der Anpassungsprozess zielt auf diese Module ab und wendet die Update-Matrizen auf sie an. Ähnlich wie bei „r“ führt die Anzielung weiterer Module während der LoRA-Adaption zu einer längeren Trainingszeit und einem größeren Bedarf an Rechenressourcen. Daher ist es üblich, nur die Aufmerksamkeitsblöcke des Transformers anzuzielen. Neuere Arbeiten, wie im QLoRA-Paper von Dettmers et al. beschrieben, deuten jedoch darauf hin, dass die Anzielung aller linearen Schichten zu einer besseren Anpassungsqualität führt. Dies wird auch hier untersucht.
Namen der linearen Schichten des Modells können mit dem folgenden Code-Snippet bequem einer Liste hinzugefügt werden:
Feinabstimmung mit LoRA
Die Entwicklererfahrung bei der Feinabstimmung von großen Sprachmodellen im Allgemeinen hat sich im letzten Jahr dramatisch verbessert. Die neueste High-Level-Abstraktion von Hugging Face ist die SFTTrainer-Klasse in der TRL-Bibliothek. Um QLoRA durchzuführen, benötigen Sie lediglich Folgendes:
1. Laden Sie das Modell mit 4-Bit in den GPU-Speicher (bitsandbytes ermöglicht diesen Prozess).
2. Definieren Sie die LoRA-Konfiguration wie oben beschrieben.
3. Definieren Sie die Trainings- und Testaufteilungen der vorbereiteten Instruktionsdaten in Hugging Face Dataset-Objekte.
4. Definieren Sie Trainingsargumente. Dazu gehören die Anzahl der Epochen, die Batch-Größe und andere Trainingshyperparameter, die während dieser Übung konstant gehalten werden.
5. Übergeben Sie diese Argumente an eine Instanz von SFTTrainer.
Diese Schritte sind in der Quelldatei im Repository, das mit diesem Blog verknüpft ist, klar angegeben.
Die eigentliche Trainingslogik ist schön abstrahiert, wie folgt:
Wenn das MLFlow-Autologging im Databricks-Workspace aktiviert ist, was sehr empfehlenswert ist, werden alle Trainingsparameter und Metriken automatisch mit dem MLFlow-Tracking-Server verfolgt und protokolliert. Diese Funktionalität ist von unschätzbarem Wert für die Überwachung langwieriger Trainingsaufgaben. Selbstverständlich wird der Feinabstimmungsprozess mit einem Compute-Cluster (in diesem Fall ein einzelner Knoten mit einer einzelnen A100-GPU) durchgeführt, der mit der neuesten Databricks Machine Runtime mit GPU-Unterstützung erstellt wurde.
Hyperparameter-Kombination Nr. 1: QLoRA mit r=8 und Anzielung von „q_proj“, „v_proj“
Die erste Kombination von QLoRA-Hyperparametern, die versucht wird, ist r=8 und zielt nur auf die Aufmerksamkeitsblöcke ab, namentlich „q_proj“ und „v_proj“ zur Anpassung.
Die folgenden Code-Snippets geben die Anzahl der trainierbaren Parameter an:
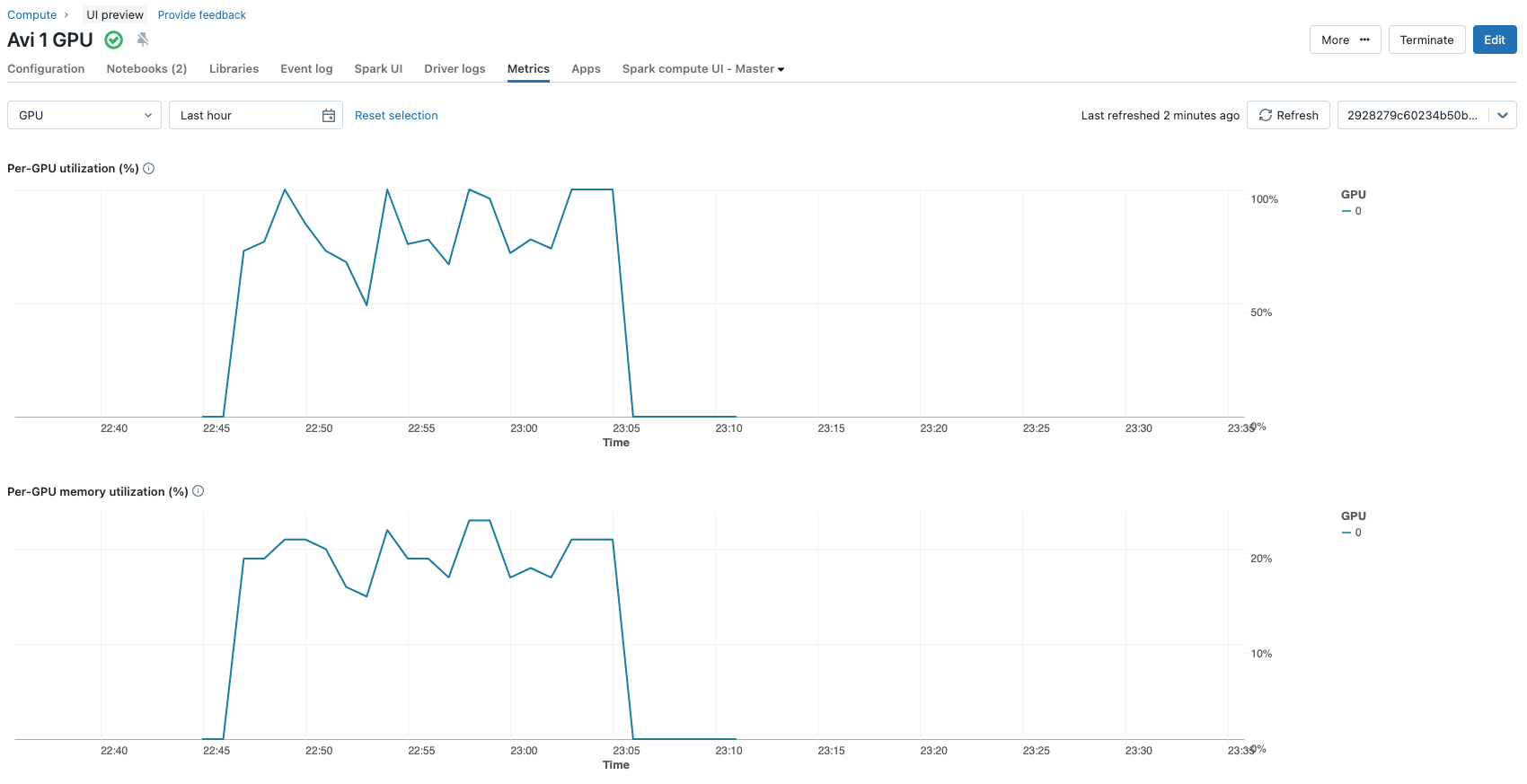
Diese Auswahl führt dazu, dass 2.662.400 Parameter während des Fine-Tuning-Prozesses aktualisiert werden (~2,6 Millionen) von insgesamt ~3,2 Milliarden Parametern, aus denen das Modell besteht. Das sind weniger als 0,1 % der Modellparameter. Der gesamte Fine-Tuning-Prozess auf einer einzelnen Nvidia A100 mit 80 GB GPU für 3 Epochen dauert nur etwa 12 Minuten. Die GPU-Auslastungsmetriken können bequem im Metrik-Tab der Cluster-Konfigurationen eingesehen werden.
Am Ende des Trainingsprozesses wird das feinabgestimmte Modell erhalten, indem die Adaptergewichte in das vortrainierte Modell geladen werden, wie folgt:
Dieses Modell kann nun für die Inferenz wie jedes andere Modell verwendet werden.
Qualitative Bewertung
Ein paar Beispiel-Prompt-Antwort-Paare sind unten aufgeführt
Prompt (an das Modell im Alpaca-Format übergeben, hier der Kürze halber nicht gezeigt):
Erstellen Sie eine detaillierte Beschreibung für das folgende Produkt: Corelogic Smooth Mouse, Kategorie: Optische Maus
Antwort:
Prompt:
Erstellen Sie eine detaillierte Beschreibung für das folgende Produkt: Hoover Lightspeed, Kategorie: Akku-Staubsauger
Antwort:
Das Modell wurde eindeutig für die Generierung konsistenterer Beschreibungen angepasst. Die Antwort auf den ersten Prompt über die optische Maus ist jedoch recht kurz und der folgende Satz „Der Staubsauger ist mit einem Staubbehälter ausgestattet, der über einen Staubbehälter geleert werden kann“ ist logisch fehlerhaft.
Hyperparameter-Kombination Nr. 2: QLoRA mit r=16 und Ziel auf alle linearen Schichten
Sicherlich können hier Dinge verbessert werden. Es lohnt sich, den Rang der während der Anpassung gelernten niedrigrangigen Matrizen auf 16 zu erhöhen, d. h. den Wert von r auf 16 zu verdoppeln und alles andere gleich zu lassen. Dies verdoppelt die Anzahl der trainierbaren Parameter auf 5.324.800 (~5,3 Millionen).
Qualitative Bewertung
Die Qualität der Ausgabe bleibt jedoch für die exakt gleichen Prompts unverändert.
Prompt:
Erstellen Sie eine detaillierte Beschreibung für das folgende Produkt: Corelogic Smooth Mouse, Kategorie: Optische Maus
Antwort:
Prompt:
Erstellen Sie eine detaillierte Beschreibung für das folgende Produkt: Hoover Lightspeed, Kategorie: Akku-Staubsauger
Antwort:
Der gleiche Mangel an Details und logische Fehler in Details, wo Details verfügbar sind, bleibt bestehen. Wenn dieses feinabgestimmte Modell in einem realen Szenario zur Generierung von Produktbeschreibungen verwendet wird, ist dies keine akzeptable Ausgabe.
Hyperparameter-Kombination Nr. 3: QLoRA mit r=8 und Ziel auf alle linearen Schichten
Da die Verdoppelung von r anscheinend keine wahrnehmbare Verbesserung der Ausgabequalität ergibt, lohnt es sich, den anderen wichtigen Regler zu ändern. d. h. alle linearen Schichten anstelle von nur den Aufmerksamkeitsblöcken anzusprechen. Hier sind die LoRA-Hyperparameter r=8 und target_layers sind 'q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj' und 'lm_head'. Dies erhöht die Anzahl der aktualisierten Parameter auf 12.994.560 und verlängert die Trainingszeit auf etwa 15,5 Minuten.
Qualitative Bewertung
Das Prompten des Modells mit denselben Prompts ergibt Folgendes:
Prompt:
Erstellen Sie eine detaillierte Beschreibung für das folgende Produkt: Corelogic Smooth Mouse, Kategorie: Optische Maus
Antwort:
Prompt:
Erstellen Sie eine detaillierte Beschreibung für das folgende Produkt: Hoover Lightspeed, Kategorie: Akku-Staubsauger
Antwort:
Jetzt ist es möglich, eine etwas längere kohärente Beschreibung der fiktiven optischen Maus zu sehen, und es gibt keine logischen Fehler in der Beschreibung des Staubsaugers. Die Produktbeschreibungen sind nicht nur logisch, sondern auch relevant. Nur zur Erinnerung: Diese relativ hochwertigen Ergebnisse werden durch das Fine-Tuning von weniger als 1 % der Modellgewichte mit einem Gesamtdatensatz von 5000 solchen Prompt-Beschreibungs-Paaren erzielt, die auf konsistente Weise formatiert sind.
Hyperparameter-Kombination Nr. 4: LoRA mit r=8 und Ziel auf alle linearen Transformer-Schichten
Es lohnt sich auch zu untersuchen, ob sich die Ausgabequalität des Modells verbessert, wenn das vortrainierte Modell statt in 4-Bit in 8-Bit eingefroren wird. Mit anderen Worten, die exakte Fine-Tuning-Prozedur mit LoRA anstelle von QLoRA zu wiederholen. Hier werden die LoRA-Hyperparameter wie zuvor in der neu gefundenen optimalen Konfiguration beibehalten, d. h. r=8 und die Anpassung zielt auf alle linearen Transformer-Schichten ab.
Qualitative Bewertung
Die Ergebnisse für die beiden im gesamten Artikel verwendeten Prompts sind wie folgt:
Prompt:
Erstellen Sie eine detaillierte Beschreibung für das folgende Produkt: Corelogic Smooth Mouse, Kategorie: Optische Maus
Antwort:
Prompt:
Erstellen Sie eine detaillierte Beschreibung für das folgende Produkt: Hoover Lightspeed, Kategorie: Akku-Staubsauger
Antwort:
Auch hier gibt es keine große Verbesserung der Qualität des Ausgabetextes.
Wichtige Beobachtungen
Basierend auf den obigen Versuchen und weiteren Beweisen, die in der ausgezeichneten Publikation zur Präsentation von QLoRA detailliert beschrieben sind, kann abgeleitet werden, dass der Wert von r (der Rang der während der Anpassung aktualisierten Matrizen) die Anpassungsqualität über einen bestimmten Punkt hinaus nicht verbessert. Die größte Verbesserung wird erzielt, wenn alle linearen Schichten im Anpassungsprozess angesprochen werden, im Gegensatz zu nur den Aufmerksamkeitsblöcken, wie in der technischen Literatur, die LoRA und QLoRA beschreibt, üblicherweise dokumentiert. Die oben durchgeführten Versuche und andere empirische Beweise deuten darauf hin, dass QLoRA im Vergleich zu LoRA tatsächlich keine erkennbare Qualitätsminderung bei der generierten Textausgabe aufweist.
Weitere Überlegungen zur Verwendung von LoRA-Adaptern im Deployment
Es ist wichtig, die Verwendung von Adaptern zu optimieren und die Grenzen der Technik zu verstehen. Die Größe des LoRA-Adapters, der durch Finetuning erhalten wird, beträgt typischerweise nur wenige Megabyte, während das vortrainierte Basismodell mehrere Gigabyte an Speicher und Festplattenspeicher beanspruchen kann. Während der Inferenz müssen sowohl der Adapter als auch das vortrainierte LLM geladen werden, sodass der Speicherbedarf ähnlich bleibt.
Darüber hinaus, wenn die Gewichte des vortrainierten LLM und des Adapters nicht zusammengeführt werden, kommt es zu einem leichten Anstieg der Inferenzlatenz. Glücklicherweise kann mit der PEFT-Bibliothek der Prozess des Zusammenführens der Gewichte mit dem Adapter mit einer einzigen Codezeile durchgeführt werden, wie hier gezeigt:
Die folgende Abbildung skizziert den Prozess vom Finetuning eines Adapters bis zur Modellbereitstellung.

Während das Adapter-Muster erhebliche Vorteile bietet, ist das Zusammenführen von Adaptern keine universelle Lösung. Ein Vorteil des Adapter-Musters ist die Möglichkeit, ein einzelnes großes vortrainiertes Modell mit aufgabenspezifischen Adaptern bereitzustellen. Dies ermöglicht eine effiziente Inferenz, indem das vortrainierte Modell als Rückgrat für verschiedene Aufgaben genutzt wird. Das Zusammenführen von Gewichten macht diesen Ansatz jedoch unmöglich. Die Entscheidung, Gewichte zusammenzuführen, hängt vom spezifischen Anwendungsfall und der akzeptablen Inferenzlatenz ab. Nichtsdestotrotz ist LoRA/QLoRA weiterhin eine äußerst effektive Methode für parameter-effizientes Finetuning und wird häufig eingesetzt.
Fazit
Low Rank Adaptation ist eine leistungsstarke Finetuning-Technik, die großartige Ergebnisse liefern kann, wenn sie mit der richtigen Konfiguration verwendet wird. Die Wahl des richtigen Rangs und der Schichten der neuronalen Netzwerkarchitektur, die während der Anpassung angesprochen werden sollen, kann die Qualität der Ausgabe des feinabgestimmten Modells bestimmen. QLoRA führt zu weiteren Speichereinsparungen bei gleichzeitiger Beibehaltung der Anpassungsqualität. Selbst wenn das Finetuning durchgeführt wird, gibt es mehrere wichtige technische Überlegungen, um sicherzustellen, dass das angepasste Modell auf die richtige Weise bereitgestellt wird.
Zusammenfassend lässt sich sagen, dass eine übersichtliche Tabelle, die die verschiedenen versuchten Kombinationen von LoRA-Parametern, die Textqualitätsausgabe und die Anzahl der aktualisierten Parameter beim Finetuning von OpenLLaMA-3b-v2 für 3 Epochen auf 5000 Beobachtungen auf einer einzelnen A100 angibt, unten gezeigt wird.
|
r |
target_modules |
Basis Modellgewichte |
Qualität der Ausgabe |
Anzahl der aktualisierten Parameter (in Millionen) |
|
8 |
Attention Blöcke |
4 |
niedrig |
2.662 |
|
16 |
Attention Blöcke |
4 |
niedrig |
5.324 |
|
8 |
Alle linearen Schichten |
4 |
hoch |
12.995 |
|
8 |
Alle linearen Schichten |
8 |
hoch |
12.995 |
Probieren Sie dies auf Databricks aus! Klonen Sie das GitHub-Repository für diesen Blog in ein Databricks Repo, um loszulegen. Ausführlichere dokumentierte Beispiele zum Finetuning von Modellen auf Databricks finden Sie hier.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.