Flexible Node-Typen sind jetzt allgemein verfügbar
Verbessern Sie die Zuverlässigkeit beim Starten von Clustern und reduzieren Sie die Computekosten mit automatischem Instanz-Fallback
von Kelsey Ge, Andrew Bagshaw, Tianyi Zhang, Vedaant Shah, Rishan Girish und Hugh March
- Workloads vor Kapazitätsfehlern schützen: Wenn Ihr bevorzugter VM-Typ nicht verfügbar ist, greift Databricks automatisch auf kompatible Alternativen zurück, sodass Cluster trotzdem gestartet werden können.
- Flexibilität im Fleet-Stil für jede Cloud: Flexible Knotentypen ermöglichen einen automatischen Fallback auf andere Instanztypen für Azure, GCP und AWS. Profitieren Sie von einer einfacheren, workspace-weiten „1-Klick“-Aktivierung mit klarer Transparenz der bezogenen Ressourcen und einer optional konfigurierbaren Fallback-Reihenfolge.
- Reduzieren Sie die Kosten, ohne die Zuverlässigkeit zu beeinträchtigen: Priorisieren Sie vergünstigte Spot-Instanzen, wenn verfügbar, und greifen Sie nur bei Bedarf auf Alternativen zurück, um den Starterfolg zu gewährleisten.
Die Sicherung spezifischer Compute-Kapazität kann eine Herausforderung sein, besonders in Zeiten hohen Traffics (und hoher Auslastung). Data Engineers und Plattformadministratoren kennen die Frustration über Fehler aufgrund unzureichender Kapazität oder "Stockout" nur zu gut, die auftreten, wenn ein Clusterstart fehlschlägt, weil ein Cloud-Anbieter eine Anfrage für einen bestimmten Instanztyp nicht erfüllen kann.
Sei es:
AWS_INSUFFICIENT_INSTANCE_CAPACITY_FAILURECLOUD_PROVIDER_RESOURCE_STOCKOUTauf Azure oderGCP_INSUFFICIENT_CAPACITY,
Diese Fehler stören kritische Workloads, insbesondere in geschäftskritischen Zeiträumen, in denen die Betriebszeit am wichtigsten ist.
Was sind flexible Node-Typen?
Bisher mussten in Databricks-Clustern alle Knoten genau dem in Ihrer Konfiguration angegebenen Instanztyp entsprechen. Wenn dieser spezielle Typ nicht verfügbar wäre, würde der Cluster-Start fehlschlagen.
Flexible Knotentypen heben diese Einschränkung auf. Wenn ein bevorzugter Instanztyp nicht verfügbar ist, greift Databricks automatisch auf eine kompatible Alternative zurück, die dieselbe Compute-Struktur aufweist. Mit anderen Worten: Der Cluster wird erfolgreich mit einer Mischung aus ähnlichen Instanztypen gestartet, anstatt direkt fehlzuschlagen.
Für Teams, die eine strengere Kontrolle benötigen, können sie über die API auch eine benutzerdefinierte Fallback-Liste definieren, die angibt, welche Instanztypen in welcher Reihenfolge ausprobiert werden sollen.
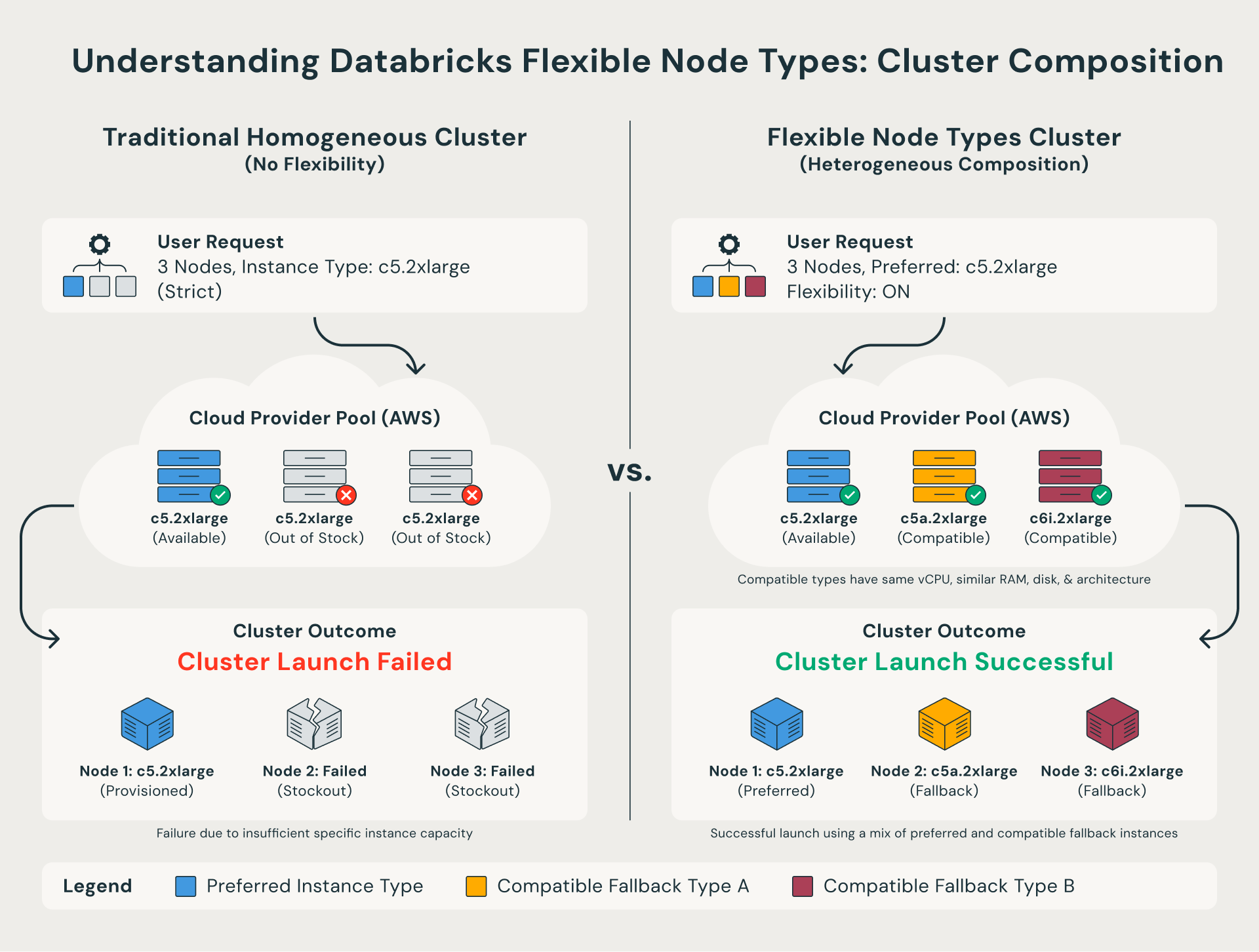
Die wichtigsten Vorteile
Weniger fehlgeschlagene Cluster-Starts bei Spitzennachfrage
Flexible Knotentypen reduzieren sowohl die Häufigkeit als auch den Schweregrad von kapazitätsbedingten Ausfällen. Wenn ein Cloud-Anbieter den bevorzugten Instanztyp nicht bereitstellen kann, greift Databricks automatisch auf kompatible Alternativen zurück, sodass Cluster gestartet werden können, anstatt dass Fehler auftreten.
Optimierte Nutzung von Spot-Instanzen
Bei Clustern, die mit Spot-with-Fallback konfiguriert sind, versuchen flexible Node-Typen, Spot-Kapazitäten über die gesamte Fallback-Liste hinweg zu beziehen, bevor sie auf On-Demand-Instanzen zurückgreifen. Dies erhöht den Anteil des Clusters, der auf Spot-Instanzen ausgeführt wird, was zur Senkung der Rechenkosten beiträgt und gleichzeitig erfolgreiche Starts priorisiert.
Klare Transparenz und präzise Steuerung
Teams können mithilfe der Systemtabelle node_timeline genau prüfen, welche Node-Typen bezogen werden. Zusätzlich kann über die API eine benutzerdefinierte Fallback-Reihenfolge festgelegt werden, die eine präzise Steuerung des Kosten- und Performanceverhaltens ermöglicht.
JETZT STARTEN
Workspace-Administratoren können das Feature einfach in den Administratoreinstellungen aktivieren (Dokumentation: AWS, Azure, GCP). Von da an gilt das Feature sofort für alle neuen Cluster-Starts. Langlaufende Cluster übernehmen das Feature bei ihrem nächsten Neustart, und zukünftige Job-Cluster, die für bestehende Jobs erstellt werden, nutzen das Feature automatisch.
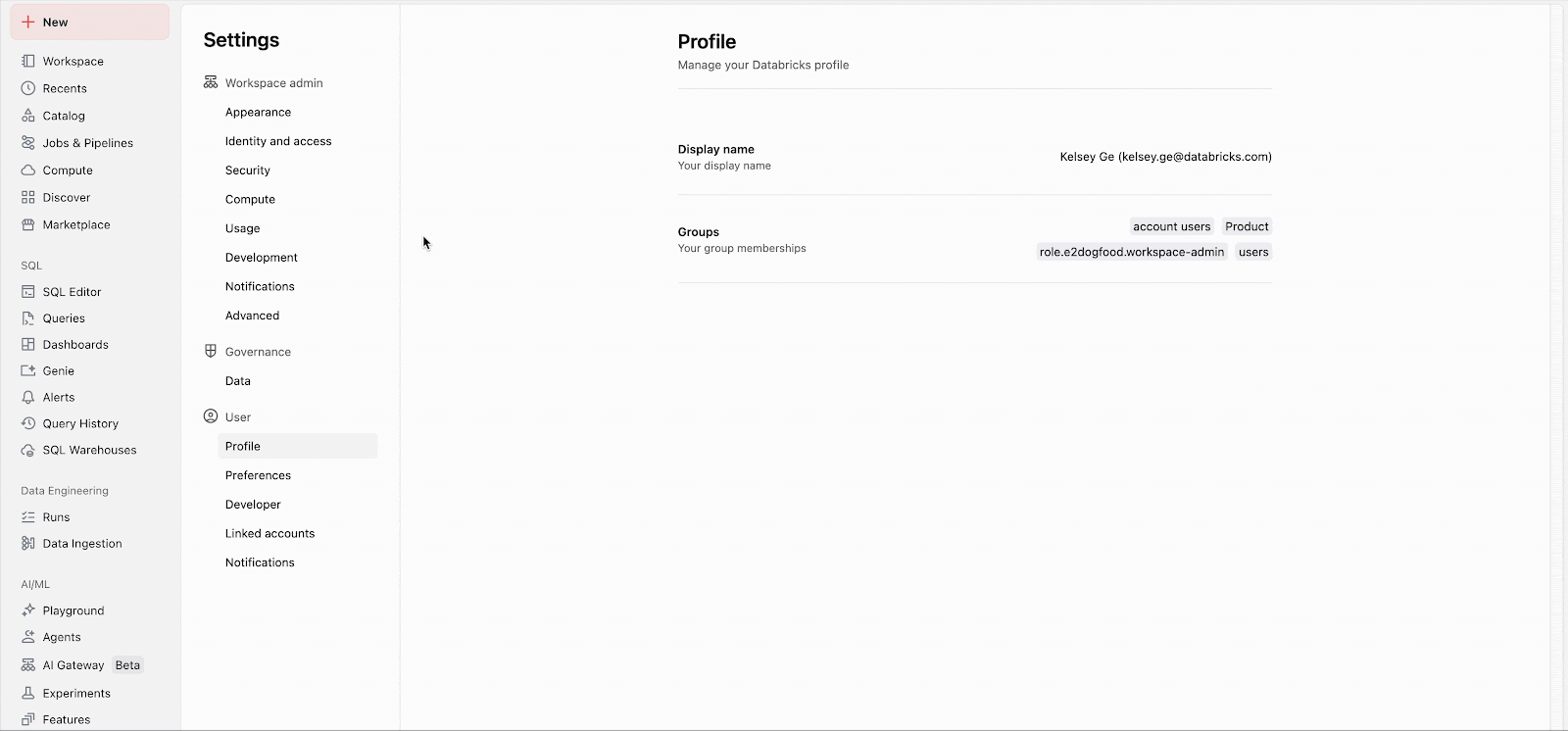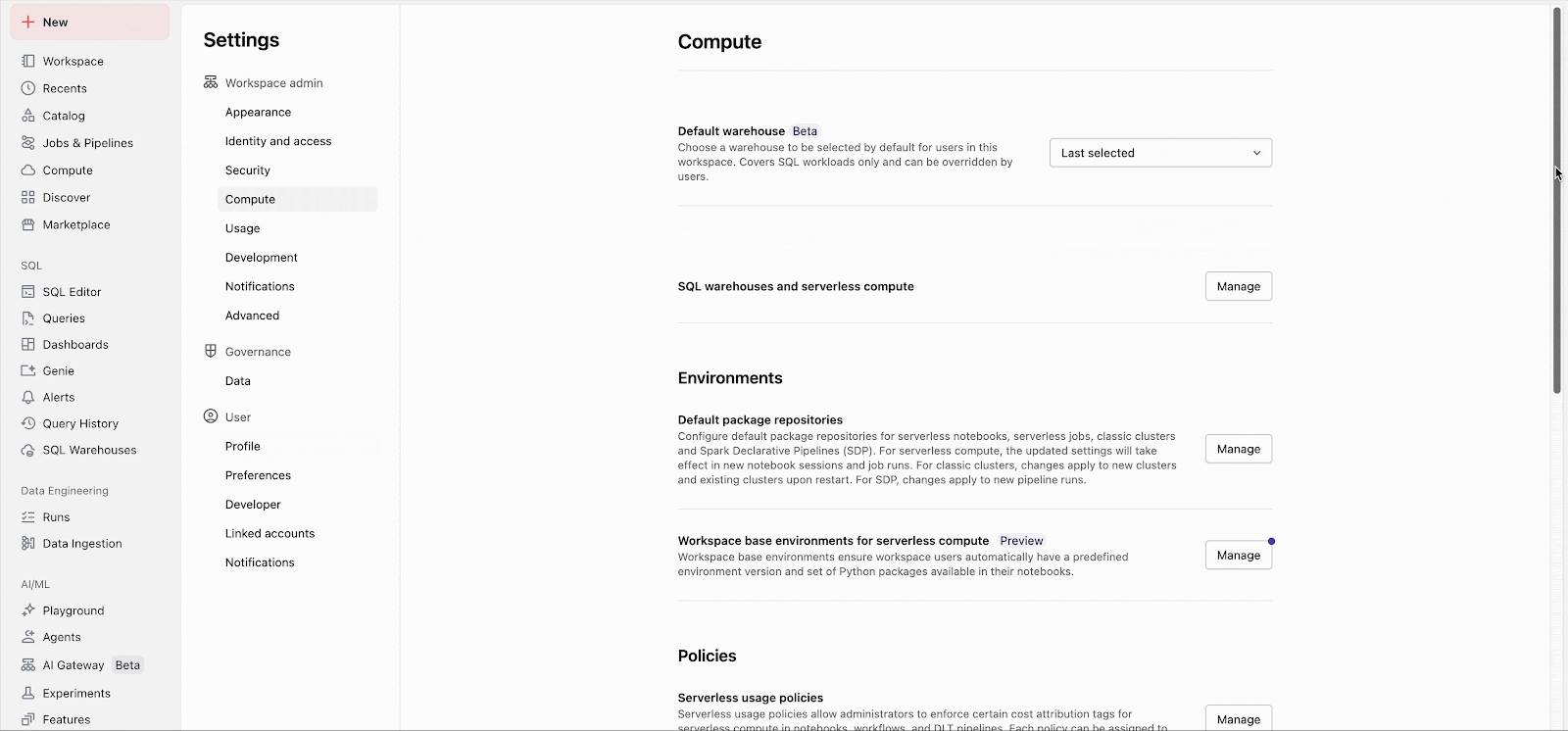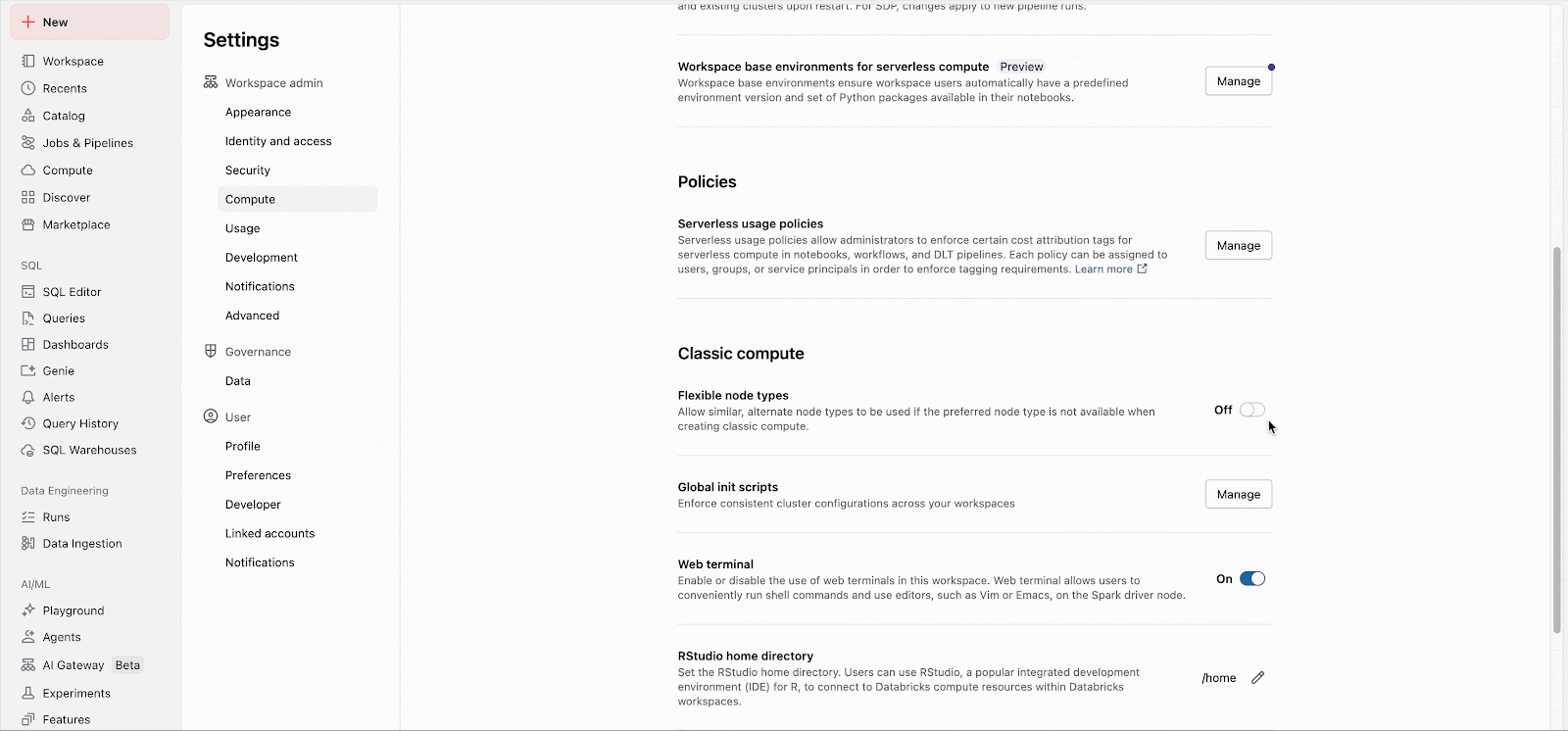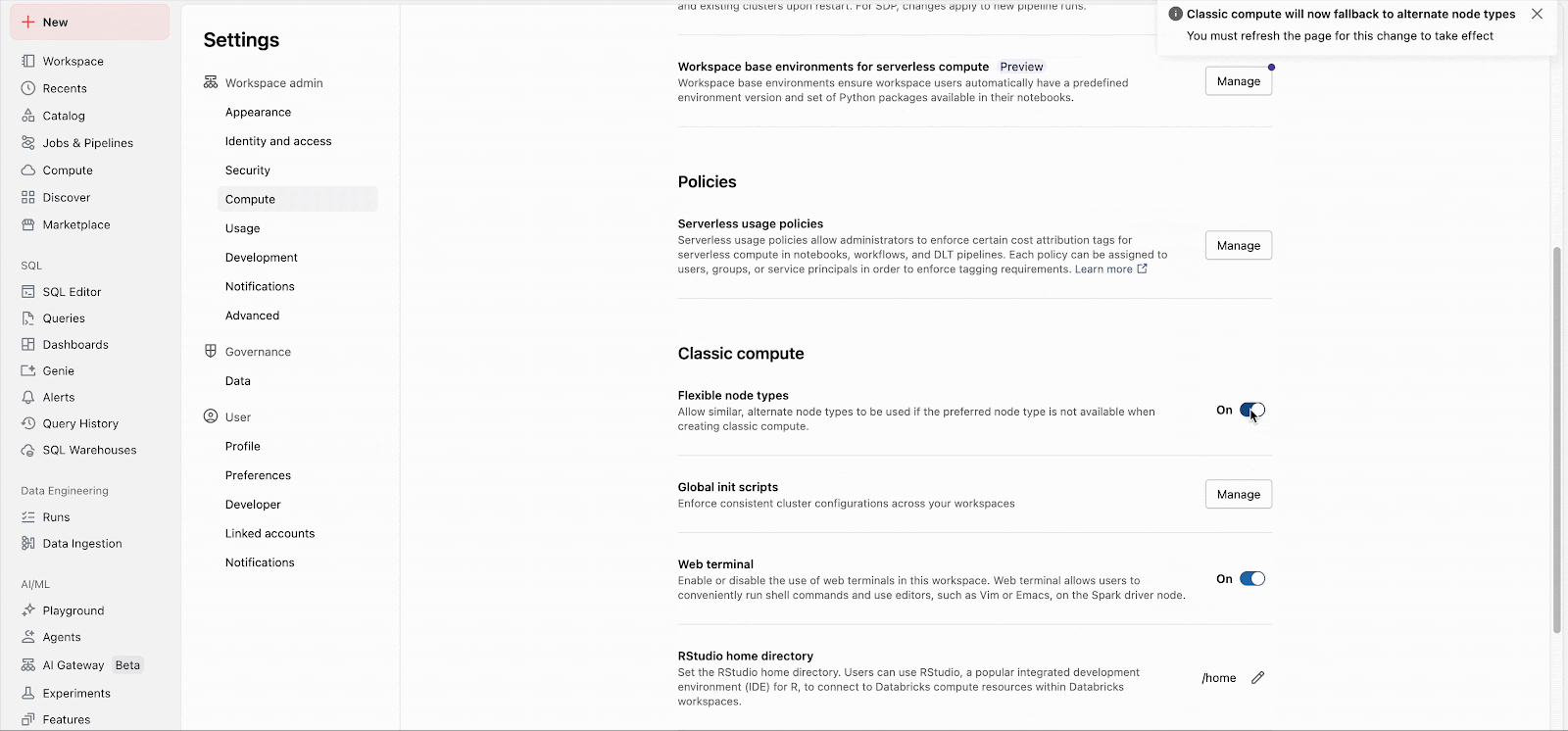
Benutzerdefinierte Fallback-Listen können über die API konfiguriert werden, unabhängig von der Workspace-Einstellung.
Weitere Details
Weitere Informationen zur Konfiguration von flexiblen Node-Typen mit Instanzpools, Abrechnung, Node-Typ-Kontingenten und selektiver Aktivierung/Deaktivierung finden Sie in der Dokumentation (Dokumentation: AWS, Azure, GCP).
Flexible Node-Typen wurden entwickelt, um Ihre Datenplattform widerstandsfähiger und kostengünstiger zu machen. Administratoren können dieses Feature noch heute mit nur einem Klick in den workspace-Administratoreinstellungen aktivieren, indem sie den Anweisungen in der Dokumentation folgen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.