Erste Schritte mit der Personalisierung durch Propensity-Scoring
von Tian Tan, Sam Steiny und Bryan Smith

Verbraucher erwarten zunehmend eine personalisierte Ansprache. Ob es sich um eine E-Mail handelt, die Produkte als Ergänzung zu einem kürzlich getätigten Kauf empfiehlt, ein Online-Banner, das einen Ausverkauf von Produkten in einer häufig durchstöberten Kategorie ankündigt, oder um Inhalte, die auf geäußerte Interessen abgestimmt sind – Verbraucher haben immer mehr Möglichkeiten, ihr Geld auszugeben, und bevorzugen Anbieter, die ihre persönlichen Bedürfnisse und Vorlieben erkennen.
Eine aktuelle Umfrage von McKinsey zeigt, dass fast drei Viertel der Verbraucher mittlerweile personalisierte Interaktionen als Teil ihres Einkaufserlebnisses erwarten. Die in dieser Umfrage enthaltene Untersuchung verdeutlicht, dass Unternehmen, die dies richtig umsetzen, durch personalisierte Kundenansprache 40 % mehr Umsatz generieren können. Dies macht die Personalisierung zu einem entscheidenden Differenzierungsmerkmal für die führenden Akteure im Einzelhandel.
Dennoch tun sich viele Einzelhändler mit der Personalisierung schwer. Eine aktuelle Umfrage von Forrester zeigt, dass nur 30 % der Verbraucher in den US und 26 % in Großbritannien der Meinung sind, dass Einzelhändler relevante Erlebnisse für sie schaffen. In einer separaten Umfrage von 3radical gaben nur 18 % der Befragten an, dass sie maßgeschneiderte Empfehlungen erhalten, während 52 % ihre Frustration über irrelevante Mitteilungen und Angebote äußerten. Da Verbraucher immer einfacher die Marke oder den Anbieter wechseln können, hat die richtige Personalisierung für immer mehr Unternehmen oberste Priorität erlangt.
Personalisierung ist ein Weg
Für ein Unternehmen, das neu im Bereich der Personalisierung ist, mag die Vorstellung einer individuellen Eins-zu-eins-Ansprache entmutigend wirken. Wie überwinden wir isolierte Prozesse, mangelhafte Datenverwaltung und Bedenken hinsichtlich des Datenschutzes, um die für diesen Ansatz erforderlichen Daten zusammenzutragen? Wie erstellen wir mit begrenzten Marketingressourcen Inhalte und Botschaften, die sich wirklich personalisiert anfühlen? Wie stellen wir sicher, dass die von uns erstellten Inhalte effektiv auf Personen mit sich ständig ändernden Bedürfnissen und Vorlieben ausgerichtet sind?
Während ein Großteil der Fachliteratur zur Personalisierung modernste Ansätze hervorhebt, die sich durch ihre Neuartigkeit (aber nicht immer durch ihre Wirksamkeit) auszeichnen, ist Personalisierung in der Realität ein Weg. In der Anfangsphase liegt der Schwerpunkt auf der Nutzung von First-Party-Daten, bei denen Datenschutz und Kundenvertrauen leichter gewahrt werden können. Es werden relativ standardmäßige prädiktive Methoden angewendet, um bewährte Funktionen voranzubringen. Sobald sich der Nutzen zeigt und das Unternehmen nicht nur Vertrauen in diese neuen Techniken gewinnt, sondern auch die verschiedenen Möglichkeiten zu ihrer Integration in die Praxis kennenlernt, kommen anspruchsvollere Ansätze zum Einsatz.
Propensity Scoring ist oft ein erster Schritt zur Personalisierung
Einer der ersten Schritte auf dem Weg zur Personalisierung ist oft die Analyse von Verkaufsdaten, um Erkenntnisse über individuelle Kundenpräferenzen zu gewinnen. In einem Prozess, der als Propensity Scoring bezeichnet wird, können Unternehmen die potenzielle Empfänglichkeit von Kunden für ein Angebot oder für Inhalte im Zusammenhang mit einer bestimmten Produktgruppe abschätzen. Mithilfe dieser Scores können Marketer bestimmen, welche der vielen verfügbaren Botschaften einem bestimmten Kunden präsentiert werden sollten. Ebenso können diese Scores verwendet werden, um Kundensegmente zu identifizieren, die für eine bestimmte Form der Ansprache mehr oder weniger empfänglich sind.
Der Ausgangspunkt für die meisten Propensity-Scoring-Analysen ist die Berechnung numerischer Attribute (Features) aus vergangenen Interaktionen. Diese Features können beispielsweise die Kaufhäufigkeit eines Kunden, den prozentualen Anteil der Ausgaben für eine bestimmte Produktkategorie, die Anzahl der Tage seit dem letzten Kauf und viele andere aus den historischen Daten abgeleitete Metriken umfassen. Der historische Zeitraum, der unmittelbar auf den Zeitraum folgt, aus dem diese Features berechnet wurden, wird dann auf relevante Verhaltensweisen untersucht, wie z. B. den Kauf eines Produkts in einer bestimmten Kategorie oder das Einlösen eines Gutscheins. Wird das Verhalten beobachtet, wird den Features das Label 1 zugewiesen. Wenn nicht, wird das Label 0 vergeben.
Unter Verwendung der Features als Prädiktoren für die Labels können Data Scientists ein Modell trainieren, um die Wahrscheinlichkeit zu schätzen, mit der das betreffende Verhalten auftreten wird. Durch die Anwendung dieses trainierten Modells auf die für den jüngsten Zeitraum berechneten Features können Marketer die Wahrscheinlichkeit abschätzen, mit der ein Kunde dieses Verhalten in absehbarer Zukunft zeigen wird.
Da uns zahlreiche Angebote, Werbeaktionen, Botschaften und andere Inhalte zur Verfügung stehen, werden mehrere Modelle, die jeweils ein anderes Verhalten vorhersagen, trainiert und auf denselben Feature-Satz angewendet. Es wird ein kundenbezogenes Profil erstellt, das aus Scores für jedes der relevanten Verhaltensweisen besteht, und anschließend an nachgelagerte Systeme übermittelt, damit das Marketing dieses für die Orchestrierung verschiedener Kampagnen nutzen kann.
Databricks bietet entscheidende Funktionen für das Propensity Scoring
So einfach Propensity Scoring auch klingen mag, es ist nicht ohne Herausforderungen. In unseren Gesprächen mit Einzelhändlern, die Propensity Scoring implementieren, stoßen wir oft auf dieselben drei Fragen:
- Wie verwalten wir die Hunderte und manchmal Tausende von Features, die wir zum Trainieren unserer Propensity-Modelle verwenden?
- Wie trainieren wir schnell Modelle, die auf neue Kampagnen abgestimmt sind, die das Marketing-Team durchführen möchte?
- Wie stellen wir Modelle, die aufgrund von Veränderungen im Kundenverhalten (Drift) neu trainiert wurden, schnell wieder in der Scoring-Pipeline bereit?
Bei Databricks liegt unser Fokus darauf, unsere Kunden durch eine Analyseplattform zu unterstützen, die speziell für die End-to-End-Anforderungen von Unternehmen entwickelt wurde. Zu diesem Zweck haben wir Funktionen wie den Feature Store, AutoML und MLflow in unsere Plattform integriert, die alle genutzt werden können, um diese Herausforderungen im Rahmen eines robusten Propensity-Scoring-Prozesses zu bewältigen.
Feature Store
Der Databricks Feature Store ist ein zentrales Repository, das die Speicherung, Erkennung und gemeinsame Nutzung von Features über verschiedene Modelltrainings hinweg ermöglicht. Beim Erfassen von Features werden auch die Lineage (Datenherkunft) und andere Metadaten erfasst, sodass Data Scientists, die von anderen erstellte Features wiederverwenden möchten, dies sicher und problemlos tun können. Standardmäßige Sicherheitsmodelle stellen sicher, dass nur autorisierte Benutzer und Prozesse diese Features nutzen können, sodass Data-Science-Prozesse in Übereinstimmung mit den Richtlinien des Unternehmens für den Datenzugriff verwaltet werden.
AutoML
Databricks AutoML ermöglicht es Ihnen, unter Nutzung bewährter Branchenpraktiken schnell Modelle zu erstellen. Als Glass-Box-Lösung erstellt AutoML zunächst eine Sammlung von Notebooks, die verschiedene, auf Ihr Szenario abgestimmte Modellvarianten darstellen. Während es die verschiedenen Modelle iterativ trainiert, um zu ermitteln, welches am besten für Ihren Datensatz geeignet ist, können Sie auf die mit jedem dieser Modelle verknüpften Notebooks zugreifen. Für viele Data-Science-Teams werden diese Notebooks zu einem editierbaren Ausgangspunkt für die weitere Untersuchung von Modellvarianten, was es ihnen letztendlich ermöglicht, ein trainiertes Modell zu erhalten, von dem sie überzeugt sind, dass es ihre Ziele erfüllt.
MLflow
MLflow ist ein Open-Source-Repository für Machine-Learning-Modelle, das innerhalb der Databricks-Plattform verwaltet wird. Dieses Repository ermöglicht es dem Data-Science-Team, die verschiedenen Modelliterationen zu verfolgen und zu analysieren, die sowohl durch AutoML als auch durch benutzerdefinierte Trainingszyklen generiert wurden. Seine Workflow-Management-Funktionen ermöglichen es Unternehmen, trainierte Modelle schnell von der Entwicklung in die Produktion zu überführen, sodass diese direkt Einfluss auf den Betrieb nehmen können.
In Kombination mit dem Databricks Feature Store behalten Modelle, die mit MLflow gespeichert wurden, das Wissen über die beim Training verwendeten Features. Wenn Modelle für die Inferenz abgerufen werden, ermöglicht dieselbe Information dem Modell, relevante Features aus dem Feature Store abzurufen, was den Scoring-Workflow erheblich vereinfacht und eine schnelle Bereitstellung ermöglicht.
Erstellung eines Propensity-Scoring-Workflows
Durch die Kombination dieser Funktionen implementieren viele Unternehmen das Propensity Scoring als Teil eines dreiteiligen Workflows. Im ersten Teil arbeiten Data Engineers mit Data Scientists zusammen, um für das Propensity Scoring relevante Features zu definieren und diese im Feature Store zu speichern. Anschließend werden tägliche oder sogar Echtzeit-Feature-Engineering-Prozesse definiert, um aktuelle Feature-Werte zu berechnen, sobald neue Daten eingehen.
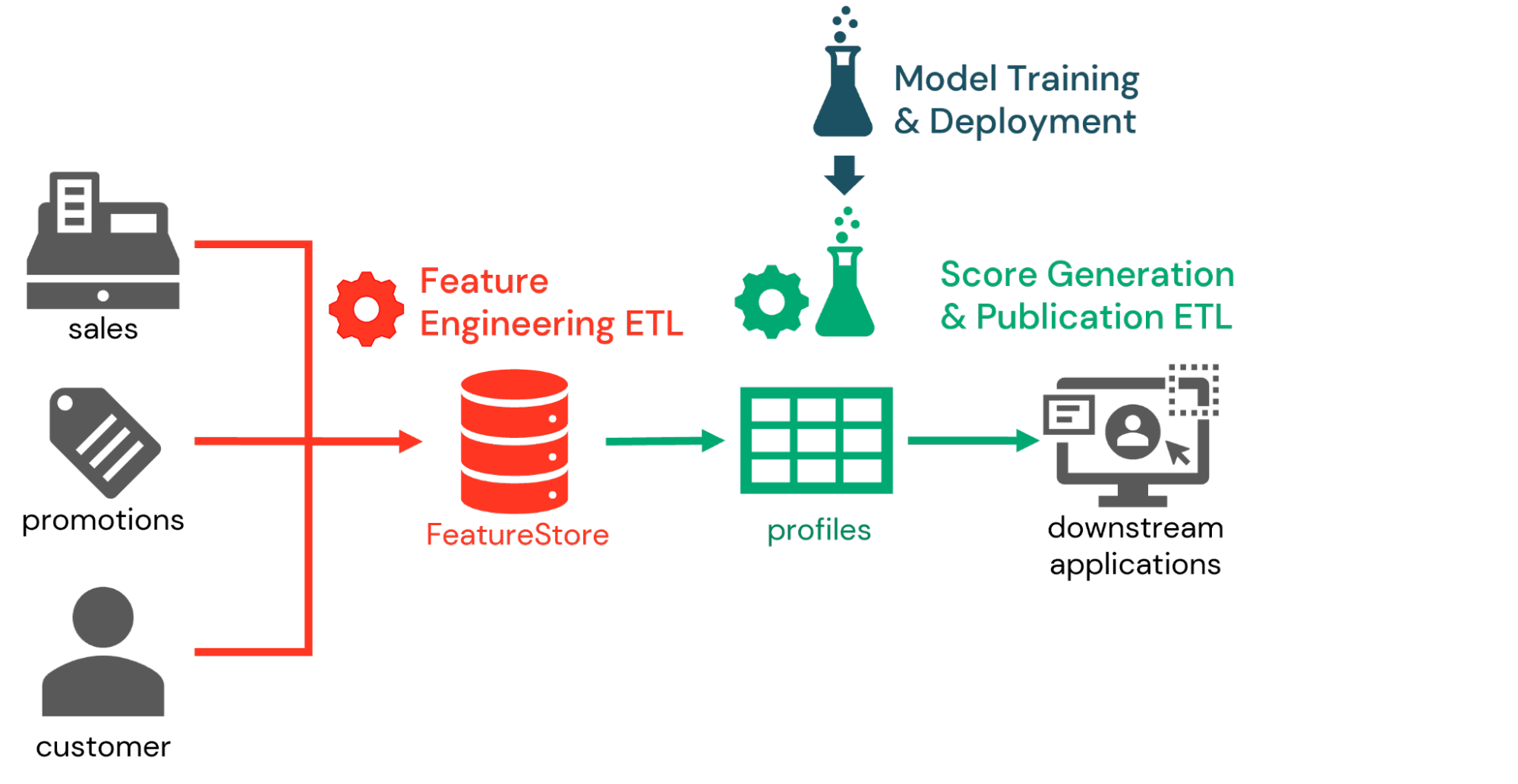
Als Nächstes werden im Rahmen des Inferenz-Workflows Kunden-IDs an zuvor trainierte Modelle übergeben, um Propensity-Scores auf der Grundlage der neuesten verfügbaren Features zu generieren. Die mit dem Modell erfassten Feature-Store-Informationen ermöglichen es Data Engineers, diese Features abzurufen und die gewünschten Scores relativ einfach zu generieren. Diese Scores können für Analysen innerhalb der Databricks-Plattform gespeichert werden, werden jedoch in der Regel an nachgelagerte Marketingsysteme übermittelt.
Schließlich trainieren Data Scientists im Modelltraining-Workflow die Propensity-Score-Modelle regelmäßig neu, um Veränderungen im Kundenverhalten zu erfassen. Da diese Modelle in MLflow gespeichert werden, werden Change-Management-Prozesse eingesetzt, um die Modelle zu bewerten und diejenigen Modelle, die die Kriterien des Unternehmens erfüllen, in den Produktionsstatus zu überführen. In der nächsten Iteration des Inferenz-Workflows wird die neueste Produktionsversion jedes Modells abgerufen, um Kundenscores zu generieren.
Um zu demonstrieren, wie diese Funktionen zusammenwirken, haben wir einen End-to-End-Workflow für das Propensity-Scoring auf der Grundlage eines öffentlich zugänglichen Datensatzes erstellt. Dieser Workflow veranschaulicht die drei Säulen des oben beschriebenen Workflows und zeigt, wie Sie wichtige Databricks-Funktionen nutzen können, um eine effektive Propensity-Scoring-Pipeline aufzubauen.
Laden Sie die Assets hier herunter und nutzen Sie diese als Ausgangspunkt, um Ihre eigene Grundlage für die Personalisierung mithilfe der Databricks-Plattform zu schaffen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.