Wie die Lakehouse-Architektur widerstandsfähig gegen Cloud-Ausfälle bleibt
von Jasraj Dange und Hans Norheim
- Agent-Workloads verändern die Anforderungen an die Cloud-Zuverlässigkeit. Agenten erstellen Datenbanken 4x schneller als Menschen, fordern serverlose und automatisch skalierende Infrastrukturen an und behandeln Control-Plane-Operationen (wie das Starten einer Datenbank) als kritische Data-Plane-Arbeit. In Lakebase starten wir jetzt zig Millionen Datenbanken pro Tag.
- Die Lakebase-Architektur ist auf Ausfallsicherheit ausgelegt, nicht darauf geflickt. Zustandslose Postgres-Berechnungen auf zonenredundantem Speicher bedeuten, dass Instanzen sofort ersetzt werden können, ohne Hot Standbys oder Crash Recovery. Wir trennen Hot-Path-Control-Plane-Operationen in einen dedizierten Dienst, minimieren Abhängigkeiten von Cloud-Anbietern und unterteilen jede Region in in sich geschlossene Zellen.
- Wir beweisen Zuverlässigkeit durch Tests und Messungen, nicht durch Versprechungen. Jede Veröffentlichung durchläuft Chaos-Tests mit Fault Injection auf Prozess-, Knoten- und Verfügbarkeitszonenebene, validiert gegen Open-Source-Tools wie SqlLancer. Wir verfolgen die Verfügbarkeit pro Datenbank (nicht Flotten-Durchschnitte) gegen ein monatliches Ziel von 99,99 %, wobei die Erreichung transparent veröffentlicht wird.
Im letzten Jahr haben Agenten die Grenzen der Cloud-Infrastruktur mit neuen Nutzungsmustern ausgereizt:
- Höherer Durchsatz von Control-Plane-Operationen: Agenten erstellen und verwalten Datenbanken, Speicher, Rechenleistung und andere Infrastrukturkomponenten programmatisch in Raten, die weit über denen von Menschen liegen. In Databricks Lakebase erstellen Agenten 4x so viele Datenbanken wie Menschen.
- Mehr Nachfrage nach On-Demand: Serverless, autoscaling und Auto-Suspend-Infrastruktur sind die neue Norm. Wenn der Agent in den Ruhezustand geht, warum für bereitgestellte Infrastruktur bezahlen?
- Kapazitätsengpässe: Die Nachfrage nach Rechenleistung, GPUs und Cloud-Infrastruktur steigt. Die Vorstellung von unendlicher Kapazität in der Cloud zeigt Risse.
Dies ist sowohl für Plattformentwickler als auch für Cloud-Anbieter eine Herausforderung. Control Planes verzeichnen erhebliche Zunahmen im Anfragevolumen für die Erstellung, Verwaltung und Skalierung von Infrastruktur, was die Zuverlässigkeit belastet. Die Zuweisung neuer Cloud-Kapazitäten wird nicht immer erfolgreich sein. Gleichzeitig erfordern agentenbasierte Workloads Daten-Plane-Level-Zuverlässigkeit für Kern-Control-Plane-Operationen als Teil ihrer operativen Abläufe. In den letzten Monaten haben wir beobachtet, wie Agenten einen exponentiellen Anstieg der Datenbankstarts verursachten, und jetzt starten wir täglich zig Millionen von Datenbanken.
Die daraus resultierende Flut von Fehlern und Vorfällen bei Cloud-Diensten hat uns Lektionen gelehrt, die unsere Zuverlässigkeits-Roadmap beeinflussen, und wir möchten Ihnen mitteilen, wie wir die Architektur und das Design von Lakebase widerstandsfähiger gegen Cloud-Ausfälle machen. Einige Punkte sind bereits in Produktion, andere sind in Arbeit.
Hochverfügbarkeitsarchitektur
Grundlage ist unsere Architektur mit getrennter Rechenleistung und Speicher, bei der Hochverfügbarkeit (HA) ein Kernprinzip des Systems und kein nachträglicher Zusatz ist.
Stateless Postgres Compute
Im Gegensatz zu vielen Cloud-Postgres-Datenbankdiensten, die monolithisch sind und zustandsbehaftete Rechenleistung haben, ist Postgres in der Lakebase-Architektur zustandslos. Alle dauerhaften Daten befinden sich in einem Remote-Speicherdienst, sodass der Compute-Prozess keinen dauerhaften Zustand auf der lokalen Festplatte speichert. Wenn Postgres oder die Hardware, auf der es läuft, ausfällt, kann es sofort ersetzt werden, ohne Daten auf einen Hot Standby zu replizieren oder die übliche Postgres-Crash-Wiederherstellung durchzuführen. Ein Hot Standby in einem monolithischen Setup erfordert eine vollständige Kopie der Daten (nicht kostenlos), während die Crash-Wiederherstellung das Write-Ahead Log (WAL) ab dem letzten Checkpoint wiederherstellen muss, was mit der Schreibrate zum Zeitpunkt des Absturzes skaliert und je nach Konfiguration 10 Minuten dauern kann. Da die Datenbankinhalte in unserem zonenredundanten Speicherdienst gespeichert sind, hat eine Single-Compute-Postgres-Instanz in Lakebase eine deutlich verbesserte Verfügbarkeit im Vergleich zu einer einzelnen zustandsbehafteten Postgres-Instanz, ohne die Kosten für eine zusätzliche Hot-Standby-Compute-Instanz.
Für Datenbanken, die höchste Verfügbarkeitsstufen erfordern, können Sie Hochverfügbarkeit konfigurieren. Dies stellt dedizierte Rechenleistung über mehrere Verfügbarkeitszonen für Ihre Datenbank bereit und stellt sicher, dass Ihre Datenbank verfügbar bleibt, auch wenn dem Cloud-Anbieter während (oder als Folge) eines Ausfallereignisses die Kapazität ausgeht. Diese Rechenleistung kann zusätzlich zur Skalierung von Lesevorgängen genutzt werden.
Zonenredundanter Speicher für alle
Monolithische Postgres-Setups werden normalerweise von lokalen Blockgeräten gesichert, die selten zonenredundant sind. Dies erfordert eine physische Replikation und kostspielige Hot-Standby-Replikate über mehrere Verfügbarkeitszonen hinweg. In Lakebase und Neon werden alle Datenbanken, unabhängig von ihrer Stufe und Konfiguration, von verteiltem, zonenredundantem, hochverfügbarem Speicher gesichert. Daten werden in hochbeständigem, zonenredundantem Objektspeicher gespeichert, und die Leistung wird durch NVMe-SSD-Caches über mehrere Verfügbarkeitszonen hinweg ohne zusätzliche Kosten für Sie beschleunigt.
Control Plane ist die neue Data Plane
In der monolithischen Architektur von Cloud-Datenbankdiensten ist die Data Plane der kritische Teil des Dienstes. Sie ist für eine Verfügbarkeit von 99,99 % und statische Stabilität ausgelegt. Die Control Plane ist „nur“ für Verwaltungsoperationen wichtig. Bei agentenbasierten und On-Demand-Workloads ist der Teil der Control Plane, der Datenbanken startet, effektiv die Data Plane. Dies hat unsere Denkweise über unsere Architektur verändert. Derzeit kümmert sich unsere Control Plane um alles, vom Starten von Datenbanken bis zur Abrechnung. Das Erstere ist eindeutig kritischer. Wir hatten Ausfälle, bei denen Hintergrundwartungsoperationen die On-Demand-Datenbankstarts ressourcenmäßig ausgebremst haben – das ist eindeutig nicht in Ordnung.
Wir arbeiten derzeit intensiv daran, die kritischen Teile der Control Plane in einen Data-Plane-Controller-Dienst auszulagern, der nur Hot-Path-Operationen (Start/Suspend) handhabt. Dieser Dienst hat weniger Geschäftslogik, eine strenge, minimale Menge an externen Abhängigkeiten (siehe nächster Abschnitt) und ist von Grund auf mit Fokus auf Ausfallsicherheit, schrittweise Verschlechterung und Defense-in-Depth konzipiert.
Um zu veranschaulichen, wie zentral die Control Plane für den Datenbankverkehr ist, können wir die Lebenszyklen von Compute-Sitzungen analysieren (die Zeit vom automatischen Wiederaufnehmen aufgrund einer eingehenden Verbindung bis zum Herunterfahren aufgrund von Inaktivität). In Neon sind 90 % der Compute-Sitzungen für automatisch pausierende Datenbanken kürzer als 10 Minuten.
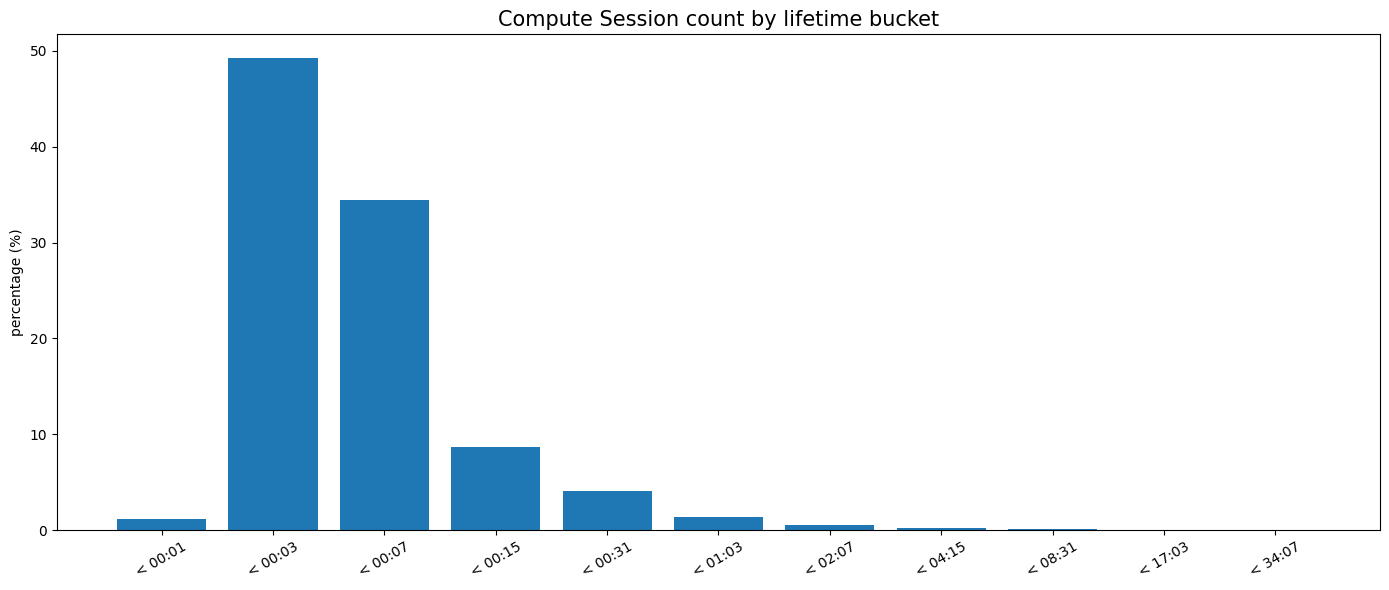
Kritische Pfadabhängigkeiten sorgfältig prüfen, einschließlich der Control Planes von Cloud-Anbietern
Das Bereitstellen von agentenbasierten Workloads bedeutet, dass das Erstellen und Wiederaufnehmen von Datenbanken hochgradig zuverlässig sein muss. Zuverlässigkeit korreliert stark mit der Abhängigkeitskette und der Menge der beteiligten Maschinen im Ablauf. In einem herkömmlichen Setup mit Postgres in Cloud-Provider-VMs geht dies weit über die Data Plane hinaus:
- Compute-Control-Plane des Cloud-Anbieters zur Bereitstellung von VMs
- Verfügbare VM-Kapazität (wobei der Cloud-Anbieter die Richtlinie kontrolliert, wer sie erhält)
- Block-Store-Control-Plane des Cloud-Anbieters zur Bereitstellung von lokalem Speicher
- Netzwerk-Control-Plane des Cloud-Anbieters zur Zuweisung von IPs, Konfiguration von Firewalls und Netzwerkrouten zur neuen VM
- Bei Verwendung von Kubernetes (K8s) – eine zusätzliche Abhängigkeit von den K8s-Systemdiensten.
In Lakebase verfolgen wir einen anderen Ansatz, der die Menge der Control-Plane-Maschinen, die an kritischen Datenbankabläufen beteiligt sind, drastisch reduziert:
- Wir weisen dem Cloud-Anbieter einen Pool großer (oft Bare-Metal-)Instanzen zu. Wir halten Puffer vor, um Ausfälle bei der Bereitstellung durch den Cloud-Anbieter zu überstehen.
- Wir haben unsere eigene vertikal skalierende Virtualisierungsschicht entwickelt, die mehrere Postgres-Instanzen auf diesen Cloud-Instanzen plant.
- Wir verlassen uns nicht auf Cloud-Block-Store-Geräte, sondern speichern Daten stattdessen in unserem eigenen zonenredundanten Speicher, der letztendlich in Objektspeichern wie S3 oder Azure Blob Storage gesichert ist.
Viele andere Dienste bei Databricks stehen vor ähnlichen Zuverlässigkeitsproblemen. Hier profitiert Lakebase davon, Teil von Databricks zu sein: Databricks verfügt über die Mittel und investiert stark in den Aufbau einer gemeinsamen Plattform, um die Zuverlässigkeit aller Produkte in allen drei großen Clouds zu erhöhen.
Kompartimentierung und Eindämmung des Schadensradius
Anstatt eine einzelne monolithische regionale Bereitstellung auszuführen, setzt sich Lakebase aus einer oder mehreren identisch aufgebauten Zellen zusammensetzend. Eine Zelle ist ein vollständiger, in sich geschlossener Teil des Neon- und Lakebase-Stacks: Kubernetes, Steuerungsebene, Rechenleistung und Speicher.
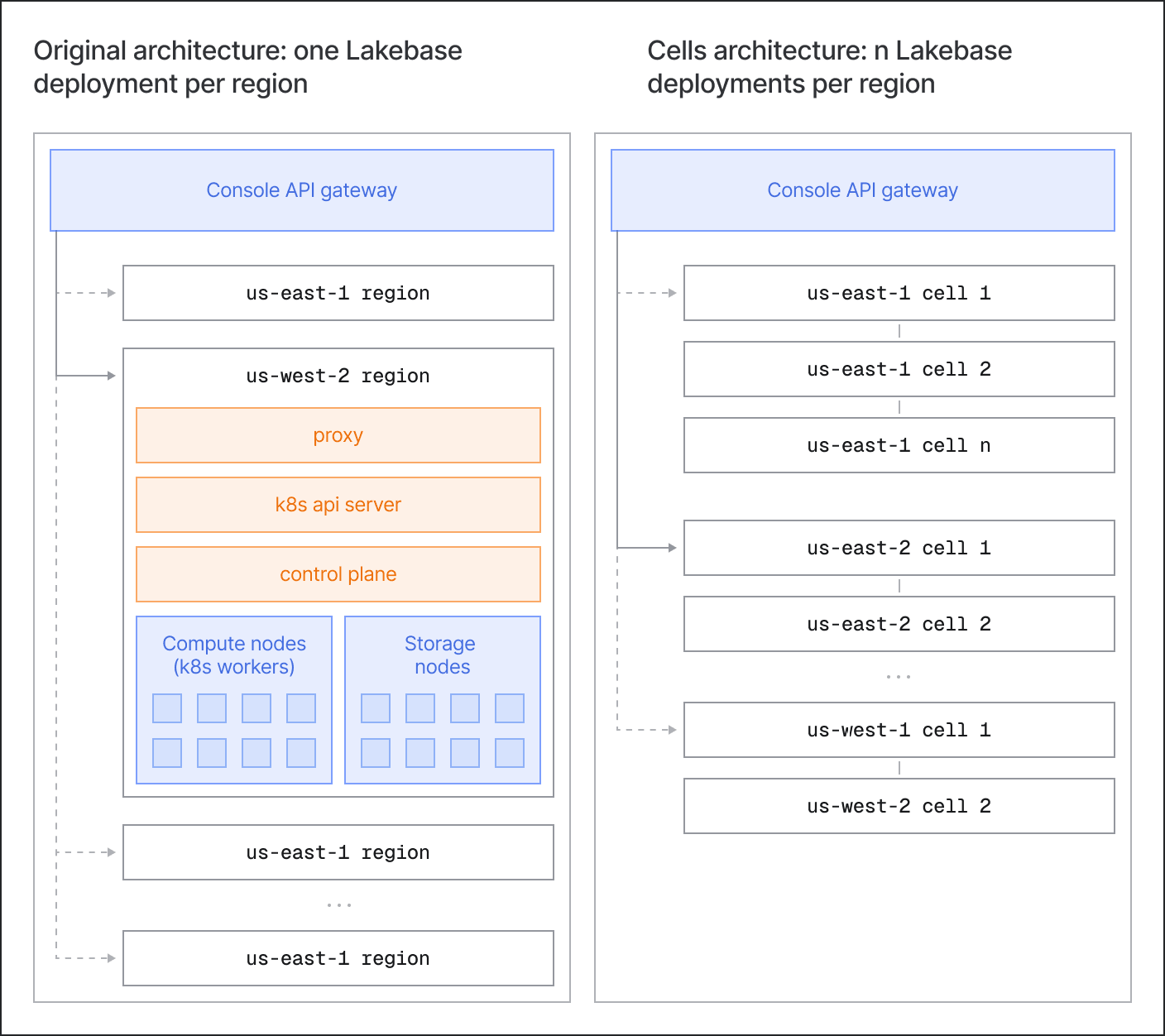
Dies hilft auf zwei Arten:
- Skalierung: Um eine Region zu vergrößern, fügen wir eine weitere Zelle hinzu. Wenn eine bestehende Zelle die Skalierungsgrenzen von Kubernetes und der Steuerungsebene erreicht, wird die Erstellung neuer Projekte an eine neu bereitgestellte Zelle weitergeleitet. Zellen werden bei wachsender Nachfrage schnell hochgefahren.
- Begrenzung des Ausfallradius: Selbst bei gründlichen Tests und integrierten Schutzmaßnahmen gehen in der Produktion immer wieder Dinge schief – Probleme mit der Kubernetes-Steuerungsebene/Systemdiensten, Code- oder Konfigurationsregressionen, DoS-Situationen usw. Die Zellengrenze isoliert Fehler und verhindert, dass sich die Situation ausbreitet, sodass die anderen Zellen in der Region normal weiter Datenverkehr bedienen können.
Zusammen ermöglicht dies unserer Plattform, eine Region elastisch zu skalieren und gleichzeitig den Ausfallradius eines einzelnen Fehlers zu begrenzen. Während eines Vorfalls am 8. Mai 2026, als AWS Probleme mit einer Verfügbarkeitszone in us-east-1 hatte, hatte eine der Zellen Probleme beim Failover auf gesunde Knoten. Die Auswirkungen beschränkten sich auf diese Zelle. Die anderen sieben Zellen in der Region haben korrekt ein Failover durchgeführt, sodass der Vorfall nur etwa 13 % der Datenbanken in der Region betraf. In diesem Fall reduzierte die zellenbasierte Architektur die Auswirkungen um etwa eine Größenordnung.
Fehlersimulation und -injektion
Redundanzarchitekturen und -prinzipien sind nicht viel wert, wenn sie in der Praxis nicht funktionieren. Man kann jeden möglichen Fehlermodus durchdenken, aber das Murphy's Law ist lebendig und gut, und komplexe Systeme finden immer einen Weg, Sie zu überraschen. Jede Lakebase-Version durchläuft vor der Produktion Fehlereinspeisung und Chaos-Tests. Wir stellen die Version auf einem echten Cluster bereit, treiben sie mit einer Mischung aus agentenbasierten und nicht-agentenbasierten OLTP- und OLAP-Workloads mit konstanter Auslastung an und beginnen dann, Dinge darunter kaputt zu machen. Wir beenden Prozesse, schalten Knoten ab, verursachen Netzwerkausfälle, löschen Festplatteninhalte und starten Komponenten in Schleifen neu, während die Workloads weiterlaufen. Wir verwenden Failpoints großzügig in unserem Code, um schwer reproduzierbare Fehler einzuschleusen, wie z. B. einen Absturz zur ungünstigsten Zeit. Dies wird von einem internen Framework zur Fehlerinjektion gesteuert, das auf einen einzelnen Prozess abzielen oder zellenweite Fehler über eine ganze Zelle hinweg koordinieren kann.
Unsere Bestehensquote ist strenger als "der Test hat keinen Fehler gemeldet". Wir verwenden Open-Source-Tools wie SqlLancer und SqlSmith sowie ähnliche interne Tools, um das korrekte Verhalten von Postgres zu überprüfen. Während die Fehlereinspeisung läuft, validieren wir die interne Datenkonsistenz, dass keine bestätigte Transaktion verloren geht und dass jede Komponente sich selbstständig in einen konsistenten Zustand zurückversetzt.
Wir heben dies nun auf eine neue Ebene, von Komponentenausfällen zu Simulationen des Ausfalls ganzer AZs. In einem echten Cluster mit laufenden Workloads trennen wir programmatisch das Netzwerk einer Verfügbarkeitszone vom Rest des Clusters und beobachten, wie das System reagiert: wie schnell der Speicher auf überlebende Replikate verschoben wird, wie schnell die Rechenleistung auf gesunde AZs umgeschaltet wird, wie die Proxy-Schicht Verbindungen umleitet und wie lange eine einzelne Datenbank einen Ausfall erlebt. Unser Ziel ist, dass kein Workload länger als 30 Sekunden ausfällt.
Messen, messen, messen
Lord Kelvin sagte: „Wenn man es nicht messen kann, ist es keine Wissenschaft“. Wir verkörpern dasselbe und machen die Messung von Verfügbarkeit und Zuverlässigkeit zu einer Wissenschaft. Die für den Benutzer sichtbare Statusanzeige, die Sie unter https://neonstatus.com/ sehen, ist eine High-Level-Ansicht. Intern messen wir Service Level Indicators (SLIs) und legen Ziele (SLOs) für alle Systemkomponenten und wichtigen Vorgänge fest, insbesondere für benutzerseitige. Wir messen zum Beispiel:
- Datenbankverfügbarkeit: Wie viel Prozent der Zeit jede einzelne Datenbank verfügbar ist. Wir messen nicht nur die aggregierte Flottenverfügbarkeit, denn ein einzelner Kunde kümmert sich nicht darum, ob die Flotte eine hohe Verfügbarkeit hatte, wenn seine Datenbank ausgefallen war.
- Datenbankstartzeit: Wie schnell eine pausierte Datenbank verfügbar ist, wenn Sie sich verbinden, oder wie schnell eine brandneue Datenbank startet.
- Datenbank-Switchover/Failover: Häufigkeit und Latenz. So selten wie möglich und so schnell wie möglich, wenn es passiert.
- Speicher: Verfügbarkeit und Latenz von Seitenlesevorgängen und dauerhaften Schreibvorgängen von Postgres in den Speicher. Diese sagen uns, ob Ihre Workloads das bekommen, was sie brauchen.
- Steuerungsebenen-APIs: Erfolgsraten und Latenz wichtiger Vorgänge wie Branching.
Unser Ziel ist, dass jede Datenbank jeden Monat eine Verfügbarkeit von über 99,99 % erreicht. Wir messen, wie nah wir diesem Ziel sind, mit Erreichung: Wie viel Prozent der Datenbanken der Flotte das Ziel erreicht haben. Unten sehen Sie die Verfügbarkeitserreichung von Neon für monatlich aktive Datenbanken im Jahr 2026.
Monat | Datenbanken erreichten 99,95 % | Datenbanken erreichten 99,99 % |
2026-01 | 99,96 % | 99,85 % |
2026-02 | 99,95 % | 99,84 % |
2026-03 | 99,96 % | 99,81 % |
2026-04 | 99,93 % | 99,75 % |
Erstklassige Zuverlässigkeit und Verfügbarkeit sind für operative Systeme von größter Bedeutung. Wir arbeiten hart daran, Ihr Vertrauen in unseren Datenbankdienst aufzubauen.
Das Team
Die oben genannten Zuverlässigkeitsarbeiten werden von Personen vorangetrieben, die Karrieren im Aufbau und Betrieb von relationalen Datenbanken hinter sich haben. Einige von ihnen:
- Jasraj Dange - Engineering-Leiter für Lakebase, leitete zuvor die Arbeiten an der Leistung und Skalierbarkeit von Azure SQL Database und machte Azure SQL Database zu einer robusten Plattform für Anwendungen.
- Hans Norheim - Konzentriert sich auf die Verfügbarkeit und Zuverlässigkeit von Lakebase, verbrachte 13 Jahre bei Microsoft mit SQL Server und Azure SQL Database, einschließlich der Hot-Patching-Technologie, die es SQL Server ermöglicht, ohne Ausfallzeit aktualisiert zu werden, und der Upgrade-Orchestrierung, die Azure SQL Database seine 99,995 % Uptime-SLA einhält.
- Stas Kelvich - Arbeitet jetzt an Lakebase, nachdem er Neon mitbegründet hat. Vor Neon arbeitete er fünf Jahre an den Interna von Postgres bei Postgres Professional, einschließlich fehlertoleranter Multi-Master-Replikation mit Quorum-Commit, Cross-Node-Snapshot-Isolation mit lose synchronisierten Uhren und Verbesserungen an Two-Phase Commit und logischer Replikation.
- John Spray - Leiter von Lakebase Storage. Leitete zuvor Storage- und Compute-Arbeiten, die wichtige Verbesserungen für die Skalierung wie Sharding vorantrieben. Davor arbeitete er an verteilten Speicher- und Systemlösungen bei Redpanda, Red Hat (Ceph) und Intel.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.