Wie Superhuman und Databricks gemeinsam eine Inferenzplattform mit 200.000 QPS aufgebaut haben
Ingenieure von Superhuman und Databricks berichten, wie sie gemeinsam Rechtschreib- und Grammatikkorrektur-Workloads auf die Databricks Model Serving Platform migriert haben, die über 200.000 QPS mit 60% Durchsatzsteigerung und Latenzen unter einer...
von Christoph Stüber, Wai Wu, Arjun DCunha, Amine El Helou, Tian Ouyang und Alex Coleman
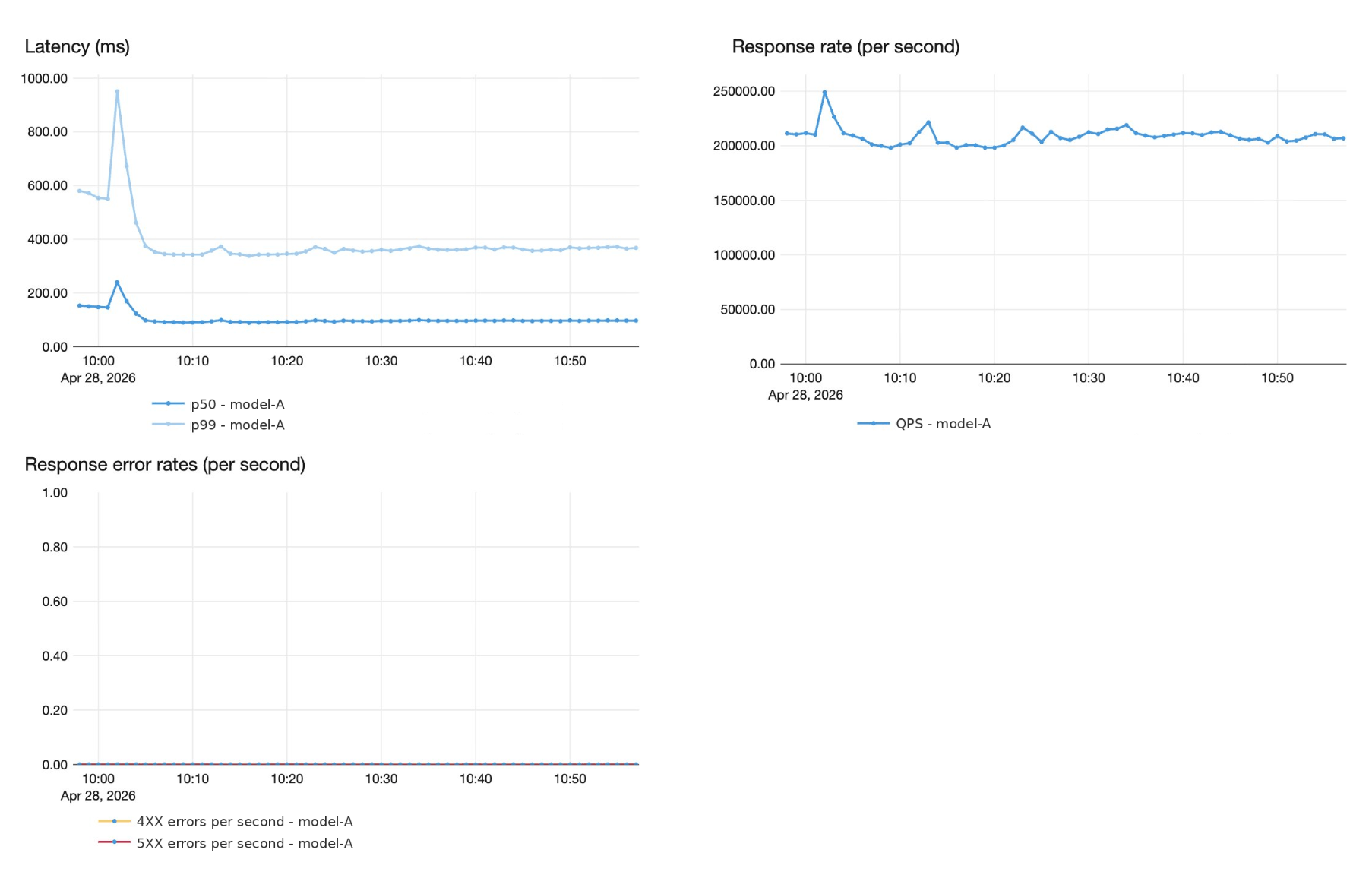
- Superhuman migrierte von einem selbstgebauten vLLM-Stack zu Databricks FMAPI Provisioned Throughput und bedient nun ein benutzerdefiniertes LLM mit über 200.000 QPS und Latenzen unter einer Sekunde (P99). Dies ermöglichte dem Superhuman-Ingenieurteam, sich auf die Entwicklung und Verbesserung seines Produkts zu konzentrieren, während die Databricks Platform für Skalierung und Infrastruktur zuständig war.
- Gemeinsame technische Optimierungen lieferten eine 60%ige Durchsatzsteigerung pro GPU (750 → 1.200 QPS pro H100-Pod) und reduzierten die Serving-Kosten durch FP8-Quantisierung, Eliminierung von CPU-seitigem Overhead und Optimierung von Attention-Kernels auf der Hopper-Architektur, alles ohne Qualitätsverluste.
- Databricks FMAPI skaliert zuverlässig auf über 250 GPUs durch produktionsreife Lastverteilung, Autoscaling und schnelles Container-Starten; mit Pre-Production-Ramp-Stresstests, die sicherstellen, dass p99-Verfügbarkeits- und Latenzziele erfüllt werden, bevor der Traffic die Produktion erreicht.
Von Analytics-Partnern zu Echtzeit-Inferenz-Partnern
Superhuman, die Produktivitätsplattform, die Superhuman, Coda, Superhuman Mail und Superhuman Go umfasst, bedient über 40 Millionen tägliche Nutzer in Dutzenden von Sprachen. Die KI-gestützte Kommunikationshilfe von Superhuman bietet Echtzeit-Vorschläge für Korrektheit, Klarheit, Tonfall und Stil in allen Bereichen, in denen Menschen schreiben.
Databricks und Superhuman sind seit Jahren Partner. Das Superhuman-Team nutzt die Databricks Data Intelligence Platform traditionell als Grundlage für Analysen. Aber Analysen waren nur die halbe Miete.
Hinter vielen der Echtzeit-Vorschläge von Superhuman verbirgt sich ein hochentwickeltes, benutzerdefiniertes KI-Modell, das in massivem Umfang bereitgestellt wird. Superhuman betreibt dieses Modell bei Spitzenlasten von über 200.000 Anfragen pro Sekunde, mit einer End-to-End-Latenz von unter 1 Sekunde bei P99 und strengen 4 Neuner-Zuverlässigkeitsgarantien. Superhuman modernisierte seinen Serving-Stack für große Sprachmodelle durch die Nutzung des Databricks Model Serving, was eine neue Art der Partnerschaft erforderte, die auf gemeinsamer Produkt- und Ingenieursarbeit basiert.
Wie Superhuman seinen Serving-Stack modernisierte
Vor dieser Migration betrieb Superhuman einen DIY-Serving-Stack, der auf vLLM basierte, zusammen mit internen Tools für Training und Modellmanagement. Ein internes ML-Infrastrukturteam pflegte diesen Stack, der eine massive Skalierung unterstützte, aber mehrere Schmerzpunkte verstärkten sich bei der Bereitstellung großer Sprachmodelle.
Das benutzerdefinierte große Sprachmodell ermöglicht die Korrektur grammatikalischer Fehler in enormem Umfang, 200.000+ QPS Spitzenlast mit etwa 50 Eingabe-Tokens und 50 Ausgabe-Tokens pro Anfrage. Es stieß an die Grenzen dessen, was der L40S-GPUs-basierte Stack leisten konnte. Jede neue Iteration des Modells erforderte monatelanges manuelles Performance-Tuning für die Inbetriebnahme. In der Zwischenzeit wuchs die operative Belastung, wobei Kapazitätsplanung, Performance-Tuning und Autoscaling Zeit von einem schlanken Team beanspruchten, das sich auf Modellqualität und Produktinnovationen konzentrieren musste.
Superhuman benötigte einen Plattformpartner, der sich zu Performance- und Latenz-SLAs für den Serving-Stack verpflichten und in die dafür erforderliche Ingenieursleistung investieren würde. Beide Teams definierten im Voraus Ziel-SLOs für die Echtzeit-Latenz: Latenz unter einer Sekunde bei p99 und keine Qualitätsregression bei den internen Evaluations-Frameworks von Superhuman.
Echtzeit-SLAs auf Plattforminfrastruktur erfüllen
Das Erreichen von Latenzzielen auf einem einzelnen Pod ist notwendig, aber nicht ausreichend. Die zuverlässige Bereitstellung von über 200.000 QPS erfordert eine Infrastruktur, die Lasten ausgleichen, dynamisch skalieren und Spitzen abfedern kann. Dies richtig hinzubekommen, erforderte eine enge Zusammenarbeit beider Teams.
Optimierung des Load Balancings: Power-of-Two-Choices
Der Traffic des Grammatikkorrektur-Endpunkts von Superhuman weist starke tägliche Muster mit schnellen Anstiegen in bestimmten Perioden auf, die oft 200.000 QPS übersteigen. Während der Standard-Kubernetes-Round-Robin-Load-Balancer bei niedrigen QPS ausreichend ist, zeigten unsere Tests, dass sich die Leistung bei höheren QPS verschlechtert, wobei eine ungleichmäßige Anforderungsverteilung zu Hotspots führt, die die Tail-Latenz erhöhen.
Im Kern unseres Ansatzes steht der Endpoint Discovery Service (EDS) – eine leichtgewichtige Steuerungsebene, die die Kubernetes-API kontinuierlich auf Änderungen an Services und EndpointSlices überwacht. EDS steuert einen benutzerdefinierten Load-Balancing-Algorithmus, der auf dem Prinzip der zwei zufälligen Auswahlmöglichkeiten (Power of Two Choices) basiert (Zitat). Für jede Anfrage werden zwei Kandidaten-Pods abgetastet und der Traffic wird an denjenigen geleitet, der weniger aktive Anfragen hat, wodurch die Hotspots vermieden werden, die Round-Robin bei hohen QPS erzeugt (siehe Blog).
Um die Plattform für variable Traffic-Muster kosteneffizient zu halten, skaliert das System dynamisch mit der Kundennachfrage. Der Autoscaler verfolgt die request_concurrency, gemittelt über die Pods, wobei pro Pod abgeleitete Concurrency-Ziele aus dem Benchmarking der maximal nachhaltigen RPS pro Replikat stammen. Die Skalierungsstrategie ist bewusst asymmetrisch: Scale-up ist aggressiv und reaktiv, während Scale-down konservativ ist, um das Flattern zu verhindern, das Latenzspitzen verursacht. Durch gemeinsames Shadow-Testing zwischen Superhuman und Databricks haben wir Edge Cases erkannt und Probleme bei der Abstimmung von Parametern des Autoscalers behoben, einschließlich der Frage, wann aggressiv skaliert werden soll, wann stabil gehalten werden soll und wie konservativ beim Scale-down vorgegangen werden soll.
Optimierung des Container-Starts durch Image-Beschleunigung
Wenn der Traffic des Superhuman-Endpunkts von der Spitzenlast zur Spitzenlast ansteigt, muss der Autoscaler Dutzende von Pods hinzufügen. Wenn jeder Pod Minuten zum Herunterladen seines Container-Images und zum Starten benötigt, erleben die Nutzer Latenzspitzen während des Anstiegs. Eine Verkürzung der Pod-Startzeit führt direkt zu schnellerem Scale-up und reibungsloserer Latenz während Traffic-Spitzen.
Das Databricks Model Serving Team übernahm die Image-Beschleunigungsarbeit, die ursprünglich für Serverless Compute entwickelt wurde (Blog), um Kaltstarts zu vermeiden. Der Ansatz passt gut für die relativ kleinen Modelle, die wir für Superhuman bereitgestellt haben.
Beim Erstellen eines Container-Images fügen wir einen zusätzlichen Schritt hinzu, um das Standard-Image-Format auf Gzip-Basis in das Block-Device-basierte Format umzuwandeln, das für Lazy Loading geeignet ist. Dies ermöglicht es, das Container-Image in der Produktion als durchsuchbares Block-Device mit 4-MB-Sektoren darzustellen.
Beim Herunterladen von Container-Images ruft unsere angepasste Container-Laufzeitumgebung nur die Metadaten ab, die zum Einrichten des Root-Verzeichnisses des Containers erforderlich sind, einschließlich Verzeichnisstruktur, Dateinamen und Berechtigungen, und erstellt entsprechend ein virtuelles Block-Device. Anschließend wird das virtuelle Block-Device in den Container eingehängt, sodass die Anwendung sofort mit der Ausführung beginnen kann.
Wenn die Anwendung zum ersten Mal eine Datei liest, löst die I/O-Anfrage an das virtuelle Block-Device einen Callback an den Image-Fetcher-Prozess aus, der den tatsächlichen Blockinhalt aus dem Remote-Container-Registry abruft. Der abgerufene Blockinhalt wird auch lokal zwischengespeichert, um wiederholte Netzwerkanfragen an die Container-Registry zu vermeiden und die Auswirkungen variabler Netzwerklatenz auf zukünftige Lesevorgänge zu reduzieren.
Dieses Lazy-Loading-Container-Dateisystem eliminiert die Notwendigkeit, das gesamte Container-Image herunterzuladen, bevor die Anwendung gestartet wird, und reduziert die Startzeit des Containers von mehreren Minuten auf nur wenige Sekunden.
Laufzeitoptimierungen: 60 % mehr Durchsatz pro Pod
Da die Plattformschicht die Flotten-Skalierung übernimmt, war die nächste Frage, wie viele QPS jeder Pod unterstützen könnte und zu welchem Preis.
In diesem Abschnitt stellen wir die Optimierungen vor, die den Durchsatz pro Pod von 750 QPS auf 1.200 QPS auf H100 GPUs erhöhten, eine Verbesserung von 60 %, während gleichzeitig keine Qualitätsregressionen auftraten.
FP8-Quantisierung
Die FP8-Quantisierung war die größte einzelne Durchsatzverbesserung und erzielte eine Steigerung des QPS pro Pod um bis zu 30 %.
Das ML-Team von Superhuman hat den Checkpoint mit der Online-Quantisierungsbibliothek von vLLM zu FP8 vorquantisiert und einen komprimierten Tensorformat-Checkpoint erstellt, den Databricks für die Bereitstellung geladen hat. In der endgültigen Konfiguration liefen die Aufmerksamkeits-Projektionen (Q, K, V und Ausgabe) und die MLP-Projektionen alle über den FP8-Pfad, während die KV-Cache-Quantisierung deaktiviert blieb, da die Gewichtsquantisierung die Durchsatzgewinne brachte und die KV-Cache-Quantisierung eigene Qualitätskompromisse mit sich brachte, die sich für diese Workload nicht lohnten.
Bevor wir uns auf die endgültige Konfiguration einigten, haben beide Teams iterativ festgelegt, welche Schichten quantisiert werden sollten. MLP-Projektionen wurden von Anfang an quantisiert, und die offene Frage war, ob die Aufmerksamkeits-Schichten quantisiert werden sollten. Databricks Model Serving hatte die Serving-Engine von Anfang an so konzipiert, dass sie Inferenz mit gemischter Präzision unterstützt, sodass wir, wenn eine Schichtgruppe unter Quantisierung zu qualitätssensibel war, sie in höherer Präzision belassen konnten, ohne die Gesamtarchitektur des Servings zu ändern. Wir haben ein Flag bereitgestellt, mit dem wir die Aufmerksamkeits-Quantisierung ein- und ausschalten konnten, damit beide Teams deren Auswirkungen direkt messen konnten. Das Experiment verlief reibungslos, die Quantisierung der Q/K/V- und Ausgabe-Projektionen führte zu keiner messbaren Qualitätsverschlechterung bei den Auswertungen von Superhuman.
Die andere Überlegung war die Quantisierungsgranularität. Standard-Kernel verwenden eine pro-Tensor-Skalierung (ein einzelner FP8-Skalierungsfaktor für einen gesamten Gewichts-Tensor). Databricks-Kernel verwenden eine pro-Kanal-Skalierung, bei der für jeden Ausgabekanal einer linearen Schicht ein separater Skalierungsfaktor berechnet wird. Dies bewahrt den Dynamikbereich, wo er wichtig ist, und hält den Quantisierungsfehler der MLP-Schicht weit unter dem Schwellenwert, bei dem er in den Auswertungen sichtbar wird. In Kombination mit Kernel-Verbesserungen erreichte die pro-Kanal-Quantisierung die gleichen oder bessere Ergebnisse als andere Open-Source-Baselines bei gleichem Durchsatz.
Eliminierung von CPU-seitigen Engpässen
Bei kleinen, schnellen Modellen wird die Leistung oft durch die CPU – nicht durch die GPU – begrenzt. Das Databricks-Team hatte bereits die Beseitigung von CPU-Engpässen in seiner Arbeit zur schnellen PEFT-Bereitstellung untersucht und hier ähnliche CPU-Optimierungen direkt auf die Workload von Superhuman angewendet.
Insbesondere führte das Team einen Multiprocessing-Runtime-Server ein. Für die meisten Model-Serving-Workloads ist ein einzelner Prozess schnell genug, um die GPU gesättigt zu halten, da die GPU der Engpass ist, nicht die CPU. Aber bei einem kleinen, schnellen Modell schließt die GPU ihren Forward-Pass schneller ab, als ein einzelner Prozess den nächsten Batch vorbereiten kann, wodurch der Engpass zur CPU verlagert wird.
Das Team löste dieses Problem, indem es mehrere RPC-Serverprozesse ausführte. Durch die parallele Vorbereitung und Verteilung von Arbeiten an die GPU durch mehrere CPU-Prozesse eliminierten wir den Serialisierungs-Engpass eines einzelnen Prozesses. Dies führte zu einem weiteren Durchsatz von 20 %.
Andere Optimierungen auf der CPU-Seite verbesserten die Leistung um einige Prozentpunkte.
- Reduzierter Python-Overhead. Wir ersetzten das Slicing, Kopieren und Füllen von Tensoren auf Python-Ebene zu Beginn jedes CUDA-Graph-Dekodierungsschritts durch einen einzigen C++-Aufruf. Wir untersuchten auch parallele Strategien (ThreadPool, OpenMP), aber Single-Threaded C++ war aufgrund des CUDA-Synchronisations-Overheads optimal. Dies reduzierte die GPU-Leerlaufzeit pro Forward-Pass geringfügig.
- Asynchrone Planung für bessere CPU-GPU-Arbeitsüberlappung. Wir haben die CPU-seitige Nachverarbeitung aus dem kritischen Pfad entfernt, sodass sie parallel zum nächsten GPU-Forward-Pass ausgeführt wird. Anstatt die gesamte Nachverarbeitung für Batch N abzuschließen, bevor Batch N+1 gestartet wird, gibt der Scheduler N+1 sofort frei und verarbeitet die Nachverarbeitung von N parallel. Die Nachverarbeitung iteriert auch nur über die relevante Teilmenge der Anfragen und nicht über den gesamten Batch. Dies führte dazu, dass der nächste Forward-Pass früher begann.
Wie geht es weiter
Diese Arbeit ist die Grundlage für eine breitere Partnerschaft. Superhuman migriert nun zusätzliche Modelle zu Databricks, die verschiedene Modellgrößen, Aufgabentypen und Latenzanforderungen umfassen – und übernimmt die AI Platform breiter für Trainingsworkflows, Experimentenverfolgung, Evaluierungen (klassische ML, Deep-Learning und Generative AI/Agents), Modell- und (LLM-)Judge-Registry sowie die Aufnahme von Agent-Traces im großen Maßstab.
Der Aufbau dieser groß angelegten Plattform war eine unternehmensweite Anstrengung auf beiden Seiten und eine außergewöhnliche Lernerfahrung. Ein großes Dankeschön an die ML- und Infrastrukturteams von Superhuman für die enge Zusammenarbeit, die Bereitschaft, offene Kompromisse einzugehen, und die Strenge, die sie in jede Qualitätsstufe und jeden Lasttest eingebracht haben. Das gemeinsam entwickelte Engineering-Playbook gehört ihnen genauso wie uns, und wir freuen uns darauf, jedem nachfolgenden Workload die gleiche Partnerschaft entgegenzubringen.
Wichtige Erkenntnisse
Die Nutzung eines verwalteten Inferenzdienstes muss nicht bedeuten, die Kontrolle aufzugeben. Superhuman behält die volle Kontrolle über Modelltraining, Quantisierung und Qualitätsstandards, während Databricks die Laufzeitleistung und Plattformzuverlässigkeit aufrechterhält. Diese Aufgabenteilung funktioniert gut mit gemeinsamen SLOs, gemeinsamer Qualitätsvalidierung und schrittweisem Lasttesting bei der Onboarding auf die Databricks-Plattform.
Sind Sie bereit, Ihre benutzerdefinierten Modelle im großen Maßstab bereitzustellen? Erfahren Sie, wie die Databricks Foundation Model API Ihre anspruchsvollsten Inferenz-SLAs erfüllen kann – und Ihrem Team einen echten Engineering-Partner bietet, nicht nur einen verwalteten Dienst. Kontaktieren Sie uns unter https://www.databricks.com/company/contact, um Ihren High-QPS-Modellbereitstellungs-Use Case zu onboarden.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.