Wie wir mit KI bei Databricks Tausende von Datenbanken debuggen
Erkenntnisse aus dem Aufbau einer KI-gestützten Plattform zur Fehlersuche in Datenbanken
von Annie Zhou, Madhav Ramesh und A Kishore Kumar
- Bei Databricks betreiben wir Tausende von OLTP-Instanzen in Hunderten von Regionen auf AWS, Azure und GCP.
- Wir haben eine agentenbasierte Plattform entwickelt, die Metriken, Tools und Fachwissen vereint, um unseren Ingenieuren die Verwaltung ihrer Datenbanken in diesem Umfang zu erleichtern.
- Diese agentenbasierte Plattform wird jetzt unternehmensweit eingesetzt und reduziert die Fehlersuchezeit um bis zu 90 % und die Einarbeitungszeit für den Betrieb unserer Infrastruktur.
Bei Databricks haben wir manuelle Datenbankoperationen durch KI ersetzt und die Zeit für die Fehlersuche um bis zu 90 % reduziert.
Unser KI-Agent interpretiert, führt aus und debuggt, indem er wichtige Metriken und Protokolle abruft und Signale automatisch korreliert. Er arbeitet über eine Flotte von Datenbanken, die auf allen wichtigen Clouds und in nahezu jeder Cloud-Region bereitgestellt werden.
Diese neue agentenbasierte Funktionalität hat es Ingenieuren ermöglicht, routinemäßig Fragen in natürlicher Sprache zu ihrem Dienstzustand und ihrer Leistung zu beantworten, ohne sich an Bereitschaftsingenieure in den Speicherungsteams wenden zu müssen.
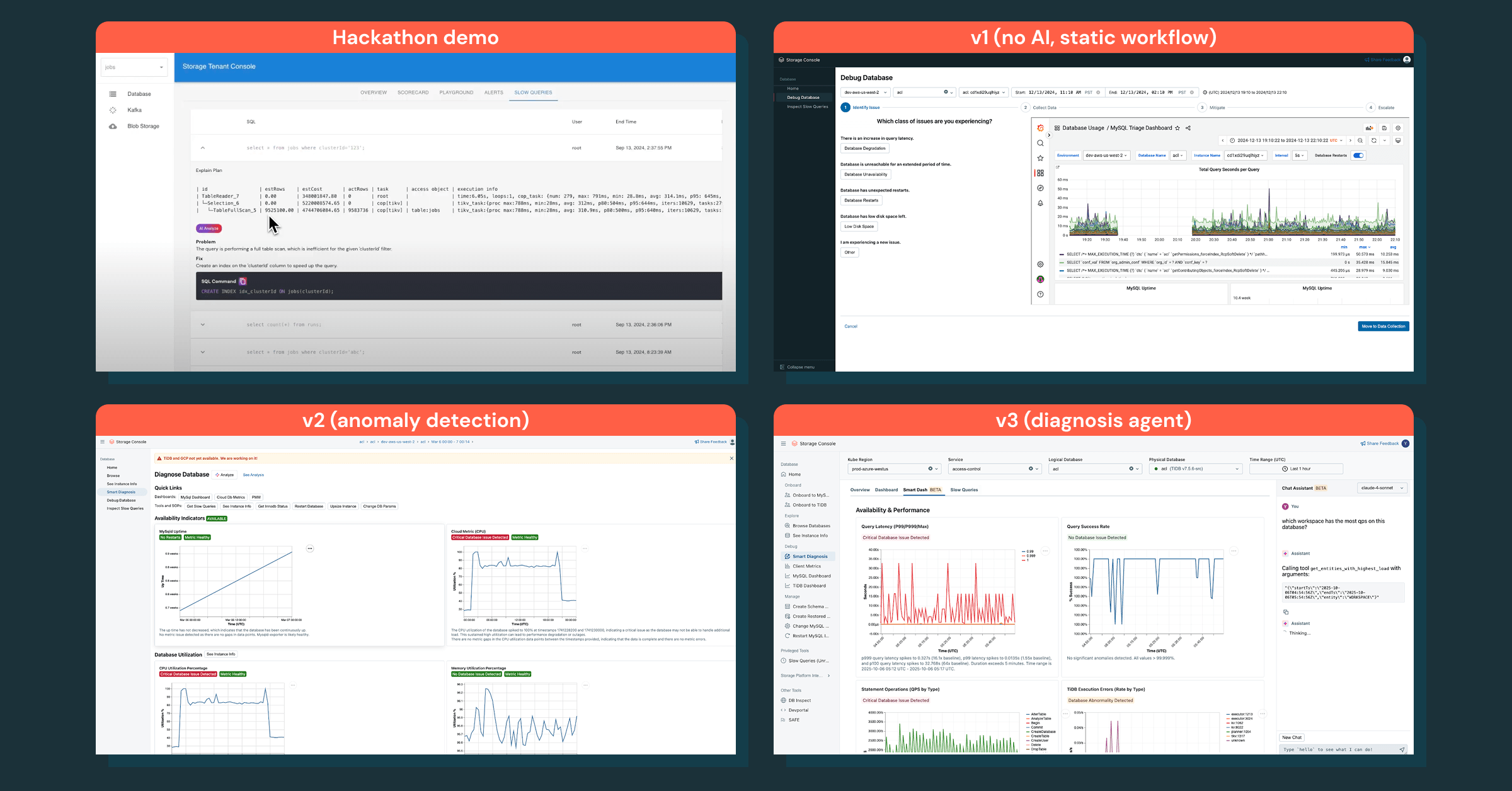
Was als kleines Hackathon-Projekt zur Vereinfachung des Untersuchungsworkflows begann, hat sich zu einer intelligenten Plattform mit unternehmensweiter Akzeptanz entwickelt. Dies ist unsere Reise.
Vor KI: Alles funktionierte, aber nichts funktionierte zusammen
Während einer typischen MySQL-Vorfalluntersuchung würde ein Ingenieur oft
- Metriken in Grafana überprüfen
- Zu einem Databricks-Dashboard wechseln, um die Client-Workload zu verstehen
- CLI-Befehle ausführen, um den InnoDB-Status zu inspizieren, eine Momentaufnahme des internen MySQL-Zustands, die Informationen wie Transaktionsverlauf, E/A-Operationen und Deadlock-Details enthält
- Sich in eine Cloud-Konsole einloggen, um langsame Abfrageprotokolle herunterzuladen
Jedes Werkzeug funktionierte für sich genommen gut, aber zusammen bildeten sie keinen kohäsiven Workflow und lieferten keine End-to-End-Einblicke. Ein erfahrener MySQL-Ingenieur konnte durch das Springen zwischen Tabs und Befehlen in der richtigen Reihenfolge eine Hypothese zusammensetzen; dies verbraucht jedoch wertvolles SLO-Budget und Zeit. Ein neuerer Ingenieur wusste oft nicht, wo er anfangen sollte.
Ironischerweise spiegelte diese Fragmentierung unserer internen Tools genau die Herausforderung wider, bei deren Überwindung Databricks unseren Kunden hilft.
Die Databricks Data Intelligence Platform vereinheitlicht Daten, Governance und KI, sodass autorisierte Benutzer ihre Daten verstehen und darauf reagieren können. Intern benötigen unsere Ingenieure dasselbe: eine vereinheitlichte Plattform, die die Daten und Workflows konsolidiert, die unserer Infrastruktur zugrunde liegen. Mit dieser Grundlage können wir Intelligenz anwenden, indem wir KI nutzen, um die Daten zu interpretieren und die Ingenieure zum nächsten richtigen Schritt zu leiten.
Unsere Reise: Vom Hackathon zu intelligenten Agenten
Wir haben nicht mit einer großen, mehrmonatigen Initiative begonnen. Stattdessen haben wir die Idee während eines unternehmensweiten Hackathons getestet. In zwei Tagen haben wir einen einfachen Prototyp erstellt, der einige Kern-Datenbankmetriken und Dashboards in einer einzigen Ansicht vereinte. Er war nicht ausgefeilt, aber er verbesserte sofort grundlegende Untersuchungsworkflows. Das gab uns unser Leitprinzip vor: Schnell handeln und kundenorientiert bleiben.
Plattformen mit Kundenorientierung aufbauen
Bevor wir weiteren Code schrieben, interviewten wir Serviceteams, um ihre Schmerzpunkte bei der Fehlersuche zu verstehen. Die Themen waren konsistent: Junior-Ingenieure wussten nicht, wo sie anfangen sollten, und Senior-Ingenieure empfanden die Werkzeuge als fragmentiert und umständlich.
Um den Schmerz aus erster Hand zu sehen, begleiteten wir Bereitschaftssitzungen und beobachteten Ingenieure bei der Echtzeit-Fehlersuche. Drei Muster stachen hervor:
- Fragmentierte Werkzeuge
Ingenieure jonglierten mit Dashboards, CLIs und manuellen Schritten für Untersuchungen und Operationen wie Neustarts oder Wiederherstellungen. Jedes Werkzeug funktionierte isoliert, aber der Mangel an Integration machte den Workflow langsam und fehleranfällig. - Zeitverschwendung bei der Kontextbeschaffung
Die meiste Arbeit bestand darin, herauszufinden, was sich geändert hatte, wie „normal“ aussah und wer den richtigen Kontext hatte, um zu helfen, aber nicht darin, den Vorfall tatsächlich zu beheben. - Unklare Anleitung zur sicheren Behebung
Während Vorfällen waren sich Ingenieure oft nicht sicher, welche Maßnahmen sicher oder effektiv waren. Ohne klare Runbooks oder Automatisierung griffen sie auf langwierige Untersuchungen zurück oder warteten auf Experten.
Rückblickend zeigten Postmortems selten diese Lücke auf: Teams mangelte es nicht an Daten oder Werkzeugen; es mangelte ihnen an intelligenter Fehlersuche, um die Flut von Signalen zu interpretieren und sie zu sicheren und effektiven Maßnahmen zu leiten.
Iterativ zur Intelligenz
Wir haben klein angefangen, mit der Datenbankuntersuchung als erstem Anwendungsfall. Unsere v1 war ein statischer agentenbasierter Workflow, der einem SOP zur Fehlersuche folgte, aber er war nicht effektiv – Ingenieure wünschten sich einen Diagnosebericht mit sofortigen Einblicken, keine manuelle Checkliste.
Wir haben unseren Fokus auf die Beschaffung der richtigen Daten und die Schichtung von Intelligenz darauf verlagert. Diese Strategie führte zur Anomalieerkennung, die die richtigen Anomalien aufzeigte, aber immer noch keine klaren nächsten Schritte lieferte.
Der eigentliche Durchbruch kam mit einem Chat-Assistenten, der das Wissen zur Fehlersuche kodifiziert, Folgefragen beantwortet und Untersuchungen in einen interaktiven Prozess verwandelt. Dies veränderte die Art und Weise, wie Ingenieure Vorfälle durchgängig debuggen.
Eine Grundlage: Abstraktion und Zentralisierung
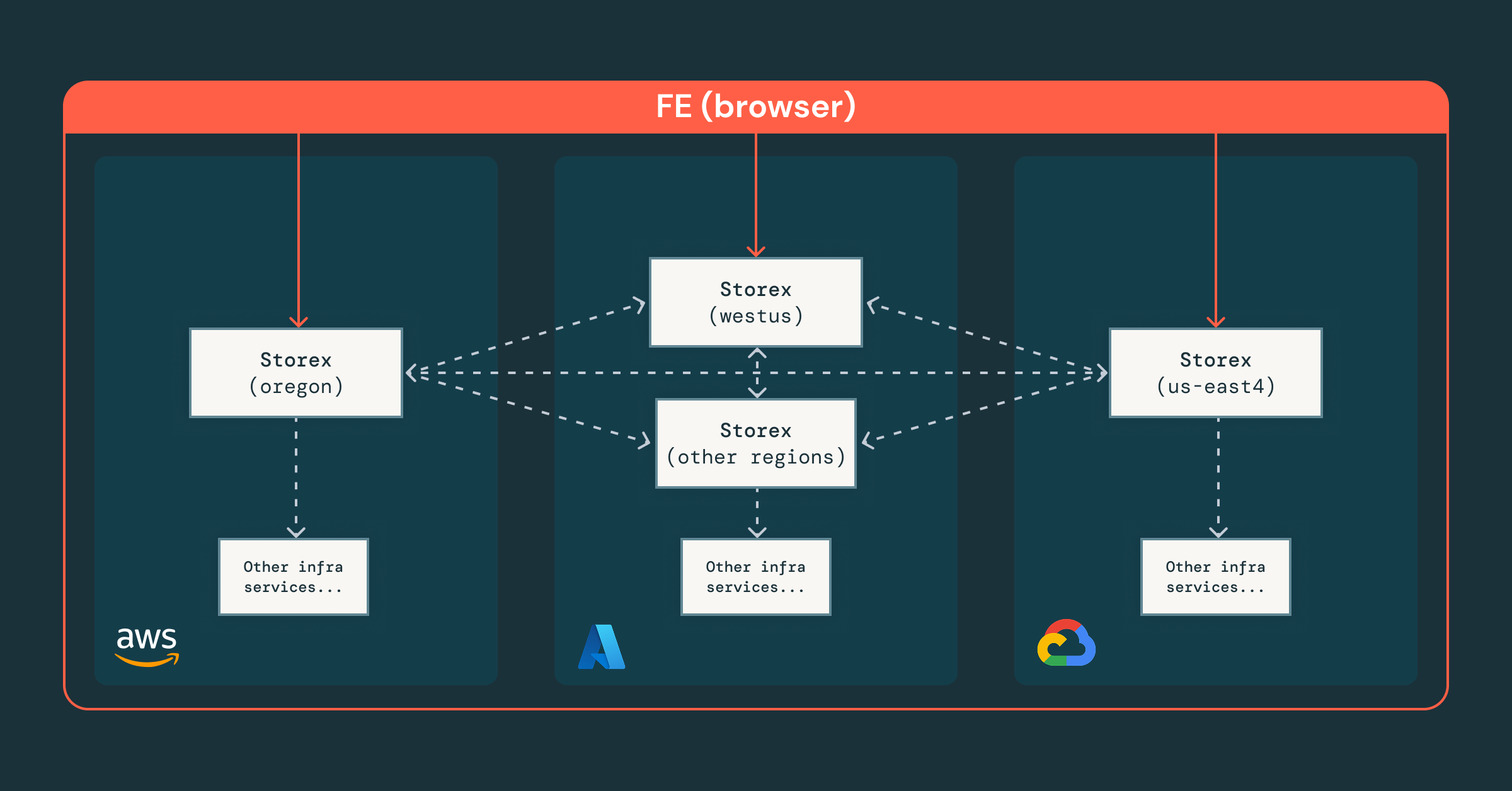
Wenn wir einen Schritt zurücktreten, erkannten wir, dass unser bestehendes Framework zwar Workflows und Daten in einer einzigen Schnittstelle vereinheitlichen konnte, unser Ökosystem aber nicht darauf ausgelegt war, dass KI unsere operative Landschaft analysiert. Jeder Agent müsste regions- und cloudspezifische Logik handhaben. Und ohne zentralisierte Zugriffskontrollen wäre er entweder zu restriktiv, um nützlich zu sein, oder zu permissiv, um sicher zu sein.
Diese Probleme sind bei Databricks besonders schwer zu lösen, da wir Tausende von Datenbankinstanzen in Hunderten von Regionen, acht regulatorischen Domänen und drei Clouds betreiben. Ohne eine solide Grundlage, die Cloud- und regulatorische Unterschiede abstrahiert, würde die KI-Integration schnell auf eine Reihe von unvermeidlichen Hindernissen stoßen:
- Kontextfragmentierung: Debugging-Daten befanden sich an verschiedenen Orten, was es für einen Agenten schwierig machte, ein konsistentes Bild zu erstellen.
- Unklare Governance-Grenzen: Ohne zentralisierte Autorisierung und Durchsetzung von Richtlinien wird es schwierig, sicherzustellen, dass der Agent (und die Ingenieure) innerhalb der richtigen Berechtigungen bleiben.
- Langsame Iterationsschleifen: Inkonsistente Abstraktionen erschweren das Testen und die Weiterentwicklung des KI-Verhaltens, was die Iteration im Laufe der Zeit erheblich verlangsamt.
Um die KI-Entwicklung sicher und skalierbar zu gestalten, haben wir uns darauf konzentriert, die Grundlage der Plattform nach drei Prinzipien zu stärken:
- Central-first Sharded Architecture, bei der eine globale Storex-Instanz regionale Shards koordiniert und eine einzige Schnittstelle bereitstellt, während sensible Daten lokal und konform bleiben.
- Feingranulare Zugriffskontrolle, die auf Team-, Ressourcen- und RPC-Ebene durchgesetzt wird, um sicherzustellen, dass Ingenieure und Agenten sicher innerhalb der richtigen Berechtigungen arbeiten.
- Vereinheitlichte Orchestrierung, bei der unsere Plattform bestehende Infrastrukturdienste integriert und konsistente Abstraktionen über Clouds und Regionen hinweg ermöglicht.
Mit zentralisierten Daten und Kontexten wurde der nächste Schritt klar: Wie konnten wir die Plattform nicht nur vereinheitlicht, sondern auch intelligent machen?
Von der Sichtbarkeit zur Intelligenz
Mit einer vereinheitlichten Grundlage war die Implementierung und Bereitstellung von Funktionen wie dem Abrufen von Datenbankschemata, Metriken oder langsamen Abfrageprotokollen für den KI-Agenten unkompliziert. Innerhalb weniger Wochen bauten wir einen Agenten, der grundlegende Datenbankinformationen aggregieren, analysieren und dem Benutzer zurückgeben konnte.
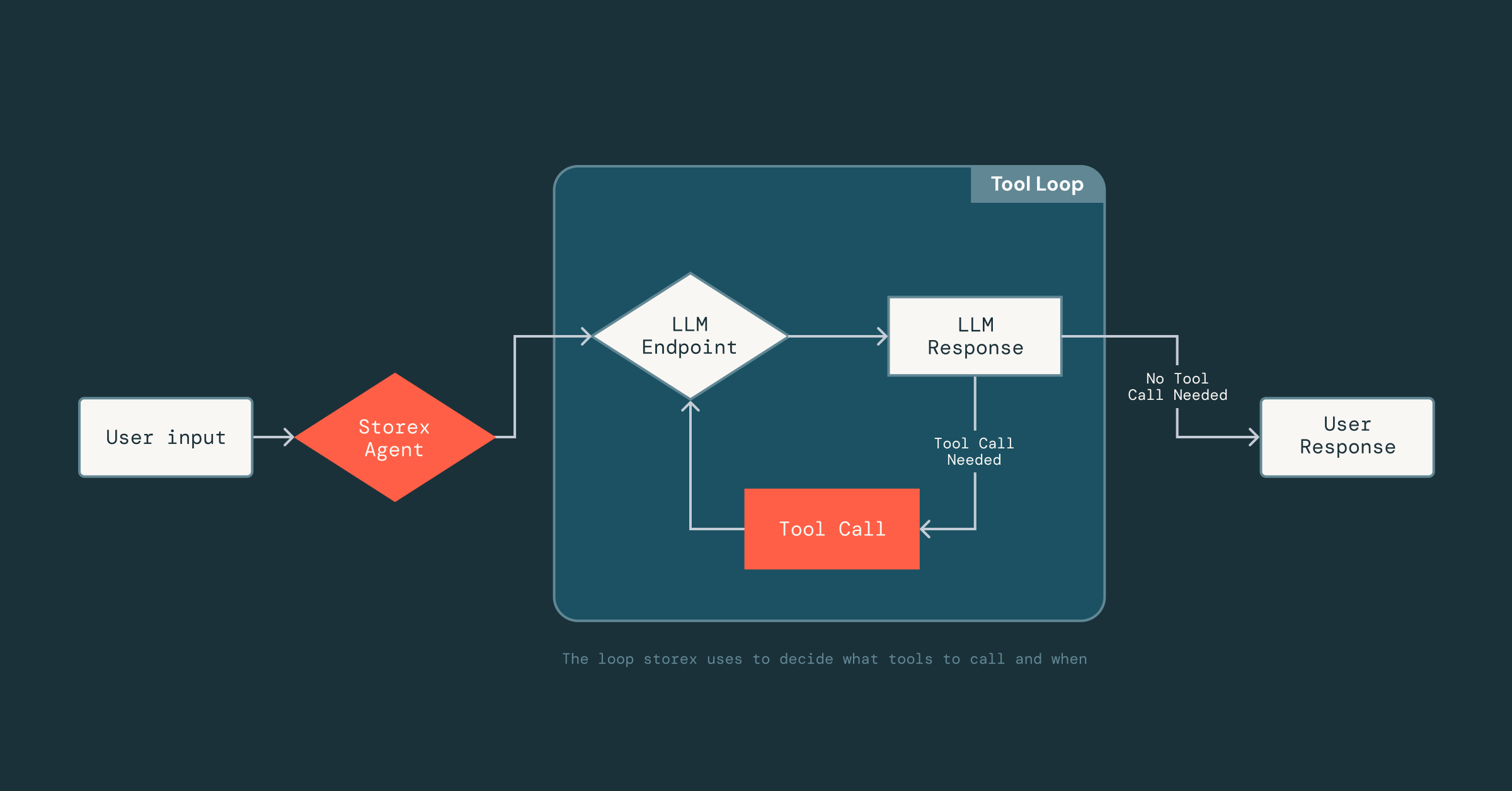
Jetzt war die schwierige Aufgabe, den Agenten zuverlässig zu machen: Da LLMs nicht-deterministisch sind, wussten wir nicht, wie er auf die Werkzeuge, Daten und Prompts reagieren würde, auf die er Zugriff hatte. Um dies richtig zu machen, waren viele Experimente erforderlich, um zu verstehen, welche Werkzeuge effektiv waren und welcher Kontext in die Prompts aufgenommen (oder weggelassen) werden sollte.
Um diese schnelle Iteration zu ermöglichen, haben wir ein leichtgewichtiges Framework entwickelt, das von den Prompt-Optimierungstechnologien von MLflow inspiriert ist und DsPy nutzt, welches die Prompt-Erstellung von der Tool-Implementierung entkoppelt. Ingenieure können Tools als normale Scala-Klassen und Funktionssignaturen definieren und einfach eine kurze Docstring hinzufügen, die das Tool beschreibt. Von dort aus kann das LLM das Eingabeformat, die Ausgabestruktur des Tools ableiten und interpretieren, wie die Ergebnisse zu interpretieren sind. Diese Entkopplung ermöglicht es uns, schnell voranzukommen: Wir können Prompts iterieren oder Tools im Agenten austauschen, ohne die zugrunde liegende Infrastruktur, die das Parsen, die LLM-Verbindungen oder den Konversationsstatus verwaltet, ständig zu ändern.
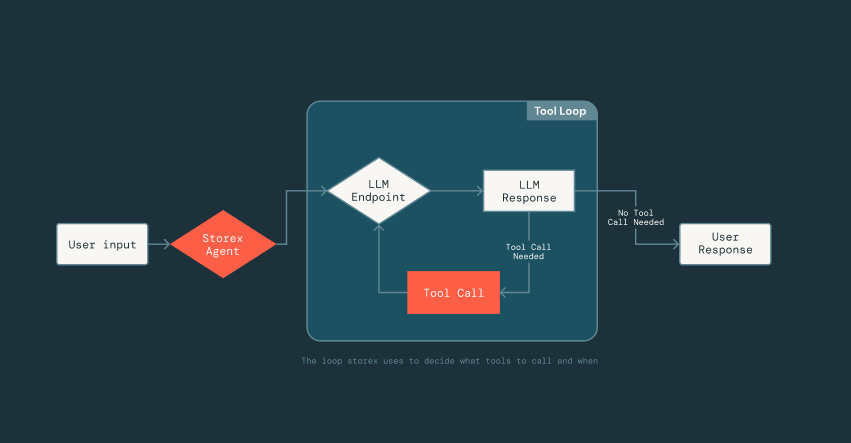{kind=link}
Wie stellen wir während der Iteration sicher, dass der Agent besser wird, ohne Regressionen einzuführen? Um dies zu lösen, haben wir ein Validierungsframework entwickelt, das Snapshots des Produktionszustands erfasst und diese über den Agenten wiedergibt. Dabei wird ein separates „Judge“-LLM verwendet, um die Antworten auf Genauigkeit und Hilfreichkeit zu bewerten, während wir die Prompts und Tools ändern.
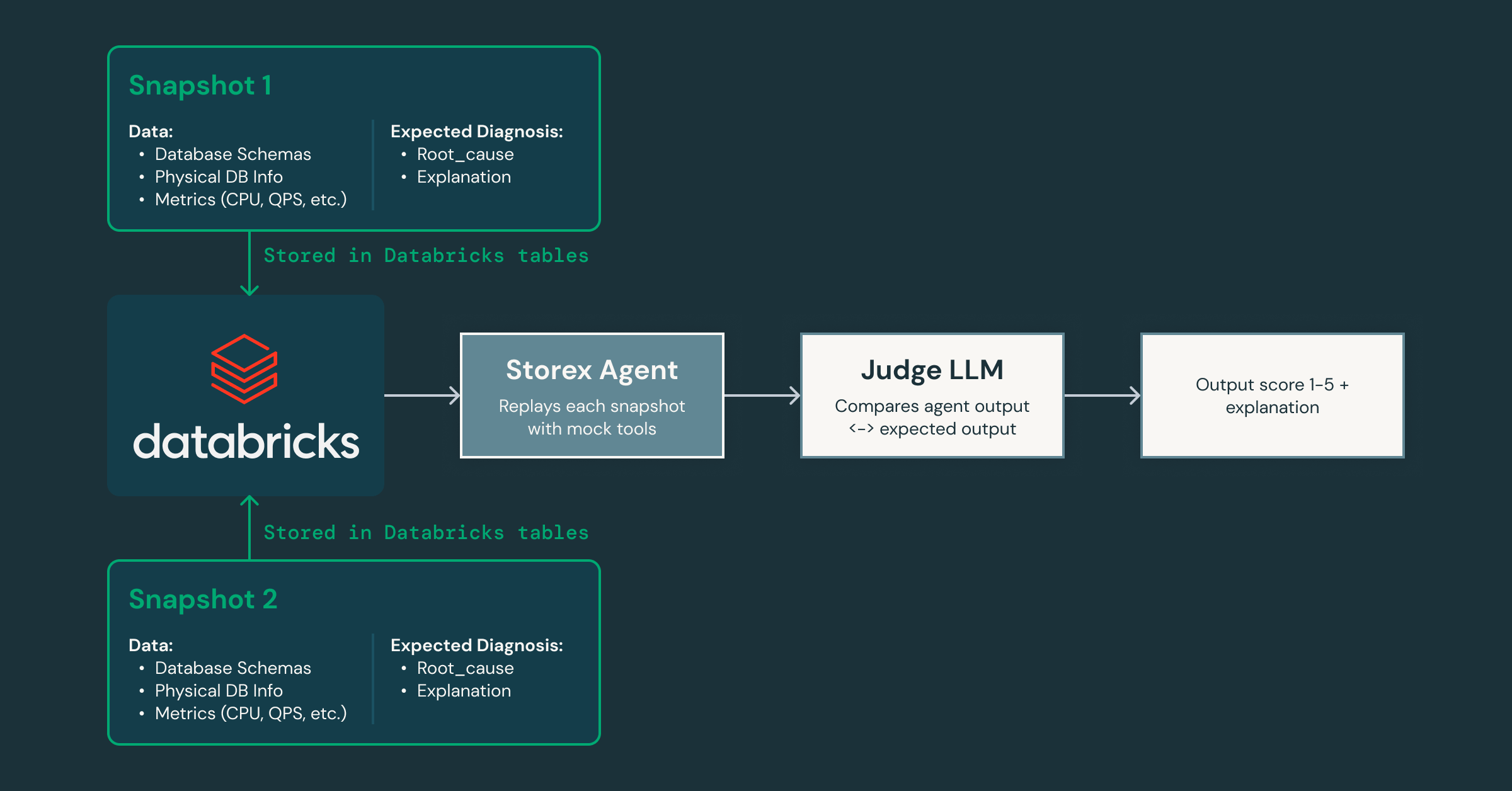
Da dieses Framework schnelle Iterationen ermöglicht, können wir problemlos spezialisierte Agenten für verschiedene Domänen aufsetzen: einen, der sich auf System- und Datenbankprobleme konzentriert, einen anderen auf clientseitige Verkehrsmuster und so weiter. Diese Zerlegung ermöglicht es jedem Agenten, tiefes Fachwissen in seinem Bereich aufzubauen und gleichzeitig mit anderen zusammenzuarbeiten, um eine umfassendere Ursachenanalyse zu liefern. Es ebnet auch den Weg für die Integration von KI-Agenten in andere Teile unserer Infrastruktur, die über Datenbanken hinausgehen.
Mit sowohl Expertenwissen als auch operativem Kontext, die in seine Entscheidungsfindung einfließen, kann unser Agent aussagekräftige Erkenntnisse gewinnen und Ingenieure aktiv durch Untersuchungen führen. Innerhalb von Minuten liefert er relevante Protokolle und Metriken, die Ingenieure möglicherweise nicht in Betracht gezogen hätten. Er verbindet Symptome über verschiedene Ebenen hinweg, z. B. identifiziert er die Arbeitsumgebung, die unerwartete Last verursacht, und korreliert IOPS-Spitzen mit kürzlichen Schema-Migrationen. Er erklärt sogar die zugrunde liegende Ursache und Wirkung und empfiehlt die nächsten Schritte zur Abmilderung.
Zusammenfassend markieren diese Teile unseren Übergang von der Sichtbarkeit zur Intelligenz. Wir sind über die Sichtbarkeit von Tools und Metriken hinaus zu einer Reasoning-Schicht übergegangen, die unsere Systeme versteht, Expertenwissen anwendet und Ingenieure zu sicheren und effektiven Abhilfemaßnahmen führt. Es ist eine Grundlage, auf der wir weiter aufbauen können, nicht nur für Datenbanken, sondern auch für den Betrieb unserer Infrastruktur als Ganzes.
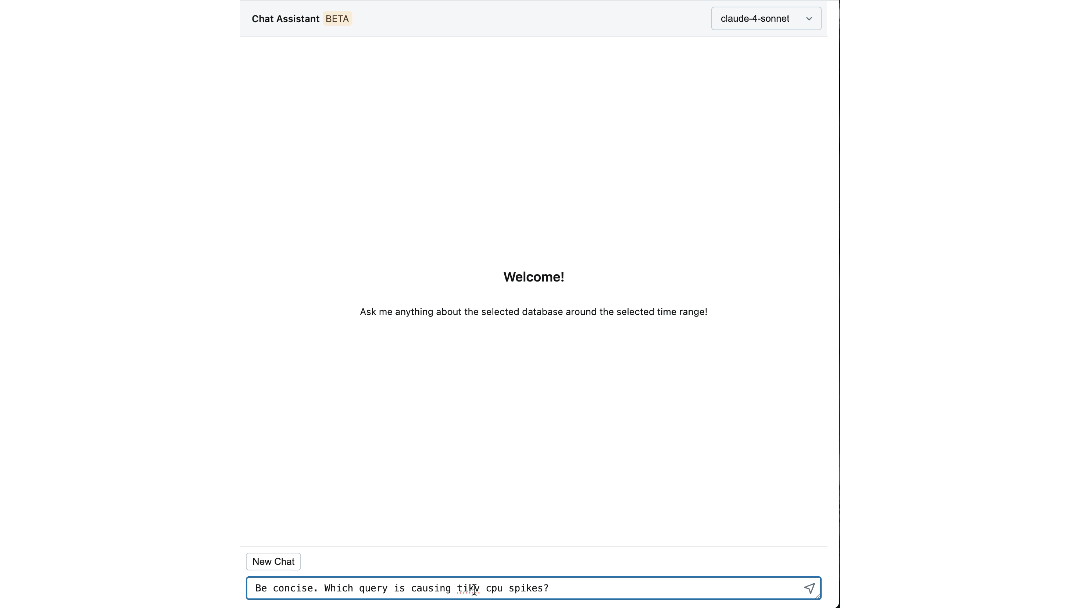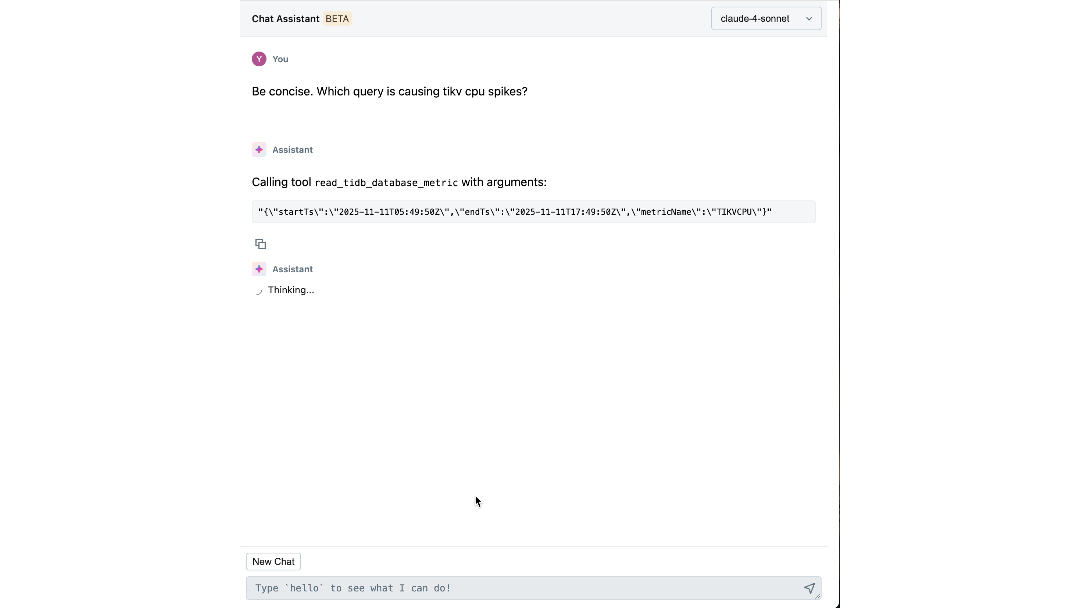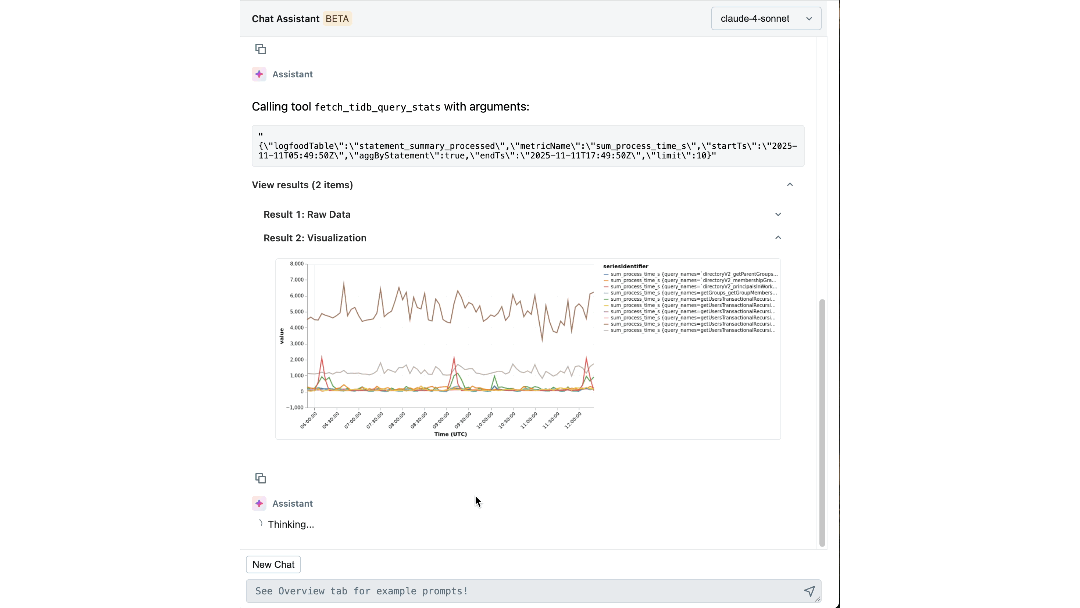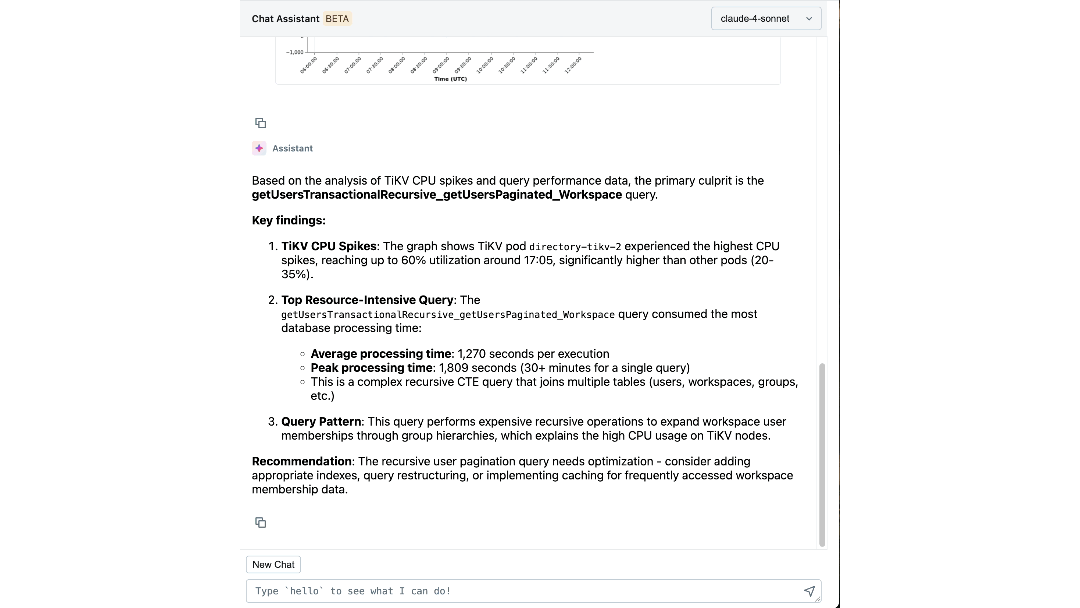
Die Auswirkungen: Neudefinition unseres Aufbaus und Betriebs im großen Maßstab
Die Plattform hat die Art und Weise verändert, wie Databricks-Ingenieure mit ihrer Infrastruktur interagieren. Einzelne Schritte, die früher den Wechsel zwischen Dashboards, CLIs und SOPs erforderten, können jetzt einfach von unserem Chat-Assistenten beantwortet werden, was die benötigte Zeit um bis zu 90 % reduziert.
Die Lernkurve für unsere Infrastruktur bei neuen Ingenieuren ist ebenfalls stark gesunken. Neue Mitarbeiter ohne Vorkenntnisse können jetzt eine Datenbankuntersuchung in weniger als 5 Minuten starten, was vorher fast unmöglich gewesen wäre. Und wir haben seit der Einführung dieser Plattform großartiges Feedback erhalten:
Der Datenbankassistent spart mir wirklich viel Zeit, sodass ich nicht mehr daran denken muss, wo sich all meine Abfrage-Dashboards befinden. Ich kann ihn einfach fragen, welche Arbeitsumgebung die Last verursacht. Bestes Tool aller Zeiten!—Yuchen Huo, Staff Engineer
Ich bin ein Vielnutzer und kann nicht glauben, dass wir früher ohne ihn gelebt haben. Der Grad an Verfeinerung und Nützlichkeit ist sehr beeindruckend. Danke Team, es ist ein echter Fortschritt für die Entwicklererfahrung.—Dmitriy Kunitskiy, Staff Engineer
Besonders gefällt mir, wie wir KI-gestützte Erkenntnisse zur Fehlersuche bei Infrastrukturproblemen einbringen. Ich schätze, wie vorausschauend das Team bei der Entwicklung dieser Konsole von Grund auf mit diesem Ziel vor Augen war.—Ankit Mathur, Senior Staff Engineer
Architektonisch legt die Plattform den Grundstein für die nächste Evolutionsstufe: KI-gestützte Produktionsoperationen. Mit vereinheitlichten Daten, Kontext und Schutzmaßnahmen können wir nun untersuchen, wie der Agent bei Wiederherstellungen, Produktionsabfragen und Konfigurationsaktualisierungen helfen kann: der nächste Schritt in Richtung eines KI-gestützten operativen Workflows.
Die bedeutsamste Auswirkung war jedoch nicht nur die reduzierte manuelle Arbeit oder das schnellere Onboarding: Es war ein Umdenken. Unser Fokus hat sich von der technischen Architektur auf die kritischen User Journeys (CUJs) verlagert, die definieren, wie Ingenieure unsere Systeme erleben. Dieser nutzerzentrierte Ansatz ermöglicht es unseren Infrastrukturteams, Plattformen zu schaffen, auf denen unsere Ingenieure erstklassige Produkte entwickeln können.
Schlussfolgerungen
Letztendlich hat sich unsere Reise auf drei Erkenntnisse reduziert:
- Schnelle Iteration ist für die Agentenentwicklung unerlässlich: Agenten verbessern sich durch schnelles Experimentieren, Validieren und Verfeinern. Unser von DsPy inspiriertes Framework ermöglichte dies, indem es uns erlaubte, Prompts und Tools schnell weiterzuentwickeln.
- Die Geschwindigkeit der Iteration wird durch die zugrunde liegende Grundlage begrenzt: Vereinheitlichte Daten, konsistente Abstraktionen und feingranulare Zugriffskontrolle beseitigten unsere größten Engpässe und machten die Plattform zuverlässig, skalierbar und bereit für KI.
- Geschwindigkeit zählt nur, wenn sie die richtige Richtung hat: Wir haben nicht vor, eine Agentenplattform zu bauen. Jede Iteration folgte einfach dem Nutzerfeedback und brachte uns der Lösung näher, die die Ingenieure benötigten.
Der Aufbau interner Plattformen ist trügerisch schwierig. Selbst innerhalb desselben Unternehmens arbeiten Produkt- und Plattformteams unter sehr unterschiedlichen Randbedingungen. Bei Databricks schließen wir diese Lücke, indem wir mit Kundenbesessenheit aufbauen, durch Abstraktionen vereinfachen und durch Intelligenz aufwerten, wobei wir unsere internen Kunden mit der gleichen Sorgfalt und Strenge behandeln, die wir auch unseren externen Kunden entgegenbringen.
Komm zu uns
Mit Blick auf die Zukunft freuen wir uns darauf, die Grenzen dessen, wie KI Produktionssysteme gestalten und komplexe Infrastrukturen mühelos erscheinen lassen kann, weiter zu verschieben. Wenn Sie leidenschaftlich daran interessiert sind, die nächste Generation KI-gestützter interner Plattformen zu entwickeln, dann kommen Sie zu uns!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.