Ingestion der Milchstraße: Petabyte-Skalierung mit Zerobus Ingest
Ein tiefer Einblick in die Architektur, die 12 GB/s pro Tabelle ermöglicht – und grenzenlose Möglichkeiten
von Aleksandar Tomić, Victoria Bukta, Nikola Obradović, Danilo Najkov, Branko Grbić und Milos Milovanovic
- Databricks Zerobus Ingest ist eine serverlose Streaming-API, mit der Teams im Handumdrehen Datenpipelines im Petabyte-Bereich ohne manuelle Infrastrukturverwaltung bereitstellen können.
- Die Architektur von Zerobus basiert auf dynamischer Partitionierung, um Rechenressourcen automatisch zu skalieren und unvorhersehbare Datenmengen ohne komplexe Optimierung effizient zu verarbeiten.
- Dieses konfigurationsfreie Framework verarbeitet mühelos massive Workloads und demonstriert in 24-Stunden-Benchmarks die Fähigkeit, einen Durchsatz von über 12 GB/s für eine einzelne Tabelle aufrechtzuerhalten.
Telemetriedaten sind überall. IoT-Sensoren in Fabrikhallen. Satelliten-Arrays, die die Atmosphäre scannen. Autonome Fahrzeuge protokollieren Tausende von Ereignissen pro Sekunde. Jedes dieser Systeme hat dasselbe grundlegende Problem: ein kontinuierlicher, hochvolumiger Datenstrom von Zeitreihenbeobachtungen, der an einem abfragbaren Ort landen muss. Er muss schnell und zuverlässig sein, ohne dass ein Engineering-Team Wochen damit verbringt, die für Kafka-basierte Workloads typische Infrastruktur abzustimmen und zu warten.
Genau dieses Problem soll Zerobus Ingest lösen. Zerobus ist der vollständig verwaltete, serverlose Streaming-Ingest-Dienst von Databricks. Es handelt sich um eine Push-basierte API, die Daten von jedem Producer entgegennimmt und direkt in Delta-Tabellen schreibt, verwaltet durch Unity Catalog.
- Keine bereitzustellende Infrastruktur.
- Keine zu wartende Connector-Pipeline.
- Keine Partitionen oder Broker-Entscheidungen.
Stattdessen erstellen Sie eine Tabelle und pushen die Daten. Sie landen in Ihrem Lakehouse und sind in Sekundenschnelle abfragbar. Sie müssen Kafka nicht mehr als Pipeline betreiben, wenn Ihr Ziel das Lakehouse ist.
Wir haben den NEOWISE-Datensatz der NASA verwendet, der 200 Milliarden Datenpunkte aus 11 Jahren umfasst, um Zerobus Ingest zu benchmarken. Dabei wurde 1 Petabyte in weniger als 24 Stunden mit minimaler Vorkonfiguration und stabiler Latenz erfasst.
Mit der Erfassung von 1 PB innerhalb von 24 Stunden demonstrieren wir die Fähigkeit von Zerobus, einen kontinuierlichen Durchsatz von 12 GB/s für eine einzelne Tabelle aufrechterzuhalten! 🚀
Jetzt im Petabyte-Bereich: Streaming der Milchstraße (12 GB/s/Tabelle)
Weitere Informationen dazu, wie Sie den Benchmark selbst ausführen können, finden Sie in diesem begleitenden Blogbeitrag in der Databricks Community.
In diesem Beitrag stellen wir drei unserer Designentscheidungen vor, die dies ermöglicht haben.
- Entwicklung eines Systems, das über dynamische Partitionierung automatisch skaliert.
- Entwicklung unseres eigenen Zero-Copy-Protobuf-Decoders.
- Implementierung eines latenzoptimierten Write-Ahead-Logs, bevor Daten im Lakehouse veröffentlicht werden.
Unsere wichtigsten Designentscheidungen
Unser Ziel war es, ein Streaming-System zu entwickeln, das Petabyte-Größenordnungen unterstützt und sich automatisch an schwankende Ingest-Muster anpasst.
Traditionelle Streaming-Architekturen erfordern die Entscheidung, wie viele Broker und Partitionen für einen bestimmten Workload benötigt werden. Dies erfordert Kenntnisse über Spitzenlasten und Ingest-Einschränkungen auf Consumer-Seite sowie Prognosen und ein Verständnis der End-to-End-Pipeline.
Indem wir zu den grundlegenden Prinzipien zurückgekehrt sind, haben wir ein System entworfen und gebaut, das Workloads im Petabyte-Bereich für Datenproduzenten „wie von Zauberhand“ skaliert.
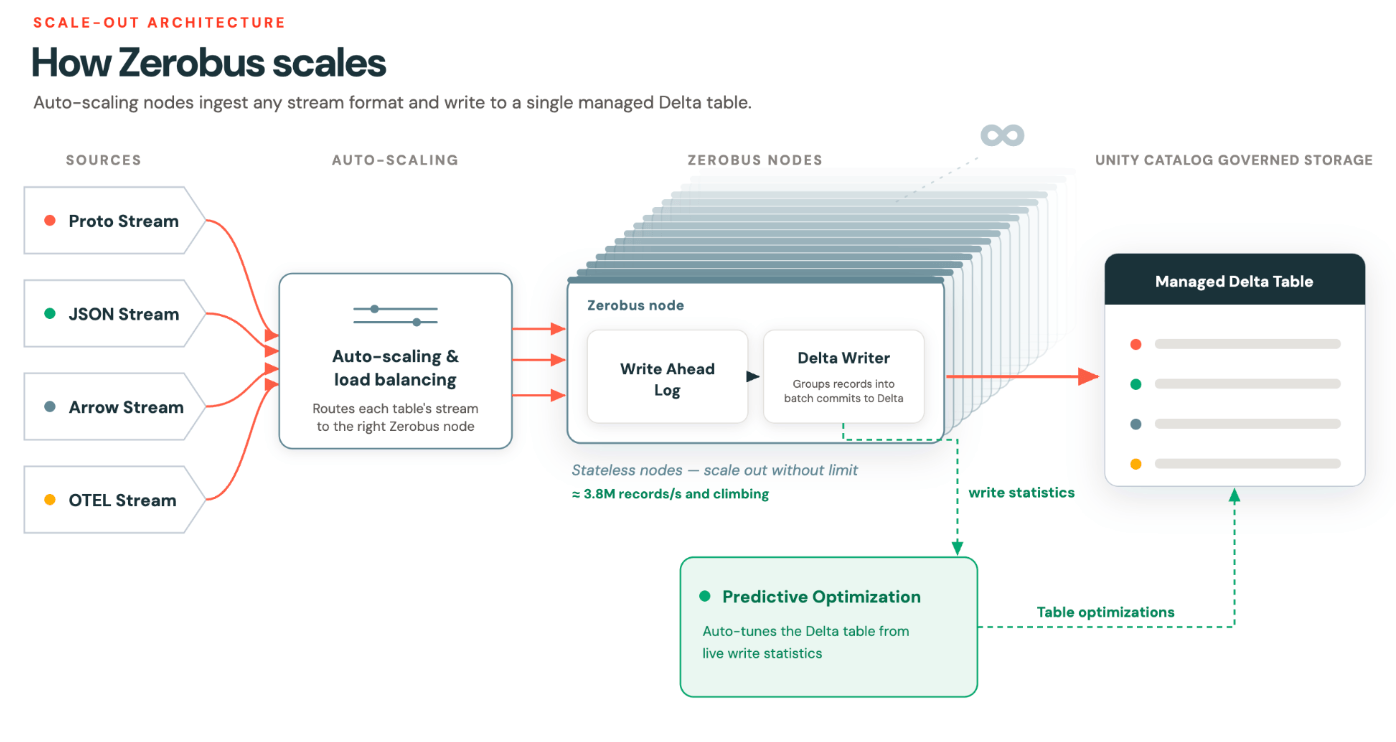
Autoskalierung durch dynamische Partitionierung
Das Problem, das wir lösen wollten, war eine effiziente Autoskalierung, um eine elastische, „grenzenlose“ Skalierung zu erreichen.
Unsere These war, dass wir durch die Abkehr von der statischen Partitionierung hin zur logischen Einheit eines Streams/einer Verbindung eine echte Autoskalierung und ein Rebalancing ermöglichen könnten, während gleichzeitig die für Consumption-Workloads wichtigen Reihenfolgegarantien gewahrt bleiben.
Das Problem der statischen Partitionierung
In Message-Bus-Architekturen sind Partitionen sowohl die Einheit der Parallelit�ät als auch der Reihenfolge. Diese Kopplung schafft eine Einschränkung, die problematisch sein kann, sobald Consumer darauf angewiesen sind.
Die Reihenfolge ist in der Regel eine Garantie pro Partition, nicht pro Producer. Die Anzahl der Partitionen und die Verteilung der Daten auf diese beeinflussen die Fähigkeit eines Consumers, mit dem Ingest Schritt zu halten. Das bedeutet:
- Wenn sich Ihre Partitionsanzahl ändert, sendet die Routing-Funktion, die die Nachrichten eines Producers einer Partition zuordnet, diese möglicherweise an eine andere Partition. Der Consumer muss dies dann ausgleichen.
- In der Praxis behandeln die meisten Teams die Partitionstopologie als unveränderlich. Man plant für die Spitzenlast und behält diese Infrastruktur dauerhaft bei. Sie können Partitionen hinzufügen, aber in der Regel können Sie sie nicht sicher reduzieren.
- Der Standard-Workaround ist ein Partitions-Routing-Schlüssel, der von einem Feld in der Nachricht abgeleitet wird. Dies hilft bei der Konsistenz der Reihenfolge, löst aber das Problem des Herunterskalierens immer noch nicht.
Wir haben die Reihenfolgegarantie auf die Stream-Verbindung verlagert
In herkömmlichen Systemen ist die Reihenfolge eine Garantie auf Partitionsebene. Bei Zerobus Ingest ist die Reihenfolge eine Garantie auf Stream-Verbindungsebene.
Wenn ein Producer einen Stream mit Zerobus öffnet (eine Verbindung zu unserem Server), registriert er eine logische Identität beim Dienst. Für die Lebensdauer dieser Verbindung kommen die Daten in der richtigen Reihenfolge an, unabhängig davon, welcher „Partitions“-Pod sie verarbeitet.
„Ihr Stream ist geordnet“, nicht „Ihre Partition ist geordnet.“ Das ist die Vereinbarung.
Hot-Routing und echte Autoskalierung
Intern verteilt Zerobus Ingest Streams auf einen Pool von Pods. Das Routing basiert auf Heuristiken: Wenn ein Pod heißläuft, werden neue eingehende Streams an einen anderen Pod geleitet. Der Producer merkt davon nichts. Seine Reihenfolgegarantie bleibt unberührt.
Die Reihenfolge wird auf Stream-Ebene geregelt, was bedeutet, dass Pods bei Nachfragespitzen hinzugefügt und bei sinkender Nachfrage entfernt werden können. Bestehende Streams laufen dann kontrolliert aus, und neue Streams werden nicht mehr dorthin geleitet. Der Pool verkleinert sich anschließend, wodurch die Rechenauslastung effizient bleibt.
Dies ist echte Autoskalierung. Die Granularitätseinheit ist die Stream-Verbindung, nicht die Partitionszuweisung.
Unser dynamisches Partitionierungsdesign ermöglicht es Zerobus, auf einen Durchsatz von über 12 GB pro Sekunde für eine Tabelle zu skalieren und gleichzeitig kosteneffizient zu bleiben.
Hochleistungs-Datenverarbeitung mit Zero-Copy
Das Hauptziel von Zerobus ist es, eine effiziente, zeilenweise Übertragung von Datenströmen jeglichen Volumens zu ermöglichen. Um dies zu erreichen, mussten wir unnötiges Kopieren und Speicherzuweisungen vollständig vermeiden – von den Eingabeformaten, die Clients an Zerobus senden, bis hin zu den internen Formaten, die Langlebigkeit garantieren, und offenen Delta-Formaten.
Zerobus unterstützt derzeit die folgenden Nachrichtenformate.
Unter den vielen von uns vorgenommenen Optimierungen möchten wir den Zero-Copy-Ansatz anhand von ZeroParser veranschaulichen – unserem maßgeschneiderten protobuf-Decoder.
Standardmäßige protobuf-Decoder zwingen Sie zur Entscheidung zwischen Geschwindigkeit und Flexibilität. Protobuf-Decoder basieren in der Regel entweder auf Codegenerierung zur Build-Zeit (Codegen) oder auf Laufzeit-Reflektion.
- Codegenerierung ist schnell, erfordert jedoch Deskriptoren zur Kompilierzeit. Zerobus empfängt Deskriptoren dynamisch zur Laufzeit aus beliebigen Benutzerschemata. Codegen ist daher keine Option.
- Laufzeit-Reflektion löst zwar das Flexibilitätsproblem, verursacht jedoch ein Performance-Problem. Dynamische protobuf-Decoder sind langsam und erfordern den Aufbau eines Objektgraphen im Speicher zur Laufzeit, was zu vielen kleinen Speicherallokationen führt.
Keiner der beiden Ansätze war akzeptabel. Wir benötigten eine dynamische Deskriptor-Unterstützung mit dem Performance-Profil von Codegen.
Das Ergebnis war die Entwicklung von zeroparser: Dieses Tool schließt diese Lücke durch Single-Pass-Parsing ohne Speicherallokationen. Dadurch können selbst bei dynamischen Deskriptoren und komplexen Schemata Durchsätze von ~1 GB/s beim protobuf-Parsing pro CPU-Kern erzielt werden.
Zeroparser ermöglicht das direkte Parsen im Wire-Format ohne Dekonstruktion eingehender Objekte, was andernfalls zu Kopier- und Allokationsvorgängen im Speicher führen würde. Mit diesem Ansatz kann Zerobus eine bessere Performance erzielen als bestehende codegenerierte protobuf-Parsing-Lösungen, während gleichzeitig die volle Flexibilität der dynamischen Bereitstellung von protobuf-Deskriptoren erhalten bleibt.
Das Lifetime-System von Rust war zentral für das Design von Zeroparser: Es garantiert Sicherheit zur Kompilierzeit während des Protokoll-Parsings, während die rohen Wire-Bytes im exklusiven Netzwerkbesitz verbleiben, wodurch unnötige Datenkopien vermieden werden.
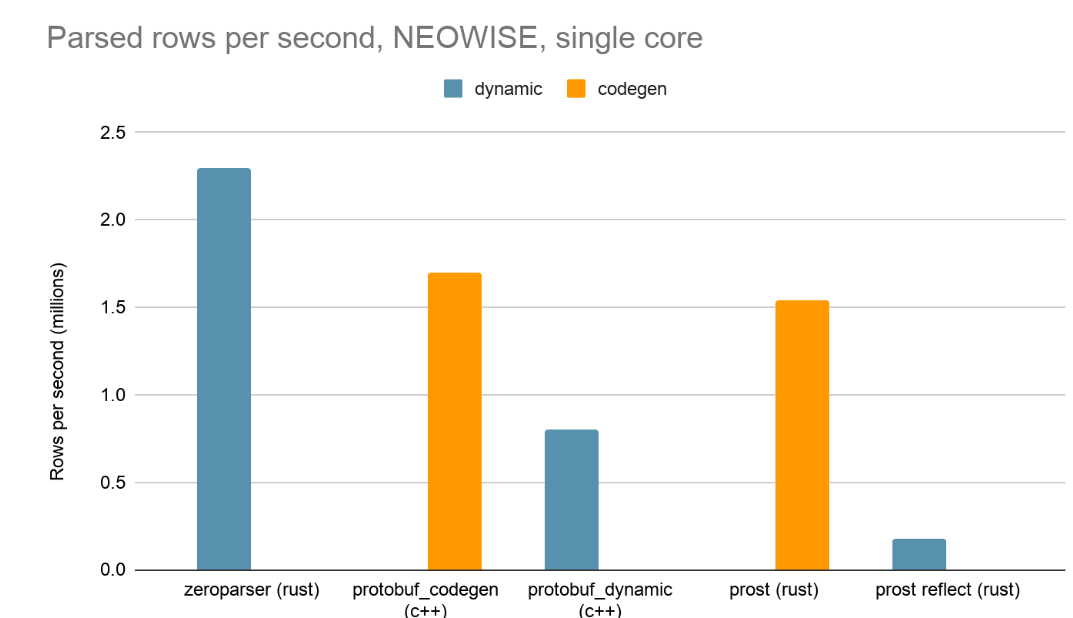
Die Ergebnisse zeigen, dass Zeroparser, obwohl es zur dynamischen Gruppe gehört, zwei branchenübliche, auf Codegen basierende Implementierungen übertroffen hat.
Zeroparser ist als Open-Source-Software als Teil des Zerobus-SDK verfügbar, das Sie hier finden.
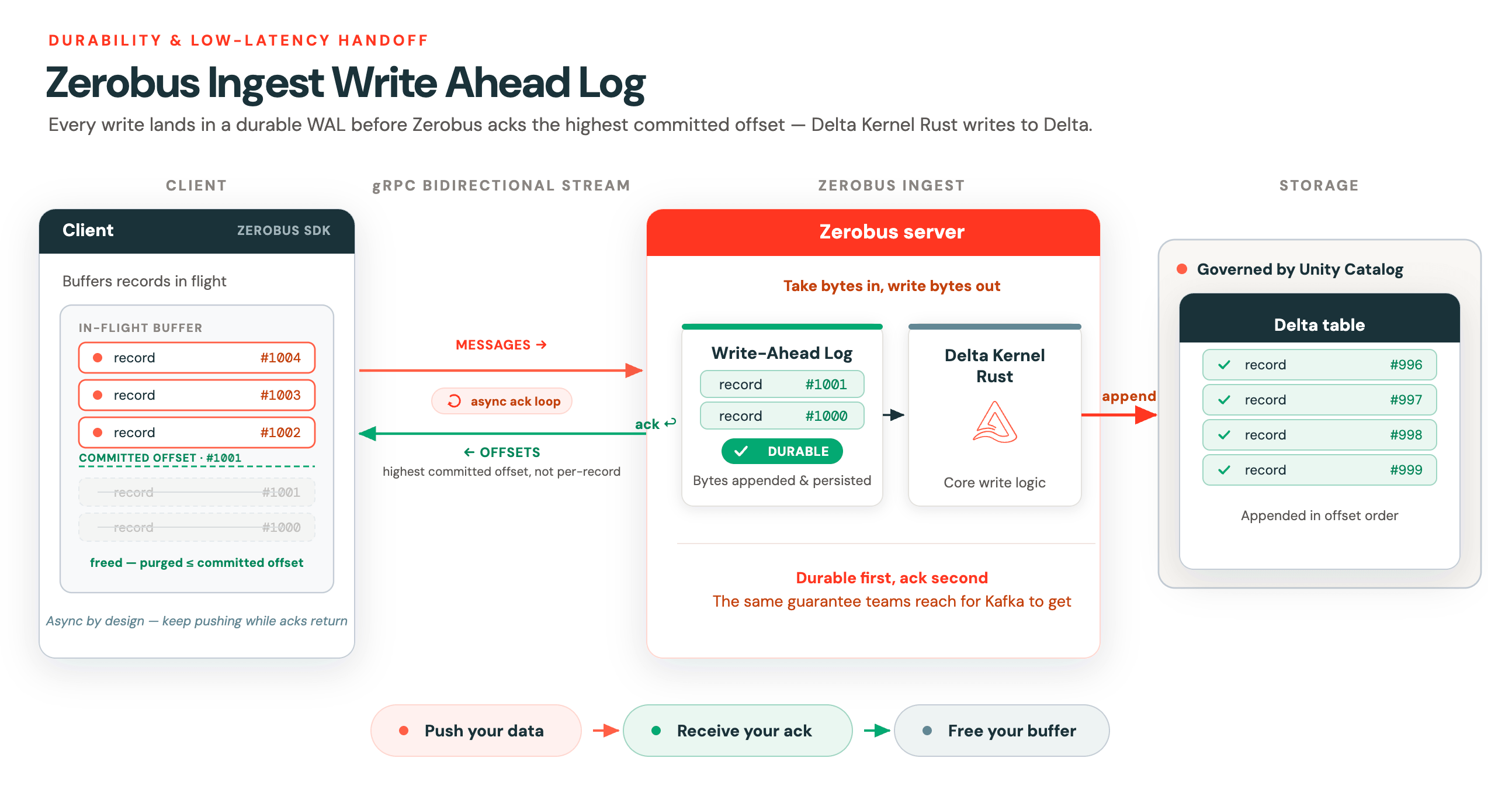
Write-Ahead-Log
Beim Streaming geht es nicht nur darum, Workloads mit hohem Durchsatz bewältigen zu können. Um ein echter Streaming-Dienst zu sein, müssen Sie auch die schnellstmögliche Übergabe von Nachrichten unterstützen. Diese geringe Latenz bei der Datenübergabe unterscheidet Streaming-Workloads wirklich von Batch-Workloads.
Um diese Übergabe mit geringer Latenz und einer Haltbarkeitsgarantie zu unterstützen, implementiert Zerobus ein latenzoptimiertes Write-Ahead-Log (WAL). Sobald Nachrichten dauerhaft gespeichert sind, sendet Zerobus eine Bestätigung an den Client zurück. Anstatt jeden Datensatz einzeln zu bestätigen, gibt der Server den höchsten übertragenen Offset im Stream zurück. Das Ergebnis ist dieser asynchrone Bestätigungs-Loop (async ack loop). Delta Kernel Rust wird dann für die Kernlogik zum Schreiben in Delta verwendet.
Dieses asynchrone Design ist entscheidend für Clients, die Daten während der Übertragung (in flight) puffern. Zerobus nutzt bidirektionales gRPC-Streaming, bei dem jeder Zerobus-Stream über zwei Kommunikationskanäle verfügt:
- Einen zum Senden von Nachrichten
- Den anderen zum Empfangen von Offset-Bestätigungen.
Sobald der Client diesen Offset empfängt, kann er alle Daten bis zu diesem Punkt sicher aus seinem lokalen In-Flight-Puffer löschen. Dies wird von den Zerobus-SDKs vollständig für Sie übernommen.
Das WAL sorgt dafür, dass Clients schlank bleiben. Daten senden, Bestätigung erhalten, Puffer freigeben. Diese Übergabe mit geringer Latenz und hoher Haltbarkeit war schon immer der Grund, warum Teams sich für Kafka entscheiden. Zerobus bietet Ihnen dieselbe Garantie.
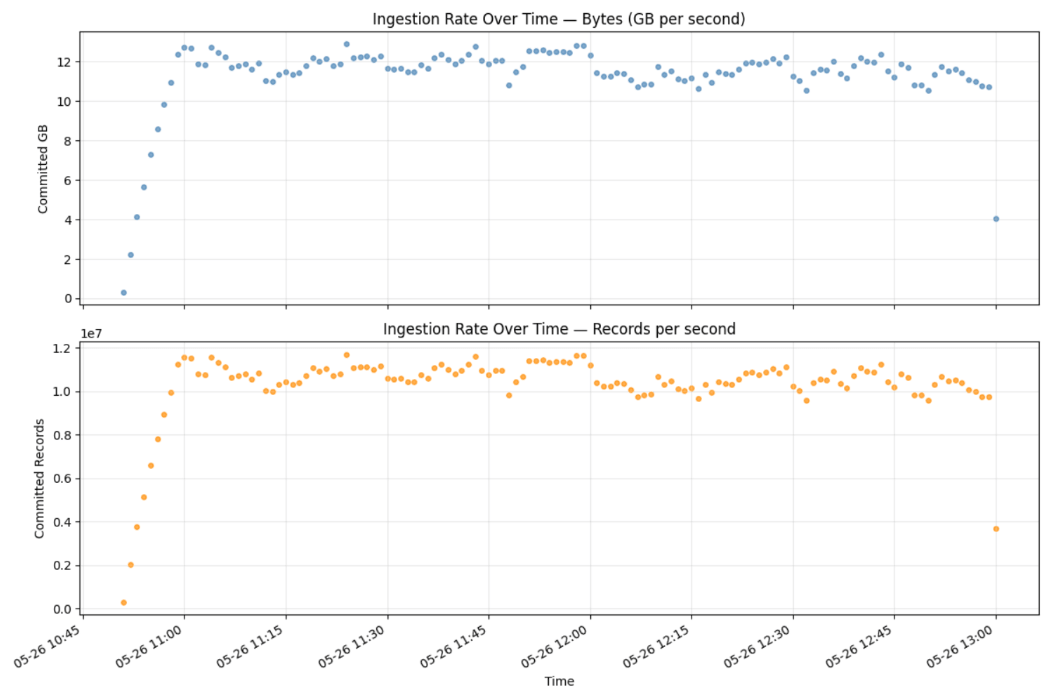
Beweis: Ingestion der Milchstraße
Der Schlüssel zum Benchmarking eines Systems liegt darin, zu verstehen, wie es in einer Produktionsumgebung verwendet wird, und dieses Verhalten und diese Nutzung dann zu emulieren. Um Zerobus Ingest einem Stresstest zu unterziehen, haben wir uns daher für den NEOWISE-Datensatz der NASA entschieden und Locust verwendet, um reale Fan-In-Muster zu emulieren.
Warum Locust? Das Fan-In-Problem
Zerobus Ingest ist dafür ausgelegt, Streams von vielen unabhängigen Producern in einer einzigen Zieltabelle zu aggregieren. Sein Durchsatz skaliert mit der Anzahl der gleichzeitig geöffneten Streams. Das bedeutet, dass Sie das System von einer einzelnen Maschine oder einem kleinen Cluster aus nicht fair testen können. Ein einzelner leistungsstarker Host würde seine eigene Bandbreite oder CPU auslasten, bevor er nennenswerten Druck auf unseren Dienst ausübt, wodurch der Producer und nicht Zerobus getestet würde.
Um ein reales Fan-In-Muster zu simulieren, verwenden wir Locust, um das Öffnen separater Streams durch Pods zu koordinieren und so die Ingestion im großen Maßstab zu testen.
Die automatische Skalierung (Autoscaling) von Zerobus reagiert dann auf die Anzahl der Streams und den Durchsatz, um die Ingestionsrate zu bewältigen.
Testkonfiguration
Unser Benchmark wurde auf Kubernetes mit einem Locust-Master und einer Flotte von Locust-Workern bereitgestellt, die jeweils als separater Pod ausgeführt wurden. Wichtigste Parameter:
Jeder Worker erhält eine eindeutige Liste von Parquet-Dateien für die Ingestion. Ein Worker streamt seinen Teilbereich und wiederholt keine Zeilen.
Die Ergebnisse
Unsere Testergebnisse zeigten die Fähigkeit von Zerobus Ingest, über einen Zeitraum von 24 Stunden hinweg eine konstante Rate von 12 GB/s von 2.048 gleichzeitigen Workern in eine einzelne Tabelle aufrechtzuerhalten. In diesem Zeitraum hat Zerobus über eine Billion Datensätze verarbeitet.
Die Aggregation über 5-Sekunden-Intervalle über der Spalte client_ts_ms liefert eine präzise, vom Server bestätigte Ansicht der committeten Zeilen und empfangenen Bytes:
Diese Abfrage wird für die Live-Tabelle in Unity Catalog ausgeführt. Die Zahlen spiegeln die Zeilen wider, die vollständig im Delta-Speicher committet wurden.
Möchten Sie es selbst ausprobieren?
Die vollständige Benchmark-Umgebung mit Datensatzvorbereitung, Producer-Code und Anweisungen für die Ausführung mit Ihrem eigenen Zerobus-Endpunkt. Probieren Sie es hier aus.
Wie geht es weiter?
Zerobus Ingest ist jetzt allgemein verfügbar auf Databricks und bereit für alle Ihre Produktions-Workloads.
Unsere Leistungsmetriken von 12 GB/s für eine Tabelle erhalten Sie standardmäßig direkt mit Zerobus Ingest. Quoten können durch Kontaktaufnahme mit Ihrem Account-Team erhöht werden.
Auf der Roadmap:
- Unterstützung für die Kafka Producer-API
- Unterstützung für die MQTT-API
- Rescue-Spalte
- System-Metadaten-Spalte
- Avro-Unterstützung
Teilen Sie uns mit, wie wir Zerobus weiterentwickeln sollen! Was ist Ihrer Meinung nach der nächste Meilenstein im Bereich Streaming? Hinterlassen Sie uns Ihre Kommentare in unserem begleitenden Databricks Community-Blog.
Wenn Sie bereit sind, mit Zerobus Ingest loszulegen, werfen Sie einen Blick auf unsere technische Dokumentation, das Zerobus Ingest SDK oder das GitHub-Repository mit dem Neowise-Benchmark.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.