Eine Einführung in Zeitreihenvorhersagen mit generativer KI
von Ryuta Yoshimatsu , Puneet Jain und Bryan Smith
Eine Einführung in Zeitreihenprognosen mit generativer KI
Zeitreihenprognosen sind seit Jahrzehnten ein Eckpfeiler der Unternehmensressourcenplanung. Vorhersagen über die zukünftige Nachfrage leiten entscheidende Entscheidungen, wie z. B. die zu lagernden Einheiten, das einzustellende Personal, Kapitalinvestitionen in Produktions- und Erfüllungsinfrastrukturen sowie die Preisgestaltung von Waren und Dienstleistungen. Genaue Nachfrageprognosen sind für diese und viele andere Geschäftsentscheidungen unerlässlich.
Prognosen sind jedoch selten perfekt. Mitte der 2010er Jahre berichteten viele Organisationen, die mit Rechenbeschränkungen und begrenztem Zugang zu fortschrittlichen Prognosefähigkeiten zu kämpfen hatten, von Prognosegenauigkeiten von nur 50-60%. Aber mit der breiteren Einführung der Cloud, der Einführung weitaus zugänglicherer Technologien und der verbesserten Zugänglichkeit externer Datenquellen wie Wetter- und Veranstaltungsdaten beginnen Organisationen, Verbesserungen zu sehen.
Da wir in das Zeitalter der generativen KI eintreten, scheint eine neue Klasse von Modellen, die als Zeitreihen-Transformer bezeichnet werden, in der Lage zu sein, Organisationen dabei zu helfen, noch weitere Verbesserungen zu erzielen. Ähnlich wie große Sprachmodelle (wie ChatGPT), die beim Vorhersagen des nächsten Wortes in einem Satz hervorragend sind, sagen Zeitreihen-Transformer den nächsten Wert in einer numerischen Sequenz voraus. Durch die Exposition gegenüber großen Mengen von Zeitreihendaten werden diese Modelle zu Experten darin, subtile Muster von Beziehungen zwischen den Werten in diesen Sequenzen zu erkennen, mit nachgewiesenem Erfolg in einer Vielzahl von Domänen.
In diesem Blog geben wir eine allgemeine Einführung in diese Klasse von Prognosemodellen, die Managern, Analysten und Datenwissenschaftlern helfen soll, ein grundlegendes Verständnis dafür zu entwickeln, wie sie funktionieren. Anschließend stellen wir eine Reihe von Notebooks zur Verfügung, die auf öffentlich zugänglichen Datensätzen basieren und zeigen, wie Organisationen, die ihre Daten in Databricks speichern, problemlos auf mehrere der beliebtesten dieser Modelle für ihre Prognoseanforderungen zugreifen können. Wir hoffen, dass dies Organisationen dabei hilft, das Potenzial der generativen KI für bessere Prognosegenauigkeiten zu nutzen.
Zeitreihen-Transformer verstehen
Generative KI-Modelle sind eine Form von Deep-Learning-Netzwerken, einem komplexen Machine-Learning-Modell, in dem eine große Anzahl von Eingaben auf verschiedene Weise kombiniert wird, um einen vorhergesagten Wert zu erhalten. Die Mechanik, wie das Modell lernt, Eingaben zu kombinieren, um eine genaue Vorhersage zu treffen, wird als Architektur eines Modells bezeichnet.
Der Durchbruch bei Deep-Learning-Netzwerken, der zur generativen KI geführt hat, war das Design einer spezialisierten Modellarchitektur namens Transformer. Während die genauen Details, wie sich Transformer von anderen Deep-Learning-Netzwerkarchitekturen unterscheiden, sehr komplex sind, ist die einfache Tatsache, dass der Transformer sehr gut darin ist, die komplexen Beziehungen zwischen Werten in langen Sequenzen zu erkennen.
Um einen Zeitreihen-Transformer zu trainieren, wird ein entsprechend architektonisch gestaltetes Deep-Learning-Netzwerk einer großen Menge von Zeitreihendaten ausgesetzt. Nachdem es die Möglichkeit hatte, mit Millionen, wenn nicht Milliarden von Zeitreihenwerten zu trainieren, lernt es die komplexen Beziehungsmuster, die in diesen Datensätzen gefunden werden. Wenn es dann einer bisher ungesehenen Zeitreihe ausgesetzt wird, kann es dieses grundlegende Wissen nutzen, um zu identifizieren, wo ähnliche Beziehungsmuster innerhalb der Zeitreihe existieren, und neue Werte in der Sequenz vorhersagen.
Dieser Prozess des Lernens von Beziehungen aus großen Datenmengen wird als Vortraining bezeichnet. Da das Wissen, das das Modell während des Vortrainings erworben hat, hochgradig verallgemeinerbar ist, können vortrainierte Modelle, die als Foundation Models bezeichnet werden, ohne zusätzliches Training auf bisher ungesehene Zeitreihen angewendet werden. Dennoch kann ein zusätzliches Training mit den proprietären Daten einer Organisation, ein Prozess, der als Fine-Tuning bezeichnet wird, in einigen Fällen dazu beitragen, dass die Organisation eine noch bessere Prognosegenauigkeit erzielt. In jedem Fall, sobald das Modell als zufriedenstellend eingestuft wird, muss die Organisation ihm einfach eine Zeitreihe vorlegen und fragen: Was kommt als Nächstes?
Häufige Herausforderungen bei Zeitreihen
Während dieses allgemeine Verständnis eines Zeitreihen-Transformers sinnvoll sein mag, werden die meisten Prognosepraktiker wahrscheinlich drei unmittelbare Fragen haben. Erstens, obwohl zwei Zeitreihen einem ähnlichen Muster folgen können, können sie in völlig unterschiedlichen Skalen operieren. Wie überwindet ein Transformer dieses Problem? Zweitens gibt es innerhalb der meisten Zeitreihenmodelle tägliche, wöchentliche und jährliche Saisonalitätsmuster, die berücksichtigt werden müssen. Woher wissen die Modelle, dass sie nach diesen Mustern suchen sollen? Drittens werden viele Zeitreihen von externen Faktoren beeinflusst. Wie können diese Daten in den Prozess der Prognoseerstellung einbezogen werden?
Die erste dieser Herausforderungen wird durch mathematische Standardisierung aller Zeitreihendaten mithilfe einer Reihe von Techniken, die als Skalierung bezeichnet werden, bewältigt. Die Mechanik davon ist intern für die Architektur jedes Modells, aber im Wesentlichen werden eingehende Zeitreihenwerte auf eine Standard-Skala umgewandelt, die es dem Modell ermöglicht, Muster in den Daten basierend auf seinem grundlegenden Wissen zu erkennen. Vorhersagen werden getroffen und diese Vorhersagen werden dann auf die ursprüngliche Skala der Originaldaten zurückgeführt.
Bezüglich der saisonalen Muster liegt im Herzen der Transformer-Architektur ein Prozess namens Self-Attention. Obwohl dieser Prozess recht komplex ist, ermöglicht dieser Mechanismus dem Modell im Grunde, den Grad zu lernen, zu dem bestimmte frühere Werte einen gegebenen zukünftigen Wert beeinflussen.
Während dies wie die Lösung für die Saisonalität klingt, ist es wichtig zu verstehen, dass sich Modelle in ihrer Fähigkeit unterscheiden, Muster auf niedriger Ebene der Saisonalität zu erkennen, basierend darauf, wie sie Zeitreiheneingaben aufteilen. Durch einen Prozess namens Tokenisierung werden Werte in einer Zeitreihe in Einheiten, sogenannte Tokens, unterteilt. Ein Token kann ein einzelner Zeitreihenwert sein oder eine kurze Sequenz von Werten (oft als Patch bezeichnet).
Die Größe des Tokens bestimmt die niedrigste Granularitätsebene, auf der saisonale Muster erkannt werden können. (Die Tokenisierung definiert auch die Logik für den Umgang mit fehlenden Werten.) Bei der Untersuchung eines bestimmten Modells ist es wichtig, die manchmal technischen Informationen zur Tokenisierung zu lesen, um zu verstehen, ob das Modell für Ihre Daten geeignet ist.
Schließlich beschäftigen sich Zeitreihen-Transformer mit externen Variablen mit einer Vielzahl von Ansätzen. Bei einigen werden Modelle sowohl auf Zeitreihendaten als auch auf zugehörige externe Variablen trainiert. Bei anderen sind Modelle so konzipiert, dass sie verstehen, dass eine einzelne Zeitreihe aus mehreren parallelen, zusammenhängenden Sequenzen bestehen kann. Unabhängig von der genauen Technik, die angewendet wird, ist mit diesen Modellen eine gewisse begrenzte Unterstützung für externe Variablen zu finden.
Ein kurzer Blick auf vier beliebte Zeitreihen-Transformer
Nachdem wir nun ein allgemeines Verständnis von Zeitreihen-Transformern haben, wollen wir uns kurz vier beliebte Foundation-Zeitreihen-Transformer-Modelle ansehen:
Chronos
Chronos ist eine Familie von Open-Source, vortrainierten Zeitreihenprognosemodellen von Amazon. Diese Modelle verfolgen einen relativ einfachen Ansatz zur Prognose, indem sie eine Zeitreihe als eine spezialisierte Sprache mit eigenen Beziehungsmustern zwischen Tokens interpretieren. Trotz dieses relativ einfachen Ansatzes, der Unterstützung für fehlende Werte, aber nicht für externe Variablen bietet, hat die Chronos-Modellfamilie beeindruckende Ergebnisse als allgemeine Prognoselösung gezeigt (Abbildung 1).

Abbildung 1. Evaluierungsmetriken für Chronos und verschiedene andere Prognosemodelle, angewendet auf 27 Benchmark-Datensätze (von https://github.com/amazon-science/chronos-forecasting)
TimesFM
TimesFM ist ein Open-Source-Foundation-Modell, das von Google Research entwickelt wurde und auf über 100 Milliarden realen Zeitreihenpunkten vortrainiert wurde. Im Gegensatz zu Chronos enthält TimesFM einige zeitreihenspezifische Mechanismen in seiner Architektur, die es dem Benutzer ermöglichen, die Organisation von Ein- und Ausgaben fein zu steuern. Dies hat Auswirkungen darauf, wie saisonale Muster erkannt werden, aber auch auf die Rechenzeiten, die mit dem Modell verbunden sind. TimesFM hat sich als sehr leistungsfähiges und flexibles Werkzeug für Zeitreihenprognosen erwiesen (Abbildung 2).
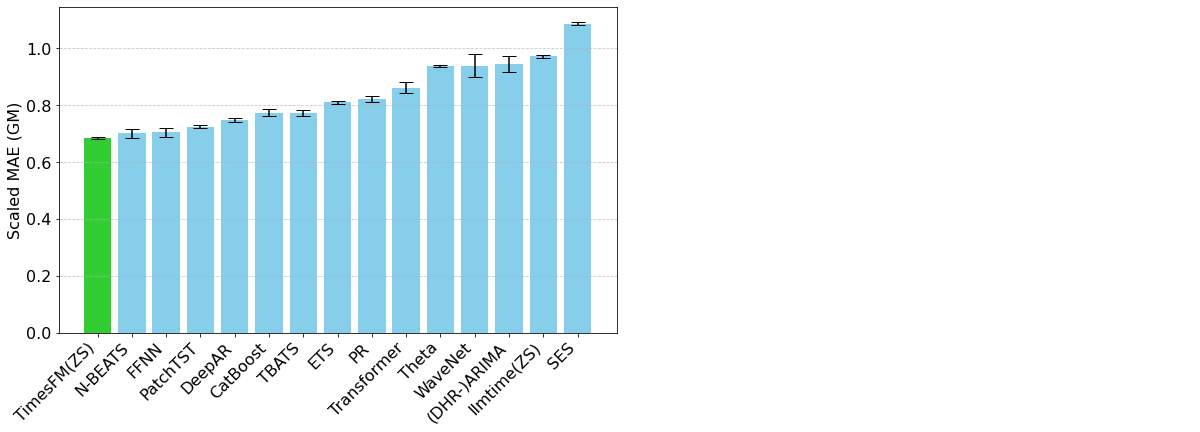
Abbildung 2. Evaluierungsmetriken für TimesFM und verschiedene andere Modelle im Vergleich zum Monash Forecasting Archive Datensatz (von https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/)
Moirai
Moirai, entwickelt von Salesforce AI Research, ist ein weiteres Open-Source-Foundation-Modell für Zeitreihenprognosen. Trainiert auf "27 Milliarden Beobachtungen aus 9 verschiedenen Domänen", wird Moirai als universeller Prognostizierer präsentiert, der sowohl fehlende Werte als auch externe Variablen unterstützen kann. Variable Patchgrößen ermöglichen es Organisationen, das Modell an die saisonalen Muster in ihren Datensätzen anzupassen, und bei richtiger Anwendung zeigen sie gute Leistungen im Vergleich zu anderen Modellen (Abbildung 3).

Abbildung 3. Evaluierungsmetriken für Moirai und verschiedene andere Modelle im Vergleich zum Monash Time Series Forecasting Benchmark (von https://blog.salesforceairesearch.com/moirai/)
TimeGPT
TimeGPT ist ein proprietäres Modell mit Unterstützung für externe (exogene) Variablen, aber nicht für fehlende Werte. TimeGPT konzentriert sich auf Benutzerfreundlichkeit und wird über eine öffentliche API gehostet, die es Organisationen ermöglicht, Prognosen mit nur einer Codezeile zu generieren. Beim Benchmarking des Modells anhand von 300.000 eindeutigen Zeitreihen auf verschiedenen Ebenen der zeitlichen Granularität zeigte das Modell beeindruckende Ergebnisse mit sehr geringer Prognoselatenz (Abbildung 4).
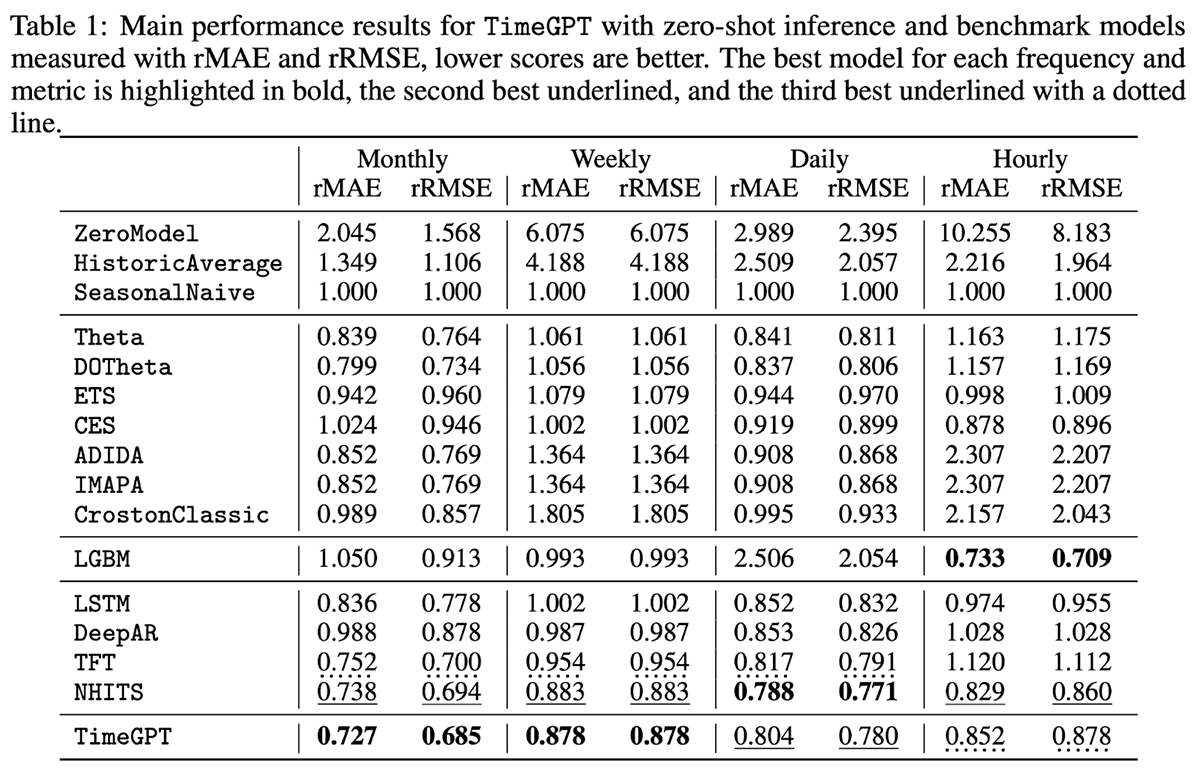
Abbildung 4. Evaluierungsmetriken für TimeGPT und verschiedene andere Modelle im Vergleich zu 300.000 eindeutigen Zeitreihen (von https://arxiv.org/pdf/2310.03589)
Erste Schritte mit Transformer-Prognosen auf Databricks
Bei so vielen Modelloptionen und weiteren, die noch kommen, ist die Kernfrage für die meisten Organisationen: Wie fängt man an, diese Modelle mit eigenen proprietären Daten zu evaluieren? Wie bei jedem anderen Prognoseansatz müssen Organisationen, die Zeitreihenprognosemodelle verwenden, ihre historischen Daten dem Modell präsentieren, um Vorhersagen zu erstellen. Diese Vorhersagen müssen sorgfältig evaluiert und schließlich in nachgelagerte Systeme integriert werden, um sie nutzbar zu machen.
Aufgrund der Skalierbarkeit von Databricks und der effizienten Nutzung von Cloud-Ressourcen nutzen viele Organisationen es seit langem als Grundlage für ihre Prognosearbeit und erstellen täglich oder sogar häufiger Millionen von Prognosen, um ihre Geschäftsabläufe zu steuern. Die Einführung einer neuen Klasse von Prognosemodellen ändert nichts an der Natur dieser Arbeit, sondern bietet diesen Organisationen lediglich mehr Optionen, dies in dieser Umgebung zu tun.
Das bedeutet nicht, dass es keine neuen Herausforderungen mit diesen Modellen gibt. Viele dieser Modelle basieren auf einer Deep-Neural-Network-Architektur und funktionieren am besten, wenn sie auf einer GPU eingesetzt werden. Im Fall von TimeGPT können API-Aufrufe an eine externe Infrastruktur Teil des Prognoseprozesses sein. Grundsätzlich bleibt jedoch das Muster unverändert, die historischen Zeitreihendaten einer Organisation zu speichern, diese Daten einem Modell zu präsentieren und die Ausgabe in einer abfragbaren Tabelle zu erfassen.
Um Organisationen zu helfen zu verstehen, wie sie diese Modelle in einer Databricks-Umgebung nutzen können, haben wir eine Reihe von Notebooks zusammengestellt, die zeigen, wie Prognosen mit jedem der vier oben beschriebenen Modelle generiert werden können. Praktiker können diese Notebooks kostenlos herunterladen und in ihrer Databricks-Umgebung verwenden, um sich mit ihrer Anwendung vertraut zu machen. Der präsentierte Code kann dann an andere, ähnliche Modelle angepasst werden, was Organisationen, die Databricks als Grundlage für ihre Prognosebemühungen nutzen, zusätzliche Optionen für den Einsatz von generativer KI in ihren Ressourcenplanungsprozessen bietet.
Beginnen Sie noch heute mit Databricks für die Prognosemodellierung mit dieser Reihe von Notebooks.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.