Vom Lakehouse zum Digital Mind: Architektur eines Multi-Agenten-KI-Ökosystems auf Databricks Agent Bricks
Erfahren Sie, wie Edmunds sein Data Lakehouse mit Agent Bricks in eine intelligente Multi-Agenten-AI-Plattform für Aktivierung, Automatisierung und kontinuierliche Innovation verwandelt hat.
von Gregory Rokita
- Edmunds hat auf Databricks Agent Bricks ein AI-natives Multi-Agenten-Ökosystem aufgebaut und damit den Schritt von der passiven Datenspeicherung hin zu intelligenter Echtzeit-Automatisierung über alle Autokauffunktionen hinweg vollzogen.
- Spezialisierte Agenten wie DataDave erreichen eine Genauigkeit von 95 % bei komplexen Analysen, während Marketingkampagnen dank der Erkenntnisse aus dem einheitlichen Lakehouse verbesserte Konversionsraten erzielen.
- Die Architektur ermöglicht skalierbare Automatisierung, die Zusammenarbeit von Agenten sowie proaktive, personalisierte Erlebnisse sowohl für interne Teams als auch für Autokäufer.
In heutigen Unternehmen ist ein umfassendes, einheitliches Data Lakehouse entscheidend für die Aktivierung von Daten. Mit einem Lakehouse können Organisationen ein passives Repository in eine dynamische, intelligente Engine verwandeln, die Anforderungen antizipiert, spezialisiertes Wissen automatisiert und fundiertere Entscheidungen ermöglicht. Bei Edmunds führte diese Priorität zum Start von Edmunds Mind, unserer Initiative zum Aufbau eines hochentwickelten Multi-Agenten-AI-Ökosystems direkt auf der Databricks Data Intelligence Platform.
Diese architektonische Entwicklung wird durch einen entscheidenden Moment in der Automobilindustrie vorangetrieben. Drei wichtige Trends sind hierbei zusammengetroffen:
- Der Aufstieg von Large Language Models (LLMs) als leistungsstarke Reasoning-Engines
- Die Skalierbarkeit und Governance von Plattformen wie Databricks als sicheres Fundament
- Die Entstehung robuster agentenbasierter Frameworks zur Orchestrierung von Automatisierung. Diese Faktoren ermöglichen Systeme, die noch vor wenigen Jahren unvorstellbar erschienen wären
Bei dieser Transformation geht es nicht nur darum, ein weiteres AI-Tool hinzuzufügen, sondern auch darum, unsere Organisation grundlegend so umzugestalten, dass sie als AI-native agiert. Die Prinzipien, Komponenten und Strategien hinter diesem intelligenten Kern sind in unserem folgenden Architekturentwurf im Detail beschrieben.
„Databricks bietet uns ein sicheres, verwaltetes Fundament, um mehrere Modelle wie GPT-4o, Claude und Llama auszuführen und die Anbieter je nach Bedarf zu wechseln – und das alles bei gleichzeitiger Kostenkontrolle. Diese Flexibilität ermöglicht es uns, die Moderation von Bewertungen zu automatisieren und die Inhaltsqualität schneller zu verbessern, sodass Autokäufer früher vertrauenswürdige Einblicke erhalten.“—Gregory Rokita, VP of Technology, Edmunds
Vom datenreichen zum erkenntnisgesteuerten Unternehmen
Unsere Vision ist es, uns von einem datenreichen Unternehmen zu einer erkenntnisgesteuerten Organisation zu entwickeln. Wir nutzen AI, um das vertrauenswürdigste, personalisierteste und prädiktivste Autokauferlebnis der Branche zu schaffen.
Dies wird durch vier strategische Hauptsäulen realisiert:
- Daten in großem Maßstab aktivieren: Übergang von statischen Dashboards zu dynamischen, dialogbasierten Interaktionen mit Daten.
- Expertise automatisieren: Die unschätzbare Logik unserer Fachexperten in wiederverwendbare, autonome Agenten kodieren.
- Produktinnovationen beschleunigen: Unseren Teams ein Toolkit intelligenter Agenten an die Hand geben, um Funktionen der nächsten Generation zu entwickeln.
- Interne Abläufe optimieren: Erhebliche Effizienzsteigerungen durch die Automatisierung komplexer interner Workflows erzielen.
Das Herzstück dieser Vision ist unser wichtigster Wettbewerbsvorteil: der Edmunds Data Moat. Dieses starke Fundament an Automobildaten basiert auf unserem branchenführenden Gebrauchtwagenbestand, den umfassendsten Expertenbewertungen und erstklassigen Preisanalysen, ergänzt durch ausführliche Kundenbewertungen und Neuwagenangebote. Dieses gesamte Ökosystem ist in unserer Databricks-Umgebung vereinheitlicht und wird dort verwaltet, wodurch ein einzigartiges, leistungsstarkes Asset entsteht. Edmunds Mind ist die Engine, die wir entwickelt haben, um dieses Potenzial voll auszuschöpfen.
Ein Blick in das Digital Agent Framework
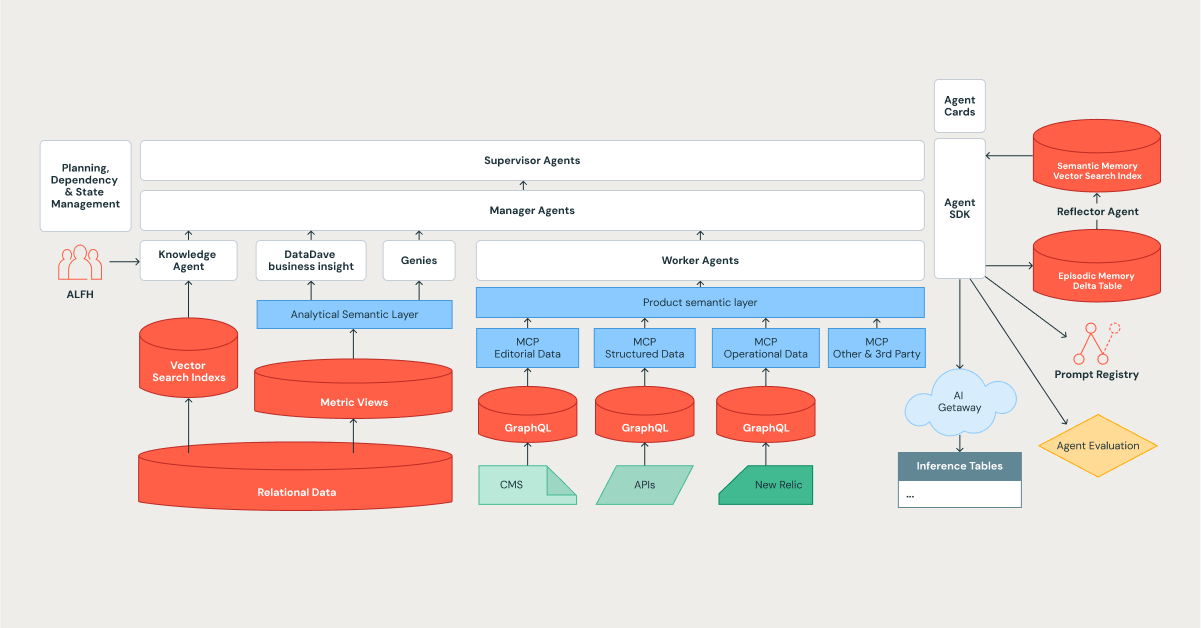
Die Architektur von Edmunds Mind ist ein hierarchisches, kognitives System, das auf Komplexität, Lernen und Skalierbarkeit ausgelegt ist, wobei die Databricks-Plattform als Fundament dient.
Die Agentenhierarchie: Eine Organisation digitaler Spezialisten
Wir haben unser System so konzipiert, dass es eine effiziente Organisation widerspiegelt. Dabei nutzen wir eine gestaffelte Struktur, in der Aufgaben zerlegt und delegiert werden. Dies passt perfekt zu den Orchestrator-Mustern in modernen Frameworks wie Databricks Agent Bricks.
- Supervisor-Agenten: Die strategischen Köpfe. Sie übernehmen die langfristige Planung, verwalten Abhängigkeiten und orchestrieren komplexe, mehrstufige Aufgaben.
- Manager-Agenten: Die Teamleiter. Sie koordinieren ein Team spezialisierter Agenten, um ein bestimmtes, klar definiertes Ziel zu erreichen.
- Worker- und spezialisierte Agenten: Dies sind die einzelnen Mitwirkenden, die spezialisiertes Fachwissen einbringen. Sie sind die Arbeitstiere des Systems und umfassen eine wachsende Liste von Spezialisten wie den Knowledge Assistant, DataDave und verschiedene Genies.
Die Kommunikation zwischen den Agenten wird durch ein standardisiertes Protokoll geregelt. Dies stellt sicher, dass Aufgabendelegationen und Datenübergaben strukturiert, typisiert und prüfbar sind, was für die Aufrechterhaltung der Zuverlässigkeit in großem Maßstab entscheidend ist.
Die Hierarchie ist zudem auf ein tolerantes Fehlerverhalten (Graceful Failure) ausgelegt. Wenn ein Manager-Agent feststellt, dass sein Team von Spezialisten eine Aufgabe nicht lösen kann, eskaliert er den gesamten Aufgabenkontext zurück an den Supervisor, einschließlich der in seinem episodischen Gedächtnis gespeicherten Fehlversuche. Der Supervisor kann dann mit einer anderen Strategie neu planen oder – was entscheidend ist – dies als neuartiges Problem kennzeichnen, das ein menschliches Eingreifen erfordert, um eine neue Fähigkeit zu entwickeln. Dies macht das System robust und zu einem lernenden Werkzeug, das uns hilft, die Grenzen seiner Kompetenz zu erkennen.
Deep Dive 1: Automatisierter Workflow zur Datenanreicherung
In der Vergangenheit war die Behebung von Ungenauigkeiten bei Fahrzeugdaten, wie z. B. falsche Farben auf einer Fahrzeugdetailseite, ein arbeitsintensiver Prozess, der eine manuelle Abstimmung zwischen mehreren Teams erforderte. Heute automatisiert und löst das AI-Ökosystem von Edmunds Mind diese Herausforderungen nahezu in Echtzeit. Diese betriebliche Effizienz wird durch unser zentralisiertes Model Serving erreicht, das unsere vielfältigen AI-Agenten-Funktionen in einer einzigen, konsistenten Umgebung konsolidiert, die sich je nach Bedarf automatisch skaliert. Diese Architektur befreit unsere Teams von operativem Aufwand, sodass sie sich darauf konzentrieren können, unseren Nutzern schnell einen Mehrwert zu bieten.
Der Behebungsprozess wird über einen gesteuerten Multi-Agenten-Workflow ausgeführt. Wenn ein Benutzer oder ein automatisches Überwachungssystem eine potenzielle Datenabweichung meldet, führt ein Supervisor-Agent sofort eine erste Einstufung (Triage) des Ereignisses durch. Er bewertet das Problem, leitet es an das entsprechende spezialisierte Team weiter und validiert die Aufgabenberechtigungen über den Unity Catalog für eine robuste Data Governance. Ein dedizierter Manager-Agent orchestriert dann eine Reihe spezialisierter Worker-Agenten, um Aufgaben auszuführen, die von der VIN-Dekodierung und dem Bildabruf bis hin zur AI-gestützten Farbanalyse und abschließenden Datenbankaktualisierungen reichen. Menschliche Data Stewards bleiben für die kritische Überprüfung unverzichtbar und verlagern ihren Fokus von der manuellen Intervention auf die wertschöpfende Freigabephase. Jede Interaktion und Entscheidung wird systematisch protokolliert, was eine umfassende Grundlage für kontinuierliches Lernen und zukünftige Prozessoptimierungen schafft.
Dieses Beispiel veranschaulicht wie das gesamte Ökosystem eine reale Aufgabe zur Datenqualität und -anreicherung von Anfang bis Ende (End-to-End) bewältigt.
- Event-Trigger: Eine Benutzerbeschwerde oder ein automatisches Überwachungssystem meldet ein potenzielles Datenqualitätsproblem (z. B. eine falsche Fahrzeugfarbe) auf einer Fahrzeugbeschreibungsseite.
- Triage und Orchestrierung: Ein Supervisor-Agent erfasst das Ereignis, erstellt eine verfolgbare Aufgabe und bewertet deren Priorität auf der Grundlage vordefinierter Geschäftsregeln.
- Delegierung an den Manager: Der Supervisor delegiert die Aufgabe an den Vehicle Data Manager Agent, nachdem er dessen Berechtigungen für den Zugriff auf und die Änderung von Fahrzeugdaten im Unity Catalog bestätigt hat.
- Koordinierte Aufgabenausführung: Der Manager-Agent orchestriert eine Reihe spezialisierter Worker-Agenten, um das Problem zu lösen: einen VIN-Dekodierungs-Agenten, einen Bildabruf-Agenten zum Abrufen von Fotos aus unserer Medienbibliothek, einen AI-gestützten Farbanalyse-Agenten zur Bestimmung der korrekten Farbe aus den Bildern und einen Datenkorrektur-Agenten zur Aktualisierung der Fahrzeugdatenbank.
- Human-in-the-Loop-Überprüfung: Bevor die Änderung live geht, kennzeichnet der Manager-Agent die automatisierte Änderung und benachrichtigt einen menschlichen Data Steward über eine Slack-Integration zur endgültigen Validierung.
- Lernen und Abschluss: Sobald der Steward die Aufgabe genehmigt, markiert der Supervisor sie als abgeschlossen. Die gesamte Interaktion – einschließlich der endgültigen menschlichen Genehmigung – wird nachverfolgt und im Langzeitgedächtnis (Long-Term Memory) protokolliert, um zukünftiges Lernen und Audits zu ermöglichen.
Deep Dive 2: Knowledge Assistant: Antworten in Echtzeit, vertrauenswürdige Markenstimme
Wo Kunden früher durch mehrere Edmunds-Dashboards navigieren oder den Edmunds-Support kontaktieren mussten, um Antworten zu erhalten, liefert der Knowledge Assistant jetzt sofortige, dialogbasierte Antworten, indem er auf das gesamte Datenspektrum von Edmunds zugreift. Dieser RAG-Agent ist auf die Markenstimme von Edmunds abgestimmt und führt Erkenntnisse aus Experten- und Kundenbewertungen, Fahrzeugspezifikationen, Medien und Echtzeitpreisen zusammen. Das Ergebnis sind schnellere, zufriedenstellendere Interaktionen für die Kunden, während das Support-Team weniger Zeit mit der Beantwortung grundlegender Anfragen verbringt.
Zu den wichtigsten Funktionen gehören:
- Personifizierung der Markenstimme: Der Agent ist präzise darauf abgestimmt, in der lebendigen, hilfreichen und vertrauenswürdigen Stimme zu kommunizieren, die Edmunds-Kunden seit Jahrzehnten kennen.
- Echtzeit-Datensynthese: Mit einer einzigen Abfrage kann der Assistent Informationen aus unseren unterschiedlichen Echtzeit-Datenquellen abrufen, synthetisieren und präsentieren. Dazu gehören Experten- und Kundenbewertungen, Fahrzeugspezifikationen, transkribierte Videoinhalte sowie aktuelle Preise und Angebote.
- Fortgeschrittene RAG-Funktionen: Wir arbeiten aktiv mit Databricks zusammen und nutzen AI Search, um die Grenzen unserer RAG-Implementierung zu erweitern. Wir konzentrieren uns auf die Verbesserung der Priorisierung der Aktualität von Inhalten und eine anspruchsvolle Metadatenfilterung, um sicherzustellen, dass die relevantesten und aktuellsten Informationen immer zuerst angezeigt werden.
Deep Dive 3: DataDaves „Generate-and-Critique“-Workflow
DataDave übernimmt nun komplexe Analysen, die zuvor zeitaufwändige manuelle Arbeit erforderten. Dieser Agent orchestriert einen strengen Workflow, bei dem jede Phase von einem spezialisierten Agenten bewertet wird, um eine Genauigkeit von 95 % bei den anspruchsvollsten Abfragen zu erzielen. DataDave kann proaktiv Chancen erkennen (z. B. die Kennzeichnung unterversorgter Händler für das Edmunds-Vertriebsteam), indem er Website-Traffic und demografische Daten synthetisiert. Dies ermöglicht es der Führungsebene von Edmunds, selbstbewusst von der Berichterstattung darüber, „was passiert ist“, zur Entscheidung darüber überzugehen, „was wir als Nächstes tun sollten“.
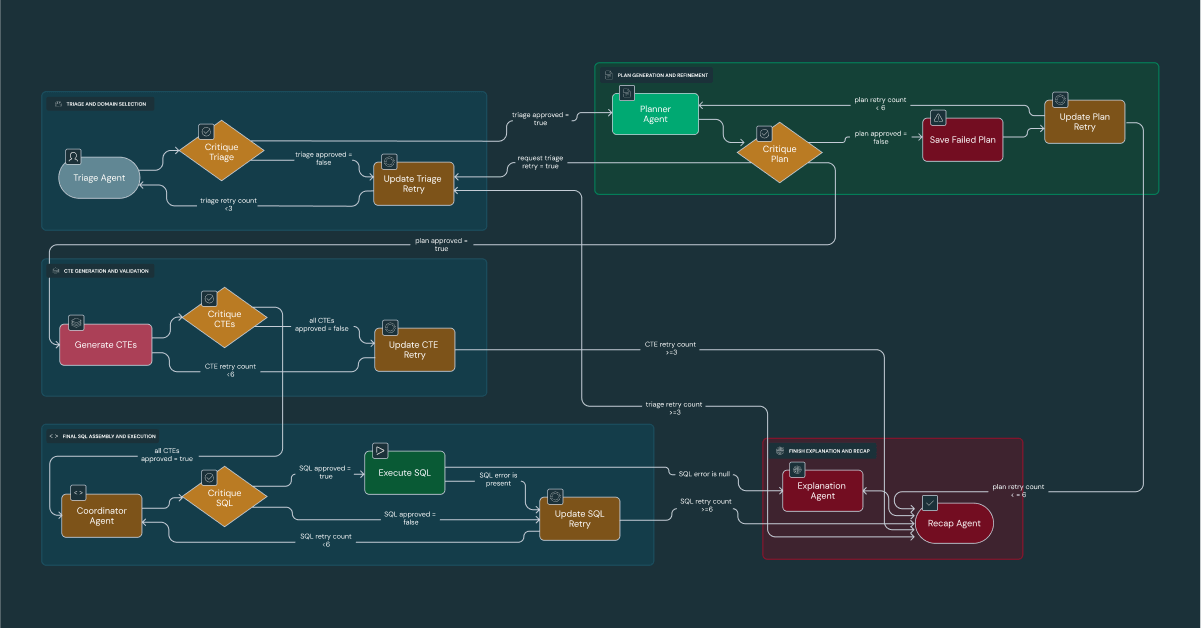
Der interne Workflow ist ein fünfphasiger Prozess aus Triage, Planung, Codegenerierung, Ausführung und Synthese, bei dem ein dedizierter Critique-Agent das Ergebnis jeder Phase validiert. Die wahre Stärke von DataDave liegt nicht nur in der Analyse interner Kennzahlen, sondern in der Fähigkeit, unsere proprietären Daten mit allgemeinem Weltwissen zu synthetisieren, um strategische Empfehlungen zu generieren. Beispielsweise kann DataDave durch die Korrelation der Website-Traffic-Daten von Edmunds mit geografischen und demografischen Daten Händler in unterversorgten Gebieten identifizieren und diese unserem Vertriebsteam proaktiv als leicht erreichbare Ziele empfehlen.
Deep Dive 4: Spezialisierung auf Preisgestaltung
Bei Edmunds gilt für uns ein Grundprinzip: Ein Preis ist nicht nur eine Zahl, sondern ein Ergebnis, das Kontext und Begründung erfordert, um vertrauenswürdig zu sein. Basierend auf unserem Ruf für die präziseste Preisgestaltung auf dem US-Markt ist unsere Agenten-Architektur darauf ausgelegt, dieses Vertrauen in großem Maßstab zu vermitteln.
Unsere Erfahrung bei der Weiterentwicklung eines monolithischen „Pricing Expert“ zu einem koordinierten Team von Spezialisten verdeutlicht dieses Prinzip. Dieses Team – orchestriert von einem Manager-Agenten und bestehend aus Experten wie einem True Market Value-Agenten, einem Depreciation-Agenten und einem Deal Rating-Agenten – liefert mehr als nur einen Listenpreis. Das Endergebnis ist eine umfassende, kontextualisierte Preisgeschichte, die erklärt, warum ein Fahrzeug auf eine bestimmte Weise bewertet wird.
Dies wandelt die Rolle unserer Preisanalysten von der manuellen Datenaggregation hin zu strategischer Aufsicht und Steuerung um. Durch die Nutzung von Databricks Agent Bricks können unsere Preisstatistiker diese hierarchischen Agententeams mit minimalem Programmieraufwand konfigurieren, was ihre Produktivität drastisch steigert und den Wartungsaufwand senkt. So können sie sich auf das konzentrieren, was wirklich zählt: das „Warum“ hinter den Zahlen.
Der kognitive Kern: Eine Architektur für sich aufbauende Intelligenz
Unsere Reise zu einem wirklich intelligenten KI-Ökosystem begann mit einer praktischen Herausforderung. Während wir spezialisierte Agenten wie DataDave für Geschäftsanalysen einsetzten, stellten wir fest, dass sie kritische, zeitkritische Geschäftserkenntnisse aufdeckten, die jedoch in ihrem operativen Kontext isoliert blieben. Beispielsweise könnte ein Agent einen anomalen Abwärtstrend in einem wichtigen Marketingkanal erkennen. Diese wichtige Erkenntnis muss jedoch effektiv an andere Einheiten – sowohl Agenten als auch Menschen – kommuniziert werden, um eine koordinierte Reaktion auszulösen. Dies verdeutlichte einen grundlegenden Bedarf: ein gemeinsames Speichersystem, das diese neu entstehenden Erkenntnisse erfassen und als Input für das gesamte Agentensystem zugänglich machen kann. Wir stellten uns eine kognitive Ebene vor, auf der sich dieses Wissen ansammeln, wachsen und genutzt werden kann, um unser gesamtes Ökosystem schrittweise intelligenter zu machen. Daher sieht unser aktueller Ansatz und Entwurf wie folgt aus.
- Episodisches Gedächtnis („Was passiert ist“): Ein hochpräzises Protokoll jeder Agentenaktion und -beobachtung, das als Ground Truth des Systems dient.
- Semantisches Gedächtnis („Was gelernt wurde“): Ein Vektorindex, der verallgemeinerte Erkenntnisse und erfolgreiche Strategien enthält, die aus episodischen Ereignissen synthetisiert wurden. Dies wird die Bibliothek für handlungsrelevantes Wissen sein.
- Automatische Gedächtniskonsolidierung: Ein im Hintergrund laufender „Reflector“-Agent überprüft regelmäßig das episodische Gedächtnis, um wichtige Erkenntnisse zu identifizieren und im semantischen Gedächtnis zu konsolidieren.
- Hierarchischer Gedächtniszugriff: Übergeordnete Agenten können auf die Gedächtnisse ihrer Untergebenen zugreifen, sodass ein Manager-Agent die Teamleistung analysieren und zukünftige Strategien optimieren kann. Diese Feedbackschleife ist zentral für die Antifragilität unseres Systems; jeder neuartige Fehler, der durch die Hierarchie eskaliert wird, ist nicht nur ein zu lösendes Problem, sondern ein Signal, das das gesamte Ökosystem trainiert und es schrittweise intelligenter und widerstandsfähiger macht.
Implementierung: mem0 + Databricks
Unsere Implementierung basiert auf Databricks AI Search unter Verwendung eines Delta Sync Index, der vollständig mit der mem0-Schnittstelle kompatibel ist. Da mem0 mit Vektordatenbanken interagiert, werden wir einen innovativen Weg gehen und sowohl episodische als auch semantische Gedächtnisse in einem einzigen, leistungsstarken Backend speichern. Unverarbeitete, nicht zusammengefasste Ereignisse („was passiert ist“) und synthetisierte Erkenntnisse („was gelernt wurde“) koexistieren als unterschiedliche Vektortypen in derselben Delta-Quelltabelle, die dann nahtlos und automatisch den AI Search-Index befüllt.
Diese vereinheitlichte Architektur schafft einen effizienten Workflow. Der Reflector-Agent kann den Index nach aktuellen episodischen Einträgen abfragen, seine Synthese durchführen und die neuen, verallgemeinterten semantischen Vektoren zurück in die Delta-Quelltabelle schreiben. Der Delta Sync Index übernimmt diese neuen Erkenntnisse dann automatisch und stellt sie für Abfragen zur Verfügung. Indem wir die Delta-Quelltabelle als einzigen Einstiegspunkt nutzen, eliminieren wir die Komplexität der Datenpipeline und gewinnen das skalierbare, serverlose und latenzarme Fundament, das für ein wirklich intelligentes Agentensystem erforderlich ist.
Beispiel-Workflow mit Edmunds Pulse
- Protokollieren: Der Agent „DataDave“ erkennt eine Vertriebsanomalie und protokolliert das Ereignis über die mem0-API in seinem episodischen Gedächtnis. Diese Aktion schreibt einen neuen Vektoreintrag in unsere Delta-Quelltabelle.
- Synthetisieren: Der Reflector-Agent verarbeitet dieses Ereignis, generiert eine verallgemeinerte Erkenntnis (z. B. „Umsatzrückgang von Produkt X an Wochenenden“) und wandelt sie in ein Vektor-Embedding um.
- Indizieren: Die neue Erkenntnis wird zurück in die Delta-Quelltabelle geschrieben, jedoch als synthetisierte Erkenntnis gekennzeichnet. Databricks AI Search synchronisiert diesen neuen Eintrag automatisch und indiziert ihn im semantischen Gedächtnis.
- Bereitstellen: Schließlich übermittelt ein dedizierter Edmunds Pulse-Agent, der das semantische Gedächtnis ständig auf hochprioritäre Informationen überwacht, dieses synthetisierte Ergebnis proaktiv an einen menschlichen Stakeholder. In Analogie zum ChatGPT Pulse-Release, das darauf abzielt, einen umgebungsbewussteren KI-Assistenten bereitzustellen, wird unser Edmunds Pulse als lebendiger „Puls“ des Unternehmens fungieren und sicherstellen, dass kritische Erkenntnisse nicht nur gespeichert, sondern aktiv kommuniziert werden, um zeitnahe und intelligente Maßnahmen anzustoßen.
Die Daten- und Wissensebene: Ein verwaltetes Fundament der Wahrheit
KI-Agenten sind auf die Qualität ihrer Daten angewiesen. Die Datenebene von Edmunds ist speziell auf Konsistenz, Governance und Flexibilität ausgelegt, wobei Unity Catalog als Eckpfeiler dient, um sicherzustellen, dass alle Informationen präzise und gut verwaltet bleiben.
Deep Dive 5: GraphQL-Datenzugriff und Interaktivitätsmuster
Das Edmunds Model Context Protocol (MCP)-Framework verbindet KI-Agenten sicher mit Echtzeit-Kontext aus allen Kerndatenquellen wie Fahrzeugspezifikationen, Bewertungen, Lagerbeständen und Betriebsmetriken aus Systemen wie New Relic. Dies wird über ein einheitliches GraphQL-API-Gateway erreicht, das die zugrunde liegende Komplexität abstrahiert und ein streng typisiertes, selbstdokumentierendes Schema bietet.
Anstatt dass sich Agenten oder Engineers mit fragmentierten Daten, unpassenden Schemata oder langsamer Fehlerbehebung herumschlagen müssen, unterstützt das System nun drei primäre Interaktionsmuster, die jeweils auf einen bestimmten Anwendungsfall abgestimmt sind:
- Dynamische Schema-Introspektion: Agenten können neue oder unbekannte Abfragen dynamisch untersuchen, indem sie das GraphQL-Schema selbst analysieren. Wenn ein Kunde eine spezifische Frage stellt – beispielsweise ob der Wert eines Autos durch aktuelle Sicherheitsrückrufe beeinflusst wird –, kann der Agent neue Datentypen direkt im laufenden Betrieb erkennen und präzise Abfragen erstellen, um die relevanten Antworten abzurufen. Diese Flexibilität ermöglicht es dem Unternehmen, sich schnell an neue Geschäftsanforderungen anzupassen, ohne dass manuelle API-Änderungen erforderlich sind.
- Granular zugeordnete Tools: Jedes Agenten-Tool ist für Routinevorgänge direkt einer bestimmten GraphQL-Abfrage oder -Mutation zugeordnet. Beispielsweise ist das Aktualisieren der Farbe eines Fahrzeugs so einfach wie das Extrahieren der VIN und der neuen Farbe, wobei der Agent die Mutation übernimmt. Dieser Ansatz erhöht die Zuverlässigkeit, reduziert manuelle Eingriffe und vereinfacht die täglichen Aufgaben des Teams.
- Persistente Abfragen: Funktionen mit hohem Datenverkehr und kritischer Performance, wie Echtzeit-Bestands-Dashboards, nutzen vorregistrierte Abfragen für maximale Effizienz. Der Agent sendet einen leichtgewichtigen Hash und Variablen, und das System liefert die Ergebnisse sofort bei reduzierter Bandbreite und erhöhter Sicherheit zurück.
Edmunds hat die Geschwindigkeit, Flexibilität und Zuverlässigkeit von Datenprozessen in Produkt- und Supportfunktionen drastisch verbessert, indem KI-Agenten über eine einzige, robuste API-Ebene strukturierter Zugriff auf alle Geschäftsdaten gewährt wird. Aufgaben, die zuvor eine maßgeschneiderte Entwicklung oder teamübergreifendes Debugging erforderten, werden jetzt in Echtzeit erledigt. So profitieren Kunden und interne Teams von tieferen Einblicken und agileren Reaktionen.
Deep Dive 6: Die Semantik- und Wissensebenen
Diese entscheidende Ebene dient als Brücke zwischen Rohdaten und dem Verständnis der Agenten. Sie abstrahiert die Komplexität der zugrunde liegenden Datenspeicher und reichert die Daten mit geschäftlichem Kontext an. So wird sichergestellt, dass Agenten auf einer konsistenten, kontrollierten und verständlichen Sicht des Edmunds-Universums arbeiten.
- Unity Catalog: Das Governance-Rückgrat: Als Herzstück unseres Daten-Ökosystems bietet Unity Catalog zentrale Governance, Sicherheit und Lineage für alle Daten- und KI-Assets. Es stellt sicher, dass alle Daten, auf die ein Agent zugreift, feingranularen Zugriffskontrollen unterliegen und ihr Weg vollständig nachvollziehbar ist – die unverzichtbare Grundlage für eine sichere und konforme KI-Plattform.
- Produkt-Semantikebene: Echtzeit-Geschäftskontext: Diese Ebene bietet Agenten eine objektorientierte Echtzeitansicht unserer Kernproduktentitäten (z. B. Fahrzeuge, Händler, Bewertungen). Entscheidend ist, dass sie direkt aus denselben GraphQL-Schemata gespeist wird, die auch die Edmunds-Website antreiben. Dies gewährleistet absolute Konsistenz: Wenn ein Agent über ein „Fahrzeug“ spricht, bezieht er sich auf dasselbe Datenmodell und dieselbe Geschäftslogik, die ein Verbraucher auf der Website sieht. Dadurch wird jegliches Risiko von Datenabweichungen (Data Drift) zwischen unseren externen Produkten und unserer internen KI ausgeschlossen.
- Analytische Semantikebene: Die Single Source of Truth für KPIs: Diese Ebene bietet eine konsistente und vertrauenswürdige Sicht auf alle geschäftlichen Leistungskennzahlen. Sie wird direkt aus unseren kuratierten Delta Metric Views gespeist – derselben Quelle, die auch alle Dashboards für die Geschäftsführung und den operativen Betrieb versorgt. Diese Abstimmung garantiert, dass DataDave oder andere Agenten bei der Berichterstattung über geschäftliche KPIs (wie Sitzungsverkehr, Leads oder Bewertungsraten) dieselben Definitionen und Datenquellen verwenden wie unsere etablierten Business-Intelligence-Tools, was eine Single Source of Truth im gesamten Unternehmen sicherstellt.
- Databricks AI Search – Die Engine für RAG: Diese Komponente ist die leistungsstarke Retrieval-Engine für unsere unstrukturierten und semistrukturierten Daten. Indem wir unseren riesigen Bestand an Bewertungen, Artikeln und transkribierten Inhalten in Vektoreinbettungen (Vector Embeddings) umwandeln, ermöglichen wir es Agenten wie dem Knowledge Assistant, blitzschnelle semantische Suchen durchzuführen. So wird der relevanteste Kontext abgerufen, um Benutzeranfragen in einem Retrieval-Augmented Generation (RAG)-Muster zu beantworten.
Vom Kostenfaktor zum Werttreiber: Messung unseres KI-ROI
Eine visionäre Architektur ist nur so gut wie ihre Umsetzung. Unser Ansatz basiert auf einer schrittweisen Roadmap und der festen Überzeugung, unser KI-Ökosystem als zentralen, wertschöpfenden Motor zu behandeln. Dies erreichen wir, indem wir unser technisches Framework für Observability, Governance und Ethik direkt mit wichtigen Geschäftsergebnissen verknüpfen. Unser Ziel ist es nicht nur, leistungsstarke KI zu entwickeln, sondern ihren Einfluss auf unser Geschäftsergebnis quantifizierbar zu machen.
Geschäftsdynamik beschleunigen
Wir haben ein ganzheitliches System entwickelt, um beide Seiten der ROI-Gleichung zu messen. Auf der Ertragsseite verknüpft unser Framework die KI-Leistung direkt mit den geschäftlichen KPIs. Zum Beispiel:
- Unser DataDave-Agent liefert komplexe, direkt nutzbare Analysen in wenigen Minuten – eine Aufgabe, für die menschliche Edmunds-Analysten zuvor Stunden benötigten. Dies beschleunigt die datengestützte Entscheidungsfindung drastisch.
- Unsere Preisgestaltungs-Agenten antworten sofort auf Anfragen, was stundenlange manuelle Recherchen überflüssig macht und unseren Teams den Rücken freihält, damit sie sich auf strategische, wertschöpfende Aufgaben konzentrieren können.
Obwohl wir die genauen Auswirkungen auf Kennzahlen wie die Kampagnen-Konversionsraten noch quantifizieren, liefert dieses Framework die Echtzeitdaten, die für den Nachweis dieser Korrelationen erforderlich sind.
Kosten optimieren
Über unser AI Gateway betreiben wir ein intelligentes wirtschaftliches Management. Wichtige Agenten wie DataDave werden an unsere leistungsstärksten Modelle geleitet, um Genauigkeit zu gewährleisten, während Routineaufgaben automatisch kostengünstigeren Modellen zugewiesen werden. Diese Modell-Tiering-Strategie ermöglicht es uns, unsere LLM- und Rechenausgaben präzise zu steuern und sicherzustellen, dass jeder investierte Dollar dem geschaffenen Geschäftswert entspricht.
„Databricks lässt uns das richtige Modell für die jeweilige Aufgabe ausführen – sicher und skalierbar. Diese Flexibilität treibt unsere Agenten an und sorgt für ein intelligenteres Autokauferlebnis.“ —Greg Rokita, VP of Technology, Edmunds
Organisatorische Befähigung: Jeden Mitarbeiter unterstützen
Um diese Vision zum Leben zu erwecken, fördern wir bei Edmunds eine Kultur der Innovation. Unser Ziel ist es, das gesamte Spektrum der Mensch-KI-Interaktion zu unterstützen – von vollständig autonomen Aufgaben über Human-in-the-Loop-Prüfungen bis hin zur kollaborativen Problemlösung.
Um dies zu unterstützen, stellen wir Engineers ein robustes Agent SDK zur Verfügung und fördern eine „Citizen Developer“-Bewegung über unsere Plattform Agent Bricks. Diese Initiative wurde mit unserer unternehmensweiten Tech-Konferenz „AI Agents @ Edmunds“ ins Leben gerufen und wird durch eine aktive LLM Agents Guild gefördert. So wird sichergestellt, dass jeder Mitarbeiter die Tools und die Unterstützung hat, um zu unserer KI-gesteuerten Zukunft beizutragen.
Der Weg in die Zukunft: Von proaktiver Intelligenz zu echter Autonomie
Unser Weg zu einem wirklich KI-nativen Unternehmen ist ein Marathon, kein Sprint. Die „Edmunds Mind“-Architektur dient uns dabei als Blaupause, und der nächste Evolutionsschritt besteht darin, proaktive Agenten zu entwickeln, die nicht nur Fragen beantworten, sondern auch geschäftliche Anforderungen antizipieren. Wir stellen uns eine Zukunft vor, in der unsere Agenten Marktchancen aus Echtzeit-Datenströmen identifizieren und den Stakeholdern strategische Erkenntnisse liefern, noch bevor diese danach fragen.
Letztendlich führt unsere Roadmap zu einem System, in dem sich Agenten selbst optimieren können – indem sie neue Tools vorschlagen, Kritikmechanismen verfeinern und sogar architektonische Verbesserungen anregen. Dies markiert den Übergang von einem System, das wir lediglich bedienen, zu einem echten kognitiven Partner. Unsere Rollen entwickeln sich dabei von Bedienern hin zu Aufsehern, Ethikern und Strategen einer neuen, intelligenten Belegschaft.
Erfahren Sie mehr darüber, wie Edmunds mithilfe von Databricks ein KI-gestütztes Autokauferlebnis aufbaut.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.