Beobachtbarkeit für jeden Agenten, überall: Produktionsbereites Tracing mit OpenTelemetry & Unity Catalog auf Databricks
OpenTelemetry-Traces in Unity Catalog schaffen einen kontinuierlichen Verbesserungs-Flywheel für KI-Agenten durch Analysen, Evals und Überwachung.
von Firas Farah, Bruno Faria und Anoop Sunke
- Das Problem: KI-Agenten generieren riesige Mengen an Tracedaten, aber herkömmliche Observability-Tools machen die Speicherung dieser Daten teuer, die Verwaltung schwierig und die Nutzung für Evaluierungs- und Analyse-Workflows mühsam.
- Die Lösung: Databricks unterstützt jetzt das Schreiben von OpenTelemetry (OTel)-Traces direkt in Unity Catalog-Tabellen über einen vollständig verwalteten, serverlosen Ingestionspfad.
- Der Vorteil: Durch die direkte Landung von Traces im Lakehouse erhalten Teams verwaltete, analysebereite Observability-Daten mit langfristiger Speicherung, vereinheitlichten Evaluierungs- und Überwachungsworkflows und keiner zu betreibenden OTel-Infrastruktur.
- Das Ergebnis: Produktions-Traces werden sofort für Analyse und Evaluierung nutzbar, was schnellere Iterationsschleifen zwischen realer Nutzung, Modellbewertung und kontinuierlicher Verbesserung ermöglicht.
Warum AI Tracing traditionelle Beobachtbarkeit durchbricht
Wenn KI-Anwendungen in die Produktion gehen, werden Traces zu einem der klarsten Wege, um zu verstehen, wie Agenten tatsächlich funktionieren, indem sie Prompts, Tool-Aufrufe, Antworten, Latenz und Ausführungspfade erfassen. Ohne starkes Tracing ist es schwierig zu verstehen, warum Agenten sich so verhalten, wie sie es tun, was das Debugging, die Bewertung und die Governance erheblich erschwert.
KI-Traces werden schnell wertvoll für Analyse-, Bewertungs- und Überwachungsworkflows, die über traditionelle Debugging- und Beobachtbarkeitsanwendungsfälle hinausgehen. Teams möchten sie länger aufbewahren, sie mit SQL analysieren, sie mit Geschäfts- und Modelldaten verknüpfen und sie für Bewertungen und Überwachung wiederverwenden. Wenn Traces nur innerhalb von Beobachtbarkeitssystemen leben, ist diese Flexibilität begrenzt, die Governance fragmentiert und die Datenübertragung in Analyse-Workflows erfordert oft zusätzliche Pipelines und Duplizierung, insbesondere wenn sensible Prompt-Daten beteiligt sind.
OTel Trace Ingestion
Databricks unterstützt jetzt das direkte Schreiben von OTel-Traces in Unity Catalog im OpenTelemetry (OTel)-Format. In der Praxis bedeutet dies, dass Traces in Echtzeit aufgenommen und in Delta-Tabellen gespeichert werden können, wo sie von der gleichen Skalierbarkeit, Governance und den gleichen Tools wie Ihre übrigen Daten profitieren.
Dies verändert die Art und Weise, wie Teams Tracedaten nutzen können:
- Echtzeit-Aufnahme mit praktischer Aufbewahrung: Traces können mit hohem Durchsatz geschrieben werden, während sie generiert werden, und langfristig aufbewahrt werden, ohne den Kostendruck, der typischerweise mit Beobachtbarkeitsplattformen verbunden ist.
- Analysieren und steuern mit dem Lakehouse: Sobald Traces in Tabellen vorhanden sind, können Sie sie wie jeden anderen Datensatz behandeln: sie mit SQL abfragen, Dashboards erstellen, ETL-Pipelines ausführen, Tools wie Genie verwenden und Governance-Kontrollen wie PII-Maskierung anwenden.
- Nutzen Sie den vollständigen MLflow-Evaluierungsstack: MLflow erleichtert die Suche, Filterung und Detailanalyse Ihrer Traces zum Debugging. Das Persistieren von Traces in Unity Catalog entfernt typische Experimentbeschränkungen (wie Trace-Limits), was die Durchführung großer Offline-Evaluierungen, die Überwachung von Produktionssystemen und die kontinuierliche Qualitätsverbesserung bei wachsenden Workloads erleichtert.
SaaS vs. Lakehouse
Warum also nicht vollständig auf ein SaaS-Beobachtungstool setzen?
- Aufbew{\"}bungsökonomie: Agenten generieren massive Text-Payloads. Die Speicherung dieser Daten in Delta Lake auf Objektspeicher ist oft erheblich kostengünstiger als SaaS-basierte Aufbewahrungsmodelle.
- Der PII-Deadlock: Das Senden von Roh-Prompts an Drittplattformen kann zu InfoSec-Reibungen führen. Das Aufbewahren von Traces in Unity Catalog hilft, die Datenhoheit zu wahren und die Governance zu vereinfachen.
- Analyse, nicht nur Telemetrie: Während SaaS-Tools für operative Metriken wie Latenz stark sind, bietet das Lakehouse eine Analyse-Engine. Sie können Traces mit Geschäftsdaten wie Umsatz und Konversionen verknüpfen, um die tatsächlichen Auswirkungen zu verstehen und über die Systemgesundheit hinauszugehen. Darüber hinaus ermöglicht Ihnen das Lakehouse, KI direkt auf Ihre Traces anzuwenden und Bewertungsframeworks zu erstellen, um die Systemqualität kontinuierlich zu verbessern.
Architektur: Serverless OpenTelemetry-Aufnahme
Databricks unterstützt die Aufnahme von OpenTelemetry (OTel)-Traces, Logs und Metriken direkt in Unity Catalog-Tabellen, wobei der OTel-Standard zur Trennung von Instrumentierung und Speicherung verwendet wird.
Databricks beseitigt die operative Komplexität traditioneller, mehrstufiger Telemetrie-Pipelines, indem es eine verwaltete Aufnahmeschicht bereitstellt, die transparent von Zerobus Ingest angetrieben wird. Zerobus Ingest fungiert als vollständig verwaltete, serverlose Aufnahmemaschine, die native Unterstützung für Standard-OpenTelemetry-Protokolle (OTLP) über gRPC für Open-Source-Kollektoren bietet, während seine REST-API-Funktionen eine nahtlose Integration mit Anwendungsframeworks wie MLflow ermöglichen. Anwendungen können Spans, Logs und Metriken direkt in Unity Catalog-Tabellen exportieren, wo die Daten im Delta-Format gespeichert werden. Mit einer „Single-Sink“-Architektur vereinfacht Zerobus Ingest die Beobachtbarkeit, indem Daten direkt in das Lakehouse gestreamt werden. Bestehende OTLP-kompatible Kollektoren können über gRPC direkt auf diesen Endpunkt zeigen und umgehen dabei vollständig zwischengeschaltete Nachrichtenbusse wie Kafka. Zerobus Ingest fungiert als Ihre Hochdurchsatz-Telemetrie-Pipeline und übernimmt Aufnahme und Dauerhaftigkeit ohne Infrastruktur-Overhead. Jeder OTel-kompatible Client kann Traces an diesen Endpunkt exportieren, einschließlich beliebter KI-Agenten-Frameworks in vielen Programmiersprachen.
Von dort werden Traces, Logs und Metriken zu First-Class-Daten im Lakehouse, die Ad-hoc-SQL-Analysen, Dashboards, nachgelagerte Analysen sowie MLflow-Evaluierungs- und Überwachungsworkflows ermöglichen. Die Vereinheitlichung Ihrer Telemetrie schafft einen kontinuierlichen Verbesserungs-Flywheel, bei dem Produktionsverhalten in Bewertung und Analyse einfließt, was wiederum zu schnellerer Iteration und besserer Agentenleistung führt.
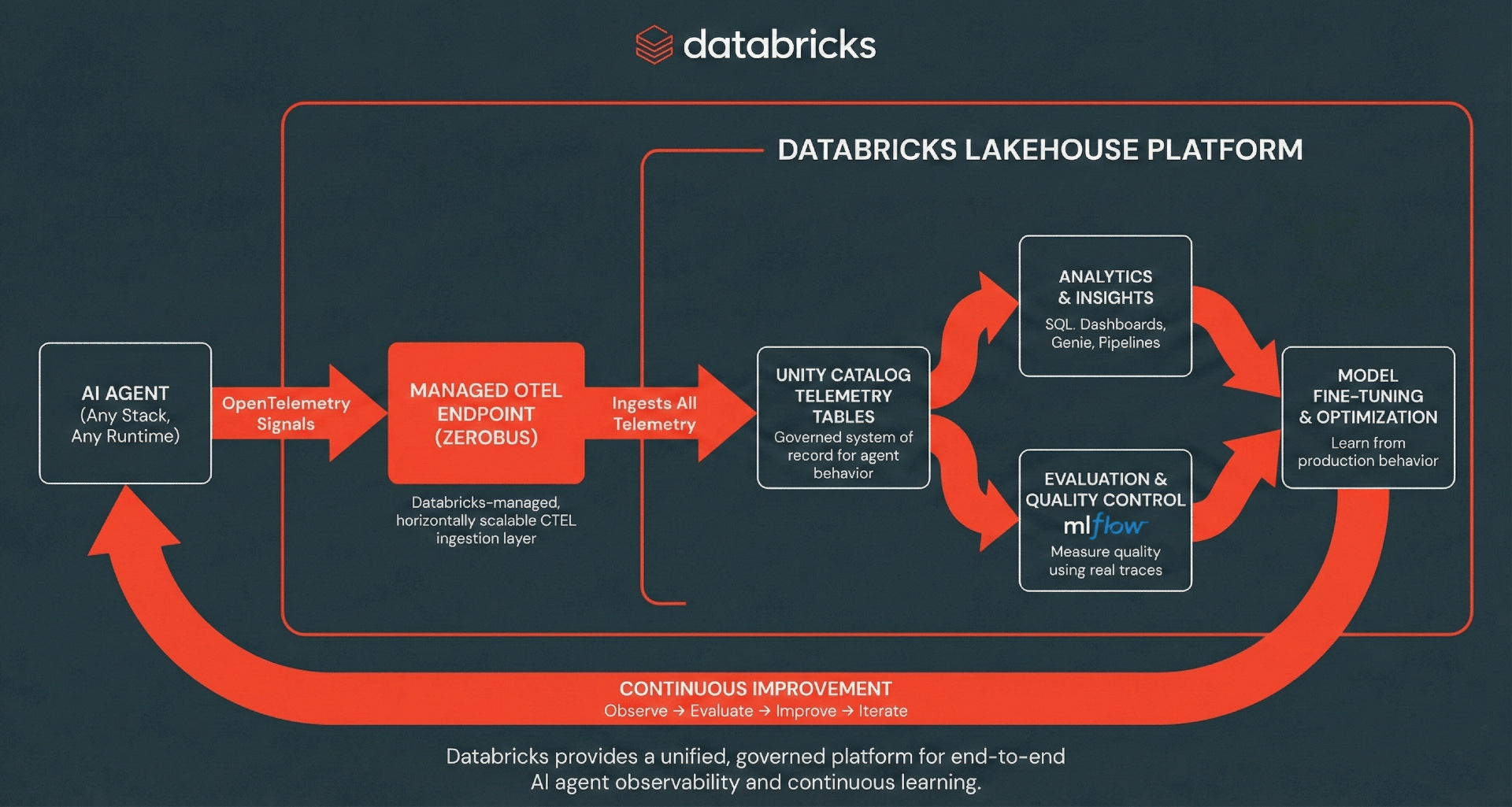
Tutorial: Traces ins Lakehouse verdrahten
Beispielagent: Support-Manager-Assistent
Für diesen Blog erstellen wir einen einfachen Support-Manager-Assistenten, mit dem wir das Ende-zu-Ende-Tracing demonstrieren können. Der Agent kann außerhalb von Databricks bereitgestellt werden, wie wir es hier getan haben, was hervorhebt, dass die Trace-Aufnahme von dem Ort entkoppelt ist, an dem der Agent ausgeführt wird.
Wir haben einen LangGraph-Agenten entwickelt, der von einem von Databricks gehosteten Claude Sonnet 4.6-Modell für die Entscheidungsfindung und Antwortgenerierung angetrieben wird. Der Agent ruft einen Genie Space als Tool auf, den Sie hier bereitstellen können.
Wenn ein Benutzer eine datengesteuerte Frage stellt, ruft der Agent Genie über die MCP-Tool-API auf. Genie übersetzt die Anfrage in SQL, führt sie gegen den Support-Datensatz aus und gibt das Ergebnis zurück. Der Agent fasst dann die Ergebnisse zusammen und liefert umsetzbare Erkenntnisse für einen Support-Manager.

OTel-Tracing mit UC einrichten
Bevor wir den Agenten instrumentieren, konfigurieren wir zunächst die Tabellen in UC, die OpenTelemetry-Traces speichern werden. In diesem Beispiel verwenden wir MLflow, um die zugrunde liegenden OpenTelemetry-Tabellen in Unity Catalog zu erstellen und sie mit einem MLflow-Experiment zu verknüpfen, damit Traces aus der Benutzeroberfläche gesucht, analysiert und kommentiert werden können. Identifizieren Sie zunächst (oder erstellen Sie) ein SQL-Warehouse und ein MLflow-Experiment und verwenden Sie dann die MLflow Python-Bibliothek, um die Unity Catalog-Tabellen bereitzustellen und das Schema mit dem Experiment zu verknüpfen. Für die vollständigen Schritte folgen Sie den Docs hier.
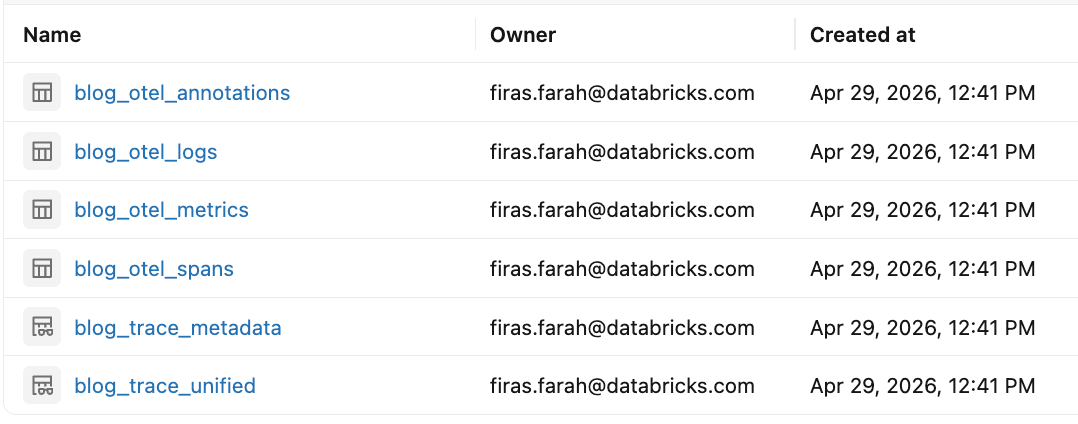
Diese Einrichtung erstellt Unity Catalog-Tabellen für OpenTelemetry-Spans, Logs und Metriken. Die zugrunde liegenden Daten werden in OpenTelemetry-kompatiblen Tabellenformaten gespeichert, und der MLflow-Dienst erstellt automatisch Databricks SQL-Ansichten daneben, die die OpenTelemetry-Daten in ein MLflow-freundliches Format für einfachere Abfragen und Analysen umwandeln. Dazu gehören:
<table_prefix>_otel_spans: detaillierte Daten auf Span-Ebene für jede Anfrage<table_prefix>_otel_logs: strukturierte Log-/Ereignisdaten, die während der Ausführung erfasst wurden<table_prefix>_otel_metrics: numerische Telemetrie, die während der Ausführung erfasst wurde<table_prefix>_otel_annotations: MLflow-spezifische Tracedaten, die kein Standard-OTel-Signal sind, einschließlich Metadaten, Tags, Bewertungen/Feedback, Erwartungen und Run-Links<table_prefix>_trace_unified: eine konsolidierte Ansicht, die Tracedaten zu einem einzigen Datensatz pro Trace zusammenstellt, einschließlich Roh-Span-Daten und Tracedaten-Metadaten<table_prefix>_trace_metadata: MLflow-Tags, Metadaten und Bewertungen, gruppiert nach Trace-ID; performanter als die einheitliche Ansicht, wenn Sie nur MLflow-Trace-Metadaten benötigen
Nachdem das Experiment eingerichtet ist, bleibt die Agenteninstrumentierung dieselbe. Jede OTel-kompatible Instrumentierungsbibliothek kann Traces an den konfigurierten Endpunkt exportieren. Sie können automatische und/oder manuelle Tracing durchführen, wie hier beschrieben. In unserem Beispiel verlassen wir uns auf mlflow.langchain.autolog(), um die detaillierte LangGraph-Ausführung (Modellaufrufe und Tool-Aufrufe) zu erfassen. Wir umschließen den Einstiegspunkt auch mit @MLflow.trace, um einen Root-Span auf Anforderungsebene zu erstellen, sodass jede Invocation als eine einzige End-to-End-Ausführung beobachtet werden kann.
Inspektion eines Beispiel-Trace
Jetzt, da der Agent instrumentiert ist und Traces in Unity Catalog fließen, werfen wir einen Blick auf eine reale Ausführung.
Für dieses Beispiel haben wir den Support Manager Assistant gefragt:
"Welchen Support-Ingenieur sollte ich für eine Beförderung vorschlagen?"
Der Agent wertete die Anfrage aus, rief mehrmals den Genie-Bereich auf, um unterstützende Daten zu sammeln, und gab eine Empfehlung basierend auf Leistungsmetriken zurück.

Während die Antwort einfach erscheint, zeigt der Trace den zugrunde liegenden Ausführungspfad, der sie erzeugt hat. Im MLflow-Experiment können wir jeden der Tool-Aufrufe sowie die Argumentationslogik unseres Claude Sonnet-Modells sehen. Wir können sehen, dass es dreimal den Genie-Bereich-Tool aufgerufen hat, bevor es eine endgültige Antwort zusammenstellte.
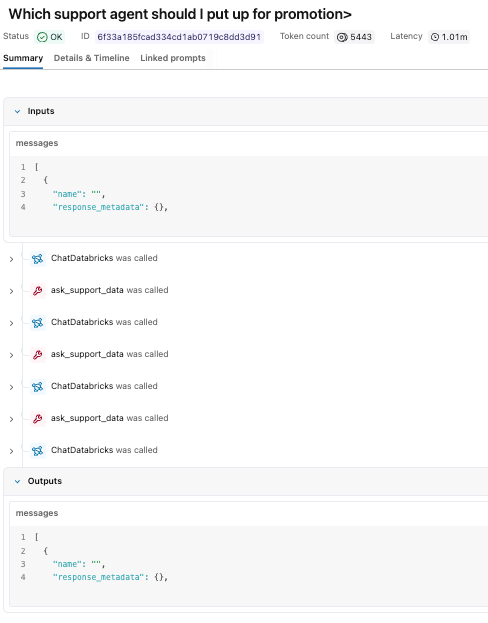
Wir können auf jeden der einzelnen Schritte klicken, um die Eingaben und Ausgaben zu untersuchen.
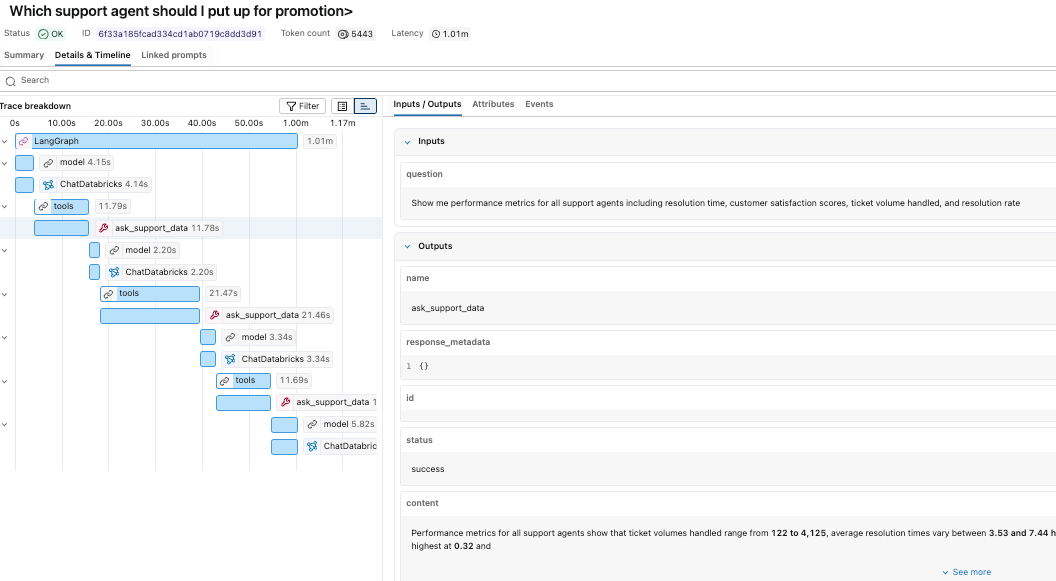
Da Traces als Delta-Tabellen gespeichert werden, können sie wie jede andere Datenmenge abgefragt werden. Wir können mit der mlflow_experiment_trace_unified-Ansicht beginnen, in der wir einen Datensatz finden, der die Anfrage, die Antwort, die Trace-Metadaten und ein Array der Spans enthält.
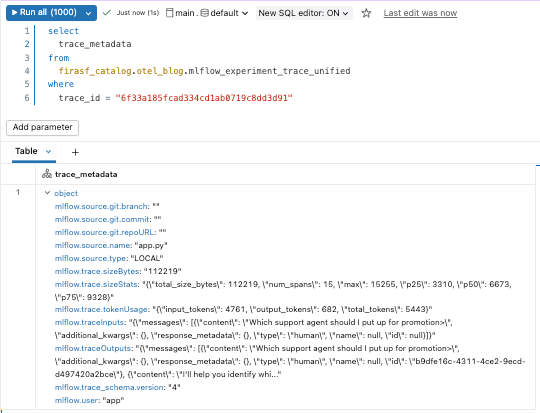
Über das Debugging hinaus: Analysen von Trace-Daten
Jetzt, da Traces in Unity Catalog gespeichert sind, sind sie sofort für Batch- und Streaming-Analysen verfügbar.
Governance in Unity Catalog
Prompts und Antworten enthalten jedoch oft sensible Informationen, daher ist die Behandlung von Trace-Daten als verwaltete Daten entscheidend. Durch die Speicherung in Unity Catalog erben Traces feingranulare Zugriffskontrollen, von Katalog- und Schema-Berechtigungen bis hin zu Spaltenmaskierung und zeilenweiser Filterung, was sichere, produktionsreife Analysen ohne Einschränkung der Flexibilität ermöglicht.
Sobald der Zugriff hergestellt ist, können Teams sichere Ad-hoc-Analysen durchführen, indem sie die zugrunde liegenden Tabellen und Ansichten mit SQL abfragen, wie wir oben getan haben. Wir können auch ETL-Pipelines sowie Dashboards und Genie-Bereiche für umsetzbare Geschäftseinblicke erstellen.
Dashboards
Die MLflow Experiment UI wird jetzt mit nativen Observability-Dashboards für Traces in Unity Catalog geliefert, einschließlich Ansichten für Trace-Volumen, Fehler, Latenz, Token-Nutzung und Kosten. Für die meisten Teams reicht dies aus, um den täglichen Agentenstatus zu überwachen.
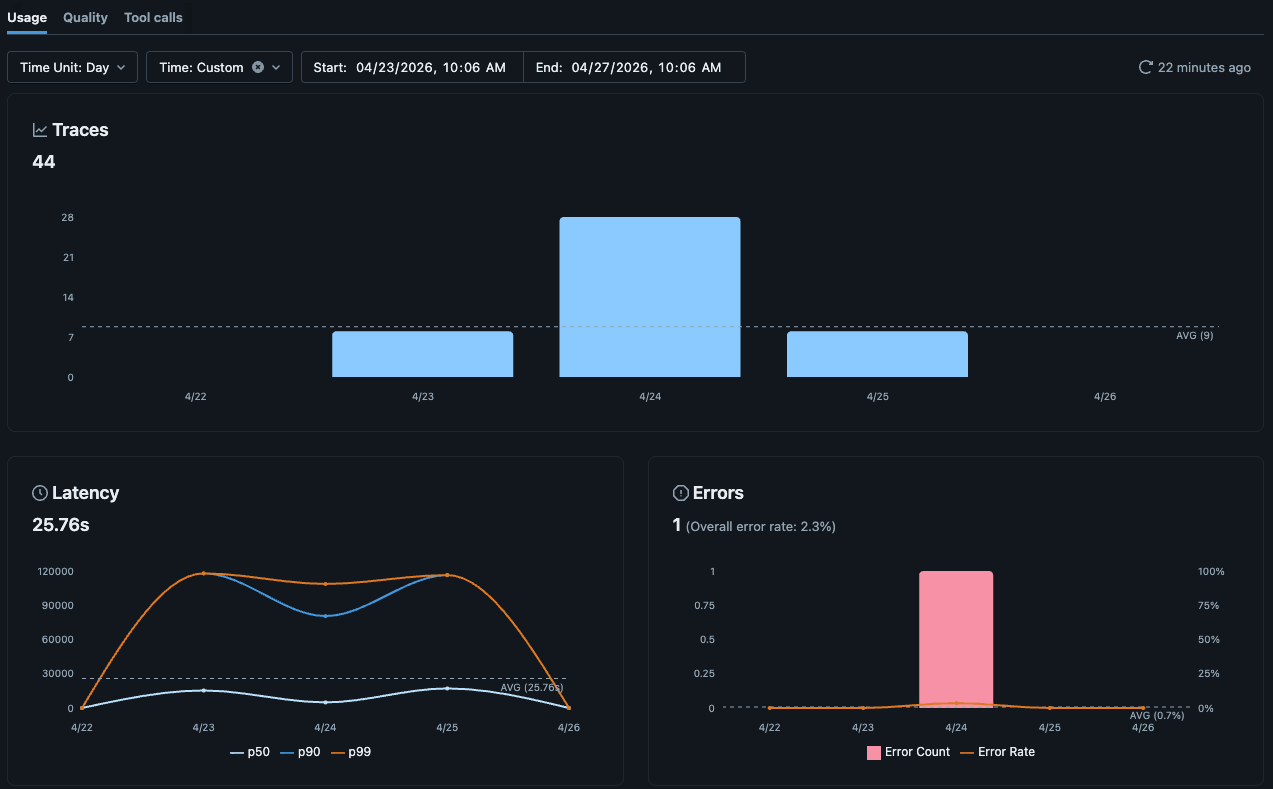
Wenn Sie eine Ansicht benötigen, die über die nativen Visualisierungen hinausgeht, sind die Trace-Tabellen immer noch nur Delta-Tabellen in Unity Catalog. Sie können ein benutzerdefiniertes KI/BI-Dashboard dagegen erstellen und Standard-SQL (mit Hilfe von KI) schreiben, um das zu modellieren, was Ihrem Team wichtig ist.
Um zu zeigen, was benutzerdefinierte Dashboards zusätzlich zu den nativen Ansichten leisten können, haben wir ein AI Operations Center auf unseren Trace-Tabellen aufgebaut. Nachfolgend sind einige erwähnenswerte Funktionen aufgeführt.
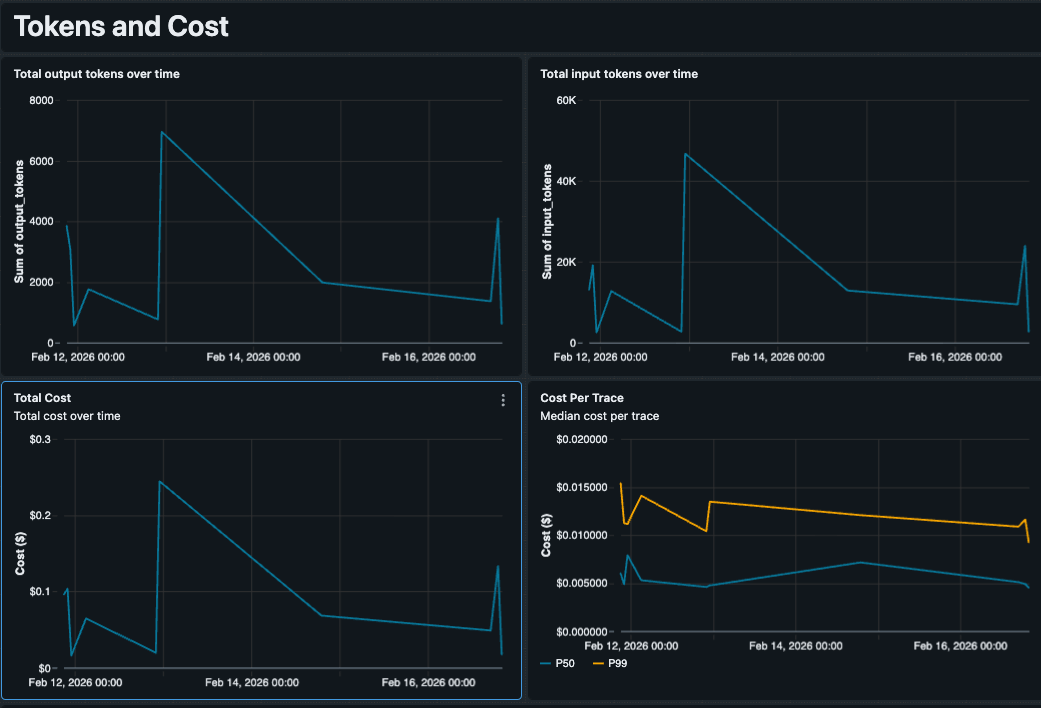
Benutzerdefinierte Kostenanalyse mit Vertragsbedingungen
Native Kostenmetriken basieren auf Standardlistenpreisen, die für Teams mit ausgehandelten Tarifen oder mit fein abgestimmten Modellen mit anderen Preisen abweichen können. Da wir die SQL-Abfrage kontrollieren, haben wir unsere Preislogik direkt in die Abfrage eingebettet. Das Dashboard verfolgt die Token-Nutzung nach Modelltyp (z. B. GPT 5.5 vs. Claude 4.6 Sonnet) und wendet unsere Vertragsbedingungen an, um geschätzte Kosten pro Trace zu ermitteln, die widerspiegeln, was wir tatsächlich bezahlen. Das macht es einfach, teure Ausreißer zu erkennen, wie eine einzelne komplexe Abfrage, die aufgrund einer Retrieval-Schleife 0,50 US-Dollar kostet.
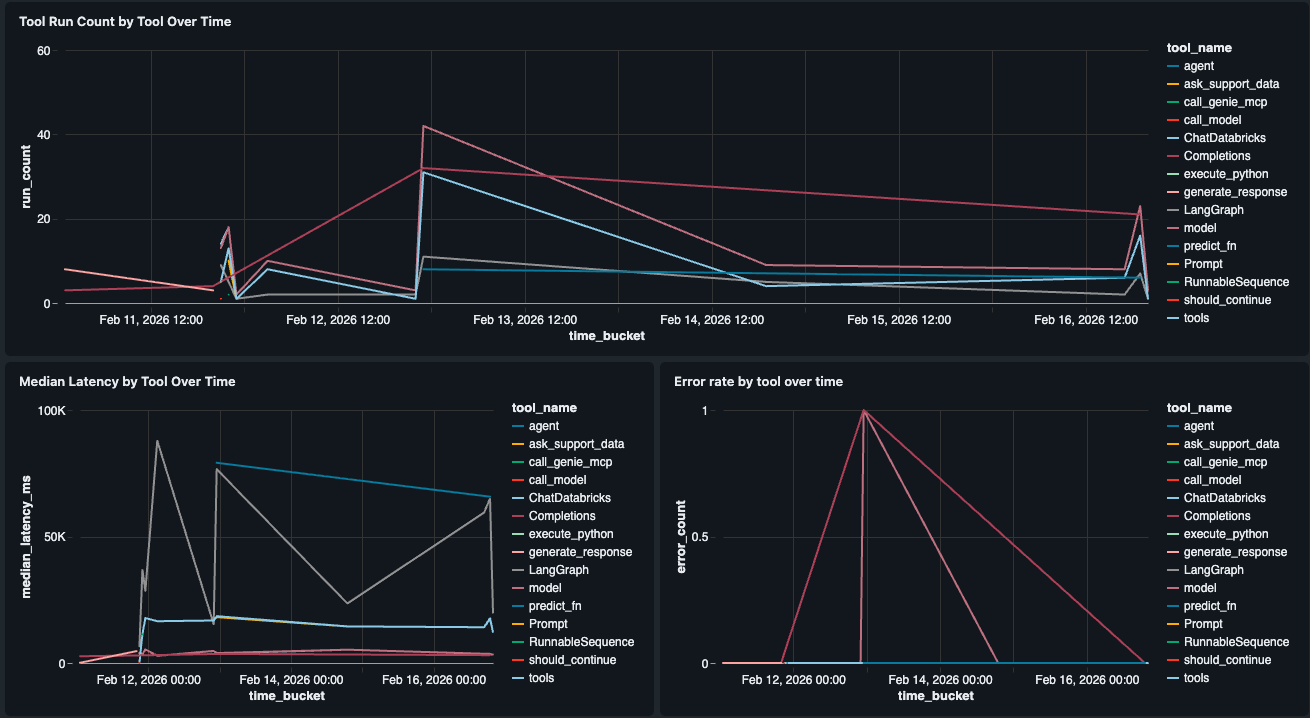
Komponentenbasierte Leistung
Native Latenzansichten zeigen P50/P99 auf Trace-Ebene. Um eine Ebene tiefer zu gehen und zu sehen, welches Tool langsam ist, haben wir ein Widget Tool Performance erstellt, das die Latenz (P50, P99) und Fehlerraten für jedes einzelne Tool im Agenten aufschlüsselt (z. B. retrieve_docs vs. generate_response). Das sagt uns, ob die LLM, ein Genie-Tool-Aufruf oder ein anderer Schritt der Engpass ist, sodass wir genau bestimmen können, wo die Benutzererfahrung beeinträchtigt wird.
Genie-Bereiche
Sowohl Geschäfts- als auch technische Stakeholder möchten oft das Agentenverhalten untersuchen, ohne SQL schreiben zu müssen. Durch die Bereitstellung von Trace-Tabellen über Genie können Teams natürlichsprachliche Analysen ihrer Telemetriedaten ermöglichen, sodass Benutzer Fragen zu Leistung, Tool-Nutzung, Latenz und Modellverhalten direkt stellen können. In unserem Beispiel könnten dazu Fragen gehören wie:
- Welche Arten von Anfragen erfordern eine Eskalation?
- Nehmen Tool-Wiederholungen zu?
- Welche Abfragen lösen die komplexesten Ausführungspfade aus?
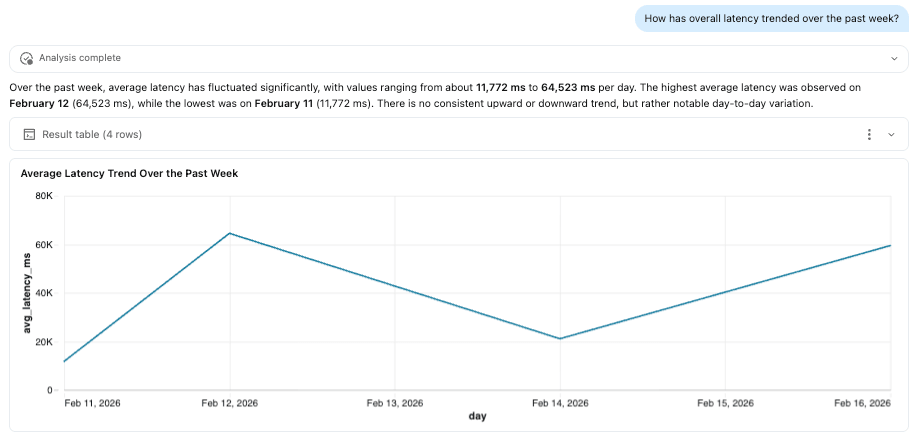
ETL-Pipelines
Da Traces als Delta-Tabellen gespeichert werden, können sie wie jede andere Datenmenge nachgelagerte ETL-Pipelines speisen. Durch die Aktivierung von Change Data Feed (CDF) können Teams Trace-Daten inkrementell verarbeiten, entweder im Batch oder im Streaming, ohne ganze Tabellen wiederholt zu scannen.
Dies ermöglicht die Operationalisierung der Observability. Eine Pipeline könnte beispielsweise Trace-Muster überwachen und Benachrichtigungen auslösen, wenn die Latenz definierte Schwellenwerte überschreitet, Tool-Fehler sprunghaft ansteigen oder die Token-Nutzung von erwarteten Basiswerten abweicht. Diese Signale können dann Dashboards, Benachrichtigungssysteme oder automatisierte Behebungs-Workflows speisen.
Wichtig ist, dass dies Echtzeit-Schutzmaßnahmen wie AI Guardrails ergänzt. Während Guardrails Richtlinien zur Laufzeit erzwingen, schaffen ETL-Pipelines eine Feedbackschleife, die Teams hilft, Trends zu analysieren, Richtlinien zu verfeinern und die Agentenleistung kontinuierlich zu verbessern.
Den Kreislauf schließen: Von Produktions-Traces zur Bewertung
Sobald Traces verfügbar sind, können sie den gesamten MLflow Evaluierungsstack befeuern und es Teams ermöglichen, die Qualität ihrer GenAI-Anwendungen über den gesamten Lebenszyklus hinweg zu messen, zu verbessern und zu erhalten. Evaluierung und Überwachung bauen direkt auf dem Tracing auf und ermöglichen es, dieselben Telemetriedaten, die während der Entwicklung, des Testens und der Produktion erfasst wurden, mit LLM-Juroren und benutzerdefinierten Metriken zu bewerten.
Während der Entwicklung bewerten
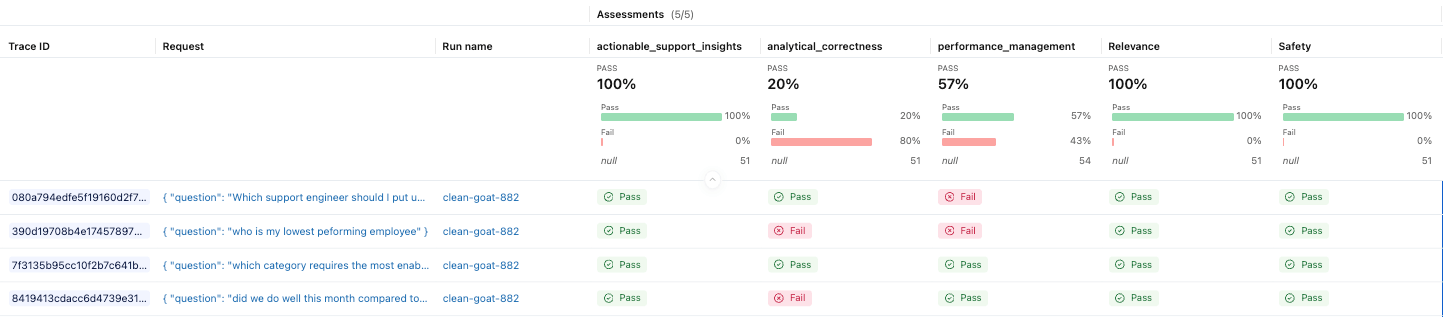
MLflow ermöglicht es uns, Bewertungen anhand eines Evaluationsdatensatzes durchzuführen und integrierte oder benutzerdefinierte Juroren anzuwenden, um die Antwortqualität zu bewerten. Ein effektiver Ansatz ist die Bootstrapping dieses Datensatzes aus realen Traces. Da diese Prompts aus tatsächlichen Benutzerinteraktionen stammen, repräsentieren sie die Szenarien, die Ihr Agent bewältigen muss, besser als rein synthetische Testfälle.
Unten erstellen wir einen Evaluationsdatensatz aus kürzlich erfassten Traces. MLflow verwendet ein SQL-Warehouse, um Datensatzdatensätze zu durchsuchen und zu materialisieren. Stellen Sie daher sicher, dass Sie die Warehouse-ID in Ihrer Umgebung konfigurieren.
Mit dem Datensatz an Ort und Stelle können wir die Juroren definieren, die unsere Anwendung bewerten werden. MLflow bietet eine Reihe von integrierten Juroren und ermöglicht es uns auch, benutzerdefinierte Richtlinien zu definieren, die auf das erwartete Verhalten unseres Agenten zugeschnitten sind.
Und wir können nun die Ergebnisse im MLflow-Experiment sehen.
Produktionsüberwachung
Entwicklungsbewertungen helfen uns, das Verhalten vor der Veröffentlichung zu validieren, aber die Produktionsüberwachung zeigt uns, wie die Anwendung mit echten Benutzern funktioniert. MLflow kann Live-Traces automatisch mit denselben Juroren auswerten und hilft uns, Regressionen, Drift und aufkommende Fehlermuster schnell zu erkennen. Dies macht die Auswertung von einer einmaligen Aufgabe zu einer fortlaufenden Praxis, während sich die Anwendung weiterentwickelt.
Kunden, die AI Observability auf Databricks nutzen
Experian
Der Übergang zum MLflow-Tracing für unseren Eva-Virtuelle-Assistenten und das Latte-Automatisierungssystem für E-Mails verlief nahtlos. Mit Traces in Unity Catalog verarbeitet unser Data-Science-Team Hunderttausende von Traces über verwaltete Delta-Tabellen und bewertet die Agentenqualität im großen Stil – alles, ohne Databricks zu verlassen. Da wir weitere wichtige Auswertungsworkflows integrieren, bedeutet die Tatsache, dass Tracing und Auswertungen auf einer einzigen, verwalteten Plattform verfügbar sind, dass wir nicht separate Tools für jede Phase des Agentenlebenszyklus pflegen müssen.—James Lin, Head of AI/ML Innovation, Experian
Superhuman (Grammarly)
Wir standardisieren auf MLflow-Tracing als Observability-Schicht für alle unsere KI-Agenten bei Superhuman. Wir bevorzugen die breitere Plattformintegration gegenüber dem Aufbau und der Wartung einer benutzerdefinierten oder punktuellen Lösung – diese Wartungsbelastung war ein echtes Problem für unsere Teams. Mit MLflow Traces in Unity Catalog können wir bis zu Hunderttausende von Traces pro Tag skalieren, und unsere Forscher können das Agentenverhalten direkt in der MLflow-Benutzeroberfläche selbstständig untersuchen, ohne technischen Support zu benötigen. Das Vorhandensein von Tracing, Auswertung und Überwachung auf einer einzigen, verwalteten Plattform ist genau das, was wir brauchten, um unsere Agenten mit Zuversicht in die Produktion zu überführen.—Martin Jewell, Lead MLE AI Infrastructure, Superhuman
SmartSheet
Wir haben Databricks als unsere Plattform für GenAI gewählt, und MLflow ist der Weg, wie unser Team KI-Agenten erstellt und bewertet. Während eines dreitägigen Co-Builds mit Databricks haben wir zwei Produktionsagenten mit MLflow-Tracing, Auswertungen, benutzerdefinierten Juroren und Labeling eingerichtet – und mit in Unity Catalog gespeicherten Traces können wir Zehntausende von Auswertungen durchführen und die Qualität mit Zuversicht iterieren, während wir skalieren.—Kapil Ashar, VP of Engineering, Smartsheet
The Standard
The Standard hilft unseren Kunden, finanzielle Wohlbefinden und Seelenfrieden zu erreichen. Daten und KI sind entscheidend, um diese Erfahrung im großen Stil zu ermöglichen. Durch die Einbettung von KI-Agentenfunktionen – wie der Extraktion von Schlüsselinformationen aus eingehenden Underwriting-Dokumenten und Anspruchseinreichungen – in wichtige Geschäftsfunktionen können wir unseren Kunden und Partnern außergewöhnlichen Service bieten. Mit Produktions-Tracing und -Überwachung können unsere Teams schnell verstehen, wie Systeme funktionieren, und zuverlässige Updates vornehmen. Durch die Verwaltung von Traces in Unity Catalog neben unseren übrigen Daten auf der Databricks Data Intelligence Platform können wir sicher abfragen, überwachen und iterieren – ohne unnötige Komplexität hinzuzufügen.—Porter Orr, AVP of AI and Automation, The Standard
Häufig gestellte Fragen (FAQ)
F: Kann ich dies für Agenten verwenden, die außerhalb von Databricks laufen?
A: Ja, der Agent kann überall laufen. Tatsächlich ist der Beispiel-Supportassistent, der für diesen Blog verwendet wurde, lokal bereitgestellt.
F: Was sind die Durchsatz- und Speicherlimits dieser Lösung?
A: Das Limit für den Aufnahmedurchsatz beginnt bei 200 QPS. Es gibt keine Speicherbeschränkung. Frühere Limits für Traces pro Experiment sind nicht mehr gültig. Wenn Sie höhere Durchsatzlimits benötigen, wenden Sie sich bitte an Ihr Databricks-Account-Team.
F: Was kann ich tun, um sicherzustellen, dass meine Suchanfragen, die MLflow-Experiment-Erfahrung und nachgelagerte Analysen performant bleiben?
A: Mit dem neuesten Produktupdate sind die Tabellen automatisch flüssig geclustert, um die Daten optimal zu organisieren. Für größere Trace-Volumen sollten Sie jedoch eine materialisierte Ansicht über den abgeleiteten Ansichten erstellen und diese inkrementell aktualisieren, um die Abfrageleistung aufrechtzuerhalten.
F: Wie werden hier PII behandelt, die in Benutzereingaben gefunden werden?
A: Diese Funktion wendet keine spezielle Behandlung für PII an. Die Daten werden jedoch in Unity Catalog gespeichert, wo Sie Governance-Funktionen wie feingranulare Zugriffskontrollen, Spaltenmaskierung und Zeilenfilterung nutzen können, um den nachgelagerten Zugriff zu verwalten und einzuschränken.
Erste Schritte
Um loszulegen, folgen Sie der Dokumentation.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.