So lesen Sie Unity Catalog-Tabellen in Snowflake in 3 einfachen Schritten
Unity Catalog funktioniert jetzt mit Snowflake, Dremio, Starburst, EMR und mehr – um Ihnen bei der Vereinheitlichung von Daten und KI zu helfen
von Aniruth Narayanan, Randy Pitcher, Susan Pierce und Ryan Johnson
Erfahren Sie, wie Sie von Snowflake aus eine Verbindung zu den Iceberg REST APIs von Unity Catalog herstellen, um eine einzelne Quelldatendatei als Iceberg zu lesen.
Update: Dieser Blog wurde aktualisiert, um die Unterstützung von Snowflake für vom Katalog bereitgestellte Anmeldeinformationen widerzuspiegeln.
Databricks hat die offene Lakehouse-Architektur für Daten pioniert und steht an der Spitze der Formatinteroperabilität. Wir freuen uns, dass mehr Plattformen die Lakehouse-Architektur übernehmen und interoperable Formate und Standards einführen. Interoperabilität ermöglicht es Kunden, teure Datenredundanzen zu reduzieren, indem sie eine einzige Datenkopie mit den Analyse- und KI-Tools ihrer Wahl für ihre Workloads verwenden. Insbesondere ein gängiges Muster für unsere Kunden ist die Nutzung der branchenführenden ETL-Preis-/Leistungsverhältnisse von Databricks für vorgelagerte Daten und der Zugriff darauf von BI- und Analysetools wie Snowflake.
Unity Catalog ist eine einheitliche und offene Governance-Lösung für Daten- und KI-Assets. Ein Hauptmerkmal von Unity Catalog ist die Implementierung der Iceberg REST Catalog APIs. Dies vereinfacht die Verwendung eines Iceberg-kompatiblen Lesers, ohne dass Ihre Metadaten-Speicherorte manuell aktualisiert werden müssen.
In diesem Blogbeitrag behandeln wir, warum der Iceberg REST Catalog nützlich ist, und gehen ein Beispiel durch, wie Unity Catalog-Tabellen in Snowflake gelesen werden können.
Hinweis: Diese Funktionalität ist über Cloud-Anbieter hinweg verfügbar. Die folgenden Anweisungen sind spezifisch für AWS S3, aber es ist möglich, andere Objektspeicherplattformen wie Azure Data Lake Storage (ADLS) oder Google Cloud Storage (GCS) zu verwenden.
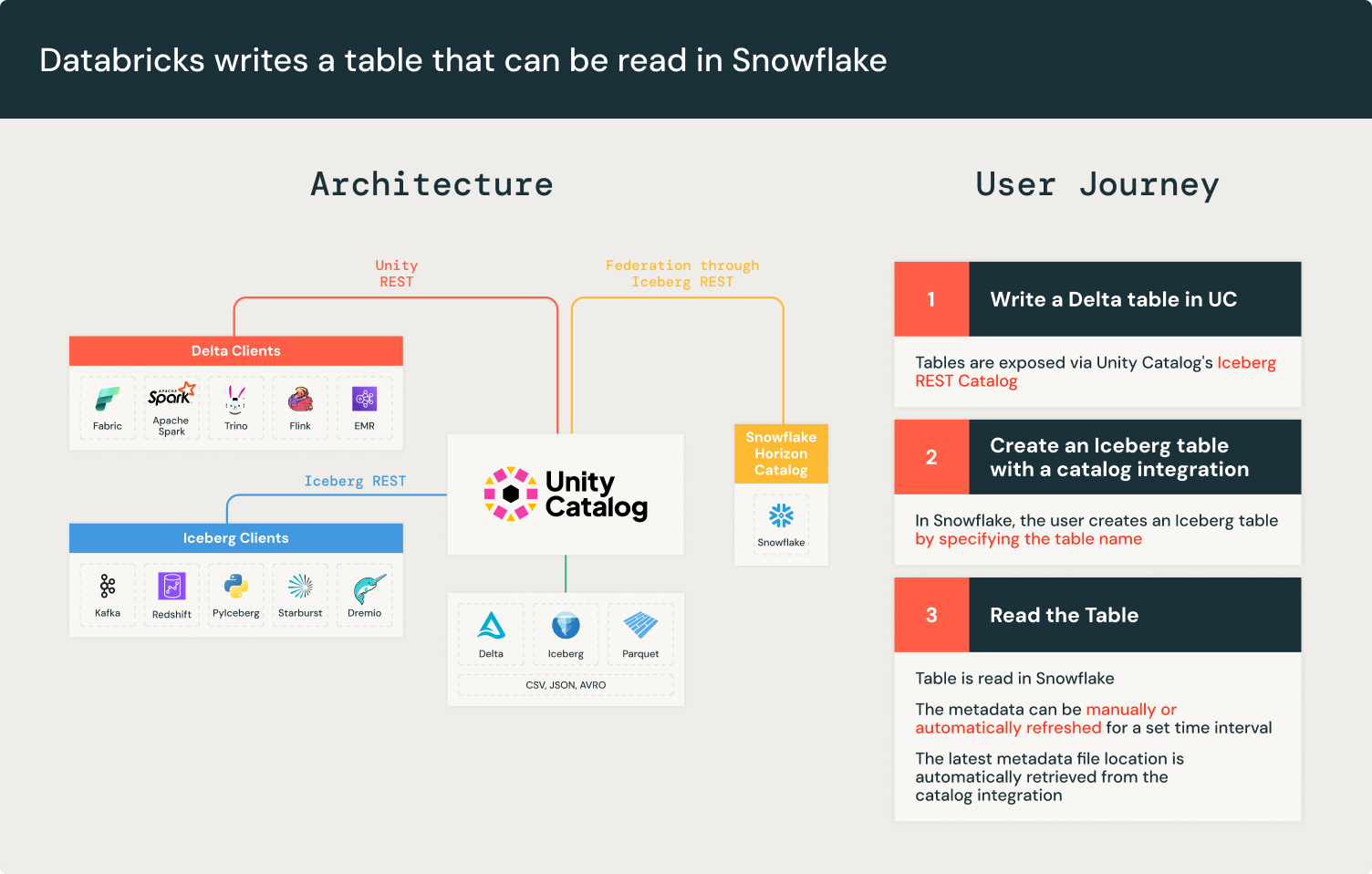
Iceberg REST API Katalogintegration
Apache Iceberg™ sorgt für Atomarität und Konsistenz, indem es für jede Tabellenänderung neue Metadatendateien erstellt. Dies stellt sicher, dass unvollständige Schreibvorgänge keine vorhandene Metadatendatei beschädigen. Der Iceberg-Katalog verfolgt die neuen Metadaten pro Schreibvorgang. Allerdings können nicht alle Engines mit jedem Iceberg-Katalog verbunden werden, was Kunden zwingt, den Speicherort der neuen Metadatendatei manuell zu verfolgen.
Iceberg löst die Interoperabilität zwischen Engines und Katalogen mit der Iceberg REST Catalog API. Der Iceberg REST-Katalog ist eine standardisierte, offene API-Spezifikation, die eine einheitliche Schnittstelle für Iceberg-Kataloge darstellt und Katalogimplementierungen von Clients entkoppelt.
Unity Catalog implementiert die Iceberg REST Catalog APIs seit der Einführung des Universal Format (UniForm) im Jahr 2023. Unity Catalog stellt die neuesten Tabellenmetadaten bereit und garantiert so die Interoperabilität mit jedem Iceberg-Client, der mit dem Iceberg REST Catalog kompatibel ist, wie z. B. Apache Spark™, Apache Trino und Snowflake. Die Iceberg REST Catalog Endpunkte von Unity Catalog ermöglichen externen Systemen den Zugriff auf Tabellen und profitieren von Leistungsverbesserungen wie Liquid Clustering und Predictive Optimization, während Databricks-Workloads weiterhin von erweiterten Unity Catalog-Funktionen wie Change Data Feed profitieren. Darüber hinaus erweitern die Unity Catalog Iceberg REST Catalog Endpunkte die Governance über bereitgestellte Anmeldeinformationen.
Snowflakes REST API-Katalogintegration ermöglicht die Verbindung mit den Iceberg REST APIs von Unity Catalog, um den neuesten Metadaten-Dateispeicherort abzurufen. Das bedeutet, dass Sie mit Unity Catalog Tabellen direkt in Snowflake lesen können.
Hinweis: Zum Zeitpunkt der Erstellung befindet sich die Unterstützung des Iceberg REST Catalog durch Snowflake in der Public Preview. Die Iceberg REST APIs von Unity Catalog sind jedoch allgemein verfügbar.
Es gibt 3 Schritte zur Erstellung einer REST-Katalogintegration in Snowflake:
- Aktivieren Sie UniForm für eine Delta Lake-Tabelle in Databricks, um Iceberg-Metadaten zu generieren
- Registrieren Sie Unity Catalog in Snowflake als Ihren Katalog
- Erstellen Sie eine Iceberg-Tabelle in Snowflake, damit Sie Ihre Daten abfragen können
Erste Schritte
Wir beginnen in Databricks mit unserer von Unity Catalog verwalteten Tabelle und stellen sicher, dass sie als Iceberg gelesen werden kann. Anschließend fahren wir mit Snowflake fort, um die restlichen Schritte abzuschließen.
Bevor wir beginnen, werden einige Komponenten benötigt:
- Ein Databricks-Konto mit Unity Catalog (Dies ist für neue Workspaces standardmäßig aktiviert)
- Ein AWS S3-Bucket und IAM-Berechtigungen
- Ein Snowflake-Konto, das auf Ihre Databricks-Instanz und S3 zugreifen kann
Unity Catalog-Namensräume folgen dem Format katalog_name.schema_name.tabellen_name. Im folgenden Beispiel verwenden wir uc_catalog_name.uc_schema_name.uc_table_name für unsere Databricks-Tabelle.
Schritt 1: UniForm für eine Delta-Tabelle in Databricks aktivieren
In Databricks können Sie UniForm für eine Delta Lake-Tabelle aktivieren. Standardmäßig werden neue Tabellen von Unity Catalog verwaltet. Vollständige Anweisungen finden Sie in der UniForm-Dokumentation, sind aber auch unten aufgeführt.
Für eine neue Tabelle können Sie UniForm während der Tabellenerstellung in Ihrem Workspace aktivieren:
Wenn Sie eine vorhandene Tabelle haben, können Sie dies über einen ALTER TABLE-Befehl tun:
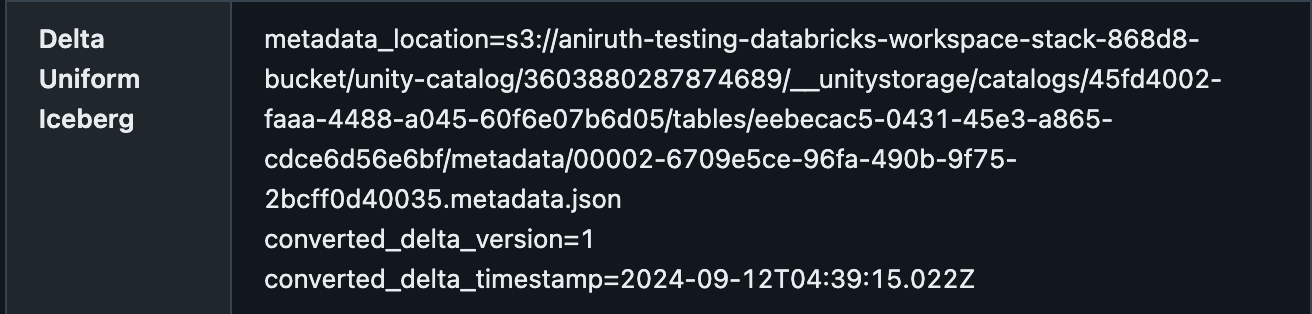
Sie können bestätigen, dass eine Delta-Tabelle UniForm aktiviert hat, im Catalog Explorer unter der Registerkarte Details, mit dem Metadaten-Speicherort. Es sollte ungefähr so aussehen:
Schritt 2: Unity Catalog in Snowflake registrieren
Während Sie sich noch in Databricks befinden, erstellen Sie einen Service Principal über die Workspace-Admin-Einstellungen und generieren Sie das dazugehörige Geheimnis und die Client-ID. Anstelle eines Service Principals können Sie auch persönliche Token zur Authentifizierung verwenden für Debugging- und Testzwecke. Wir empfehlen die Verwendung eines Service Principals für Entwicklungs- und Produktions-Workloads. Für diesen Schritt benötigen Sie Ihren <deployment-name> und die Werte für Ihre OAuth <client-id> und <secret>, damit Sie die Integration in Snowflake authentifizieren können.
Wechseln Sie nun zu Ihrem Snowflake-Konto.
Hinweis: Es gibt einige Namensunterschiede zwischen Databricks und Snowflake, die verwirrend sein können:
- Ein „Katalog“ in Databricks ist ein „Warehouse“ in der Snowflake Iceberg-Katalogintegrationskonfiguration.
- Ein „Schema“ in Databricks ist ein „catalog_namespace“ in der Snowflake Iceberg-Katalogintegration.
Sie werden im folgenden Beispiel sehen, dass der Wert CATALOG_NAMESPACE uc_schema_name aus unserer Unity Catalog-Tabelle ist.
In Snowflake erstellen Sie eine Katalogintegration für Iceberg REST-Kataloge. Nach diesem Prozess erstellen Sie eine Katalogintegration wie unten gezeigt:
Die REST API-Katalogintegration ermöglicht auch Vended Credentials und eine zeitbasierte automatische Aktualisierung.
Vended Credentials umfassen sowohl den Speicherort einer Tabelle als auch eine temporäre Zugriffsberechtigung für diesen Speicherort. Dies ermöglicht Clients den Zugriff auf Tabellen über den Katalog, ohne dass der direkte Zugriff des Clients auf den Speicherort der Tabelle konfiguriert werden muss. Wir empfehlen die Verwendung von Vended Credentials, um die Governance im Katalog zu vereinfachen und zu zentralisieren. Im obigen Beispiel konfigurieren wir Snowflake so, dass die Vended Credentials von Unity Catalog mit dem Parameter ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS im REST_CONFIG-Objekt verwendet werden.
Derzeit unterstützt Snowflake Vended Credentials nur für Tabellen in AWS S3. Für Tabellen in Azure Data Lake Storage (ADLS) oder Google Cloud Storage (GCS) benötigt Snowflake direkten Zugriff auf den Speicherort der Tabelle mit einem externen Volume.
Mit der automatischen Aktualisierung fragt Snowflake den neuesten Metadatenstandort von Unity Catalog in einem Zeitintervall ab, das für die Katalogintegration definiert ist. Die automatische Aktualisierung ist jedoch mit der manuellen Aktualisierung inkompatibel, sodass Benutzer bis zum Zeitintervall nach einer Tabellenaktualisierung warten müssen. Der auf der Katalogintegration konfigurierte Parameter REFRESH_INTERVAL_SECONDS gilt für alle Snowflake Iceberg-Tabellen, die mit dieser Integration erstellt wurden. Er ist nicht pro Tabelle anpassbar.
Schritt 3: Erstellen Sie eine Apache Iceberg™-Tabelle in Snowflake
Erstellen Sie in Snowflake eine Iceberg-Tabelle mit der zuvor erstellten Katalogintegration, um eine Verbindung zur Delta Lake-Tabelle herzustellen. Sie können den Namen für Ihre Iceberg-Tabelle in Snowflake wählen; er muss nicht mit der Delta Lake-Tabelle in Databricks übereinstimmen.
Hinweis: Die korrekte Zuordnung für CATALOG_TABLE_NAME in Snowflake ist der Name der Databricks-Tabelle. In unserem Beispiel ist dies uc_table_name. Sie müssen den Katalog oder das Schema in diesem Schritt nicht angeben, da diese bereits in der Katalogintegration angegeben wurden.
Optional können Sie die automatische Aktualisierung über das Zeitintervall der Katalogintegration aktivieren, indem Sie AUTO_REFRESH = TRUE zum Befehl hinzufügen. Beachten Sie, dass bei aktivierter automatischer Aktualisierung die manuelle Aktualisierung deaktiviert ist.
Sie haben nun erfolgreich die Delta Lake-Tabelle in Snowflake gelesen.
Abschluss: Testen Sie die Verbindung
Aktualisieren Sie in Databricks die Delta-Tabellendaten, indem Sie eine neue Zeile einfügen.
Wenn Sie zuvor die automatische Aktualisierung aktiviert haben, wird die Tabelle im angegebenen Zeitintervall automatisch aktualisiert. Wenn nicht, können Sie die Aktualisierung manuell durch Ausführen von ALTER ICEBERG TABLE <snowflake_table_name> REFRESH aktualisieren.
Hinweis: Wenn Sie zuvor die automatische Aktualisierung aktiviert haben, können Sie den Befehl zur manuellen Aktualisierung nicht ausführen und müssen auf den Abschluss des automatischen Aktualisierungsintervalls warten, um die Tabelle zu aktualisieren.
Wir freuen uns über die fortgesetzte Unterstützung der Lakehouse-Architektur. Kunden müssen keine Daten mehr duplizieren, was Kosten und Komplexität reduziert. Diese Architektur ermöglicht es Kunden auch, das richtige Werkzeug für die richtige Arbeitslast zu wählen.
Der Schlüssel zu einem offenen Lakehouse ist die Speicherung Ihrer Daten in einem offenen Format wie Delta Lake oder Iceberg. Proprietäre Formate binden Kunden an eine Engine, aber offene Formate bieten Flexibilität und Portabilität. Unabhängig von der Plattform ermutigen wir Kunden, ihre Daten immer selbst zu besitzen, als ersten Schritt zur Interoperabilität. In den kommenden Monaten werden wir weiterhin Funktionen entwickeln, die die Verwaltung eines offenen Data Lakehouse mit Unity Catalog vereinfachen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.