Gemeinsame Cluster in Unity Catalog für den Sieg: Einführung von Cluster-Bibliotheken, Python-UDFs, Scala, Machine Learning und mehr
von Jakob Mund, Stefania Leone, Martin Grund, Herman van Hövell, Andrew Li und Sven Wagner-Boysen
Wir freuen uns, Ihnen mitteilen zu können, dass Sie dank neuer Sicherheits- und Governance-Funktionen in Unity Catalog noch mehr Workloads auf den hocheffizienten Multi-User-Clustern von Databricks ausführen können. Datenteams können jetzt SQL-, Python- und Scala-Workloads sicher auf gemeinsam genutzten Rechenressourcen entwickeln und ausführen. Damit ist Databricks die einzige Plattform in der Branche, die eine feingranulare Zugriffskontrolle auf gemeinsam genutzten Rechenressourcen für Scala-, Python- und SQL-Spark-Workloads bietet.
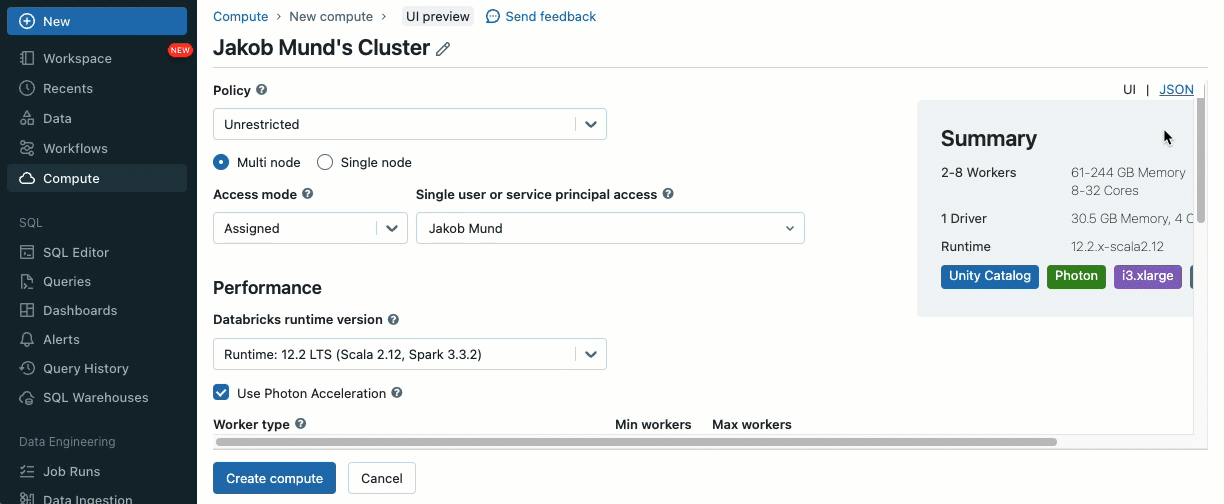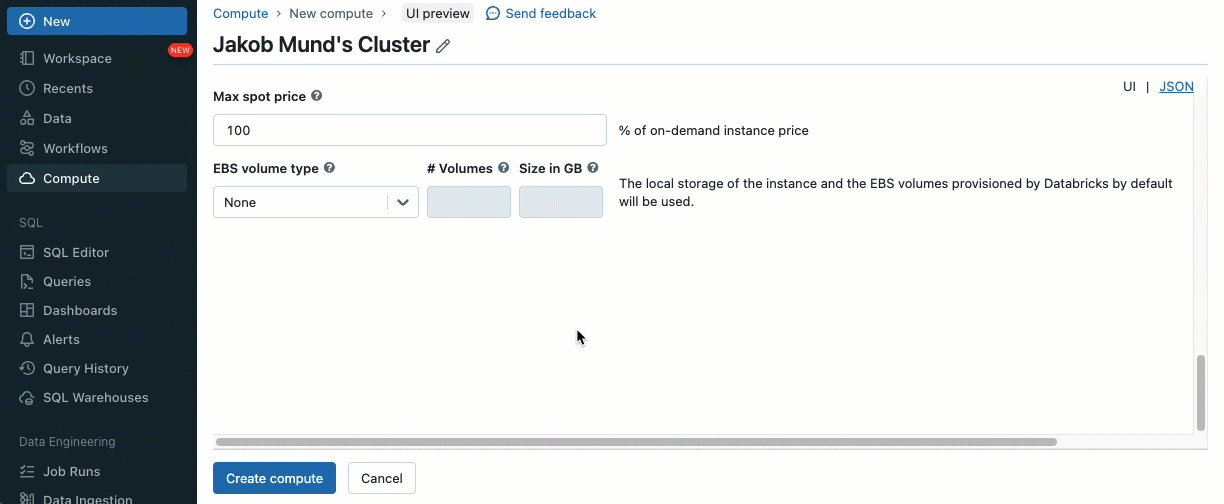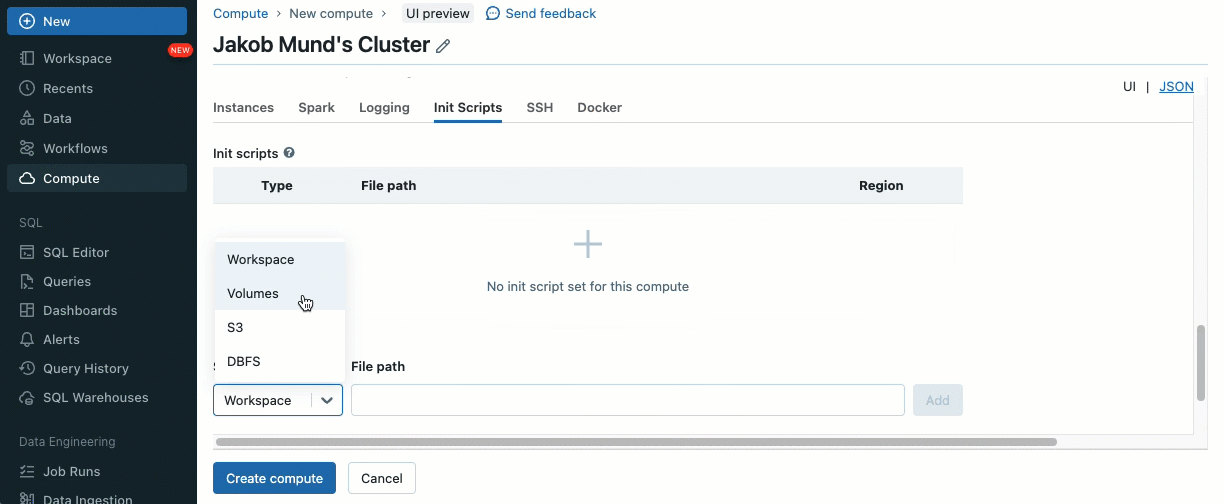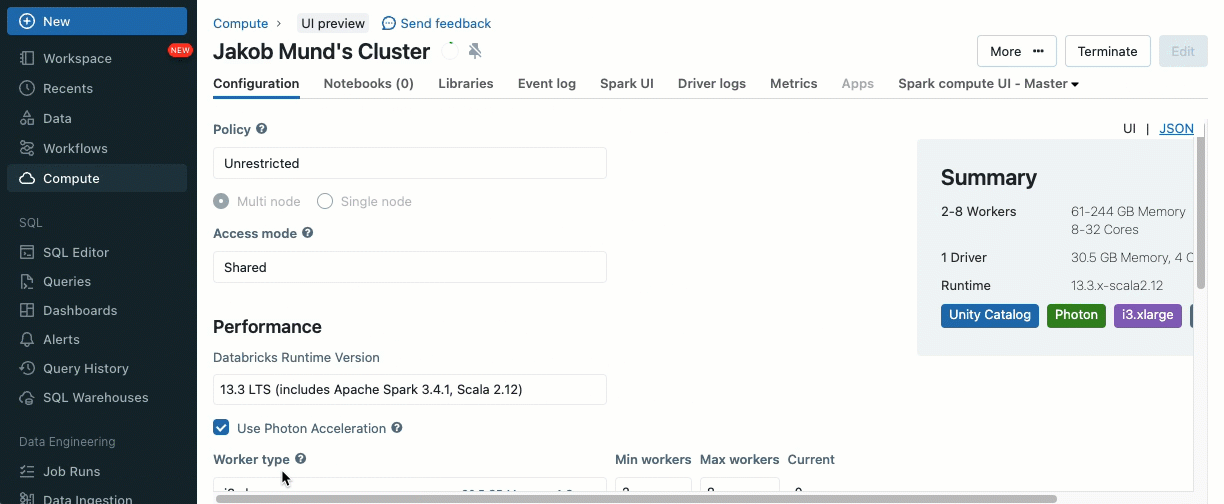
Ab Databricks Runtime 13.3 LTS können Sie Ihre Workloads dank der folgenden Funktionen, die auf gemeinsam genutzten Clustern verfügbar sind, nahtlos auf gemeinsam genutzte Cluster verschieben:
- Cluster-Bibliotheken und Init-Skripte: Optimieren Sie die Cluster-Einrichtung, indem Sie Cluster-Bibliotheken installieren und Init-Skripte beim Start ausführen, mit verbesserter Sicherheit und Governance, um zu definieren, wer was installieren darf.
- Scala: Führen Sie Multi-User-Scala-Workloads sicher neben Python und SQL aus, mit vollständiger Benutzercode-Isolation zwischen gleichzeitigen Benutzern und Erzwingung von Unity Catalog-Berechtigungen.
- Python und Pandas UDFs: Führen Sie Python- und (skalare) Pandas-UDFs sicher aus, mit vollständiger Benutzercode-Isolation zwischen gleichzeitigen Benutzern.
- Single-Node Machine Learning: Führen Sie scikit-learn, XGBoost, Prophet und andere beliebte ML-Bibliotheken auf dem Spark-Treiberknoten aus und verwenden Sie MLflow für die Verwaltung des End-to-End-Machine-Learning-Lebenszyklus.
- Structured Streaming: Entwickeln Sie Echtzeit-Datenverarbeitungs- und Analyselösungen mit Structured Streaming.
Einfacherer Datenzugriff in Unity Catalog
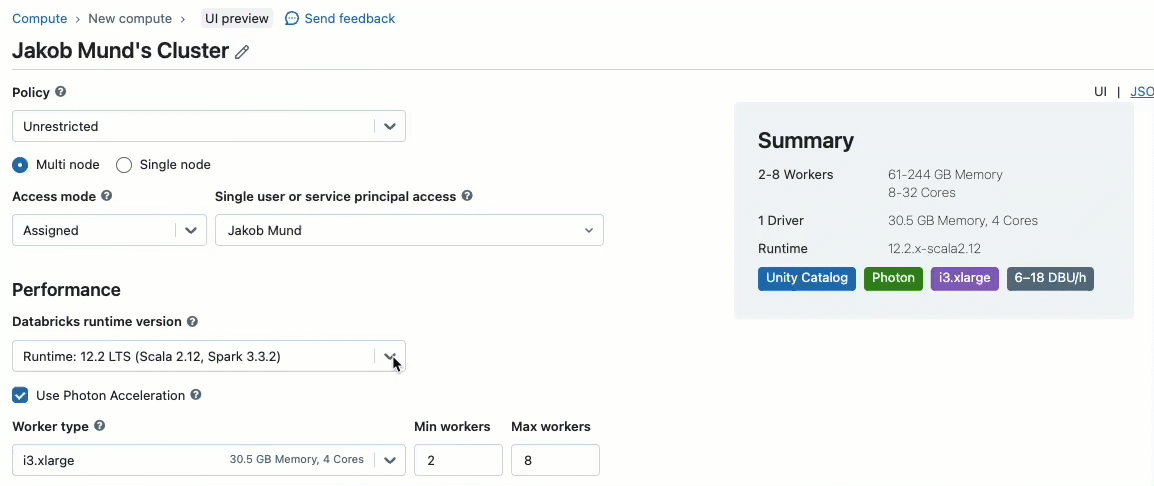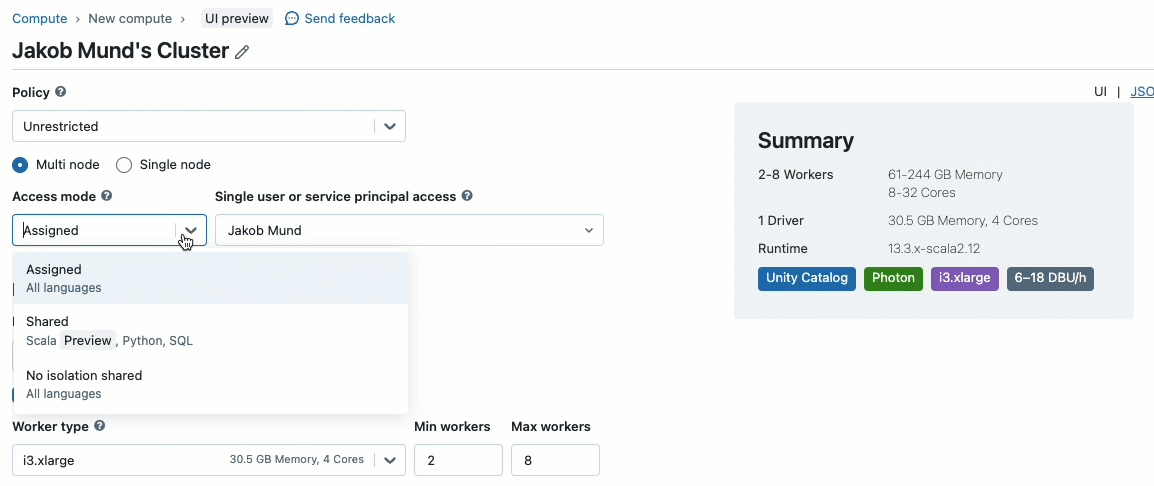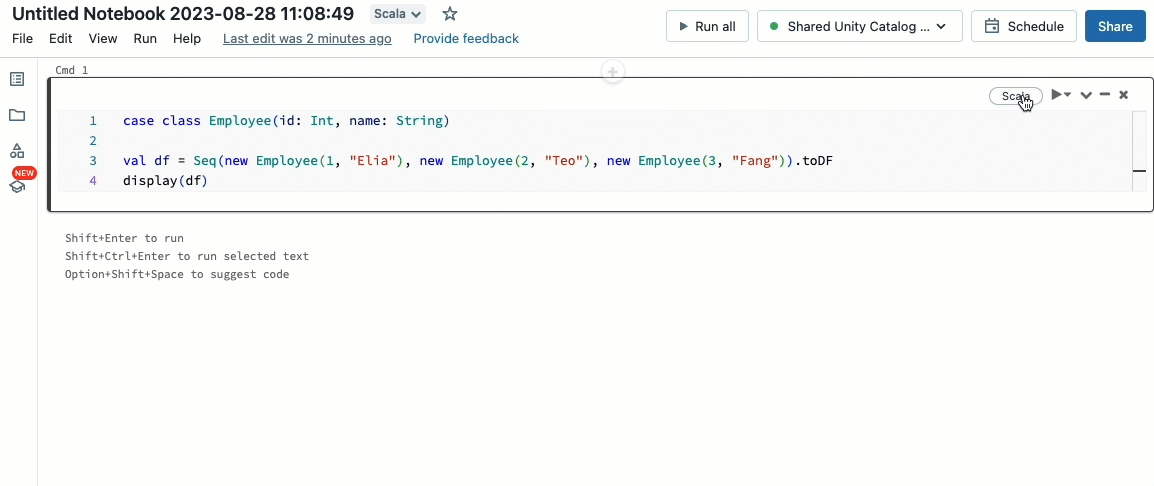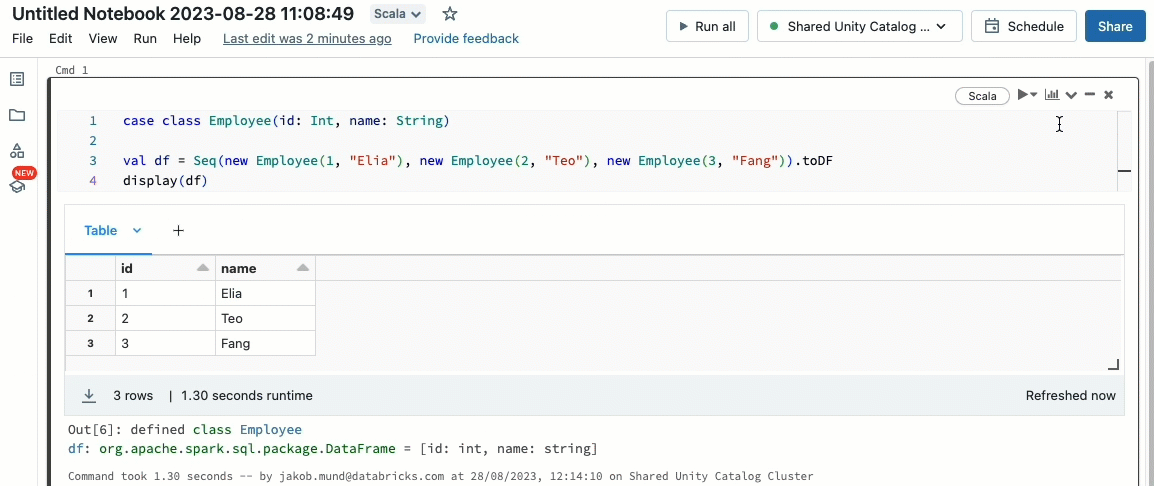
Beim Erstellen eines Clusters zur Arbeit mit von Unity Catalog verwalteten Daten können Sie zwischen zwei Zugriffsmodi wählen:
- Cluster im Shared-Zugriffsmodus – oder einfach gemeinsam genutzte Cluster – sind die empfohlenen Rechenoptionen für die meisten Workloads. Gemeinsam genutzte Cluster ermöglichen es einer beliebigen Anzahl von Benutzern, sich anzumelden und gleichzeitig Workloads auf derselben Rechenressource auszuführen, was erhebliche Kosteneinsparungen, eine vereinfachte Clusterverwaltung und eine ganzheitliche Daten-Governance, einschließlich feingranularer Zugriffskontrolle, ermöglicht. Dies wird durch die Benutzer-Workload-Isolation von Unity Catalog erreicht, die jeden SQL-, Python- und Scala-Benutzercode in vollständiger Isolation ohne Zugriff auf niedrigere Ressourcen ausführt.
- Cluster im Single-User-Zugriffsmodus werden für Workloads empfohlen, die privilegierten Maschinen-Zugriff erfordern oder RDD-APIs, verteiltes ML, GPUs, Databricks Container Service oder R verwenden.
Während Single-User-Cluster der traditionellen Spark-Architektur folgen, bei der Benutzercode auf Spark mit privilegiertem Zugriff auf die zugrunde liegende Maschine ausgeführt wird, stellen gemeinsam genutzte Cluster die Benutzerisolation dieses Codes sicher. Die folgende Abbildung veranschaulicht die Architektur und die Isolationsprimitive, die für gemeinsam genutzte Cluster einzigartig sind: Jeder clientseitige Benutzercode (Python, Scala) wird vollständig isoliert ausgeführt, und UDFs, die auf Spark-Executors ausgeführt werden, laufen in isolierten Umgebungen. Mit dieser Architektur können wir Workloads sicher auf denselben Rechenressourcen multiplexen und gleichzeitig eine kollaborative, kosteneffiziente und sichere Lösung anbieten.
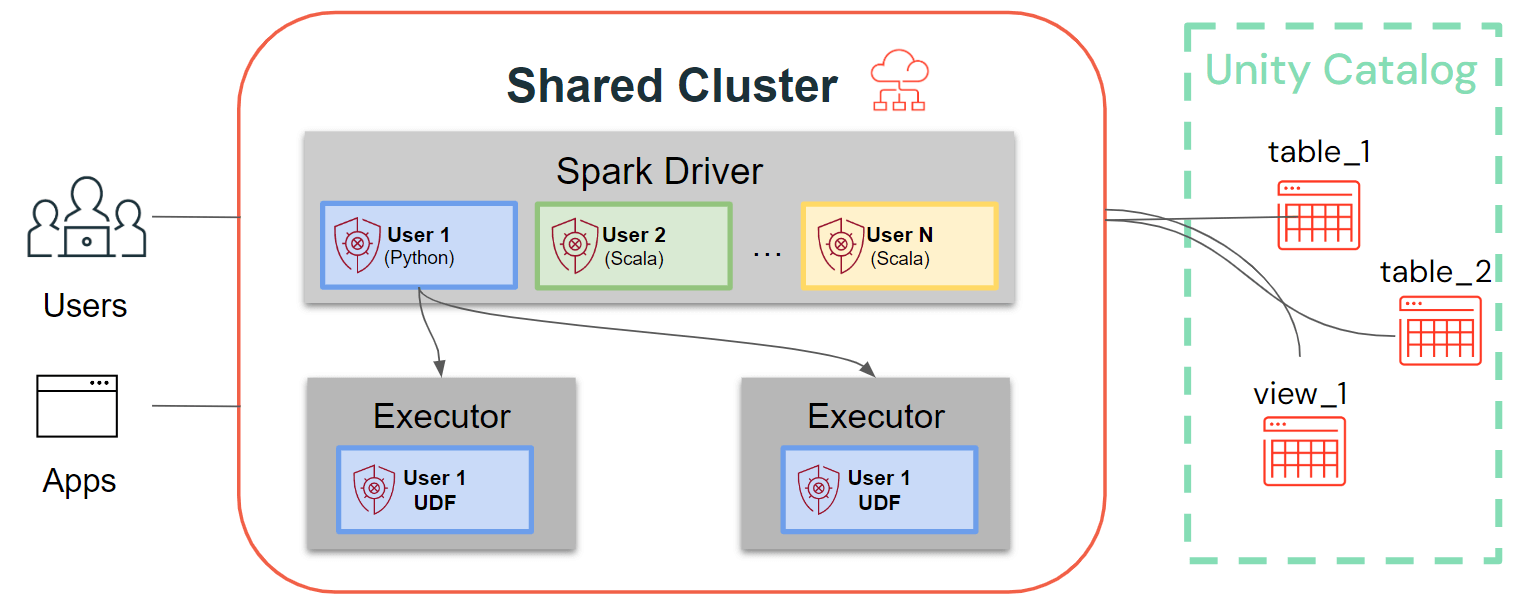
Neueste Verbesserungen für gemeinsam genutzte Cluster: Cluster-Bibliotheken, Init-Skripte, Python-UDFs, Scala, ML und Streaming-Unterstützung
Konfigurieren Sie Ihren gemeinsam genutzten Cluster mit Cluster-Bibliotheken & Init-Skripten
Cluster-Bibliotheken ermöglichen es Ihnen, Bibliotheken für einen Cluster oder sogar für mehrere Cluster nahtlos zu teilen und zu verwalten, um konsistente Versionen sicherzustellen und den Bedarf an wiederholten Installationen zu reduzieren. Egal, ob Sie Machine-Learning-Frameworks, Datenbankkonnektoren oder andere wesentliche Komponenten in Ihre Cluster integrieren müssen, Cluster-Bibliotheken bieten eine zentralisierte und mühelose Lösung, die jetzt auf gemeinsam genutzten Clustern verfügbar ist.
Bibliotheken können von Unity Catalog-Volumes (AWS, Azure, GCP), Workspace-Dateien (AWS, Azure, GCP), PyPI/Maven und Cloud-Speicherorten installiert werden, indem die vorhandene Cluster-UI oder API verwendet wird.
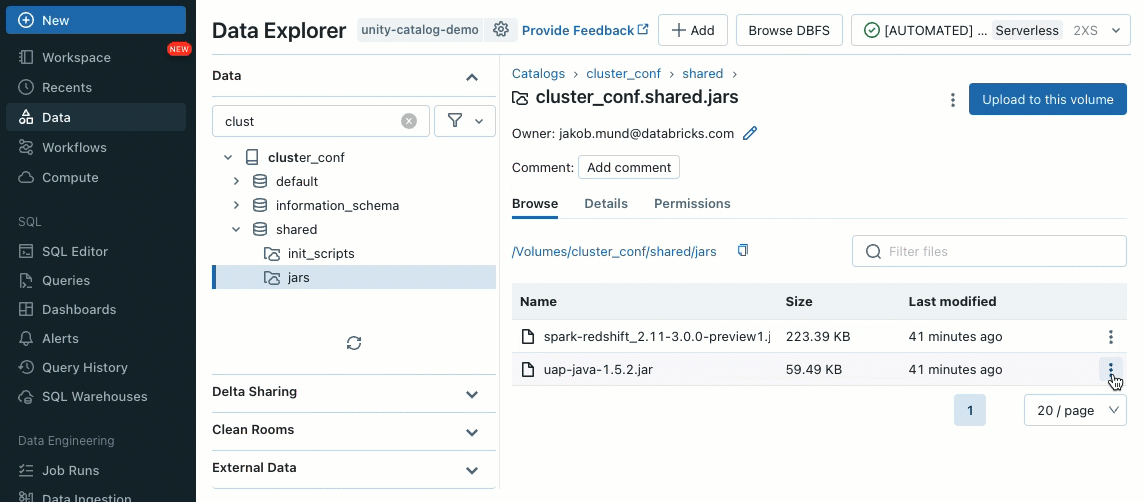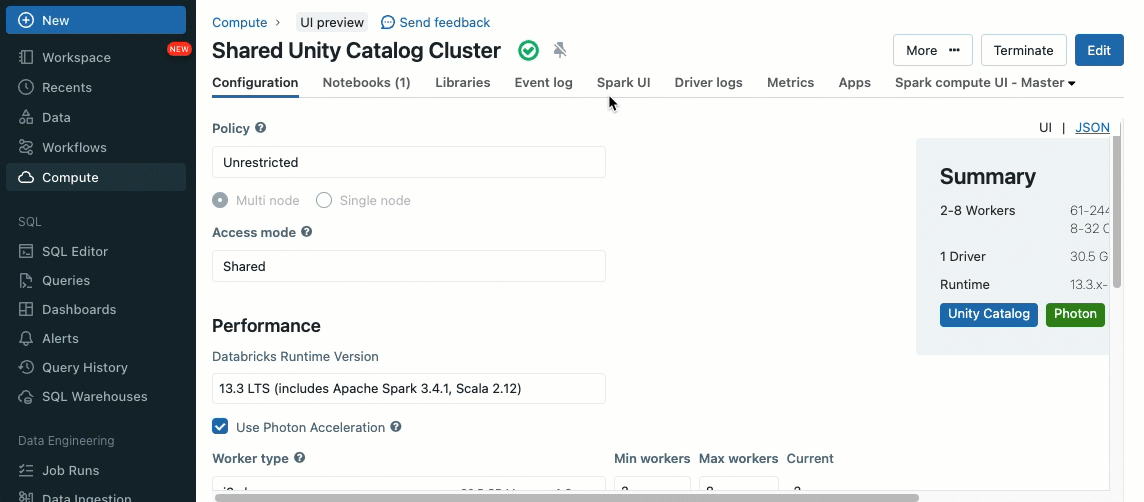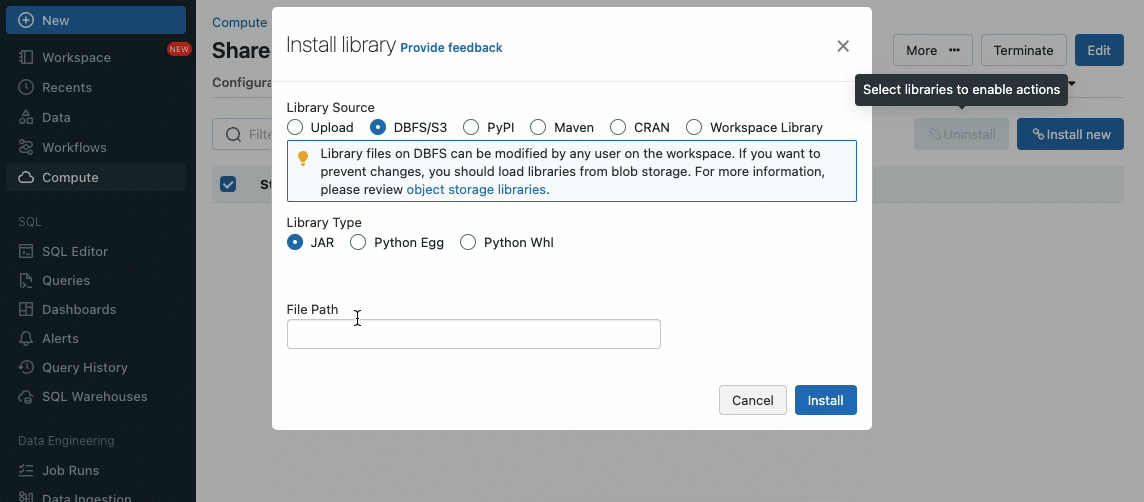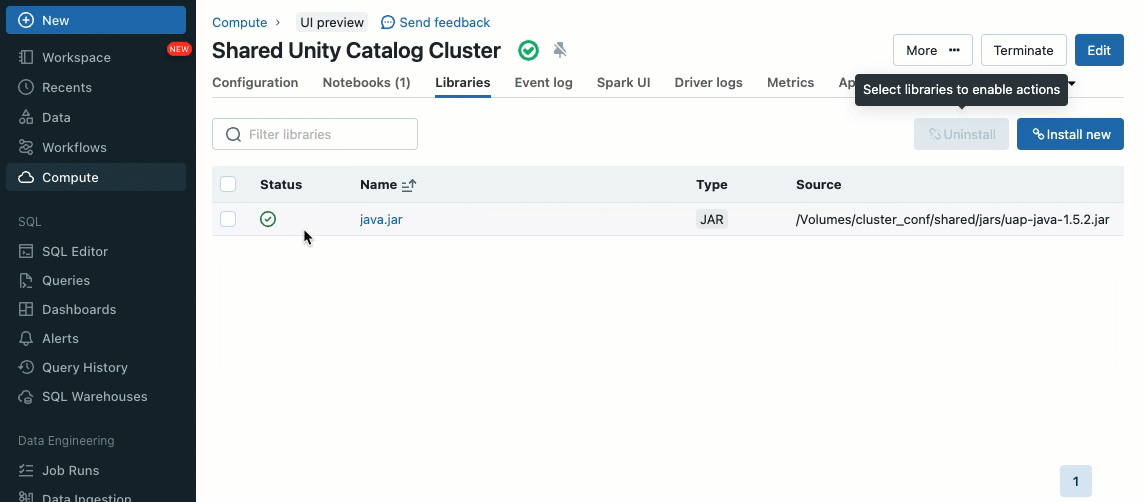
Mithilfe von Init-Skripten können Sie als Cluster-Administrator benutzerdefinierte Skripte während des Cluster-Erstellungsprozesses ausführen, um Aufgaben wie die Einrichtung von Authentifizierungsmechanismen, die Konfiguration von Netzwerkeinstellungen oder die Initialisierung von Datenquellen zu automatisieren.
Init-Skripte können auf gemeinsam genutzten Clustern installiert werden, entweder direkt während der Cluster-Erstellung oder für eine Flotte von Clustern mithilfe von Cluster-Richtlinien (AWS, Azure, GCP). Für maximale Flexibilität können Sie wählen, ob Sie ein Init-Skript aus Unity Catalog-Volumes (AWS, Azure, GCP) oder Cloud-Speicher verwenden möchten.
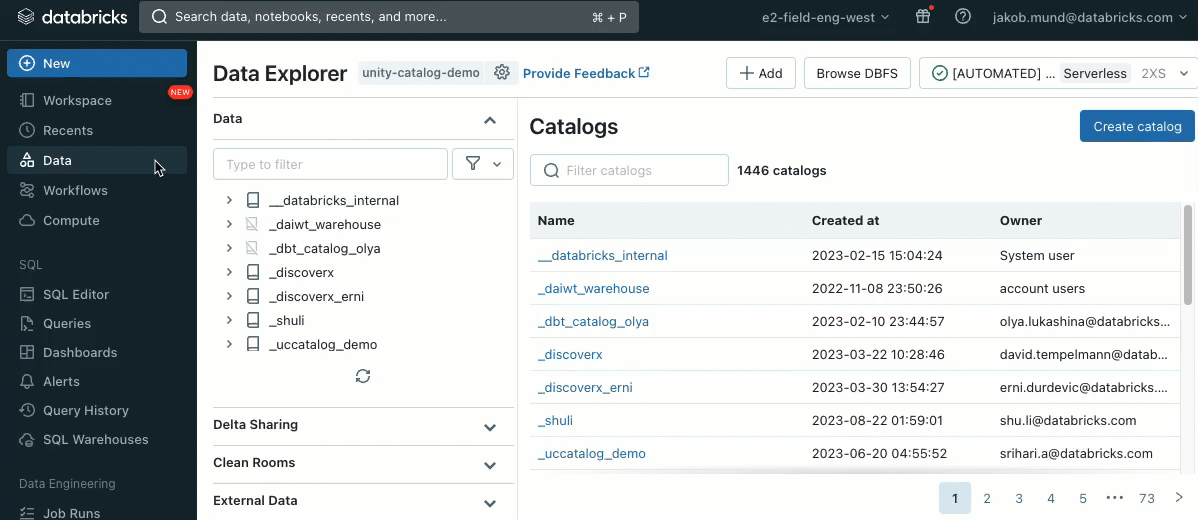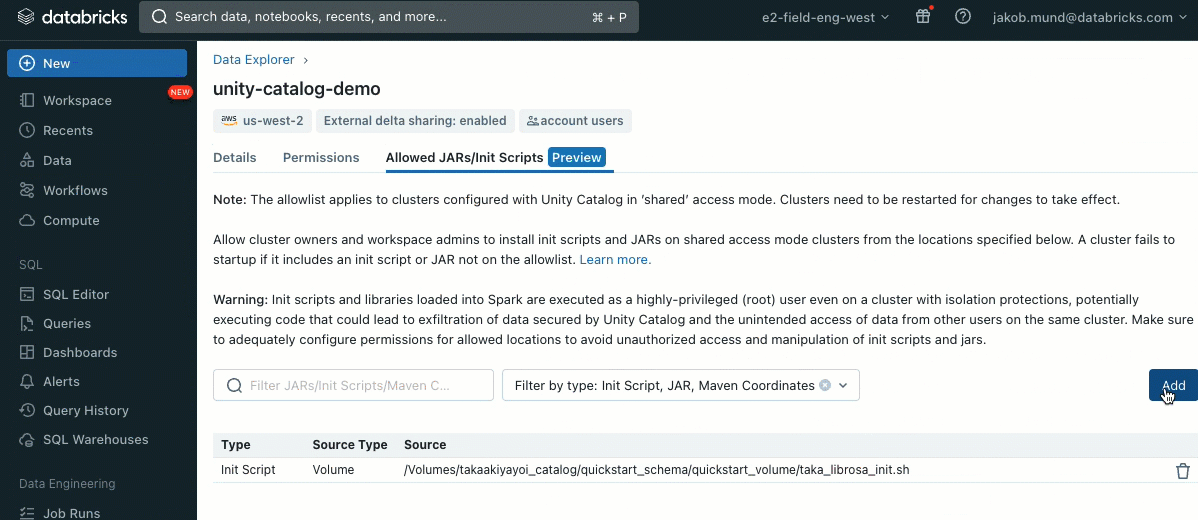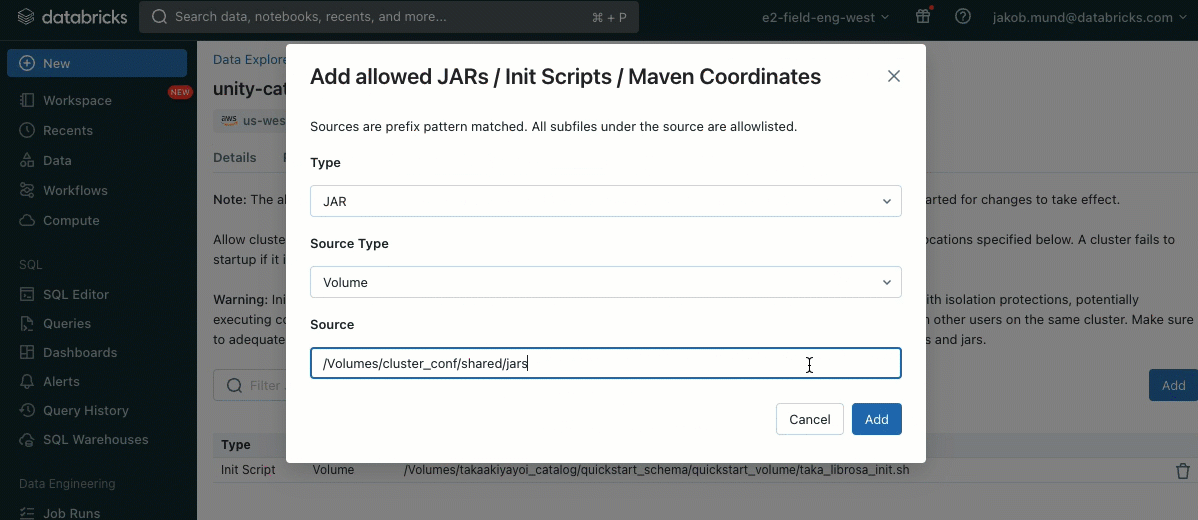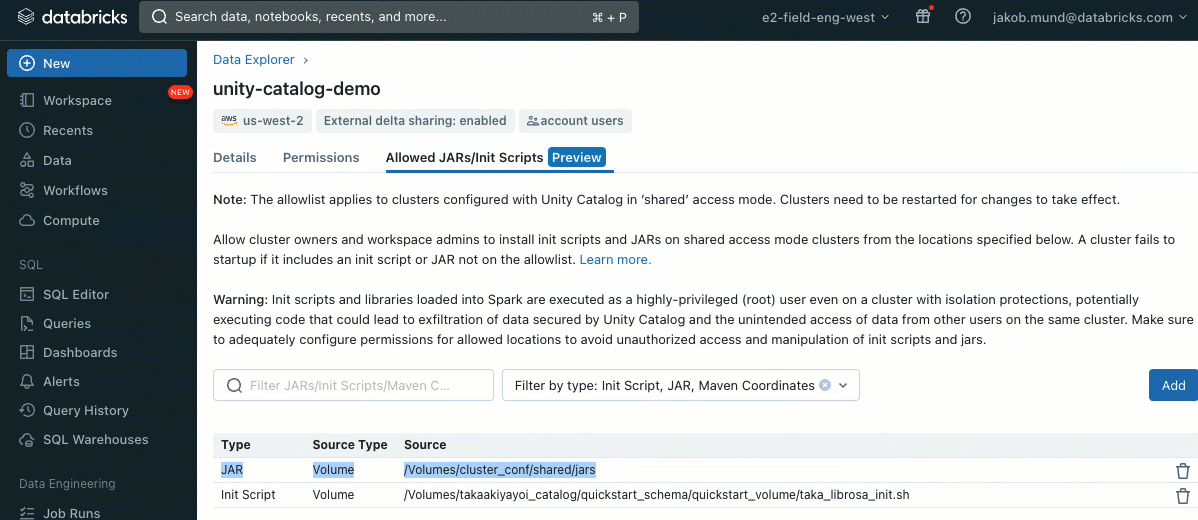
Als zusätzliche Sicherheitsebene führen wir eine Zulassungsliste (Allowlist) (AWS, Azure, GCP) ein, die die Installation von Cluster-Bibliotheken (JARs) und Init-Skripten regelt. Dies gibt Administratoren die Kontrolle über deren Verwaltung auf gemeinsam genutzten Clustern. Für jeden Metastore kann der Metastore-Administrator die Volumes und Cloud-Speicherorte konfigurieren, von denen Bibliotheken (JARs) und Init-Skripte installiert werden können. Dies bietet ein zentrales Repository vertrauenswürdiger Ressourcen und verhindert unbefugte Installationen. Dies ermöglicht eine granularere Kontrolle über die Cluster-Konfigurationen und hilft, die Konsistenz über die Daten-Workflows Ihrer Organisation hinweg aufrechtzuerhalten.
Bringen Sie Ihre Scala-Workloads mit
Scala wird jetzt auf gemeinsam genutzten Clustern unterstützt, die von Unity Catalog verwaltet werden. Dateningenieure können die Flexibilität und Leistung von Scala nutzen, um alle Arten von Big-Data-Herausforderungen gemeinsam auf demselben Cluster zu bewältigen und vom Unity Catalog-Governance-Modell zu profitieren.
Die Integration von Scala in Ihren bestehenden Databricks-Workflow ist ein Kinderspiel. Wählen Sie einfach Databricks Runtime 13.3 LTS oder höher bei der Erstellung eines gemeinsam genutzten Clusters aus, und Sie können Scala-Code neben anderen unterstützten Sprachen schreiben und ausführen.
Nutzen Sie User-Defined Functions (UDFs), Machine Learning & Structured Streaming
Das ist noch nicht alles! Wir freuen uns, weitere bahnbrechende Fortschritte für gemeinsam genutzte Cluster vorstellen zu können.
Unterstützung für Python- und Pandas-User-Defined Functions (UDFs): Sie können jetzt die Leistung von Python- und (skalaren) Pandas-UDFs auch auf gemeinsam genutzten Clustern nutzen. Bringen Sie Ihre Workloads einfach nahtlos auf gemeinsam genutzte Cluster – keine Codeanpassungen erforderlich. Durch die Isolierung der Ausführung von UDF-Benutzercode auf Spark-Executors in einer Sandbox-Umgebung bieten gemeinsam genutzte Cluster eine zusätzliche Schutzschicht für Ihre Daten und verhindern unbefugten Zugriff und potenzielle Sicherheitsverletzungen.
Unterstützung für alle gängigen ML-Bibliotheken über den Spark-Treiberknoten und MLflow: Egal, ob Sie mit Scikit-learn, XGBoost, Prophet und anderen beliebten ML-Bibliotheken arbeiten, Sie können jetzt Machine-Learning-Modelle direkt auf gemeinsam genutzten Clustern nahtlos erstellen, trainieren und bereitstellen. Um ML-Bibliotheken für alle Benutzer zu installieren, können Sie die neuen Cluster-Bibliotheken verwenden. Mit der integrierten Unterstützung für MLflow (2.2.0 oder höher) war die Verwaltung des End-to-End-Machine-Learning-Lebenszyklus noch nie einfacher.
Structured Streaming ist jetzt auch auf gemeinsam genutzten Clustern verfügbar, die von Unity Catalog verwaltet werden. Diese transformative Ergänzung ermöglicht die Echtzeit-Datenverarbeitung und -analyse und revolutioniert die Art und Weise, wie Ihre Datenteams Streaming-Workloads kollaborativ verwalten.
Starten Sie noch heute, weitere gute Dinge kommen
Entdecken Sie die Leistung von Scala, Cluster-Bibliotheken, Python-UDFs, Single-Node-ML und Streaming auf gemeinsam genutzten Clustern noch heute, indem Sie einfach Databricks Runtime 13.3 LTS oder höher verwenden. Weitere Informationen und der Beginn Ihrer Reise zur Datengüte finden Sie in den Schnellstartanleitungen (AWS, Azure, GCP).
In den kommenden Wochen und Monaten werden wir die Compute-Architektur des Unity Catalog weiter vereinheitlichen und die Arbeit mit Unity Catalog noch einfacher gestalten!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.