Vereinfachen Sie die Datenaufnahme mit der neuen Python Data Source API
von Craig Lukasik und Allison Wang
Dieser Blogbeitrag untersucht, wie die neue Python Data Source API von Spark die Aufnahme von IoT-Daten vereinfacht.
Data-Engineering-Teams stehen häufig vor der Aufgabe, maßgeschneiderte Ingestionslösungen für unzählige benutzerdefinierte, proprietäre oder branchenspezifische Datenquellen zu entwickeln. Viele Teams stellen fest, dass die Entwicklung von Ingestionslösungen mühsam und zeitaufwendig ist. Angesichts dieser Herausforderungen haben wir zahlreiche Unternehmen aus verschiedenen Branchen interviewt, um ihre vielfältigen Datenintegrationsanforderungen besser zu verstehen. Dieses umfassende Feedback führte zur Entwicklung der Python Data Source API für Apache Spark™.
Einer der Kunden, mit denen wir eng zusammengearbeitet haben, ist Shell. Geräteausfälle im Energiesektor können erhebliche Folgen haben und Sicherheit, Umwelt und betriebliche Stabilität beeinträchtigen. Bei Shell hat die Minimierung dieser Risiken Priorität, und eine Möglichkeit, dies zu erreichen, ist die Konzentration auf den zuverlässigen Betrieb von Geräten.
Shell besitzt eine riesige Flotte von Anlagevermögen und Geräten im Wert von über 180 Milliarden US-Dollar. Um die riesigen Datenmengen zu verwalten, die bei Shells Betrieb anfallen, setzt das Unternehmen auf fortschrittliche Tools, die die Produktivität steigern und seinen Datenteams ermöglichen, nahtlos an verschiedenen Initiativen zu arbeiten. Die Databricks Data Intelligence Platform spielt eine entscheidende Rolle, indem sie den Datenzugang demokratisiert und die Zusammenarbeit zwischen Shells Analysten, Ingenieuren und Wissenschaftlern fördert. Die Integration von IoT-Daten stellte jedoch für einige Anwendungsfälle eine Herausforderung dar.
Anhand unseres Beispiels mit Shell wird dieser Blogbeitrag untersuchen, wie diese neue API frühere Herausforderungen bewältigt und Codebeispiele zur Veranschaulichung ihrer Anwendung bereitstellen.
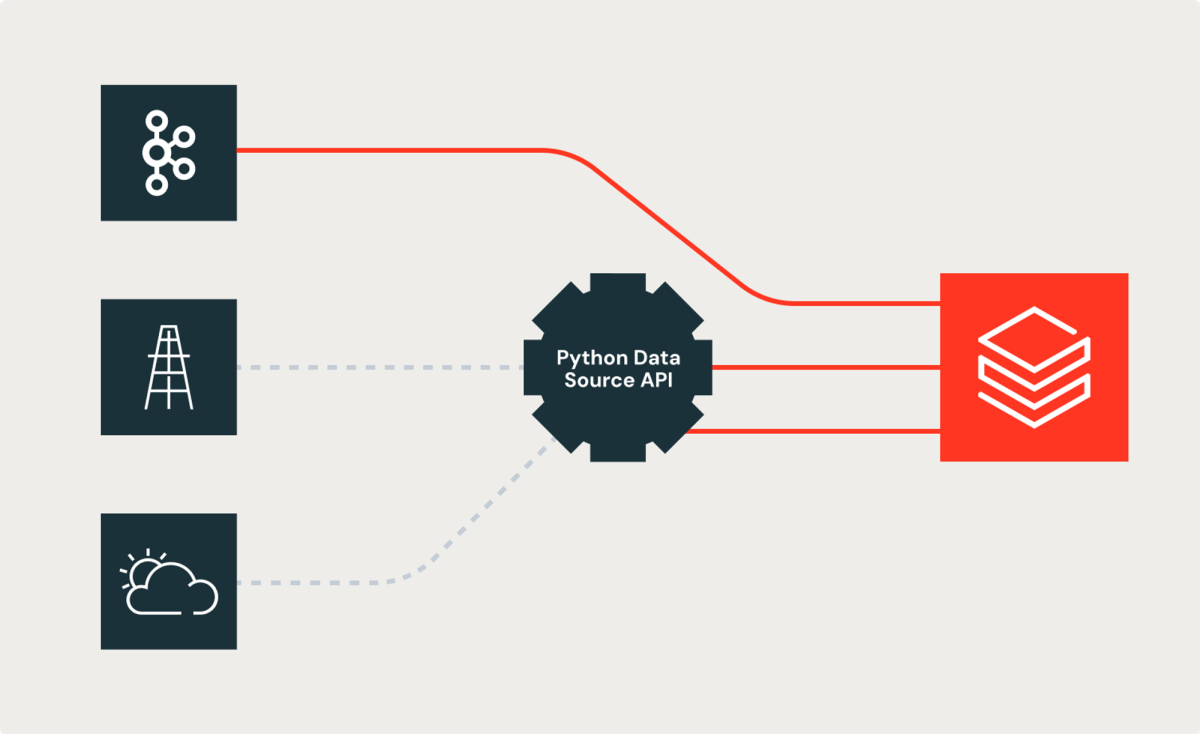
Die Herausforderung
Betrachten wir zunächst die Herausforderung, mit der Shells Data Engineers konfrontiert waren. Obwohl viele Datenquellen in ihren Datenpipelines integrierte Spark-Quellen (z. B. Kafka) verwenden, sind einige auf REST-APIs, SDKs oder andere Mechanismen angewiesen, um Daten für Konsumenten bereitzustellen. Shells Data Engineers hatten damit zu kämpfen. Sie entwickelten maßgeschneiderte Lösungen, um Daten aus integrierten Spark-Quellen mit Daten aus diesen Quellen zu verknüpfen. Diese Herausforderung kostete die Data Engineers viel Zeit und Energie. Wie oft in großen Organisationen üblich, führen solche maßgeschneiderten Implementierungen zu Inkonsistenzen bei der Umsetzung und den Ergebnissen. Bryce Bartmann, Shells Chief Digital Technology Advisor, wünschte sich Einfachheit und sagte uns: „Wir schreiben viele coole REST-APIs, auch für Streaming-Anwendungsfälle, und würden sie gerne einfach als Datenquelle in Databricks nutzen, anstatt den gesamten Plumbing-Code selbst zu schreiben.“
„Wir schreiben viele coole REST-APIs, auch für Streaming-Anwendungsfälle, und würden sie gerne einfach als Datenquelle in Databricks nutzen, anstatt den gesamten Plumbing-Code selbst zu schreiben.“ - Bryce Bartmann, Chief Digital Technology Advisor, Shell
Die Lösung
Die neue Python Custom Data Source API lindert die Probleme, indem sie die Lösung mit objektorientierten Konzepten angeht. Die neue API bietet abstrakte Klassen, die benutzerdefinierten Code, wie z. B. REST-API-basierte Lookups, kapseln und als weitere Spark-Quelle oder -Senke bereitstellen können.
Data Engineers wünschen sich Einfachheit und Komponierbarkeit. Stellen Sie sich zum Beispiel vor, Sie sind ein Data Engineer und möchten Wetterdaten in Ihre Streaming-Pipeline aufnehmen. Idealerweise möchten Sie Code schreiben, der so aussieht:
Dieser Code sieht einfach aus und ist für Data Engineers leicht zu verwenden, da sie bereits mit der DataFrame API vertraut sind. Zuvor war ein gängiger Ansatz für den Zugriff auf eine REST-API in einem Spark-Job die Verwendung einer PandasUDF. Dieser Artikel zeigt, wie kompliziert es sein kann, wiederverwendbaren Code zum Senden von Daten an eine REST-API mit einer Pandas UDF zu schreiben. Die neue API vereinfacht und standardisiert hingegen, wie Spark-Jobs – Streaming oder Batch, Senke oder Quelle – mit nicht-nativen Quellen und Senken arbeiten.
Als Nächstes untersuchen wir ein reales Beispiel und zeigen, wie die neue API uns ermöglicht, eine neue Datenquelle („weather“ in diesem Beispiel) zu erstellen. Die neue API bietet Funktionen für Quellen, Senken, Batch und Streaming, und das folgende Beispiel konzentriert sich auf die Verwendung der neuen Streaming-API zur Implementierung einer neuen „weather“-Quelle.
Verwendung der Python Data Source API – ein reales Szenario
Stellen Sie sich vor, Sie sind ein Data Engineer, der mit der Erstellung einer Datenpipeline für einen Predictive-Maintenance-Anwendungsfall beauftragt ist, der Druckdaten von Bohrlochkopfanlagen benötigt. Nehmen wir an, die Temperatur- und Druckmetriken des Bohrlochkopfs fließen über Kafka von den IoT-Sensoren. Wir wissen, dass Structured Streaming native Unterstützung für die Verarbeitung von Daten aus Kafka bietet. Soweit so gut. Die Geschäftsanforderungen stellen jedoch eine Herausforderung dar: Dieselbe Datenpipeline muss auch Wetterdaten erfassen, die sich auf den Bohrlochkopfstandort beziehen, und diese Daten werden nicht über Kafka gestreamt, sondern sind stattdessen über eine REST-API zugänglich. Die Stakeholder und Data Scientists wissen, dass das Wetter die Lebensdauer und Effizienz von Geräten beeinflusst und diese Faktoren die Wartungspläne für Geräte beeinflussen.
Einfach anfangen
Die neue API bietet eine einfache Option, die für viele Anwendungsfälle geeignet ist: die SimpleDataSourceStreamReader API. Die SimpleDataSourceStreamReader API ist geeignet, wenn die Datenquelle einen geringen Durchsatz hat und keine Partitionierung erfordert. Wir werden sie in diesem Beispiel verwenden, da wir nur Wetterdatenmesswerte für eine begrenzte Anzahl von Bohrlochkopfstandorten benötigen und die Häufigkeit der Wetterdatenmesswerte gering ist.
Werfen wir einen Blick auf ein einfaches Beispiel, das die SimpleDataSourceStreamReader API verwendet.
Wir werden später einen komplizierteren Ansatz erklären. Der andere, komplexere Ansatz ist ideal für die Erstellung einer partitionierungsfähigen Python Data Source. Vorerst kümmern wir uns nicht darum, was das bedeutet. Stattdessen zeigen wir ein Beispiel, das die einfache API verwendet.
Codebeispiel
Das folgende Codebeispiel geht davon aus, dass die „einfache“ API ausreichend ist. Die __init__ Methode ist unerlässlich, da sie der Reader-Klasse (WeatherSimpleStreamReader unten) ermöglicht, die zu überwachenden Bohrlochkopfstandorte zu verstehen. Die Klasse verwendet eine „locations“-Option, um die Standorte zu identifizieren, für die Wetterinformationen ausgegeben werden sollen.
Nachdem wir die einfache Reader-Klasse definiert haben, müssen wir sie in eine Implementierung der abstrakten Klasse DataSource integrieren.
Nachdem wir die DataSource definiert und eine Implementierung des Streaming-Readers integriert haben, müssen wir die DataSource bei der Spark-Sitzung registrieren.
Das bedeutet, dass die Wetterdatenquelle eine neue Streaming-Quelle mit den bekannten DataFrame-Operationen ist, mit denen Daten-Ingenieure vertraut sind. Dieser Punkt ist hervorhebenswert, da diese benutzerdefinierten Datenquellen dem gesamten Team zugutekommen. Mit einem objektorientierteren Ansatz sollte das breitere Team von dieser Datenquelle profitieren, falls es Wetterdaten als Teil seines Anwendungsfalls benötigt. Daher möchten Daten-Ingenieure möglicherweise die benutzerdefinierten Datenquellen in eine Python-Wheel-Bibliothek extrahieren, um sie in anderen Pipelines wiederzuverwenden.
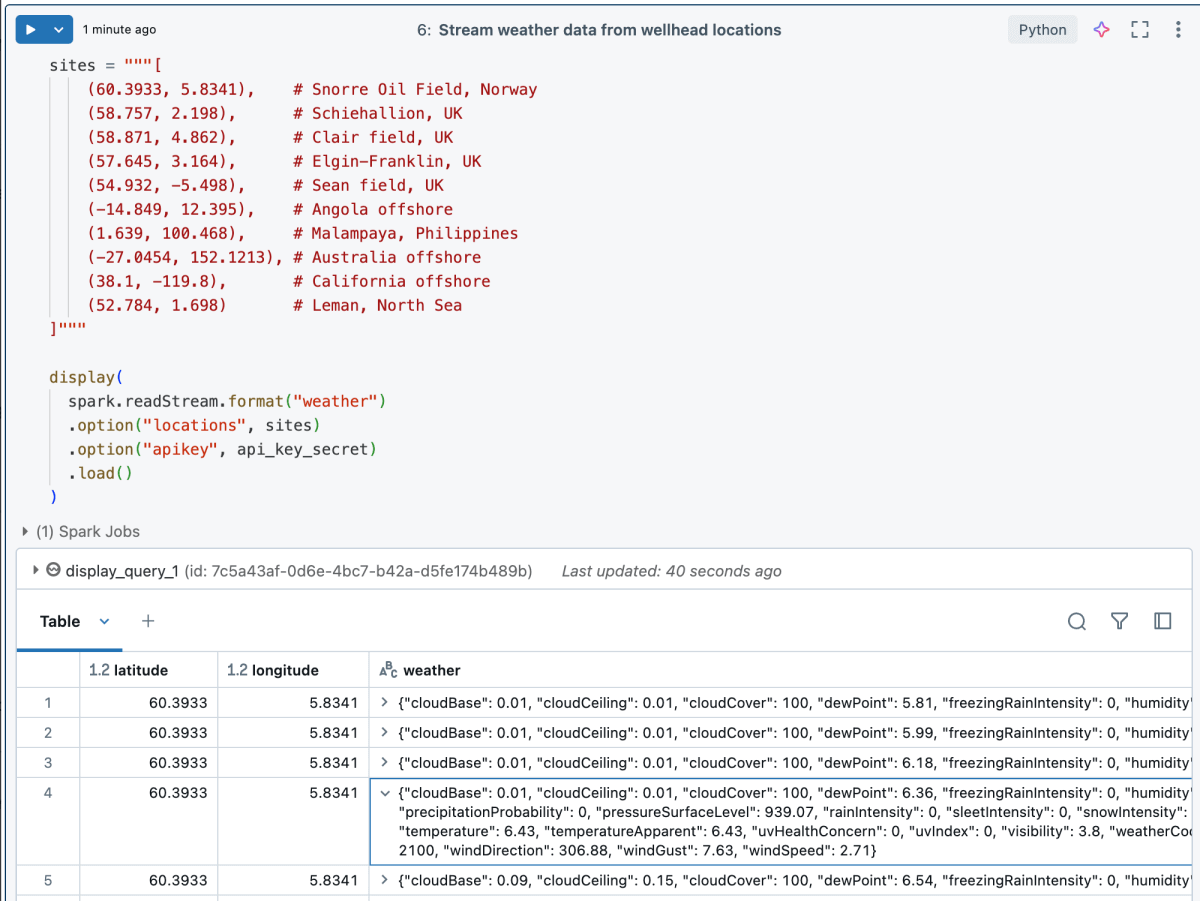
Unten sehen wir, wie einfach es für den Daten-Ingenieur ist, den benutzerdefinierten Stream zu nutzen.
Beispielergebnisse:
Weitere Überlegungen
Wann die partitionierungsfähige API verwendet werden soll
Nachdem wir die "einfache" API der Python Data Source durchlaufen haben, erklären wir eine Option für die Partitionsfähigkeit. Partitionsfähige Datenquellen ermöglichen die Parallelisierung der Datengenerierung. In unserem Beispiel würde eine partitionierungsfähige Datenquellenimplementierung dazu führen, dass Worker-Aufgaben die Standorte auf mehrere Aufgaben aufteilen, sodass die REST-API-Aufrufe über Worker und den Cluster verteilt werden können. Auch hier enthält unser Beispiel diese Raffinesse nicht, da das erwartete Datenvolumen gering ist.
Batch- vs. Stream-APIs
Abhängig vom Anwendungsfall und davon, ob Sie möchten, dass die API den Quellstream generiert oder die Daten senkt, müssen Sie sich auf die Implementierung verschiedener Methoden konzentrieren. In unserem Beispiel kümmern wir uns nicht um das Senken von Daten. Wir hätten auch die Batch-Reader-Implementierung einbeziehen sollen. Sie können sich jedoch darauf konzentrieren, die notwendigen Klassen für Ihren spezifischen Anwendungsfall zu implementieren.
| Quelle | Senke | |
|---|---|---|
| Batch | reader() | writer() |
| Streaming | streamReader() oder simpleStreamReader() | streamWriter() |
Wann die Writer-APIs verwendet werden sollen
Dieser Artikel konzentriert sich auf die Reader-APIs, die in readStream verwendet werden. Die Writer-APIs ermöglichen ähnliche beliebige Logik auf der Ausgabeseite der Datenpipeline. Nehmen wir zum Beispiel an, die Betriebsleiter an der Bohrlochkopfstation möchten, dass die Datenpipeline eine API an der Bohrlochkopfstation aufruft, die einen roten/gelben/grünen Ausrüstungsstatus anzeigt, der die Logik der Pipeline nutzt. Die Writer-API würde es Daten-Ingenieuren ermöglichen, die Logik auf die gleiche Weise zu kapseln und eine Datensenke bereitzustellen, die wie vertraute writeStream-Formate funktioniert.
Fazit
"Einfachheit ist die ultimative Raffinesse." - Leonardo da Vinci
Als Architekten und Daten-Ingenieure haben wir nun die Möglichkeit, Batch- und Streaming-Workloads mithilfe der PySpark Custom Data Source API zu vereinfachen. Wenn Sie Möglichkeiten für neue Datenquellen finden, von denen Ihre Datenteams profitieren würden, sollten Sie die Datenquellen zur Wiederverwendung im gesamten Unternehmen trennen, z. B. durch die Verwendung eines Python-Wheels.
Die Python Data Source API ist genau das, was wir brauchten. Sie bietet unseren Daten-Ingenieuren die Möglichkeit, Code zu modularisieren, der für die Interaktion mit unseren REST-APIs und SDKs erforderlich ist. Die Tatsache, dass wir jetzt wiederverwendbare Spark-Datenquellen im gesamten Unternehmen erstellen, testen und bereitstellen können, wird unseren Teams helfen, schneller voranzukommen und mehr Vertrauen in ihre Arbeit zu haben." - Bryce Bartmann, Chief Digital Technology Advisor, Shell
Zusammenfassend lässt sich sagen, dass die Python Data Source API für Apache Spark™ eine leistungsstarke Ergänzung ist, die erhebliche Herausforderungen bewältigt, mit denen Daten-Ingenieure bisher bei der Arbeit mit komplexen Datenquellen und -senken, insbesondere in Streaming-Kontexten, konfrontiert waren. Ob mit der "einfachen" oder der partitionierungsbewussten API, Ingenieure verfügen nun über die Werkzeuge, um eine breitere Palette von Datenquellen und -senken effizient in ihre Spark-Pipelines zu integrieren. Wie unsere Ausführungen und der Beispielcode gezeigt haben, ist die Implementierung und Nutzung dieser API unkompliziert und ermöglicht schnelle Erfolge für Predictive Maintenance und andere Anwendungsfälle. Die Databricks-Dokumentation (und die Open-Source-Dokumentation) erklären die API im Detail, und mehrere Python-Datenquellenbeispiele finden Sie hier.
Schließlich kann die Betonung der Erstellung benutzerdefinierter Datenquellen als modulare, wiederverwendbare Komponenten nicht hoch genug eingeschätzt werden. Durch die Abstraktion dieser Datenquellen in eigenständige Bibliotheken können Teams eine Kultur der Code-Wiederverwendung und Zusammenarbeit fördern, was die Produktivität und Innovation weiter steigert. Während wir weiterhin die Grenzen dessen erforschen und erweitern, was mit Big Data und IoT möglich ist, werden Technologien wie die Python Data Source API eine entscheidende Rolle bei der Gestaltung der Zukunft datengesteuerter Entscheidungsfindung im Energiesektor und darüber hinaus spielen.
Wenn Sie bereits Databricks-Kunde sind, schnappen Sie sich eines dieser Beispiele und passen Sie es an, um Ihre Daten hinter einer REST-API zu erschließen. Wenn Sie noch kein Databricks-Kunde sind, starten Sie kostenlos und probieren Sie noch heute eines der Beispiele aus.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.