SOTA-Einbettungsmodell für Agenten-Workflows jetzt in öffentlicher Vorschau
Qwen3-Embedding-0.6B ist das erste mehrsprachige Einbettungsmodell auf Foundation Model Serving mit branchenführender Leistung bei allen Einbettungsaufgaben
von Felix Zhu, Cade Daniel und Wai Wu
- Qwen3-Embedding-0.6B ist jetzt in Model Serving verfügbar und liefert State-of-the-Art-Retrieval-Leistung in einem kompakten 0,6B-Modell, optimiert für Vektorsuche und KI-Agenten-Workloads.
- Das erste mehrsprachige Einbettungsmodell auf Databricks, das sprachübergreifendes Retrieval in über 100 Sprachen für globale Unternehmensdaten unterstützt.
- Matryoshka-Einbettungen ermöglichen flexible Kosten-Leistungs-Kompromisse, sodass Einbettungen von 1024 auf bis zu 32 Dimensionen gekürzt werden können, für schnellere Suche und geringere Speicherkosten.
Retrieval ist die Grundlage moderner KI-Systeme, und die Qualität des Einbettungsmodells bestimmt, wie effektiv Anwendungen Unternehmensdaten finden und daraus schlussfolgern können. Heute bringen wir Qwen3-Embedding-0.6B auf Databricks auf den Markt, ein hochmodernes Einbettungsmodell, das eine starke Retrieval-Leistung, mehrsprachige Abdeckung und sichere serverlose Bereitstellung bietet.
Zusammen mit Agent Bricks und AI Search ermöglicht dieses Modell Teams, KI-Agenten direkt auf Basis von Unternehmensdaten in Databricks zu erstellen, relevante Kontexte abzurufen und über verwaltete Daten zu schlussfolgern, ohne Daten außerhalb der Plattform zu verschieben.
Erstellen Sie Retrieval-gestützte Agenten mit Agent Bricks
Hochmoderne Einbettungsmodelle sind eine kritische Grundlage für moderne KI-Systeme und ermöglichen es Anwendungen, den richtigen Kontext aus großen Sammlungen von Unternehmensdaten abzurufen. Qwen3-Embedding-0.6B, jetzt auf Databricks verfügbar, bietet eine starke Retrieval-Leistung für diese Workloads.
Qwen3-Embedding-0.6B basiert auf dem leistungsstarken Qwen3-Fundament und stammt vom selben Forschungsteam, das auch hinter der weit verbreiteten GTE-Serie steht. Mit einer maximalen Kontextlänge von 32.000 Tokens bietet dieses Modell eine unglaubliche Flexibilität, um Dokumente in verschiedene Größen zu zerlegen. Darüber hinaus ermöglicht sein instruktionsbewusstes Design Entwicklern, das Modell mit einem einfachen Prompt an spezifische Aufgaben und Sprachen anzupassen, was die Retrieval-Leistung typischerweise um 1-5 % steigert.
Auf Databricks kann dies mit Agent Bricks und AI Search kombiniert werden, um Retrieval-gestützte KI-Agenten direkt auf Basis von Unternehmensdaten zu erstellen. Teams können Dokumente mit AI Search indizieren und während der Agentenausführung relevante Kontexte abrufen, wodurch Agenten auf verwalteten Daten, die in Databricks gespeichert sind, basieren.
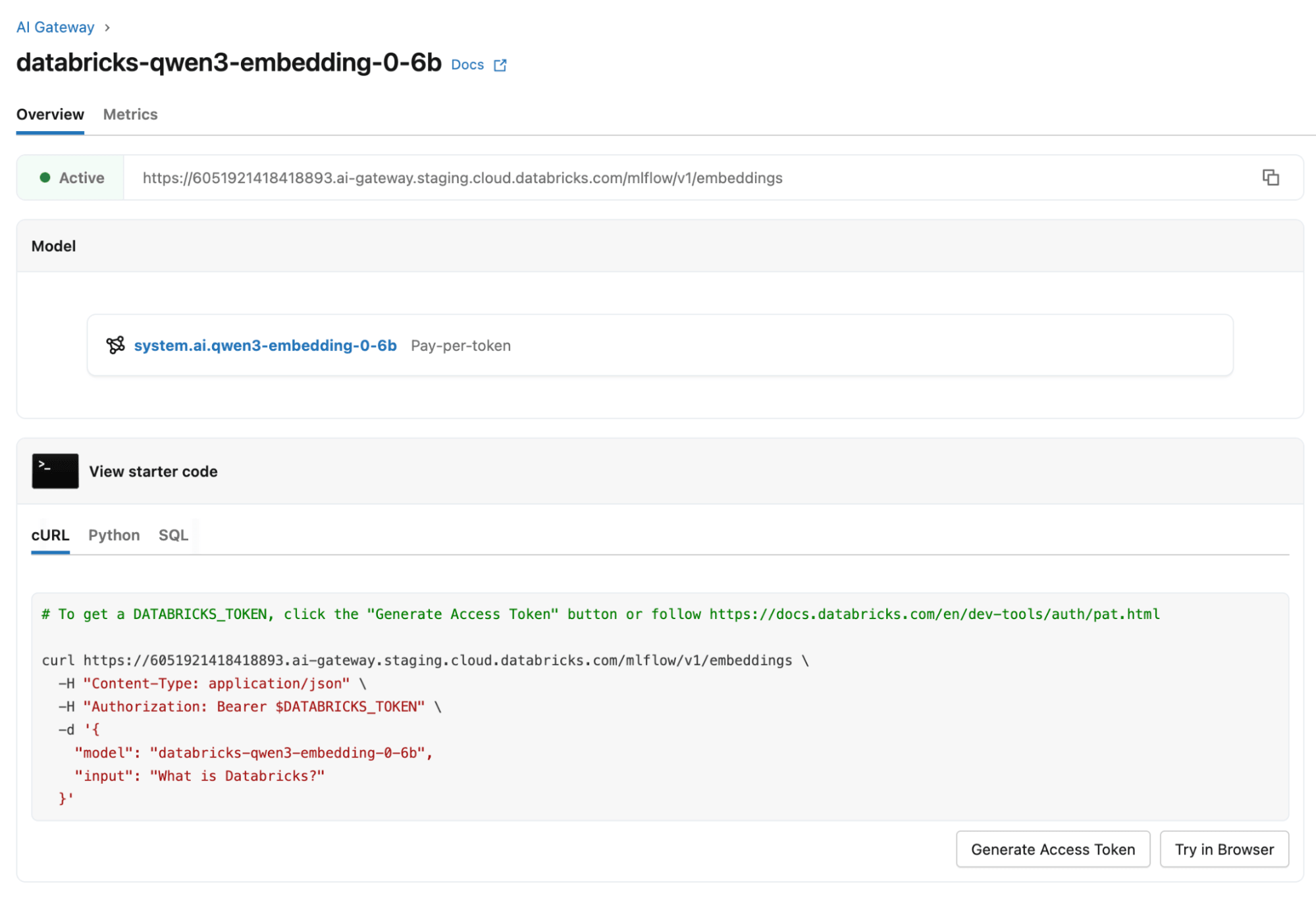
So verbessert dieses Einbettungsmodell KI-Agenten auf Databricks
Qwen3-Embedding-0.6B liefert State-of-the-Art-Qualität für seine Größe. Auf den MTEB-Ranglisten für mehrsprachige und englische Daten (v2) übertrifft es die meisten anderen Modelle der 0,6B-Klasse und übertrifft Flaggschiff-Einbettungsmodelle von OpenAI und Cohere, während es mit viel größeren 7B+-Modellen mithalten kann. Das bedeutet, dass Sie erstklassige Retrieval-Leistung ohne die Latenz und Kosten sehr großer Modelle erzielen können.
Das Modell bietet auch eine Feinsteuerung über Kosten und Recall durch Matryoshka Representation Learning (MRL), das die wichtigsten Informationen in den frühen Vektordimensionen konzentriert. Dies ermöglicht es, Einbettungen sicher für günstigere Speicherung und schnellere Suche zu kürzen, während der Großteil des Signals erhalten bleibt. Mit Qwen3-Embedding-0.6B können Sie zur Laufzeit jede Einbettungsgröße von 32 bis 1024 Dimensionen wählen – kleinere Vektoren für groß angelegte Recall-Indizes und Vektoren in voller Größe für präziseres Reranking.
Um diese Funktion mit databricks-qwen3-embedding-0-6b zu nutzen, setzen Sie das optionale Feld dimensions in Ihrer Embeddings REST API-Anfrage auf die gewünschte Ausgabegröße (eine Zweierpotenz zwischen 32 und 1024). Weitere Details finden Sie in der Dokumentation der Foundation Model REST API.
Mehrsprachig von Grund auf
Qwen3-Embedding-0.6B ist das erste mehrsprachige Einbettungsmodell, das von Databricks gehostet wird und von Anfang an für globale Workloads konzipiert wurde. Während viele Einbettungsmodelle primär für Englisch mit begrenzter mehrsprachiger Unterstützung entwickelt wurden, erbt Qwen3-Embedding-0.6B die breite Sprachabdeckung vom Qwen3-Basismodell, das auf Texten in mehr als 100 Sprachen vortrainiert wurde.
Dies ermöglicht eine starke Leistung nicht nur für das englische Retrieval, sondern auch für mehrsprachige und sprachübergreifende Aufgaben. Anwendungen können in einer Sprache suchen und Ergebnisse in einer anderen abrufen oder gemischtsprachige Datensätze und Code-Retrieval über mehrere Programmiersprachen hinweg unterstützen.
Sichere serverlose Bereitstellung
Wie andere von Databricks gehostete Foundation Models läuft Qwen3-Embedding-0.6B auf sicheren, vollständig verwalteten serverlosen GPUs innerhalb der Databricks-Plattform.
Rufen Sie einfach die Foundation Model APIs auf, und Databricks kümmert sich um Bereitstellung, automatische Skalierung und Zuverlässigkeit. Da das Modell auf geo-bewusster, konformer Infrastruktur läuft, können Sie Einbettungen nahe an Ihren Daten halten, Anforderungen an den Datenspeicherort einhalten und Retrieval direkt in bestehende Databricks-Workloads integrieren.
Probieren Sie Qwen3-Embedding-0.6B noch heute aus!
Ob Sie semantische Suche, RAG-Pipelines, mehrsprachiges Retrieval oder Textklassifizierungssysteme erstellen, Qwen3-Embedding-0.6B bietet eine außergewöhnliche Kombination aus Geschwindigkeit, Effizienz und State-of-the-Art-Genauigkeit. Dieses Modell ist als databricks-qwen3-embedding-0-6b auf allen Clouds in allen Regionen verfügbar, die Foundation Model Serving unterstützen, und Sie können dieses Modell auf der Databricks Serving-Seite ausprobieren. Es ist auf allen Model Serving-Oberflächen verfügbar: Pay-Per-Token, AI Functions (Batch-Inferenz) und Provisioned Throughput. Sie können dieses Modell auch für AI Search-Anwendungsfälle auswählen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.