TabPFN KI beschleunigt die Geschäftstransformation auf Databricks
Entdecken Sie, wie TabPFN auf Databricks Vorhersagen für strukturiertes ML beschleunigt, Trainingszyklen eliminiert und KI mit umfassender Governance über zentrale Geschäftsabläufe hinweg skaliert.
von Dominik Safari, Philipp Singer, Diana Kriuchkova, Sauraj Gambhir, Ryuta Yoshimatsu , Bryan Smith und Dael Williamson
- Warum klassische ML-Workflows komplex und ressourcenintensiv bleiben – und wie TabPFN das grundlegend ändert
- Wie Databricks es Teams ermöglicht, TabPFN-Vorhersagen direkt neben Lakehouse-Daten zu erstellen, bereitzustellen und zu verwalten
- Der freigesetzte Geschäftswert: schnellere Zeit bis zur Vorhersage, reduzierter Data-Science-Aufwand und eine breitere ML-Einführung in den Kernbetriebe
Heutzutage ist es schwierig, ein Wirtschaftsmagazin, eine Telefonkonferenz zu den Quartalsergebnissen, ein Branchen-Whitepaper oder eine Strategiepräsentation zur Geschäftstransformation zu finden, in der sich nicht alles um künstliche Intelligenz (KI) dreht. Moderne KI stellt einen fundamentalen Wandel dar, wie Unternehmen den Konsum, die Interpretation und die Erstellung von Inhalten angehen, und ermöglicht es Unternehmen, eine Vielzahl von Tasks zu erweitern und zu automatisieren, die bisher tiefgreifendes Fachwissen und jahrelanges Spezialwissen erforderten.
Doch bei all der Aufmerksamkeit, die die Fähigkeit der KI auf sich zieht, unstrukturierte Inhalte – d. h. Texte, Bilder, Audio usw. – zu verstehen und zu erstellen, stützen sich sehr viele Kerngeschäftsprozesse seit Langem auf klassisches Machine Learning (ML), eine andere, wenn auch verwandte Technologie, die aus strukturierten Dateneingaben prädiktive Labels erzeugt (Abbildung 1). Bisher hat die transformative Kraft der KI das klassische ML weitgehend unberührt gelassen.
Das Fortbestehen traditioneller ML-Workflows ist auf ihre inhärente Komplexität und hohe Arbeitsintensität zurückzuführen. Data Scientists verbringen routinemäßig mehr als 80 % ihrer Zeit mit Aktivitäten, die noch vor dem eigentlichen Modelltraining stattfinden: Aufbereitung und Validierung strukturierter Dateneingaben, Feature-Engineering und Auswahl der richtigen Modellklasse. Da sich die zugrunde liegenden Datenverteilungen zudem verschieben und die Modell-Performance im Laufe der Zeit nachlässt, ist diese Arbeit keine einmalige Investition, sondern ein fortlaufender Zyklus aus Monitoring, Debugging und Neutraining.
Im großen Scale verschärft sich diese Herausforderung. Unternehmen, die Hunderte, wenn nicht Tausende von ML-Modellen einsetzen, verlassen sich auf automatisierte Experimentier-Frameworks, um Tausende von Parameterkombinationen zu evaluieren. Aber selbst die Automatisierung kann grundlegende Ressourcenbeschränkungen nicht überwinden.
Die Realität ist ernüchternd: Unternehmen müssen angesichts begrenzter Ressourcen und der Notwendigkeit, schnell Geschäftsergebnisse zu liefern, entscheiden, welche Modelle Optimierungsaufwand erhalten und welche "gut genug" laufen. Aber das Aufkommen neuer KI-Modelle, die sich auf strukturierte Dateneingaben und prädiktive Ausgaben konzentrieren, könnte endlich einen Weg nach vorne weisen.
Video 1. Interaktion mit dem TabPFN-Modell als Teil des Databricks Solution Accelerators
Wir stellen vor: TabPFN, ein KI-Modell für Machine Learning
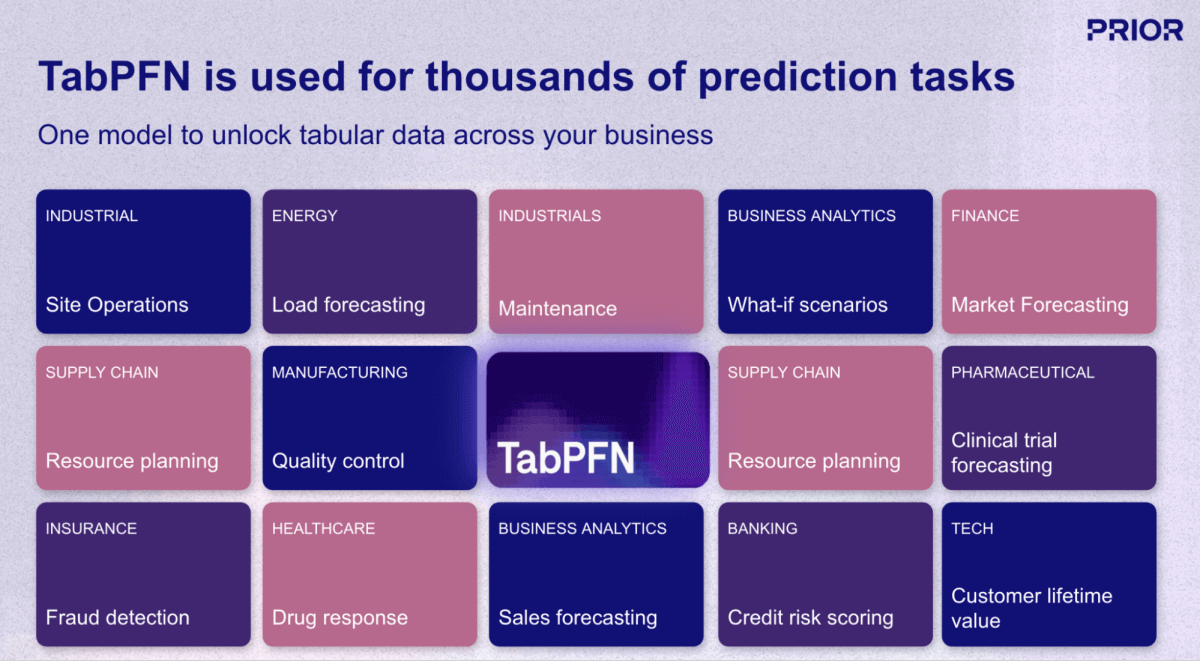
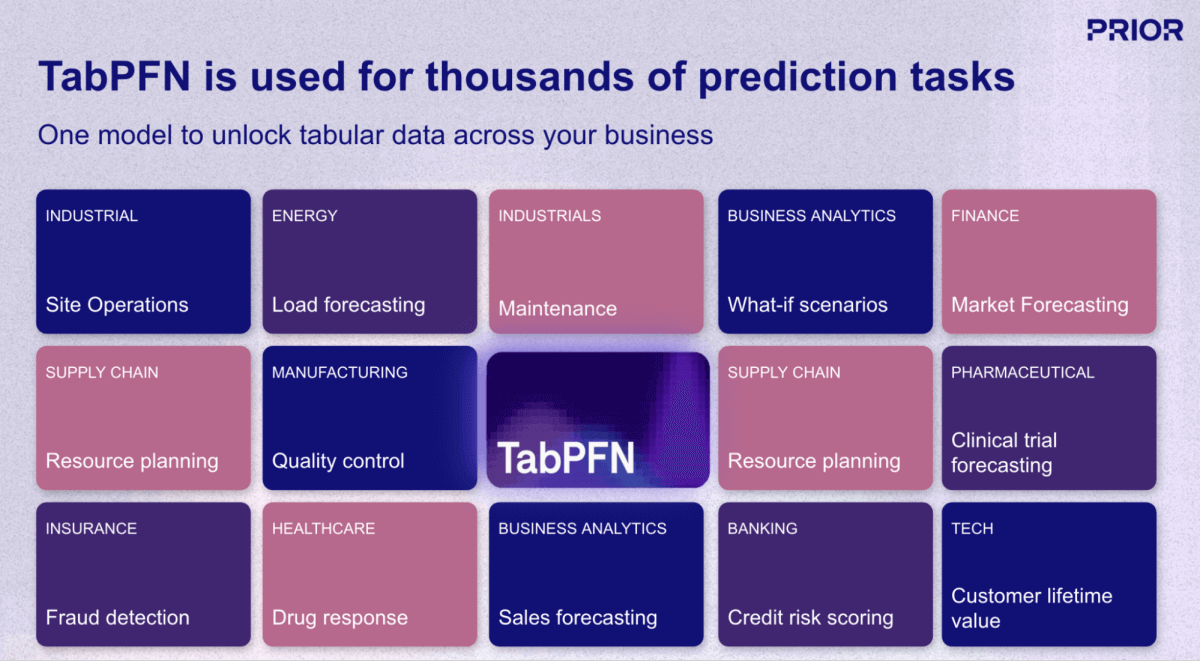
Eine der vielversprechendsten Entwicklungen in diesem Bereich ist TabPFN, ein Foundation-Modell (KI) von Prior Labs, das den Workflow für machine learning (ML) für strukturierte Daten grundlegend neu gestaltet. Im Gegensatz zu herkömmlichen ML-Ansätzen, die für jede Vorhersage-Task die Erstellung und das Training eines einzigartigen Modells erfordern, wendet TabPFN dasselbe "vortrainierte, einsatzbereite" Paradigma von LLMs auf tabellarische Geschäftsdaten an. Das Modell wurde mit über 130 Millionen synthetischen Datasets vortrainiert, wodurch es effektiv "gelernt hat zu lernen", und zwar mit strukturierten Daten aus praktisch jeder Domäne und jedem Anwendungsfall (Abbildung 1).
{kind=link}
Verkürzung der ML-Timeline
Die Auswirkungen auf die ML-Produktivität sind dramatisch. Während bei herkömmlichen Ansätzen Data Scientists Stunden oder Tage in die Datenaufbereitung, das Feature-Engineering, die Modellauswahl und die Hyperparameter-Optimierung investieren müssen, liefert TabPFN Vorhersagen auf Produktionsniveau in einem einzigen Forward-Pass, was in der Regel in Sekunden gemessen wird.
Das Modell verarbeitet Roheingaben direkt und verwaltet automatisch fehlende Werte, gemischte Datentypen, kategorische und Text-Features sowie Ausreißer, ohne die aufwendige Vorverarbeitung zu benötigen, die typischerweise den Großteil des Aufwands im Bereich Data Science ausmacht. Besonders bedeutsam ist vielleicht, dass TabPFN den laufenden Wartungsaufwand für das Nachtrainieren von Modellen überflüssig macht: Sobald neue Daten verfügbar sind, aktualisieren Unternehmen einfach den Kontext des Modells, anstatt einen neuen Trainingszyklus zu starten.
Performance ohne Kompromisse
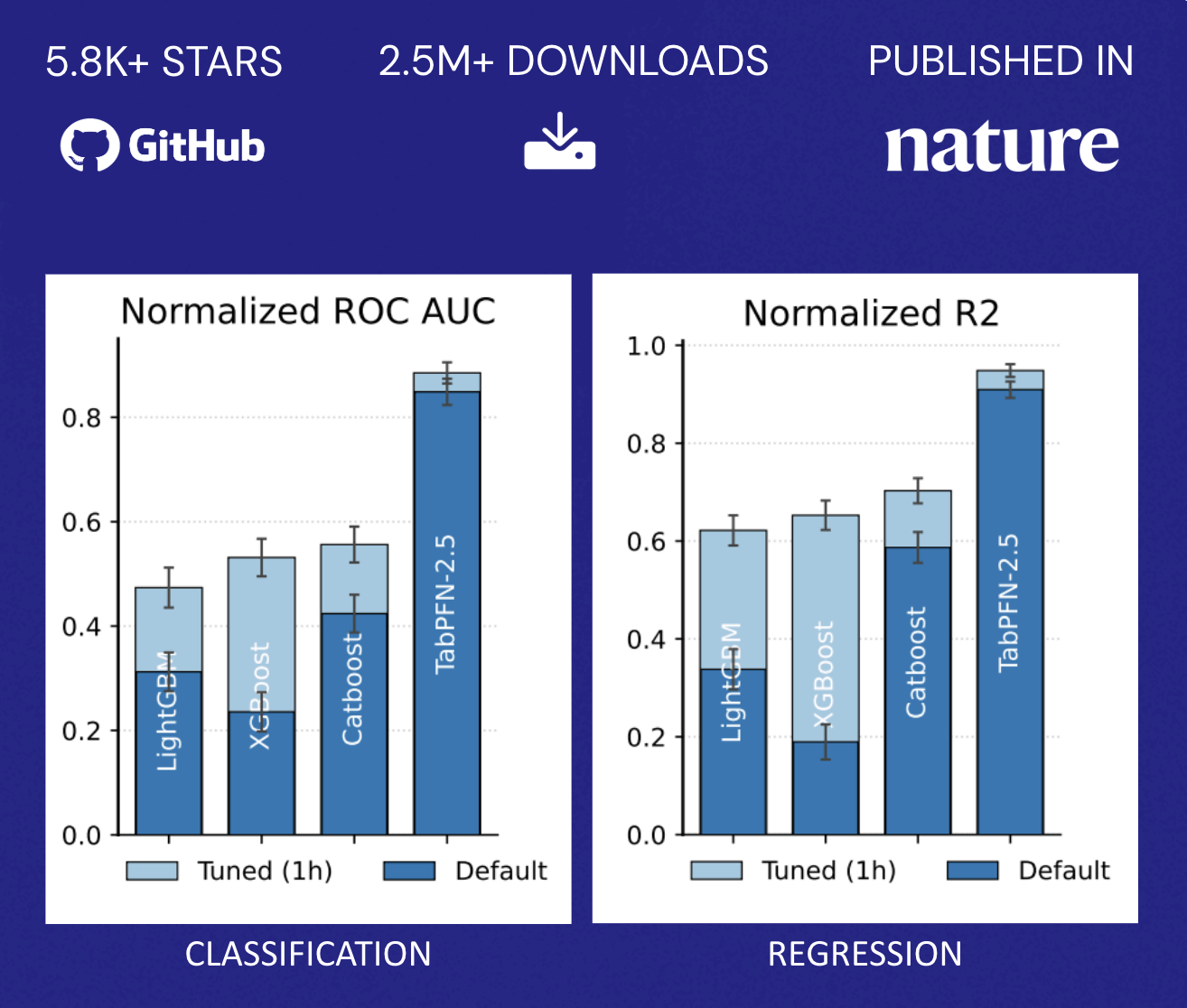
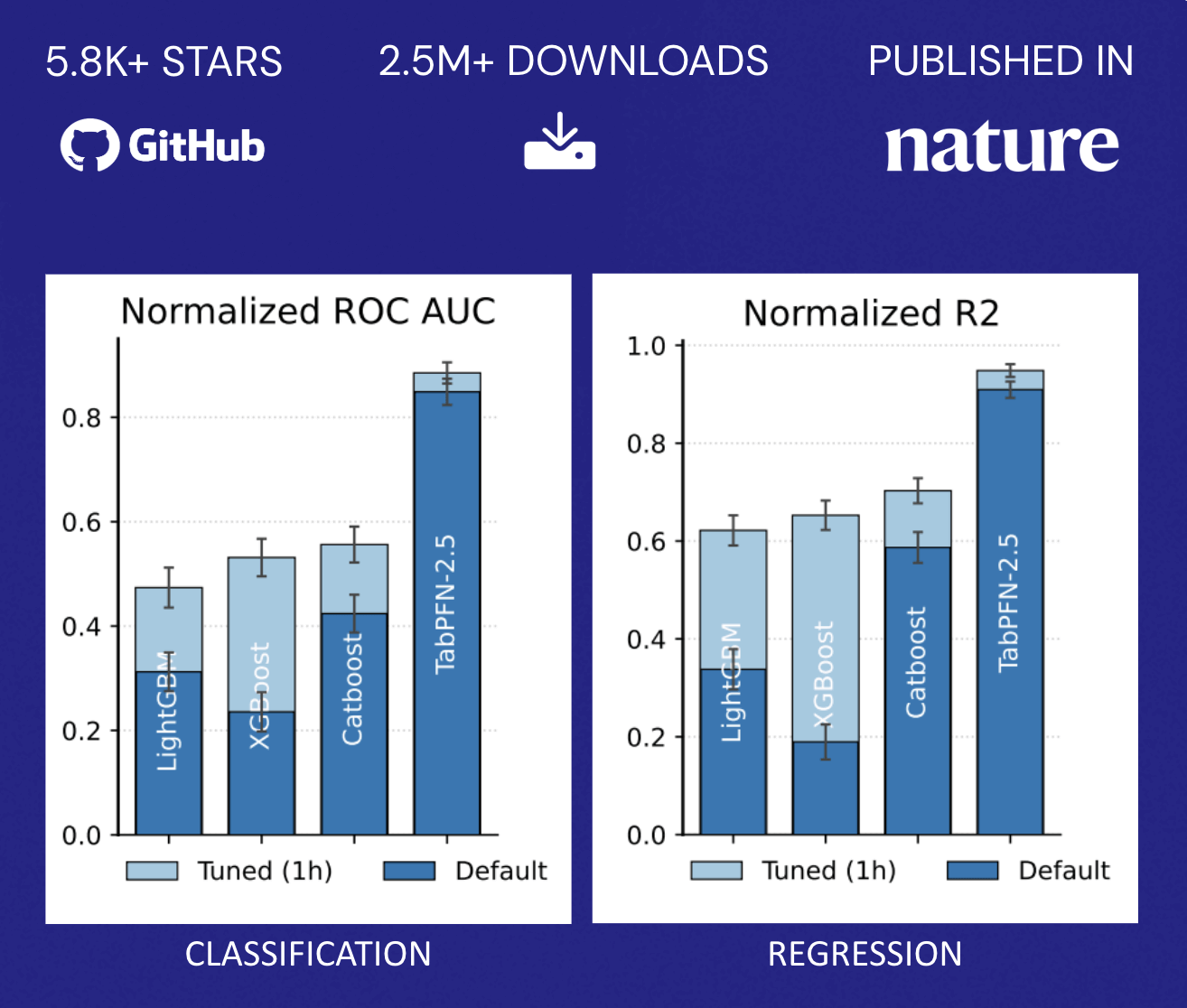
TabPFN übertrifft die Genauigkeit herkömmlicher Methoden, die stundenlanges automatisiertes Tuning erfordern. Dieses Performanceprofil verändert die zuvor beschriebene Wirtschaftlichkeit grundlegend: Unternehmen stehen nicht mehr vor der binären Wahl zwischen Modellgenauigkeit und Ressourcenzuweisung. Stattdessen können sie prädiktive F�ähigkeiten für ein breiteres Spektrum von Anwendungsfällen schnell bereitstellen, ohne ihre Data Science-Teams proportional zu vergrößern. Dies demokratisiert ML über die Handvoll der wertvollsten Anwendungen hinaus, die typischerweise dedizierte Optimierungsanstrengungen rechtfertigen (Abbildung 2).
{kind=link}
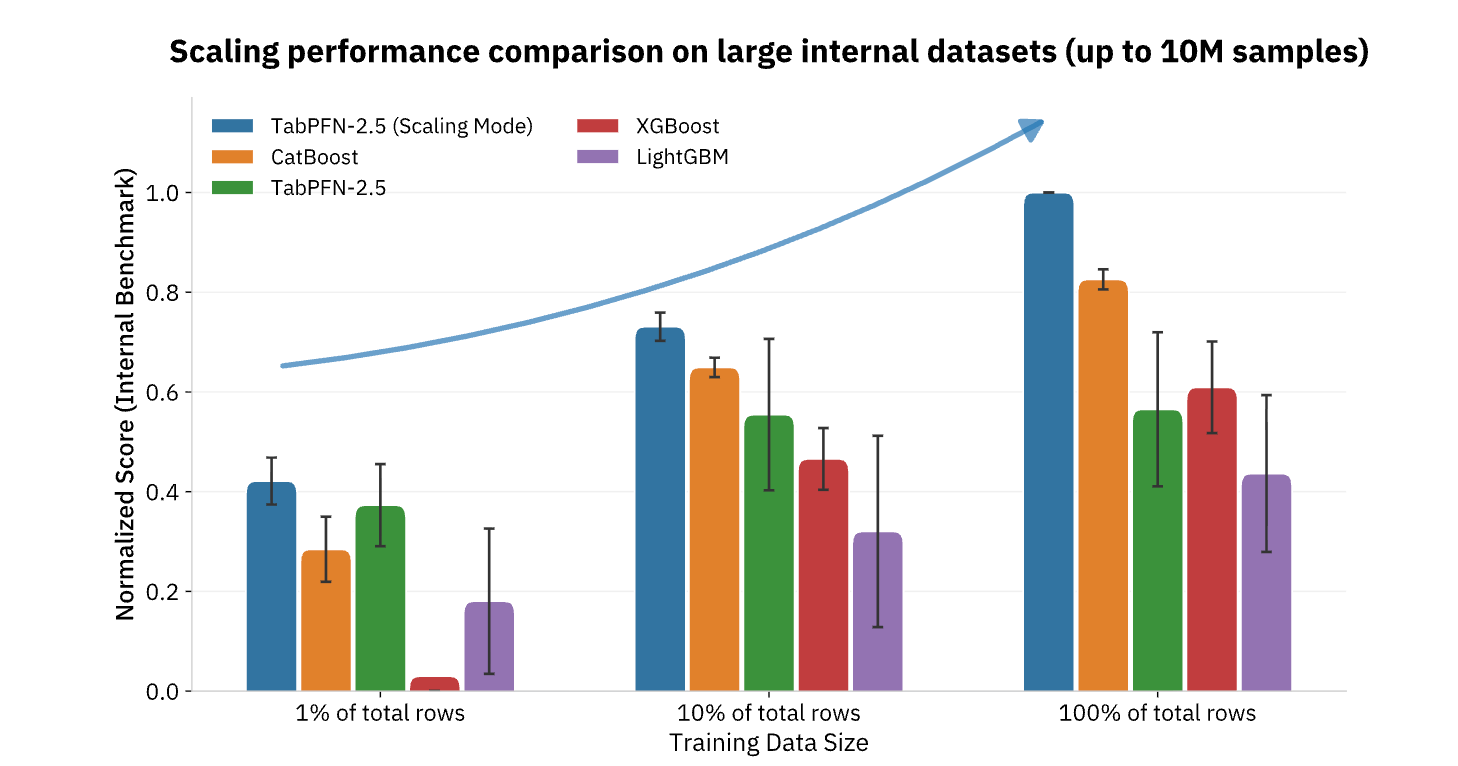
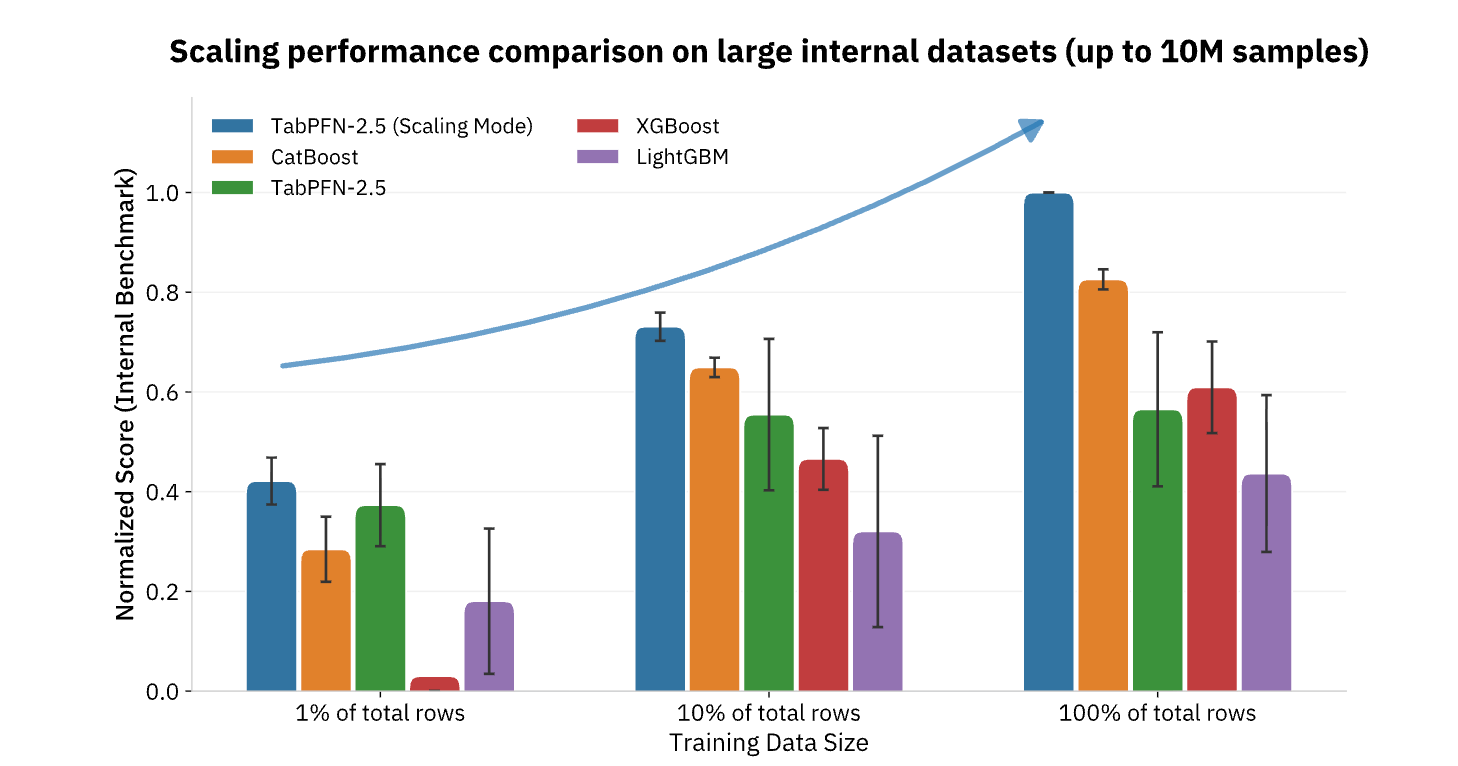
Skalierung des Einflusses von KI auf strukturierte Vorhersagen
TabPFN unterstützt derzeit Datensätze mit bis zu 100.000 Zeilen und 2.000 Merkmalen, wobei Unternehmensversionen die Unterstützung auf 10 Millionen Zeilen erweitern und so die überwiegende Mehrheit der operativen ML-Anwendungsfälle im Einzelhandel, im Finanz- und Gesundheitswesen, in der Fertigung und in anderen Branchen abdecken. Für Unternehmen, die KI über die Erstellung von Inhalten und Natural Language Tasks hinaus operationalisieren möchten, stellen Foundation Models wie TabPFN das fehlende Teil dar, das die gleichen sprunghaften Produktivitätsverbesserungen für die strukturierten Daten und die Predictive Analytics bringt, die seit langem das Rückgrat der datengesteuerten Entscheidungsfindung bilden (Abbildung 3).
{kind=link}
TabPFN wird bereits in vielen realen Anwendungen für Unternehmen auf der ganzen Welt eingesetzt. Implementierungen in verschiedenen Bereichen, vom Finanzrisikomanagement mit Taktile über die Bewertung von Gesundheitsergebnissen mit NHS bis hin zur vorausschauenden Wartung mit Hitachi, haben eine Steigerung erfahren – sowohl bei der Effizienz als auch bei der Qualität der Ergebnisse. TabPFN übertrifft durchweg herkömmliche ML-Methoden, verbessert die Baseline um 10%-65% und beschleunigt Data-Science-Workflows um 90%. Unternehmen erschließen Umsatzsteigerungen, bessere Gesundheitsergebnisse, Einsparungen bei den Wartungskosten, Abwanderungsprävention und vieles mehr.
Verwendung von TabPFN mit Databricks
Databricks ist seit Langem die bevorzugte Plattform für Data Scientists, die prädiktive Fähigkeiten mit Machine Learning (ML) aufbauen möchten. Als offene Plattform eignet sich TabPFN gut für den Einsatz innerhalb der Databricks-Plattform.
Dort entwickeln, wo die Daten liegen
Das meiste klassische ML in Unternehmen beginnt mit Lakehouse-Daten: Transaktionen, Betriebstelemetrie, Kundenereignisse, Bestandssignale und Risikoindikatoren. Die Verlagerung dieser Daten in externe Umgebungen verlangsamt Teams, indem sie Duplikate erzeugt, das Sicherheitsrisiko erhöht und die Reproduzierbarkeit und Überprüfbarkeit schwächt. Databricks ermöglicht TabPFN-Workflows direkt neben den verwalteten Daten, sodass Teams die Datenverschiebung minimieren und gleichzeitig die Kontrollen beibehalten können. Mit dem Unity Catalog zentralisieren Unternehmen die Zugriffskontrolle und die Überprüfung und bewahren die Herkunft über Daten- und KI-Assets hinweg, was wichtig ist, wenn Sie nachweisen müssen, welche Daten verwendet wurden, wie Features abgeleitet wurden und wer zum Zeitpunkt der Entscheidung Zugriff hatte.
Ergebnisse effizient operationalisieren
TabPFN ist ein Modellierungsansatz. Um in der Produktion Wirkung zu erzielen, muss es sich in wiederholbare Unternehmensmuster wie Batch- und Echtzeit-Scoring, Evaluierung, Governance und Monitoring integrieren lassen. Databricks ist eine starke Plattform für diese Workflows, mit skalierbarer compute- und Echtzeit-Inferenz-Infrastruktur, die TabPFN in einen zuverlässigen operativen Prozess verwandeln kann. Für die Evaluierung und das Monitoring bietet MLflow Experiment-Tracking und eine Modellregistrierung, um Versionen, Lineage und Promotion-Workflows auf auditierbare Weise zu verwalten.
Laufende Modell-Governance bereitstellen
Databricks bietet ein kontinuierliches Monitoring der Performance des TabPFN-Modells und erkennt, wenn Vorhersagen von den tatsächlichen Geschäftsergebnissen abweichen. Wenn Anpassungen erforderlich sind, eliminiert die Architektur von TabPFN den traditionellen, wochenlangen Retraining-Zyklus: Teams aktualisieren einfach den Kontext des Modells mit aktuellen Daten und stellen es innerhalb von Minuten statt Tagen erneut bereit. Diese Kombination aus automatisiertem Monitoring und schneller Aktualisierungsfähigkeit stellt sicher, dass die Vorhersagequalität an veränderte Marktbedingungen angepasst bleibt, und reduziert gleichzeitig drastisch die Data Science Ressourcen, die typischerweise für die laufende Modellwartung erforderlich sind.
Um Teams beim Testen von TabPFN mit minimalem Einrichtungsaufwand zu helfen, haben wir einen öffentlich verfügbaren Solution Accelerator veröffentlicht, der zeigt, wie man TabPFN End-to-End auf Databricks mit verwalteten Lakehouse-Daten ausführt. Der Accelerator enthält eine Reihe von Notebooks, die realistisch Daten aus einer Vielzahl von Branchenszenarien simulieren und mit TabPFN Vorhersagen erstellen (Video 1).
Legen Sie noch heute los, bringen Sie die transformative Kraft der KI in Ihre ML-Workloads und treiben Sie die durchgängige Transformation von Geschäftsprozessen voran.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.