Was sind Hash-Buckets?
Eine Feature-Engineering-Technik, die kategoriale Variablen mit hoher Kardinalität mithilfe von Hash-Funktionen auf Vektoren fester Größe abbildet, um eine effiziente Speichernutzung im maschinellen Lernen zu ermöglichen.
- Wendet Hash-Funktionen (wie MurmurHash3) an, um kategoriale Merkmale in Buckets fester Größe zu konvertieren und so den Speicherbedarfs-Explosion der One-Hot-Kodierung für Variablen mit hoher Kardinalität zu vermeiden.
- Akzeptiert Hash-Kollisionen, bei denen mehrere Werte demselben Bucket zugeordnet werden. Dies reduziert die Genauigkeit zugunsten einer deutlich höheren Speicher- und Recheneffizienz beim Streaming und Lernen großer Datenmengen.
- Wird häufig in Spamfiltern, Empfehlungssystemen und der CTR-Vorhersage eingesetzt, wo Merkmalsräume Millionen eindeutiger Werte enthalten können, die eine herkömmliche Kodierung unmöglich machen.
Als Hashtabelle [Hash-Map] bezeichnet man in der Informatik eine Datenstruktur, die auf Grundlage eines Schlüssels [einer eindeutigen Zeichenfolge oder Ganzzahl] praktisch direkten Zugriff auf Objekte bietet. Eine Hashtabelle verwendet eine Hashfunktion zum berechnungsgestützten Hinzufügen eines Index zu einem Array mit Buckets oder Slots, denen der gewünschte Wert dann entnommen werden kann. Der verwendete Schlüssel weist die folgenden Hauptmerkmale auf:
- Der Schlüssel kann die Nummer Ihres Personalausweises, Ihre Telefonnummer, Kontonummer usw. sein.
- Schlüssel müssen eindeutig sein.
- Jeder Schlüssel ist mit einem Wert verknüpft. Man spricht auch vom Mapping von Schlüssel und Wert.
Das Playbook für agentenbasierte KI für Unternehmen

Mit Hashbuckets werden Datenelemente zu Sortier- oder Nachschlagezwecken verteilt. Zweck dieses Verfahrens ist es, den Einfluss der verknüpften Listen zu reduzieren, damit die Suche nach einem bestimmten Element beschleunigt werden kann. 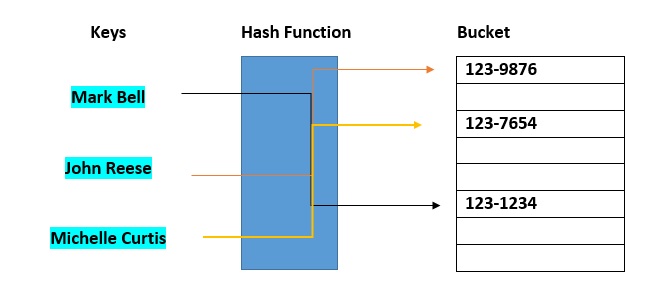 Eine Hashtabelle, die Buckets verwendet, ist eigentlich eine Kombination aus einem Array und einer verknüpften Liste. Jedes Element im Array [der Hashtabelle] ist ein Header für eine verknüpfte Liste. Alle Elemente, die am selben Standort gehasht werden, werden in der Liste gespeichert. Die Hashfunktion ordnet die Datensätze dem jeweils ersten Slot eines der Buckets zu. Ist der Slot bereits belegt, dann werden die Bucket-Slots der Reihe nach durchsucht, bis ein freier Slot gefunden wird. Wenn ein Bucket komplett voll ist, wird der Datensatz in einem Overflow-Bucket mit unendlicher Kapazität am Ende der Tabelle gespeichert. Alle Buckets verwenden denselben Overflow-Bucket. Gute Implementierungen nutzen jedoch eine Hashfunktion, die die Datensätze gleichmäßig auf die Buckets verteilt, damit möglichst wenige Datensätze in den Overflow-Bucket gelangen.
Eine Hashtabelle, die Buckets verwendet, ist eigentlich eine Kombination aus einem Array und einer verknüpften Liste. Jedes Element im Array [der Hashtabelle] ist ein Header für eine verknüpfte Liste. Alle Elemente, die am selben Standort gehasht werden, werden in der Liste gespeichert. Die Hashfunktion ordnet die Datensätze dem jeweils ersten Slot eines der Buckets zu. Ist der Slot bereits belegt, dann werden die Bucket-Slots der Reihe nach durchsucht, bis ein freier Slot gefunden wird. Wenn ein Bucket komplett voll ist, wird der Datensatz in einem Overflow-Bucket mit unendlicher Kapazität am Ende der Tabelle gespeichert. Alle Buckets verwenden denselben Overflow-Bucket. Gute Implementierungen nutzen jedoch eine Hashfunktion, die die Datensätze gleichmäßig auf die Buckets verteilt, damit möglichst wenige Datensätze in den Overflow-Bucket gelangen.
Zusätzliche Ressourcen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.