Was ist Lambda-Architektur?
Architektur, die Batch- und Stream-Verarbeitung kombiniert, mit einer Batch-Schicht für Genauigkeit, einer Geschwindigkeitsschicht für Echtzeitergebnisse und einer Bereitstellungsschicht, die beides zusammenführt.
- Die Batch-Schicht speichert den Master-Datensatz unveränderlich und nur erweiterbar. Sie berechnet Batch-Ansichten mittels MapReduce-ähnlicher Verarbeitung vor und liefert so genaue und umfassende Ergebnisse, allerdings mit stundenlanger Latenz.
- Die Speed-Schicht verarbeitet ausschließlich aktuelle Datenströme mithilfe latenzarmer Systeme wie Storm oder Flink und erzeugt Echtzeitansichten, die die Verzögerung der Batch-Schicht kompensieren. Bei Aktualisierungen der Batch-Ansichten wird letztendlich Konsistenz erreicht.
- Die Serving-Schicht indiziert Batch- und Speed-Ansichten und ermöglicht so schnelle Ad-hoc-Abfragen, die beide Perspektiven zusammenführen. Die Architekturkomplexität hat sich jedoch verringert, da Streaming-Systeme wie Apache Spark sowohl Batch- als auch Echtzeitfunktionen bieten.
Was ist eine Lambda-Architektur?
Lambda-Architekturen sind eine Methode zur Verarbeitung großer Datenmengen (d. h. „Big Data“), die mit einem hybriden Ansatz Zugang zu Batch- und Stream-Verarbeitungsmethoden bietet. Mithilfe einer Lambda-Architektur lässt sich das Problem der Berechnung beliebiger Funktionen lösen. Lambda-Architekturen selbst bestehen aus drei Schichten:
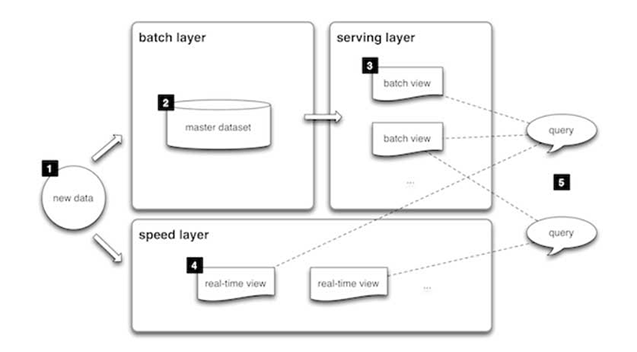
Batch-Schicht
Neue Daten werden kontinuierlich in das Datensystem eingespeist. Sie werden gleichzeitig an die Batch- und die Speed-Schicht weitergeleitet. Alle Daten werden gleichzeitig betrachtet und schließlich in der Streaming-Schicht korrigiert. Hier finden wir viel ETL und ein traditionelles Data Warehouse. Diese Schicht wird nach einem vordefinierten Zeitplan erstellt – in der Regel ein- oder zweimal pro Tag. Die Batch-Schicht erfüllt zwei sehr wichtige Funktionen:
- Sie verwaltet das Stamm-Dataset.
- Sie berechnet die Batch-Ansichten voraus.
Bereitstellungsschicht
Die Ausgaben der Batch-Schicht in Form von Batch-Ansichten und die der Speed-Schicht in Form von Quasi-Echtzeit-Ansichten werden an die Bereitstellung weitergeleitet. Diese Schicht indiziert die Batch-Ansichten, sodass sie mit geringster Latenz ad-hoc abgefragt werden können.
Speed-Schicht (Streaming-Schicht)
Diese Schicht verarbeitet die Daten, die aufgrund der Latenzzeit der Batch-Schicht nicht bereits in der Batch-Ansicht bereitgestellt werden. Außerdem werden hier nur aktuelle Daten bearbeitet, um dem Benutzer durch die Erstellung von Echtzeitansichten einen vollständigen Überblick über die Daten zu vermitteln.
Das Playbook für agentenbasierte KI für Unternehmen

Vorteile von Lambda-Architekturen
Nachfolgend finden Sie die wichtigsten Vorteile von Lambda-Architekturen:
- Keine Serververwaltung: Sie müssen Software weder installieren noch warten oder verwalten.
- Flexible Skalierung: Ihre Anwendung kann entweder automatisch oder durch Anpassung der Kapazität skaliert werden.
- Automatisierte Hochverfügbarkeit: Bezeichnet die Tatsache, dass serverlose Anwendungen bereits über integrierte Verfügbarkeit und Fehlertoleranz verfügen. Sie bietet die Garantie dafür, dass alle Anfragen beantwortet werden, ganz gleich, ob sie erfolgreich waren oder nicht.
- Business Agility: Sie können in Echtzeit auf geänderte Geschäfts- und Marktszenarien reagieren.
Mögliche Schwierigkeiten bei Lambda-Architekturen
- Komplexität: Lambda-Architekturen können sehr komplex sein. Administratoren müssen in der Regel zwei getrennte Codebasen für die Batch- und die Streaming-Schicht pflegen, was die Fehlersuche erschweren kann.
Verwandte Themen
Delta Lake: Einheitliche Batch- und Streaming-Quelle und -Senke
Zusätzliche Ressourcen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.