Intelligentes Data Warehousing auf Databricks – Kloniert
Diese Referenzarchitektur zeigt, wie die Databricks Data Intelligence Platform modernes Data Warehousing und BI durch Streaming- und Batch-Ingestion, governed Storage, skalierbare SQL-Analysen und integrierte AI im einheitlichen Lakehouse ermöglicht.
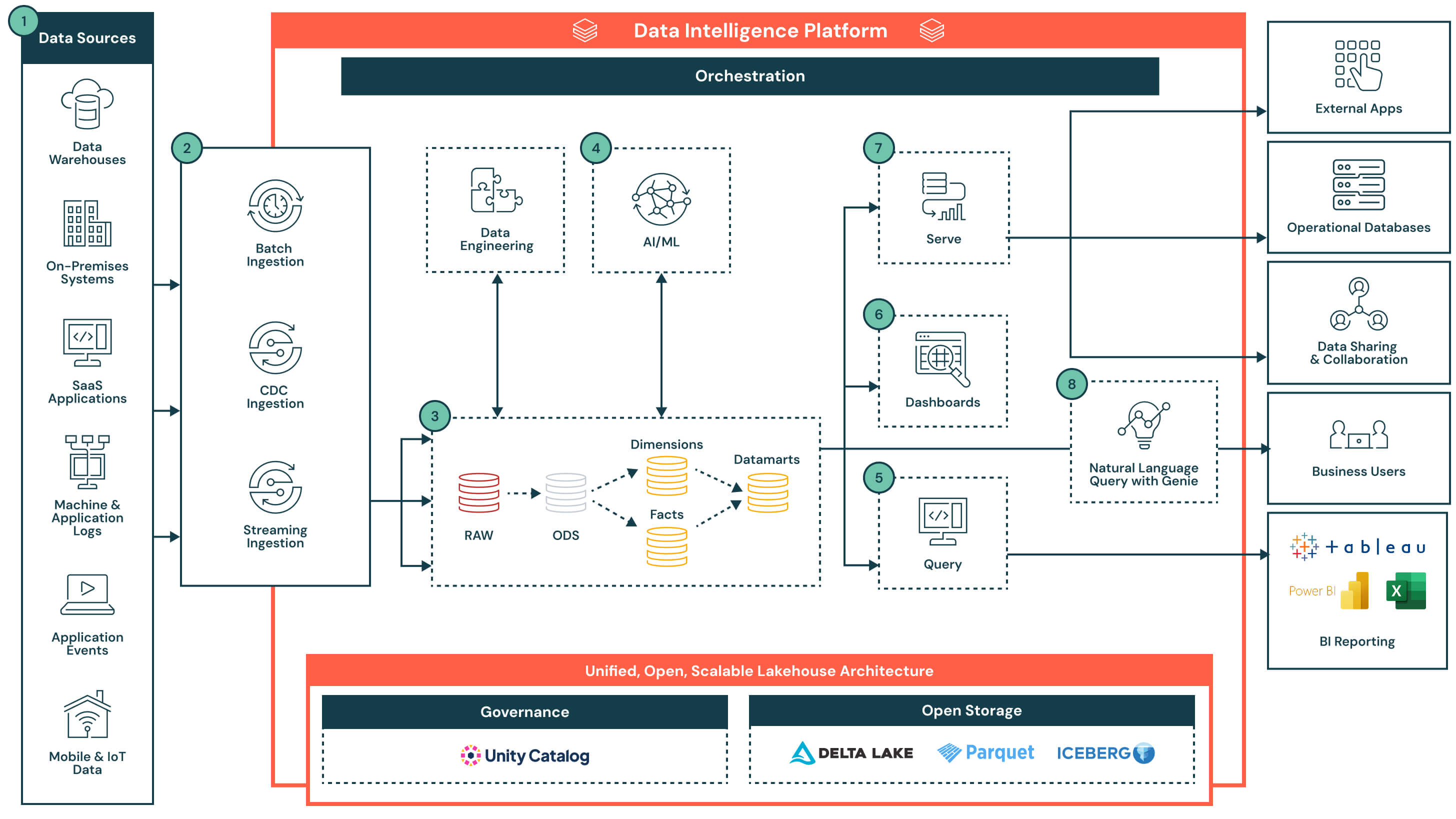
Architektur-Übersicht
Die Architektur unterstützt traditionelles Reporting, Echtzeit-Dashboards, prädiktive Modellierung und Self-Service-Analytics – und erfüllt gleichzeitig die Unternehmensstandards für Sicherheit, Governance und Performance.
Diese Lösung zeigt, wie die Databricks Data Intelligence Platform, powered by Databricks Lakehouse, Unternehmen dabei unterstützt, ihre Data-Warehousing-Strategie zu modernisieren und gleichzeitig den Anforderungen von Datenteams und Business-Stakeholdern gerecht zu werden.
Die Architektur beginnt mit einem offenen, kontrollierten Lakehouse, das von Unity Catalog verwaltet wird. Daten werden aus einer Vielzahl von Systemen geladen – darunter operative Datenbanken, SaaS-Apps, Event-Streams und Dateisysteme – und landen in einer zentralen Speicherebene. Die Data Intelligence der Plattform unterstützt alles von ETL- und SQL-Analysen bis hin zu Dashboards und AI-Anwendungsfällen. Durch die Unterstützung des flexiblen Zugriffs über SQL, BI-Tools und Abfragen in natürlicher Sprache beschleunigt die Plattform die Bereitstellung von Datenprodukten und macht Erkenntnisse im gesamten Unternehmen zugänglich.
Anwendungsfälle
Technische Anwendungsfälle
- Erfassen von strukturierten, unstrukturierten, Batch- und Streaming-Daten aus verschiedenen Quellen
- Erstellen robuster, deklarativer ETL-Pipelines
- Modellieren von Fakten, Dimensionen und Data Marts mithilfe einer Medallion-Architektur
- Ausführen von hochgradig gleichzeitigen SQL-Abfragen für Reporting und Dashboards
- Direktes Integrieren von ML-Ergebnissen in das Warehouse für die nachgelagerte Nutzung
Geschäftliche Anwendungsfälle
- Bereitstellen von Echtzeit-Dashboards für Vertriebs-, Betriebs- oder Kundenkennzahlen
- Ermöglichen von Ad-hoc-Explorationen über Schnittstellen in natürlicher Sprache wie Genie
- Unterstützen prädiktiver Anwendungsfälle wie Bedarfsprognosen und Churn-Modellierung
- Sicheres Teilen kontrollierter Datenprodukte abteilungsübergreifend oder mit Partnern
- Bereitstellen schneller, zuverlässiger Erkenntnisse für Finanz-, Marketing- und Produktteams
Schlüsselfunktionen mit Data Intelligence
Die Data-Intelligence-Komponente dieser Architektur macht die Plattform intelligenter, anpassungsfähiger und benutzerfreundlicher für verschiedene Personas und Workloads. Sie nutzt AI und Metadaten-Erkennung im gesamten System, um Prozesse zu vereinfachen und Entscheidungen zu automatisieren:
- Schnittstelle für natürliche Sprache (Genie): Versteht den geschäftlichen Kontext und ermöglicht es Benutzern, Fragen zu Daten in einfacher Sprache zu stellen
- Semantisches Verständnis: Erkennt Beziehungen zwischen Tabellen, Spalten und Nutzungsmustern, um Joins, Filter oder Berechnungen vorzuschlagen
- Prädiktive Optimierung: Optimiert kontinuierlich die Abfrageleistung und die Compute-Zuweisung basierend auf historischen Workloads
- Einheitliche Governance: Kennzeichnet, klassifiziert und verfolgt die Nutzung von Daten-Assets, was das Auffinden intuitiver und sicherer macht
- Schlüsselfunktion: Eine selbstoptimierende Plattform, die sich an Ihre Daten und Benutzer anpasst
- Alleinstellungsmerkmal: Data Intelligence ist direkt in Ingestion, Abfrage, Governance und Visualisierung integriert – nicht nachträglich aufgesetzt
Datenfluss mit Schlüsselfunktionen und Alleinstellungsmerkmalen
- Datenquellen: Daten werden in einer Vielzahl von Systemen gespeichert, darunter Unternehmensanwendungen (z. B. SAP, Salesforce), Datenbanken, IoT-Geräte, Anwendungsprotokolle und externe APIs. Diese Quellen können strukturierte, semistrukturierte oder unstrukturierte Daten erzeugen.
- Daten-Ingestion: Importiert Daten über Batch-Jobs, Change Data Capture (CDC) oder Streaming. Diese Pipelines speisen die Lakehouse-Architektur nahezu in Echtzeit oder in geplanten Intervallen, je nach Quellsystem und Anwendungsfall.
- Wichtigstes Alleinstellungsmerkmal: Einheitliche Ingestion für alle Modalitäten – Batch, Streaming und CDC – ohne separate Infrastruktur oder Pipelines zu benötigen
- Datentransformation, ETL, deklarative Pipelines: Nach dem Laden werden die Daten über die Medallion-Architektur transformiert und schrittweise von Rohdaten zu kuratierten Daten verfeinert.
- Raw-Zone zu Bronze-Zone: Aus externen Quellsystemen geladene Daten, wobei die Strukturen in dieser Ebene den Tabellenstrukturen des Quellsystems im Ist-Zustand entsprechen, ohne Transformationen oder Aktualisierungen der Daten
- Bronze-Zone zu Silver-Zone: Standardisieren und Bereinigen eingehender Daten
- Silver-Zone zu Gold-Zone: Anwenden von Geschäftslogik zur Erstellung wiederverwendbarer Modelle
- Fakten und Dimensionen → Data Marts: Aggregieren und Kuratieren von Daten für nachgelagerte Analysen
- Wichtigstes Alleinstellungsmerkmal: Deklarative, produktionsreife Pipelines mit integrierter Lineage, Observability und Schema-Evolution
- Kuratierte Daten für AI-Anwendungsfälle: Kuratierte Daten aus Data Marts können zum Trainieren oder Anwenden von Machine-Learning-Modellen verwendet werden. Diese Modelle unterstützen Anwendungsfälle wie Bedarfsprognosen, Anomalieerkennung und Customer Scoring.
- Modellergebnisse werden zusammen mit traditionellen Warehouse-Daten gespeichert, um einen einfachen Zugriff über SQL oder Dashboards zu ermöglichen
- Ergebnisse können je nach Anforderungen nach Zeitplan aktualisiert oder in Echtzeit bewertet werden
- Wichtigstes Alleinstellungsmerkmal: Gemeinsam lokalisierte Analyse- und AI-Workloads auf derselben Plattform – kein Datentransfer erforderlich. Modellergebnisse werden als native, abfragbare und kontrollierte Assets behandelt.
- Abfragegestützte BI-Reporting-Tools: Databricks Lakehouse unterstützt Abfragen mit hoher Nebenläufigkeit und geringer Latenz durch Serverless-Compute und lässt sich problemlos mit gängigen BI-Tools verbinden.
- Integrierter Abfrage-Editor und Abfrageverlauf
- Abfragen liefern kontrollierte, aktuelle Ergebnisse aus Data Marts oder angereicherten Modellausgaben
- Wichtigstes Alleinstellungsmerkmal: Das Databricks Lakehouse ermöglicht es BI-Tools, Daten direkt und ohne Replikation abzufragen. Dies reduziert die Komplexität, vermeidet zusätzliche Lizenzkosten und senkt die TCO. In Kombination mit Serverless-Compute und intelligenter Optimierung bietet es Performance auf Data-Warehouse-Niveau bei minimalem Abstimmungsaufwand.
- Dashboards: Können direkt in Databricks oder in externen BI-Tools wie Power BI oder Tableau erstellt werden. Benutzer können Visualisierungen in natürlicher Sprache beschreiben, und der Databricks Assistant erstellt die entsprechenden Diagramme, die dann über eine Point-and-Click-Benutzeroberfläche verfeinert werden können.
- Visualisierungen mithilfe von natürlicher Spracheingabe erstellen
- Dashboards interaktiv mit Filtern und Drilldowns anpassen und untersuchen
- Dashboards im gesamten Unternehmen veröffentlichen und sicher teilen, auch mit Benutzern außerhalb des Databricks-Workspace
- Wichtigstes Alleinstellungsmerkmal: Bietet eine Low-Code- und KI-gestützte Benutzeroberfläche zum Erstellen und Erkunden von Dashboards auf Basis von kontrollierten Echtzeitdaten
- Bereitstellung kuratierter Daten: Nach der Bereinigung können Daten auch über Dashboards hinaus bereitgestellt werden:
- Freigabe für nachgelagerte Anwendungen oder operative Datenbanken für transaktionale Entscheidungen
- Nutzung in kollaborativen Notebooks für Analysen
- Verteilung über Delta Sharing an Partner, Teams oder externe Konsumenten mit einheitlicher Governance
- Abfragen in natürlicher Sprache (NLQ): Geschäftsanwender können mithilfe natürlicher Sprache auf kontrollierte Daten zugreifen. Diese dialogorientierte Benutzeroberfläche, die auf generativer KI basiert, ermöglicht es Teams, über statische Dashboards hinauszugehen und Echtzeit-Erkenntnisse im Self-Service zu gewinnen. NLQ übersetzt die Absicht des Benutzers in SQL, indem es die Semantik und die Metadaten des Unternehmens aus dem Unity Catalog nutzt.
- Unterstützt interaktive Ad-hoc-Fragen in Echtzeit, die nicht vordefiniert in Dashboards integriert sind
- Passt sich im Laufe der Zeit intelligent an sich ändernde Geschäftsterminologie und -kontexte an
- Nutzt vorhandene Data Governance und Zugriffskontrollen über Unity Catalog
- Bietet Auditierbarkeit und Rückverfolgbarkeit von Abfragen in natürlicher Sprache für Compliance und Transparenz
- Wichtigstes Alleinstellungsmerkmal: Passt sich kontinuierlich an neue Geschäftskonzepte an und liefert präzise, kontextbezogene Antworten, ohne dass SQL-Kenntnisse erforderlich sind
- Plattformfunktionen: Governance, Performance, Orchestrierung und offener Speicher: Die Architektur basiert auf einer Reihe plattformeigener Funktionen, die Sicherheit, Optimierung, Automatisierung und Interoperabilität über den gesamten Datenlebenszyklus hinweg unterstützen. Wichtigste Funktionen:
- Governance: Unity Catalog bietet zentrale Zugriffskontrolle, Lineage, Auditing und Datenklassifizierung für alle Workloads
- Performance: Die Photon-Engine, intelligentes Caching und workload-bezogene Optimierung ermöglichen schnelle Abfragen ohne manuelle Abstimmung
- Orchestrierung: Die integrierte Orchestrierung verwaltet Datenpipelines, KI-Workflows und geplante Jobs für Batch- und Streaming-Workloads, mit nativer Unterstützung für Abhängigkeitsmanagement und Fehlerbehandlung
- Offener Speicher: Daten werden in offenen Formaten (Delta Lake, Parquet, Iceberg) gespeichert, was die Interoperabilität zwischen Tools, die Portabilität zwischen Plattformen und die langfristige Beständigkeit ohne Vendor-Lock-in ermöglicht
- Überwachung und Auditierbarkeit: End-to-End-Transparenz bei Abfrage-Performance, Pipeline-Ausführung und Benutzerzugriffen für eine bessere Kontrolle und Kostenverwaltung
- Wichtigstes Alleinstellungsmerkmal: Services auf Plattformebene sind integriert – nicht nachträglich aufgesetzt – was sicherstellt, dass Governance, Automatisierung und Performance über alle Daten-Workflows, Clouds und Teams hinweg konsistent sind


