10 billions d'échantillons par jour : Mise à l'échelle au-delà de l'infrastructure de surveillance traditionnelle chez Databricks
Comment nous avons construit une plateforme de surveillance conçue pour la croissance exponentielle de Databricks
par David Yuan, Yi Jin, Karan Bavishi, HC Zhu et Joey Beyda
- Les systèmes de surveillance de Databricks gèrent plus de 5 milliards de séries chronologiques actives en temps réel sur AWS, Azure et GCP.
- Pour maintenir ces systèmes fiables et nécessitant peu d'intervention malgré une mise à l'échelle rapide, nous avons réarchitecturé nos couches TSDB et d'agrégation en personnalisant des solutions de surveillance open source.
- Face à la forte croissance des métriques de dépannage à haute cardinalité, nous avons développé une nouvelle plateforme basée sur le Lakehouse appelée Hydra. Cette approche a débloqué de riches capacités de débogage à grande échelle et un stockage 50 fois moins cher que notre pile existante.
L'infrastructure de surveillance de Databricks a plus que triplé de taille au cours de la dernière année, suivant désormais 5 milliards de séries chronologiques actives en temps réel et ingérant plus de 10 billions d'échantillons par jour. À cette échelle massive, nous avons constaté que les solutions prêtes à l'emploi étaient inefficaces ou difficiles à adapter à nos exigences. Cet article partage ce que nous avons construit à la place : une plateforme évolutive qui tire parti du meilleur de l'écosystème de surveillance open source tout en intégrant des personnalisations pour nos besoins uniques.
Les ingénieurs de Databricks dépendent de systèmes de surveillance qui nous alertent rapidement des problèmes, automatisent la mise à l'échelle et les restaurations, et permettent un dépannage intelligent. Ces systèmes doivent être très fiables afin que nous puissions être certains de ne pas être pris au dépourvu lors d'un incident potentiel. Cependant, développer cette infrastructure à l'échelle de Databricks s'est avéré être un défi de taille :
- Outre les exigences de scalabilité, de fiabilité et d'efficacité, nous exploitons nos systèmes à l'échelle mondiale dans environ 70 régions cloud, réparties sur les 3 principaux fournisseurs de cloud. Nous devons prendre en charge des performances équivalentes malgré les différences entre les clouds, et même entre les régions individuelles.
- Face à cette étendue et cette variété, l'exploitation d'une infrastructure à grande échelle peut rapidement devenir insoutenable. Le système doit être aussi « autonome » que possible – s'auto-réparer et s'auto-adapter, plutôt que nos équipes d'astreinte ne gèrent directement chaque pile régionale – tout en offrant des interfaces simples aux utilisateurs.
- Avec la croissance des charges de travail serverless et d'IA chez Databricks, le taux de renouvellement de notre infrastructure a explosé, entraînant des augmentations rapides de la cardinalité des métriques. Nous ne pouvions plus traiter et stocker les données de surveillance à haute cardinalité comme nous l'avions toujours fait, mais nous visions toujours à maintenir les flux de travail de débogage sur lesquels les ingénieurs s'appuyaient.
Face à ces défis, l'ancienne pile de surveillance de Databricks était confrontée à des problèmes de fiabilité. Nous avons entrepris de développer une nouvelle plateforme fiable qui répondrait aux attentes de nos ingénieurs. Nous avons depuis résolu 3 problèmes clés :
- Concevoir une base de données de séries chronologiques (TSDB) fiable et efficace
- Introduire l'agrégation de métriques pour protéger les TSDB de la cardinalité
- Permettre un dépannage hautement dimensionnel avec le lakehouse Databricks
Bases de données de séries chronologiques Thanos
Que sont les TSDB ?
Les TSDB sont un composant essentiel des architectures de systèmes de surveillance traditionnels. Ces bases de données spécialisées sont conçues pour ingérer de grandes quantités de données de métriques de séries chronologiques et pour servir des lectures en temps réel à QPS élevé et à faible latence. Elles sont particulièrement optimales pour les modèles de requêtes de surveillance tels que les alertes et les actualisations de tableaux de bord, qui nécessitent d'émettre le même ensemble de requêtes de manière répétée et d'obtenir des résultats ultra-rapides basés sur les données les plus récentes.
Les anciennes TSDB de Databricks avaient été conçues pour une échelle d'un ordre de grandeur inférieur et sont devenues un goulot d'étranglement majeur pour nous ces dernières années. En fait, le problème de fiabilité n°1 pour l'ensemble de l'infrastructure de surveillance était la difficulté de faire évoluer nos TSDB. Il s'agit d'une opération peu fréquente pour de nombreuses autres entreprises, mais quelque chose que nous devions faire presque quotidiennement compte tenu de la croissance exponentielle de Databricks.
Nous avons donc développé une nouvelle TSDB, nommée Pantheon, qui est un fork du projet open source CNCF Thanos. Nous avons réussi à passer à plus de 160 instances de Thanos dans toutes les régions et chez trois fournisseurs de cloud, avec un total d'environ 5 milliards de séries chronologiques actives en mémoire et plus de 10 billions d'échantillons ingérés quotidiennement. Notre plus grande instance héberge environ 300 millions de séries chronologiques en mémoire et prend en charge près de 1 000 requêtes PromQL par seconde ; nous exécutons également de petits déploiements à 3 nœuds et tout ce qui se trouve entre les deux. En raison de l'étendue, de l'échelle et de la variété de nos déploiements, nous découvrons souvent des cas limites et des optimisations de performances de Thanos et les contribuons à la communauté open source.
La migration vers Pantheon nous a permis d'économiser des millions de dollars en coûts annuels de cloud, tout en réduisant les temps d'arrêt de l'infrastructure de surveillance d'environ 5 fois et en éliminant de nombreuses sources de travail manuel. L'architecture de Pantheon est présentée ci-dessous, et les sections suivantes expliquent plusieurs décisions de conception clés qui ont rendu ces réalisations possibles.
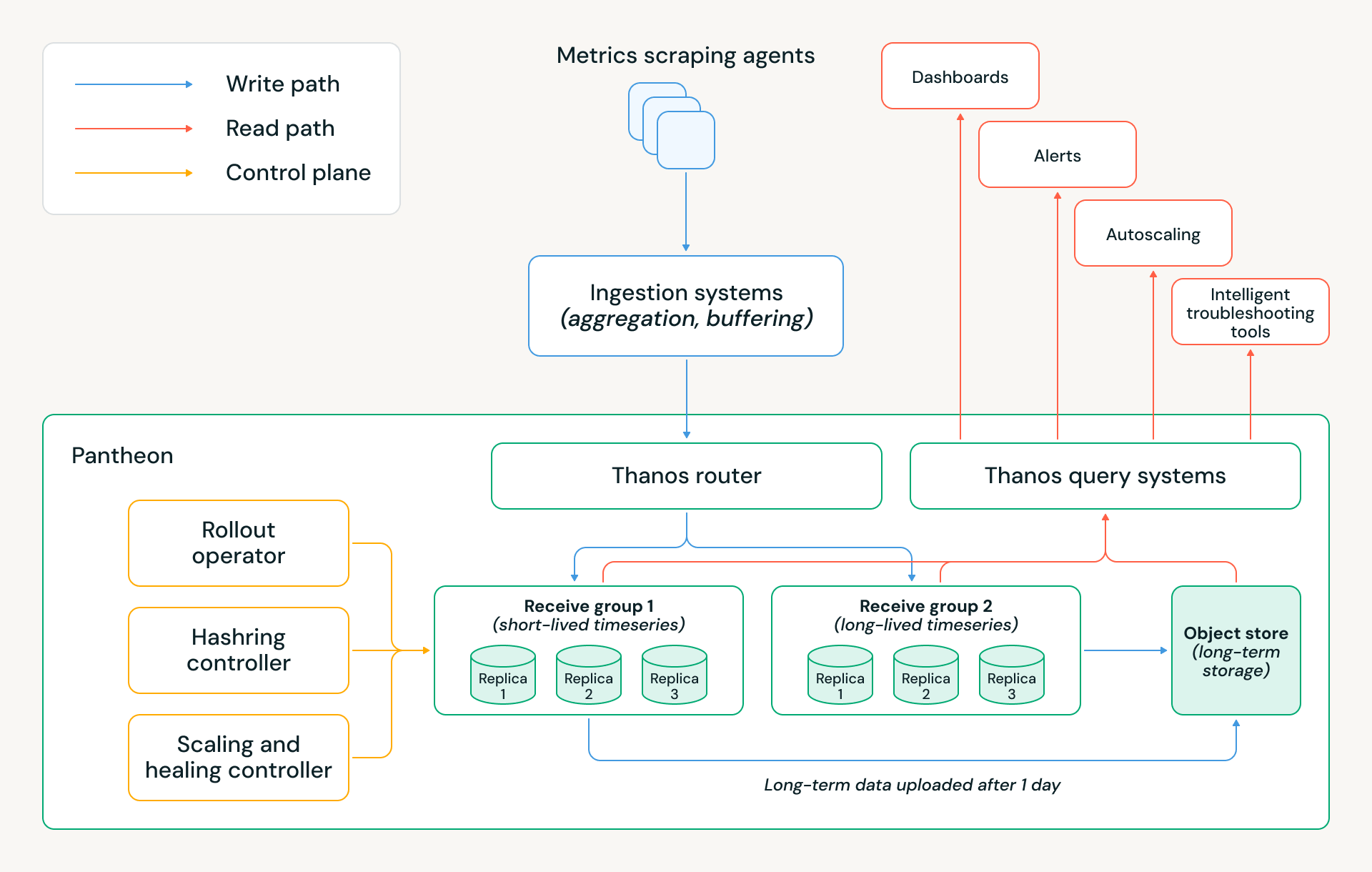
Architecture de stockage
Un élément clé de Thanos est son architecture de stockage hiérarchisé. Les séries chronologiques les plus récentes sont conservées en mémoire, celles des dernières 24 heures sont conservées sur disque, et toutes les données plus anciennes sont stockées sur un stockage objet. Cela signifie que les alertes et autres requêtes en temps réel peuvent répondre à des exigences de performance strictes, car elles dépendent généralement des données les plus récentes. En même temps, l'utilisation du stockage objet permet au système de découpler essentiellement le calcul du stockage ; un cluster peut évoluer sans avoir besoin de rééquilibrer toutes ses données historiques entre les nœuds de la base de données.
Cette architecture a résolu notre goulot d'étranglement clé (les montées en charge) et a jeté les bases des économies de coûts de Pantheon. Nous avons appliqué plusieurs autres optimisations :
- Rétention en mémoire : Nous déployons deux groupes de réception avec des politiques de rétention en mémoire distinctes : l'un optimisé pour les séries chronologiques de longue durée provenant de services persistants, conservant deux heures d'échantillons en mémoire, et l'autre optimisé pour les séries chronologiques de courte durée provenant des charges de travail éphémères de Databricks, ne conservant que 30 minutes de données en mémoire. Cette séparation reflète la durée de vie que nous avons observée pour les charges de travail serverless chez Databricks, et réduit considérablement l'empreinte mémoire et les coûts cloud tout en préservant l'exactitude.
- Structure du groupe de réception : Chaque groupe est intentionnellement implémenté comme trois StatefulSets Kubernetes isolés, correspondant à trois réplicas, au lieu d'un seul grand anneau de hachage. Cette conception préserve la réplication à trois voies avec des écritures de quorum, tout en offrant une isolation opérationnelle et des données plus forte. Cette configuration nous permet de déployer ou de redémarrer un StatefulSet entier en parallèle lors des versions ou des rotations de nœuds sans violer le quorum ni impacter la disponibilité en écriture, ce qui simplifie considérablement les opérations quotidiennes.
- Multitenance : Pantheon utilise la multitenance de Thanos pour héberger des ensembles de locataires disjoints à travers les groupes de réception. Au niveau du routeur, nous appliquons une attribution de locataire basée sur des règles, en déduisant le locataire pour chaque échantillon de données en inspectant le nom de la métrique et les étiquettes sélectionnées. Cela permet aux échantillons au sein du même lot d'écriture d'être acheminés vers différents locataires — et donc différents groupes de réception — sans nécessiter de modifications côté client en amont.
- Téléchargements au moins une fois : Pour optimiser davantage les coûts tout en préservant l'exactitude, seuls deux des trois StatefulSets téléchargent des blocs vers le stockage objet. Cela réduit le trafic de téléchargement redondant et les coûts de stockage cloud tout en maintenant les garanties de durabilité et de cohérence des données grâce à la réplication et à la sémantique de quorum.
Plan de contrôle de Pantheon
À notre échelle mondiale, les opérations manuelles, l'automatisation Kubernetes au meilleur effort ou les comportements de Thanos "vanilla" sont insuffisants. Chaque version, événement de mise à l'échelle ou défaillance d'hôte doit être géré de manière sûre, automatique et avec une intervention humaine minimale, tout en préservant le quorum et la disponibilité des données. Pour y parvenir, Pantheon introduit un plan de contrôle spécialement conçu, responsable de l'orchestration du cycle de vie et des décisions de capacité des composants Thanos. Il se compose de trois contrôleurs clés :
- Opérateur de déploiement (Rollout Operator) : Coordonne les versions et la mise à l'échelle sur trois StatefulSets de réception isolés, garantissant le quorum pour les lectures et les écritures. Il permet des versions plus rapides grâce à des mises à jour parallèles des StatefulSets, garantissant qu'au plus une réplique est indisponible à tout moment.
- Contrôleur d'anneau de hachage (Hashring Controller) : Gère les points de terminaison de réception visibles par le routeur. Seuls les pods sains et entièrement prêts sont ajoutés à l'anneau de hachage, et les suppressions sont mises en scène lors des réductions d'échelle ou de la maintenance. Cela découple la gestion du trafic du cycle de vie des pods et empêche les violations accidentelles de quorum ou le routage partiel lors des changements dynamiques de cluster.
- Contrôleur d'auto-mise à l'échelle et d'auto-réparation (Autoscaling and Self-Healing Controller) : Met à l'échelle les clusters en fonction de l'ingestion et de la pression des ressources spécifiques à Pantheon plutôt que des signaux Kubernetes génériques. Un système de réparation intégré détecte et corrige en continu les modes de défaillance courants — tels que les hôtes défectueux, les pods surchargés ou un WAL corrompu — permettant au système de s'auto-réparer sans intervention de l'opérateur. À notre échelle, ces automatisations se déclenchent des dizaines de fois par semaine.
Cardinalité et agrégation
Qu'est-ce que la cardinalité et pourquoi est-elle importante ?
Les propriétaires de métriques ajoutent souvent des étiquettes telles que l'ID de nœud ou l'ID de pod pour les aider à déboguer les problèmes sur des dimensions spécifiques et à atténuer les incidents plus rapidement. Cependant, cela conduit à un défi classique d'observabilité : la gestion de la cardinalité. La cardinalité d'une métrique est le nombre de combinaisons uniques de ses étiquettes. Si le nombre de pods que vous surveillez augmente de 10 fois, la cardinalité de toute métrique avec une étiquette d'ID de pod augmente également. La cardinalité est le principal facteur d'échelle pour une TSDB, et la croissance de la cardinalité des métriques existantes augmente les coûts et la pression de mise à l'échelle sur Pantheon.
La croissance rapide de l'infrastructure est un défi dont nous bénéficions chez Databricks. Alors que notre base de clients et l'utilisation de nos produits ont considérablement augmenté, de nombreux clients ont récemment adopté notre architecture de calcul sans serveur, et notre plateforme de calcul sans serveur lance des dizaines de millions de machines virtuelles chaque jour. À mesure que de plus en plus de charges de travail passent au sans serveur, l'infrastructure que nous surveillons devient plus volatile, et la durée de vie de ces étiquettes d'identifiant ne cesse de raccourcir.
Cela a entraîné une explosion de la cardinalité, réduisant les gains de scalabilité et de coût de Pantheon. Nous avons donc dû devenir beaucoup plus intelligents quant aux données de métriques que nous stockions. C'est là qu'est intervenue l'« agrégation » : la suppression des étiquettes coûteuses des systèmes sans serveur pendant l'ingestion, tout en offrant une vue agrégée de l'ensemble du parc aux propriétaires de services. Une stratégie d'agrégation automatisée pour les métriques nous a permis de « fléchir la courbe » de la croissance de la cardinalité, garantissant que l'infrastructure de surveillance n'a pas besoin de s'adapter plus rapidement que le reste de Databricks.
Architecture d'agrégation
Construire une infrastructure d'agrégation fiable à grande échelle est difficile car elle est stateful (avec état). Les agrégateurs gérant des millions de compteurs d'entrée doivent être capables de gérer correctement les réinitialisations – si une série chronologique d'entrée disparaît, la valeur de sortie agrégée doit continuer à augmenter de manière monotone plutôt que de chuter. Avec des métriques partitionnées entre les agrégateurs, vous devez également gérer des scénarios tels que les redémarrages de pods et le déséquilibre de charge.
Ces problèmes sont souvent résolus en utilisant un système de messagerie comme Kafka pour les attributions de partitionnement et le maintien des données précédentes ; cela est coûteux à notre échelle et ajoute un délai d'ingestion qui impacte les cas d'utilisation en temps réel. L'approche alternative consiste à stocker l'état en mémoire dans les agrégateurs et à rediriger les métriques entre les agrégateurs pour respecter l'attribution. Cependant, cela entraîne une perte de données lorsqu'un agrégateur est redéployé ; dans une version initiale de notre infrastructure d'agrégation, ce comportement rendait les métriques agrégées presque inintelligibles pour nos utilisateurs.
Pour que cela fonctionne de manière transparente, nous avons plutôt développé notre propre système d'agrégation en utilisant Telegraf et le service « auto-sharder » de Databricks, Dicer. Cette architecture utilise un routage intelligent et persistant au lieu de rediriger les métriques entre les agrégateurs, ce qui a résolu les modes de défaillance liés au redéploiement. Avec d'autres optimisations que nous avons ajoutées à Telegraf, nous avons pu faire évoluer le pipeline à plus de 1 Go/s dans notre plus grande région et des milliers de règles d'agrégation.
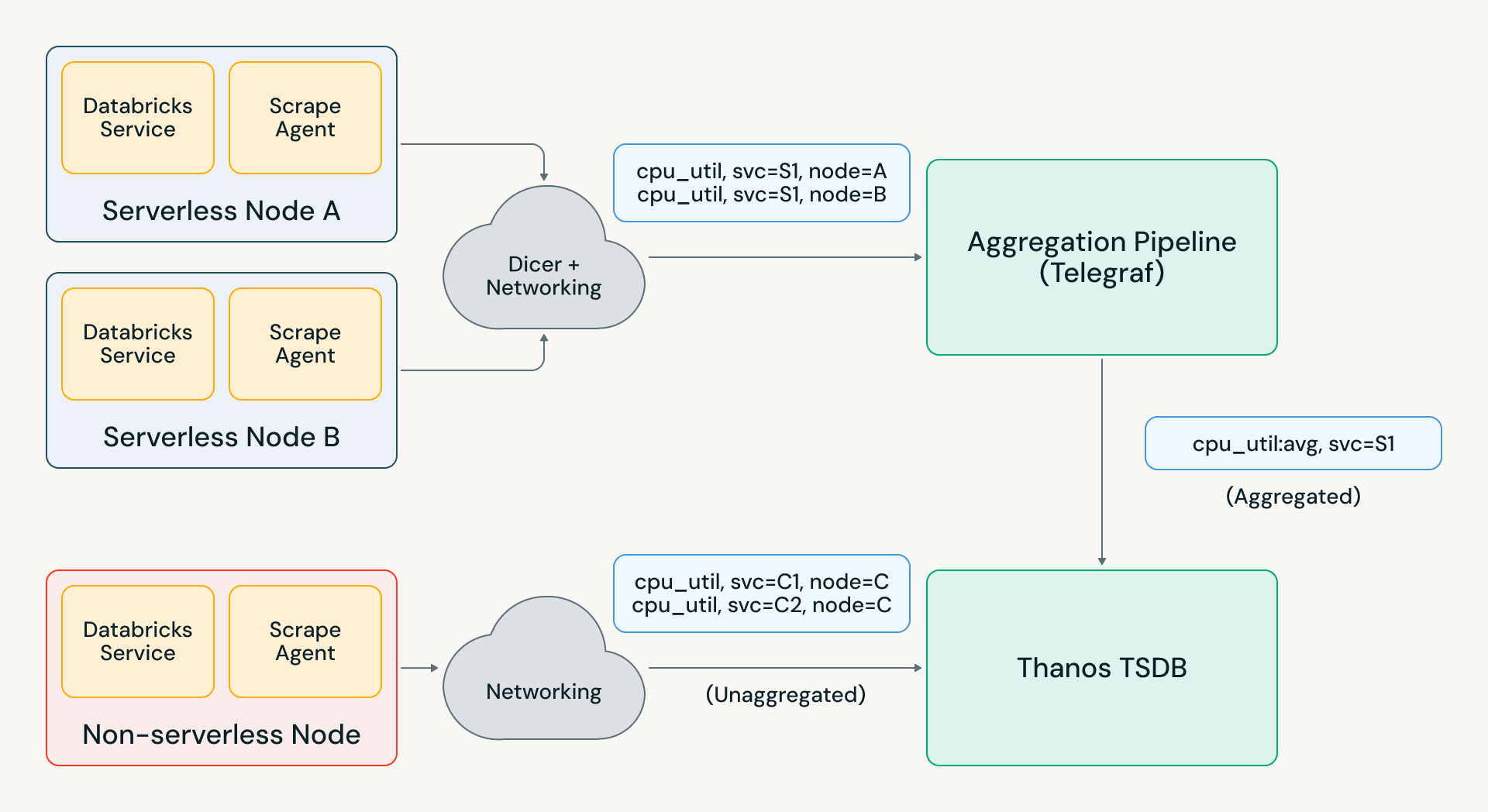
Ce nouveau pipeline d'agrégation est devenu le bouclier protégeant nos TSDB de la croissance de la cardinalité à long terme ainsi que des pics de métriques inattendus. Par exemple, un incident d'infrastructure récent chez Databricks a entraîné une augmentation de 2 à 5 fois de la charge des métriques dans diverses régions. Telegraf a absorbé la majeure partie de cette charge, et Pantheon n'a enregistré qu'une augmentation de 20 %, permettant aux ingénieurs de l'entreprise d'exécuter des requêtes de débogage et d'alerte sans aucun impact.
Données à haute cardinalité sur le lakehouse
Le problème de l'agrégation
Notre infrastructure d'agrégation nous permet de protéger Pantheon de la croissance exponentielle de la cardinalité, mais cela a un coût — elle supprime les dimensions exactes dont les ingénieurs ont besoin lors des incidents. Considérez un parc mondial avec :
- Des millions de nœuds actifs au cours des 2 dernières heures
- Plusieurs locataires par nœud
- Charges de travail de courte durée
- Mise à l'échelle automatique rapide
Les métriques agrégées vous indiquent :
- L'utilisation du CPU au niveau de la région est élevée
- La latence au niveau du service augmente fortement
Mais elles ne vous disent pas :
- Quel locataire est à l'origine de la pression d'échange
- Quel nœud a planté
- Quel shard est isolé
- Quelle charge de travail est bruyante
Les ingénieurs de Databricks avaient toujours besoin d'une solution pour les workflows de dépannage qui reposaient sur ces étiquettes à haute cardinalité. Ces scénarios de « recherche d'une aiguille dans une botte de foin » nécessitaient le stockage et le traitement efficaces de quantités massives de données brutes, ce que Pantheon ne pouvait pas faire. Pour prendre en charge ces cas d'utilisation, nous avons recherché une architecture de stockage différente qui ne serait pas limitée par la croissance de la cardinalité.
Place au lakehouse !
Notre idée clé : le lakehouse Databricks est parfaitement adapté ! Il découple le stockage (stockage d'objets bon marché + Delta Lake) du calcul (streaming + clusters de requêtes) et est massivement scalable sur les deux dimensions.
En utilisant les meilleures capacités de Databricks, nous avons développé une nouvelle plateforme pour les données brutes de dépannage appelée Hydra, qui a rendu le débogage à haute cardinalité pratique à grande échelle. Hydra ingère 20 milliards de séries chronologiques actives non agrégées provenant de millions de nœuds dans le monde, tout en atteignant une fraîcheur des données de bout en bout de 5 minutes et un stockage de données 50 fois moins cher que Thanos.
Ces succès ont été rendus possibles par la conception native du lakehouse d'Hydra :

- Nous utilisons Apache Spark™ Structured Streaming sur Databricks pour exécuter des tâches d'ingestion continues qui traitent les données de métriques de manière incrémentielle à mesure qu'elles arrivent, en les écrivant dans Delta Lake. Structured Streaming vous permet d'exprimer des calculs de streaming de la même manière que vous écrivez des tâches par lots, mais avec un traitement continu, incrémentiel et une sémantique exactement une fois pour une ingestion fiable.
- Pour découvrir et ingérer efficacement des millions de fichiers de stockage d'objets, nous tirons parti de Databricks Auto Loader, une source Structured Streaming à haut débit qui suit et traite de manière incrémentielle les nouveaux fichiers sans nécessiter de listage manuel ou de gestion d'état. Auto Loader persiste automatiquement les métadonnées sur les fichiers découverts et s'adapte pour gérer les modèles d'arrivée quasi en temps réel.
- Nous partitionnons également l'ingestion par région, en déployant des tâches de streaming indépendantes à travers les zones géographiques. Cela permet à chaque pipeline de s'adapter automatiquement de manière indépendante, minimise la latence interrégionale et réduit le rayon d'impact en cas de défaillance. Ensemble, ces choix de conception permettent aux données de métriques brutes d'être interrogeables en quelques minutes après leur émission, même à un volume de plusieurs milliards de séries, tout en maintenant les systèmes de tableau de bord performants.
Unification des interfaces
Construire Hydra n'était pas seulement un défi d'infrastructure ; c'était un défi de conception d'interface. Dès le début, nous avons conçu Hydra autour des parcours utilisateurs critiques (CUJ) pour nos ingénieurs plutôt qu'autour des couches de stockage ou des pipelines d'ingestion. Notre objectif était simple : les ingénieurs devraient pouvoir travailler avec des métriques à haute cardinalité en utilisant les mêmes interfaces sur lesquelles ils s'appuient déjà.
Interrogation via Grafana
La plupart des ingénieurs commencent leur workflow de débogage dans Grafana. Ils s'attendent à écrire du PromQL, à utiliser des tableaux de bord existants, à explorer les étiquettes et à pivoter rapidement lors des incidents.
Pour préserver ce workflow, Hydra s'intègre directement à Grafana en permettant l'exécution de requêtes PromQL sur les données stockées dans Databricks. Nous avons construit une couche de conversion PromQL-vers-SQL qui traduit les expressions PromQL en requêtes SQL exécutées sur des tables Delta dans le Lakehouse. Cette approche permet aux ingénieurs de continuer à utiliser la syntaxe et les tableaux de bord PromQL familiers sans modification. En même temps, les requêtes sous-jacentes sont exécutées sur des tables Delta à grande échelle plutôt que sur une TSDB en mémoire.
Accès SQL direct dans Databricks
Bien que Grafana soit idéal pour le débogage en direct, certaines investigations nécessitent une analyse plus approfondie. Les ingénieurs peuvent avoir besoin de joindre des métriques avec des métadonnées de déploiement, de corréler des métriques avec des journaux, d'exécuter des analyses sur de larges plages de temps, d'effectuer une détection d'anomalies ou d'exporter des ensembles de données pour des analyses avancées.
Hydra expose également directement les tables Delta sous-jacentes au sein de Databricks. Les ingénieurs peuvent interroger ces tables à l'aide de Databricks SQL ou de notebooks, permettant une analyse flexible qui va au-delà des workflows de surveillance traditionnels.
Parce que les données résident dans le Lakehouse, elles peuvent être jointes à d'autres jeux de données d'entreprise et sont régies par les mêmes contrôles de sécurité et d'accès. Cela transforme les données d'observabilité en un actif analytique de premier ordre plutôt qu'en un silo de surveillance isolé.
Sémantique unifiée des métriques
Un principe de conception clé de Hydra est que les ingénieurs ne devraient pas avoir besoin de comprendre notre architecture d'ingestion. Qu'une métrique soit accédée via le chemin agrégé supporté par TSDB, ou le chemin de métrique brute supporté par le Lakehouse, l'interface reste cohérente.
Les noms de métriques, la sémantique des étiquettes et les dimensions des métadonn�ées sont unifiés dans tous les environnements. Les équipes de service émettent des métriques une seule fois en utilisant une interface standardisée. La plateforme gère l'agrégation, la préservation des données brutes, l'ingestion, le stockage et le routage des requêtes. Ce modèle unifié réduit la charge cognitive et élimine le besoin pour les équipes de gérer des configurations distinctes pour différents backends d'observabilité.
À l'avenir, nous cherchons à améliorer les performances de Hydra afin qu'il atteigne une fraîcheur des données similaire à celle de Pantheon et que les deux expériences convergent encore davantage.
Points clés
Pour faire évoluer l'infrastructure de surveillance de Databricks, nous avons dû optimiser la fiabilité, l'efficacité, l'opérabilité et les parcours des développeurs. Pour nous, « l'évolution » a signifié plus que simplement augmenter la taille de nos déploiements. Cela a signifié :
- Intégrer la résilience et l'automatisation à notre architecture fondamentale, pour parvenir à des opérations « sans intervention » pour ces systèmes globaux et en constante évolution
- Repenser à partir des principes fondamentaux le type de systèmes nécessaires pour divers cas d'utilisation de la surveillance, de l'alerte au dépannage en passant par l'analyse à travers les sources de données
- Faire évoluer notre architecture à mesure que le reste de l'infrastructure de Databricks s'est transformé à nos côtés
Ce seront des parcours sans fin pour nous, et ils illustrent pourquoi l'ingénierie d'infrastructure est un domaine si dynamique chez Databricks. Si vous aimez résoudre des problèmes d'ingénierie complexes et souhaitez vous joindre à nous pour l'aventure, consultez databricks.com/careers !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.