Application de votre réseau de neurones convolutif : webinaire à la demande et FAQ maintenant disponibles !
par Denny Lee et Cyrielle Simeone
Essayez ce notebook dans Databricks
Le 25 octobre, nous avons organisé un webinar en direct —Application de votre réseau neuronal convolutif— avec Denny Lee, Technical produit Marketing Manager chez Databricks. Il s'agit du troisième webinar d'une série gratuite sur les fondamentaux du deep learning proposée par Databricks.

Dans ce webinar, nous avons exploré en profondeur les réseaux de neurones convolutifs (CNN), un type particulier de réseau de neurones qui part du principe que les entrées sont des images et qui s'est avéré très efficace pour la classification d'images et la reconnaissance d'objets.
Nous avons notamment abordé :
- Architecture CNN, avec des nœuds disposés en 3D avec une largeur, une hauteur et une profondeur, permettant d'appliquer des filtres convolutifs pour extraire des caractéristiques.
- Fonctionnement des noyaux de convolution (filtres), y compris comment choisir la taille des filtres, les strides et le padding pour extraire des caractéristiques de régions de pixels dans vos images d'entrée.
- Techniques de pooling (ou de sous-échantillonnage) pour réduire la taille de l'image, diminuant ainsi le nombre de paramètres et le risque de surapprentissage.
Nous avons démontré certains de ces concepts en utilisant Keras (backend TensorFlow) sur Databricks. Voici un lien vers notre Notebook pour commencer dès aujourd'hui :
Vous pouvez toujours regarder la partie 1 et la partie 2 ci-dessous :


Si vous souhaitez un accès gratuit à la plateforme d'analyse unifiée Databricks et y essayer nos Notebooks, vous pouvez démarrer un Essai gratuit ici.
Pour conclure, nous avons tenu une séance de questions-réponses, dont vous trouverez ci-dessous les questions et leurs réponses, regroupées par thème.
Fondamentaux
Q : Ai-je vraiment besoin de comprendre les mathématiques derrière les réseaux de neurones pour les utiliser ?
Bien qu'il ne soit pas absolument nécessaire de comprendre les mathématiques qui sous-tendent les réseaux de neurones pour les utiliser, il est important de comprendre ces principes fondamentaux pour choisir les bons algorithmes et pour savoir comment optimiser, améliorer et architecturer vos modèles de deep learning (et de modèles de machine learning). L'article de Wale Akinfaderin « The Mathematics of Machine Learning » est un bon article sur ce sujet.
Réseau de neurones convolutif
Q : Pourquoi utiliser des CNN plutôt que des réseaux de neurones classiques ? Et comment utilisez-vous les CNN dans la vie réelle, pouvez-vous nous donner des exemples d'applications ?
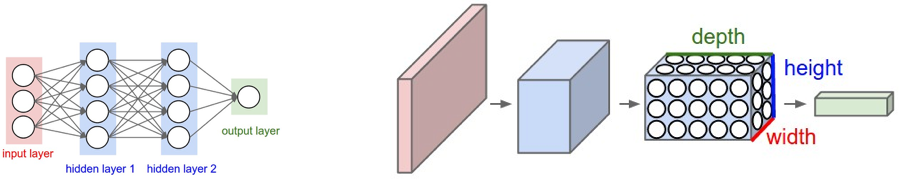
Source : https://cs231n.github.io/convolutional-networks/
Comme expliqué plus en détail dans l'entraînement des réseaux de neurones, les réseaux de neurones convolutifs (CNN) sont similaires aux réseaux de neurones artificiels classiques, mais les premiers partent du principe explicite que les entrées sont des images. Le problème, c'est que les réseaux de neurones artificiels entièrement connectés (comme le montre le graphique de gauche) ne montent pas bien en charge face aux images. Par exemple, 200 pixels x 200 pixels x 3 canaux de couleur (par ex. RGB) donnerait 120 000 poids. Plus l'image est grande ou complexe (au niveau des canaux), plus le nombre de poids requis est élevé. Dans le cas des CNN, les nœuds sont uniquement connectés à une petite région de la couche précédente organisée en 3D (largeur, hauteur, profondeur). Comme les nœuds ne sont pas entièrement connectés, cela réduit le nombre de poids (c.-à-d. cardinalité) permettant ainsi au réseau d'effectuer ses passes plus rapidement.
Q : Un CNN est un réseau de couches, définies par leur taille et leur type. Comment les choisir ? Sur quelle base ? En d'autres termes, comment concevoir mon architecture ?
Comme indiqué dans Introduction aux réseaux de neurones : webinar à la demande et FAQ maintenant disponibles, bien qu'il existe des règles générales sur votre point de départ (par ex. start par une couche cachée et développez en conséquence, le nombre de nœuds d'entrée est égal à la dimension des caractéristiques, etc.), l'essentiel est que vous devrez effectuer des tests. C'est-à-dire, entraînez votre modèle, puis exécutez les tests et/ou les validations sur ce modèle pour comprendre la précision (plus elle est élevée, mieux c'est) et la perte (plus elle est faible, mieux c'est). Pour la conception de votre architecture, il est préférable de commencer par les architectures les mieux comprises et étudiées (par ex. AlexNet, LeNet-5, Inception, VGG, ResNet, etc.). À partir de là, vous pouvez ajuster le nombre, la taille et le type de couches au fur et à mesure que vous réalisez vos expérimentations.
Q : Pourquoi utiliser la fonction softmax pour la couche entièrement connectée ?
Lorsque nous travaillons avec la régression logistique, cela présuppose une distribution de Bernoulli pour notre classification binaire. Quand on a affaire à plus de deux classifieurs (comme notre problème de classification MNIST), on a besoin de la généralisation de la distribution de Bernoulli qui est une distribution multinomiale. Le type de régression qui est appliqué à une distribution multinomiale (multi-classificateur) est connu sous le nom de régression softmax. Pour MNIST, nous classifions des chiffres manuscrits pour une valeur comprise entre 0, ..., 9 au niveau de la couche entièrement connectée, d'où l'utilisation de softmax.
Q : La taille du filtre est-elle toujours un nombre impair ?
Une approche courante pour la taille du filtre est f x f où f est un nombre impair. Bien que cela ne soit pas explicitement mentionné, à la diapositive 39 de Applying réseaux de neurones, f est un nombre impair car l'objectif est de convoluer le pixel source et ses pixels environnants. Le strict minimum serait une taille de filtre de 3 x 3, car cela correspondrait au pixel source plus 1 pixel dans un espace 2D.

Le fait d'avoir une taille f paire aurait pour conséquence de convoluer moins de la moitié des pixels autour du pixel source. Pour aller plus loin, vous trouverez une bonne réponse SO à cette question à l'adresse https://datascience.stackexchange.com/questions/23183/why-convolutions-always-use-odd-numbers-as-filter-size/23186.
Q : Comment puis-je implémenter un CNN avec une longueur d'entrée variable ? Autrement dit, avez-vous des suggestions pour des données d'entraînement qui contiennent des images de tailles variables ?
En général, vous devrez redimensionner vos images ou leur appliquer un remplissage par zéros afin que toutes les images d'entrée de votre CNN aient la même taille. Il existe des approches basées sur les LSTM, les RNN ou les réseaux de neurones récursifs (en particulier pour les données textuelles) qui peuvent traiter des entrées de taille variable, mais notez qu'il s'agit souvent d'une tâche non triviale.
Environnement ML & Ressources
Q : Je suis un utilisateur payant de Databricks. Je sais comment exécuter Keras sur mon propre PC, mais pas encore dans Databricks.
Lorsque vous utilisez Databricks, lancez un cluster Databricks Runtime for Machine Learning qui inclut notamment Keras, TensorFlow, XGBoost, Horovod et scikit-learn. Pour plus d'informations, consultez Announcing Databricks Runtime for Machine Learning.
Q : Avons-nous eu une session similaire pour le ML ?
De nombreux webinaires Databricks de qualité sont disponibles ; ceux qui portent sur le Machine Learning incluent, sans s'y limiter :
- Présentation de MLflow : une infrastructure pour le cycle de vie complet du machine learning
- Paralléliser le code R à l'aide d'Apache® Spark
- Mise en production de modèles MLlib Apache Spark™ pour le service de prédictions en temps réel
- Comment Databricks et le Machine Learning propulsent l'avenir de la génomique
- GraphFrames : Graphes basés sur les DataFrames pour Apache® Spark™
- Apache Spark MLlib : Initiation et Scikit-Learn
Ressources
- Machine Learning 101
- Démo ConvNetJS MNIST d'Andrej Karparthy
- Qu'est-ce que la rétropropagation dans les réseaux de neurones ?
- CS231n : Réseaux de Neurones Convolutifs pour la Reconnaissance Visuelle
- Avec un accent particulier sur CS231n : Cours 7 : Réseaux de neurones convolutifs
- Réseaux de neurones et apprentissage profond
- TensorFlow
- Boîte à outils de visualisation profonde
- Rétropropagation avec TensorFlow
- TensorFrames : Google TensorFlow avec Apache Spark
- Intégrer les bibliothèques de deep learning avec Apache Spark
- Créez, montez en charge et déployez facilement des pipelines de Deep Learning
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.