Traitement des données géospatiales à grande échelle avec Databricks
par Nima Razavi et Michael Johns
Ce billet de blog est obsolète. Veuillez consulter ce billet de blog sur Spatial SQL pour des approches à jour sur le stockage et le traitement des données géospatiales au sein de votre Databricks Lakehouse.
L'évolution et la convergence de la technologie ont alimenté un marché dynamique pour des données géospatiales précises et opportunes. Chaque jour, des milliards d'appareils portables et IoT, ainsi que des milliers de plateformes de télédétection aéroportées et satellitaires, génèrent des centaines d'exaoctets de données géolocalisées. Ce boom des big data géospatiales, combiné aux avancées du machine learning, permet aux organisations de tous secteurs de créer de nouveaux produits et capacités.
Par exemple, de nombreuses entreprises fournissent des services localisés basés sur des drones tels que la cartographie et l'inspection de sites (référence Développement pour le cloud intelligent et le edge intelligent). Une autre industrie en croissance rapide pour les données géospatiales est celle des véhicules autonomes. Les startups et les entreprises établies amassent de vastes corpus de données géospatiales hautement contextualisées provenant de capteurs de véhicules pour offrir la prochaine innovation en matière de voitures autonomes (référence Databricks alimente l'ambition de wejo de créer un écosystème de données de mobilité). Les détaillants et les agences gouvernementales cherchent également à exploiter leurs données géospatiales. Par exemple, l'analyse du trafic piétonnier (référence Création d'un jeu de données d'informations sur le trafic piétonnier) peut aider à déterminer le meilleur emplacement pour ouvrir un nouveau magasin ou, dans le secteur public, à améliorer la planification urbaine. Malgré tous ces investissements dans les données géospatiales, un certain nombre de défis subsistent.
Défis de l'analyse géospatiale à grande échelle
Le premier défi consiste à gérer l'échelle dans les applications de streaming et par lots. La prolifération massive de données géospatiales et les SLA requis par les applications submergent les systèmes de stockage et de traitement traditionnels. Les données clients débordent depuis de nombreuses années des bases de données géographiques existantes à échelle verticale vers les data lakes en raison de pressions telles que le volume des données, la vélocité, le coût de stockage et l'application stricte du schéma à l'écriture. Bien que les entreprises aient investi dans les données géospatiales, peu disposent de l'architecture technologique appropriée pour préparer ces grands ensembles de données complexes pour l'analyse en aval. De plus, étant donné que les données à grande échelle sont souvent nécessaires pour des cas d'utilisation avancés, la majorité des initiatives pilotées par l'IA échouent à passer du pilote à la production.
La compatibilité avec divers formats spatiaux constitue le deuxième défi. Il existe de nombreux formats géospatiaux spécialisés, établis au fil des décennies, ainsi que des sources de données incidentelles à partir desquelles des informations de localisation peuvent être collectées :
- Formats vectoriels tels que GeoJSON, KML, Shapefile et WKT
- Formats raster tels que ESRI Grid, GeoTIFF, JPEG 2000 et NITF
- Normes de navigation telles qu'utilisées par les appareils AIS et GPS
- Bases de données géographiques accessibles via des connexions JDBC / ODBC telles que PostgreSQL / PostGIS
- Formats de capteurs distants provenant de plateformes hyperspectrales, multispectrales, Lidar et Radar
- Normes Web OGC telles que WCS, WFS, WMS et WMTS
- Journaux géolocalisés, photos, vidéos et médias sociaux
- Données non structurées avec des références de localisation
Dans ce billet de blog, nous donnons un aperçu des approches générales pour traiter les deux principaux défis mentionnés ci-dessus en utilisant la plateforme d'analyse de données unifiée de Databricks. C'est la première partie d'une série de billets de blog sur le traitement de grands volumes de données géospatiales.
Mise à l'échelle des charges de travail géospatiales avec Databricks
Databricks offre une plateforme d'analyse de données unifiée pour le big data analytics et le machine learning, utilisée par des milliers de clients dans le monde. Elle est alimentée par Apache Spark™, Delta Lake et MLflow, avec un large écosystème d'intégrations de bibliothèques tierces et disponibles. Databricks UDAP offre une sécurité, un support, une fiabilité et des performances de niveau entreprise à grande échelle pour les charges de travail de production. Les charges de travail géospatiales sont généralement complexes et il n'existe pas de bibliothèque unique adaptée à tous les cas d'utilisation. Bien qu'Apache Spark n'offre pas nativement de Types de données spatiaux, la communauté open source ainsi que les entreprises ont déployé de nombreux efforts pour développer des bibliothèques spatiales, résultant en une multitude d'options parmi lesquelles choisir.
Il existe généralement trois modèles pour mettre à l'échelle les opérations géospatiales telles que les jointures spatiales ou les voisins les plus proches :
- Utilisation de bibliothèques dédiées qui étendent Apache Spark pour l'analyse géospatiale. GeoSpark, GeoMesa, GeoTrellis et Rasterframes sont quelques-unes de ces bibliothèques utilisées par nos clients. Ces frameworks offrent souvent plusieurs liaisons linguistiques, ont une bien meilleure mise à l'échelle et performance que les approches non formalisées, mais peuvent également présenter une courbe d'apprentissage.
- Encapsulation de bibliothèques mono-nœud telles que GeoPandas, Geospatial Data Abstraction Library (GDAL) ou Java Topology Service (JTS) dans des fonctions définies par l'utilisateur (UDF) ad hoc pour le traitement de manière distribuée avec des DataFrames Spark. C'est l'approche la plus simple pour mettre à l'échelle les charges de travail existantes sans réécrire beaucoup de code ; cependant, elle peut introduire des inconvénients en termes de performance car elle est davantage de type « lift-and-shift ».
- Indexation des données avec des systèmes de grille et exploitation de l'index généré pour effectuer des opérations spatiales est une approche courante pour traiter des charges de travail à très grande échelle ou à ressources limitées. S2, GeoHex et H3 d'Uber sont des exemples de tels systèmes de grille. Les grilles approximent les entités géographiques telles que les polygones ou les points avec un ensemble fixe de cellules identifiables, évitant ainsi les opérations géospatiales coûteuses et offrant ainsi un comportement de mise à l'échelle beaucoup plus performant. Les implémenteurs peuvent choisir entre des grilles fixes à une seule précision, qui peuvent être quelque peu imprécises mais plus performantes, ou des grilles à plusieurs précisions, qui peuvent être moins performantes mais atténuent l'imprécision.
Les exemples suivants sont généralement orientés autour d'un jeu de données de prise en charge / dépose de taxi de New York, que l'on trouve ici. Les données des zones de taxi de New York avec leurs géométries seront également utilisées comme ensemble de polygones. Ces données contiennent des polygones pour les cinq arrondissements de New York ainsi que les quartiers. Ce notebook vous guidera à travers les préparations et les nettoyages effectués pour convertir les fichiers CSV initiaux en Delta Lake Tables, une source de données fiable et performante.
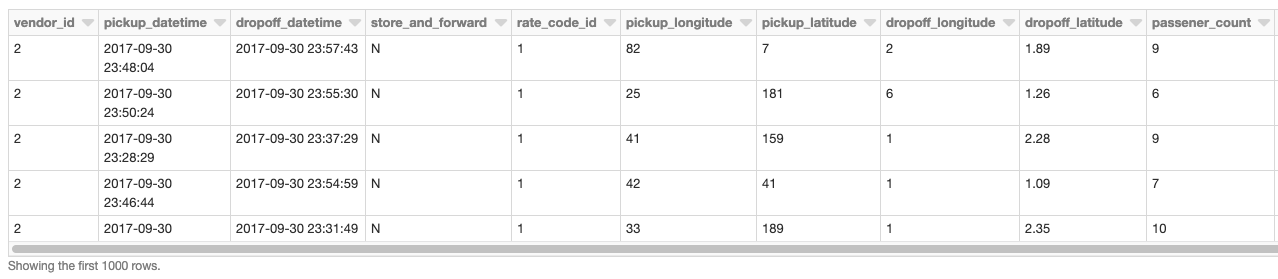
Notre DataFrame de base est constitué des données de prise en charge / dépose de taxi lues à partir d'une Delta Lake Table à l'aide de Databricks.
Opérations géospatiales à l'aide de bibliothèques géospatiales pour Apache Spark
Au cours des dernières années, plusieurs bibliothèques ont été développées pour étendre les capacités d'Apache Spark pour l'analyse géospatiale. Ces frameworks se chargent d'enregistrer les types définis par l'utilisateur (UDT) et les fonctions définies par l'utilisateur (UDF) couramment appliqués de manière cohérente, allégeant ainsi le fardeau qui pèse sur les utilisateurs et les équipes pour écrire une logique spatiale ad hoc. Veuillez noter que dans cet article de blog, nous utilisons plusieurs frameworks spatiaux différents choisis pour mettre en évidence diverses capacités. Nous comprenons qu'il existe d'autres frameworks au-delà de ceux mis en évidence que vous pourriez également vouloir utiliser avec Databricks pour traiter vos charges de travail spatiales.
Auparavant, nous avions chargé nos données de base dans un DataFrame. Nous devons maintenant transformer les attributs de latitude/longitude en géométries de points. Pour ce faire, nous utiliserons des UDF pour effectuer des opérations sur les DataFrames de manière distribuée. Veuillez vous référer aux notebooks fournis à la fin du blog pour plus de détails sur l'ajout de ces frameworks à un cluster et les appels d'initialisation pour enregistrer les UDF et les UDT. Pour commencer, nous avons ajouté GeoMesa à notre cluster, un framework particulièrement apte à gérer les données vectorielles. Pour l'ingestion, nous tirons parti de son intégration de JTS avec Spark SQL, ce qui nous permet de convertir et d'utiliser facilement les classes de géométrie JTS enregistrées. Nous utiliserons la fonction st_makePoint qui, étant donné une latitude et une longitude, crée un objet de géométrie Point. Comme la fonction est une UDF, nous pouvons l'appliquer directement aux colonnes.
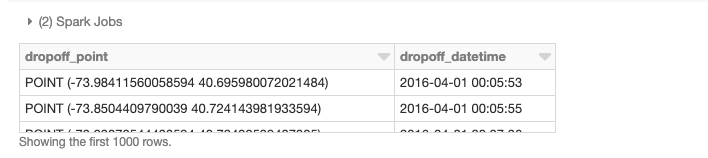
Nous pouvons également effectuer des jointures spatiales distribuées, dans ce cas en utilisant l'UDF st_contains fournie par GeoMesa pour produire la jointure résultante de tous les polygones par rapport aux points de prise en charge.
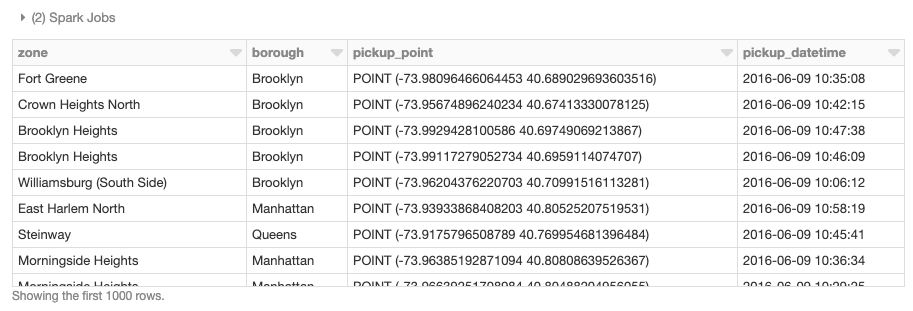
Encapsulation de bibliothèques mono-nœud dans des UDF
En plus d'utiliser des frameworks spatiaux distribués spécialement conçus, les bibliothèques mono-nœud existantes peuvent également être encapsulées dans des UDF ad hoc pour effectuer des opérations géospatiales sur des DataFrames de manière distribuée. Ce modèle est disponible pour toutes les liaisons linguistiques Spark – Scala, Java, Python, R et SQL – et constitue une approche simple pour tirer parti des charges de travail existantes avec des modifications minimales du code. Pour démontrer un exemple mono-nœud, chargeons les données des arrondissements de New York et définissons l'UDF find_borough(...) pour l'opération point dans le polygone afin d'attribuer chaque emplacement GPS à un arrondissement en utilisant geopandas. Cela aurait également pu être accompli avec une UDF vectorisée pour des performances encore meilleures.
Nous pouvons maintenant appliquer l'UDF pour ajouter une colonne à notre DataFrame Spark qui attribue un nom d'arrondissement à chaque point de prise en charge.
Systèmes de grille pour l'indexation spatiale
Les opérations géospatiales sont intrinsèquement coûteuses en calcul. Point dans le polygone, jointures spatiales, plus proche voisin ou accrochage aux routes impliquent tous des opérations complexes. En indexant avec des systèmes de grille, l'objectif est d'éviter complètement les opérations géospatiales. Cette approche conduit aux implémentations les plus évolutives avec la mise en garde d'opérations approximatives. Voici un bref exemple avec H3.
La mise à l'échelle des opérations spatiales avec H3 est essentiellement un processus en deux étapes. La première étape consiste à calculer un index H3 pour chaque caractéristique (points, polygones, …) définie comme UDF geoToH3(...). La deuxième étape consiste à utiliser ces index pour des opérations spatiales telles que la jointure spatiale (point dans le polygone, k plus proches voisins, etc.), dans ce cas définie comme UDF multiPolygonToH3(...).
Nous pouvons maintenant appliquer ces deux UDF aux données de taxi de New York ainsi qu'à l'ensemble des polygones des arrondissements pour générer l'index H3.
Étant donné un ensemble de points lat/lon et un ensemble de géométries de polygones, il est maintenant possible d'effectuer la jointure spatiale en utilisant le champ h3index comme condition de jointure. Ces affectations peuvent être utilisées pour agréger le nombre de points qui tombent dans chaque polygone, par exemple. Il y a généralement des millions ou des milliards de points qui doivent être mis en correspondance avec des milliers ou des millions de polygones, ce qui nécessite une approche évolutive. Il existe d'autres techniques non couvertes dans ce blog qui peuvent être utilisées pour l'indexation à l'appui des opérations spatiales lorsqu'une approximation est insuffisante.

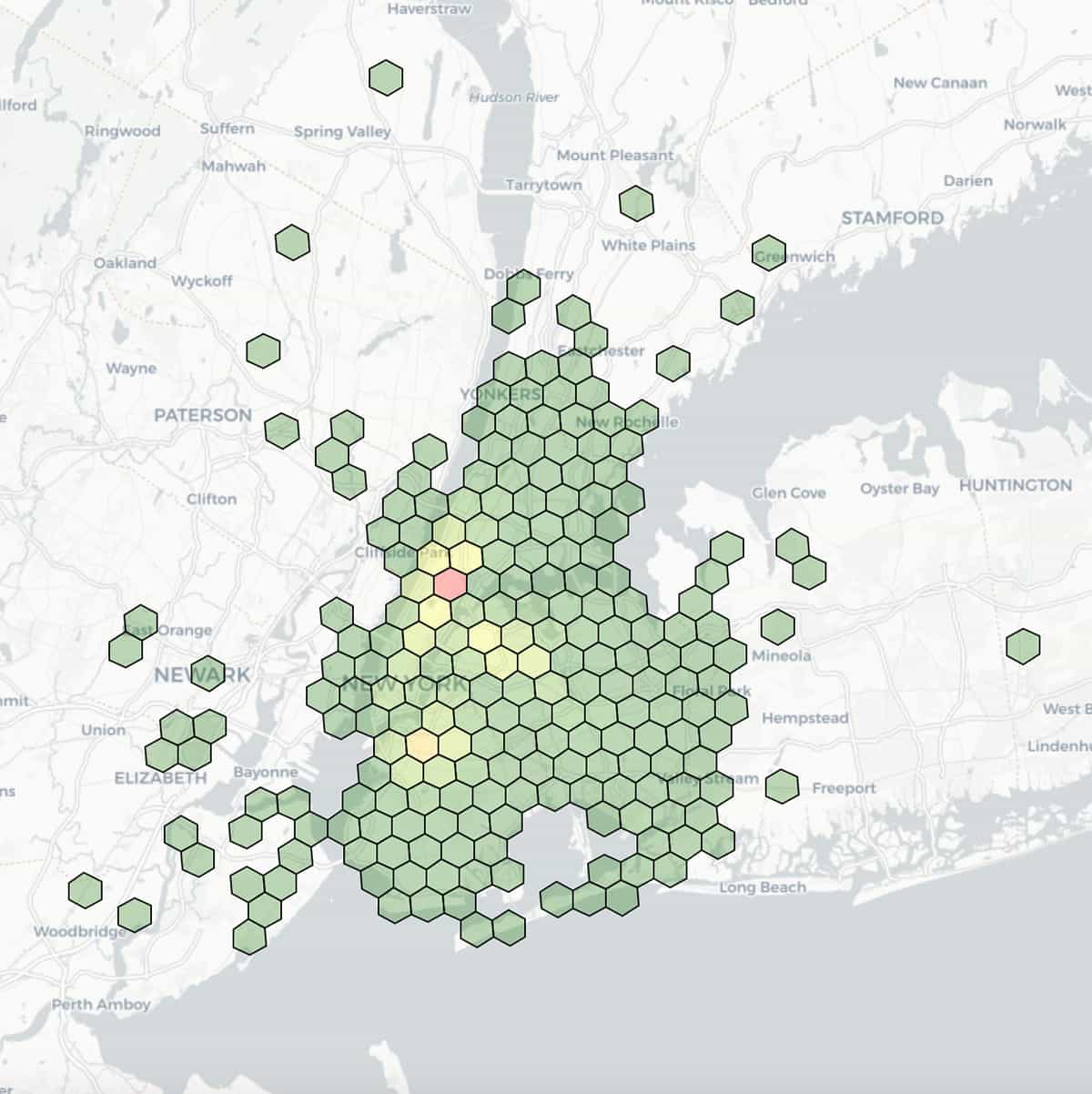
Voici une visualisation des lieux de dépose des taxis, avec la latitude et la longitude regroupées en cellules d'une résolution de 7 (longueur de côté de 1,22 km) et colorées par les dénombrements agrégés dans chaque cellule.
Gestion des formats spatiaux avec Databricks
Les données géospatiales impliquent des points de référence, tels que la latitude et la longitude, vers des emplacements physiques ou des étendues sur la Terre, ainsi que des entités décrites par des attributs. Bien qu'il existe de nombreux formats de fichiers parmi lesquels choisir, nous avons sélectionné une poignée de formats vectoriels et raster représentatifs pour démontrer la lecture avec Databricks.
Données vectorielles
Les données vectorielles sont une représentation du monde stockée sous forme de coordonnées x (longitude), y (latitude) en degrés, et éventuellement z (altitude en mètres) si l'élévation est prise en compte. Les trois types de symboles de base pour les données vectorielles sont les points, les lignes et les polygones. Well-known-text (WKT), GeoJSON et Shapefile sont quelques formats populaires pour stocker des données vectorielles que nous mettons en évidence ci-dessous.
Lisons les données des taxis de NYC avec des géométries stockées en WKT. La structure de données que nous voulons obtenir est un DataFrame, ce qui nous permettra de nous standardiser avec d'autres API et sources de données disponibles, comme celles utilisées ailleurs dans le blog. Nous pouvons facilement convertir le contenu texte WKT trouvé dans le champ the_geom en sa classe JTS Geometry correspondante via l'appel UDF st_geomFromWKT(...).
GeoJSON est utilisé par de nombreux packages SIG open source pour encoder une variété de structures de données géographiques, y compris leurs entités, propriétés et étendues spatiales. Pour cet exemple, nous allons lire les limites des arrondissements de NYC avec l'approche adoptée en fonction du flux de travail. Étant donné que les données sont conformes au format JSON, nous pourrions utiliser le lecteur JSON intégré de Databricks avec .option("multiline","true") pour charger les données avec le schéma imbriqué.

À partir de là, nous pourrions choisir d'extraire certains des champs vers des colonnes de premier niveau en utilisant la fonction explode intégrée de Spark. Par exemple, nous pourrions vouloir remonter la géométrie, les propriétés et le type, puis convertir la géométrie en sa classe JTS correspondante, comme montré dans l'exemple WKT.

Nous pouvons également visualiser les données des taxis de NYC dans un notebook en utilisant un DataFrame existant ou en rendant directement les données avec une bibliothèque telle que Folium, une bibliothèque Python pour le rendu de données spatiales. Le Databricks File System (DBFS) fonctionne sur une couche de stockage distribuée qui permet au code de travailler avec des formats de données en utilisant des normes de système de fichiers familières. DBFS dispose d'un montage FUSE pour permettre des appels d'API locaux qui effectuent des opérations de lecture et d'écriture de fichiers, ce qui rend très facile le chargement de données avec des API non distribuées pour le rendu interactif. Dans la commande Python open(...) ci-dessous, le préfixe "/dbfs/..." active l'utilisation du montage FUSE.
Shapefile est un format vectoriel populaire développé par ESRI qui stocke l'emplacement géométrique et les informations d'attribut des entités géographiques. Le format se compose d'une collection de fichiers avec un préfixe de nom de fichier commun (*.shp, *.shx et *.dbf sont obligatoires) stockés dans le même répertoire. Une alternative au shapefile est KML, également utilisé par nos clients mais non montré par souci de brièveté. Pour cet exemple, utilisons les shapefiles des bâtiments de NYC. Bien qu'il existe de nombreuses façons de démontrer la lecture des shapefiles, nous donnerons un exemple utilisant GeoSpark. Le ShapefileReader intégré est utilisé pour générer le DataFrame rawSpatialDf.
En enregistrant rawSpatialDf comme vue temporaire, nous pouvons facilement passer à la syntaxe Spark SQL pure pour travailler avec le DataFrame, y compris l'application d'une UDF pour convertir le WKT du shapefile en Géométrie.
De plus, nous pouvons utiliser la visualisation intégrée de Databricks pour des analyses en ligne telles que le graphique des bâtiments les plus hauts de NYC.

Données raster
Les données raster stockent des informations sur les caractéristiques dans une matrice de cellules (ou pixels) organis�ées en lignes et colonnes (discrètes ou continues). Les images satellite, la photogrammétrie et les cartes numérisées sont des types de données d'observation de la Terre (EO) basées sur des données raster.
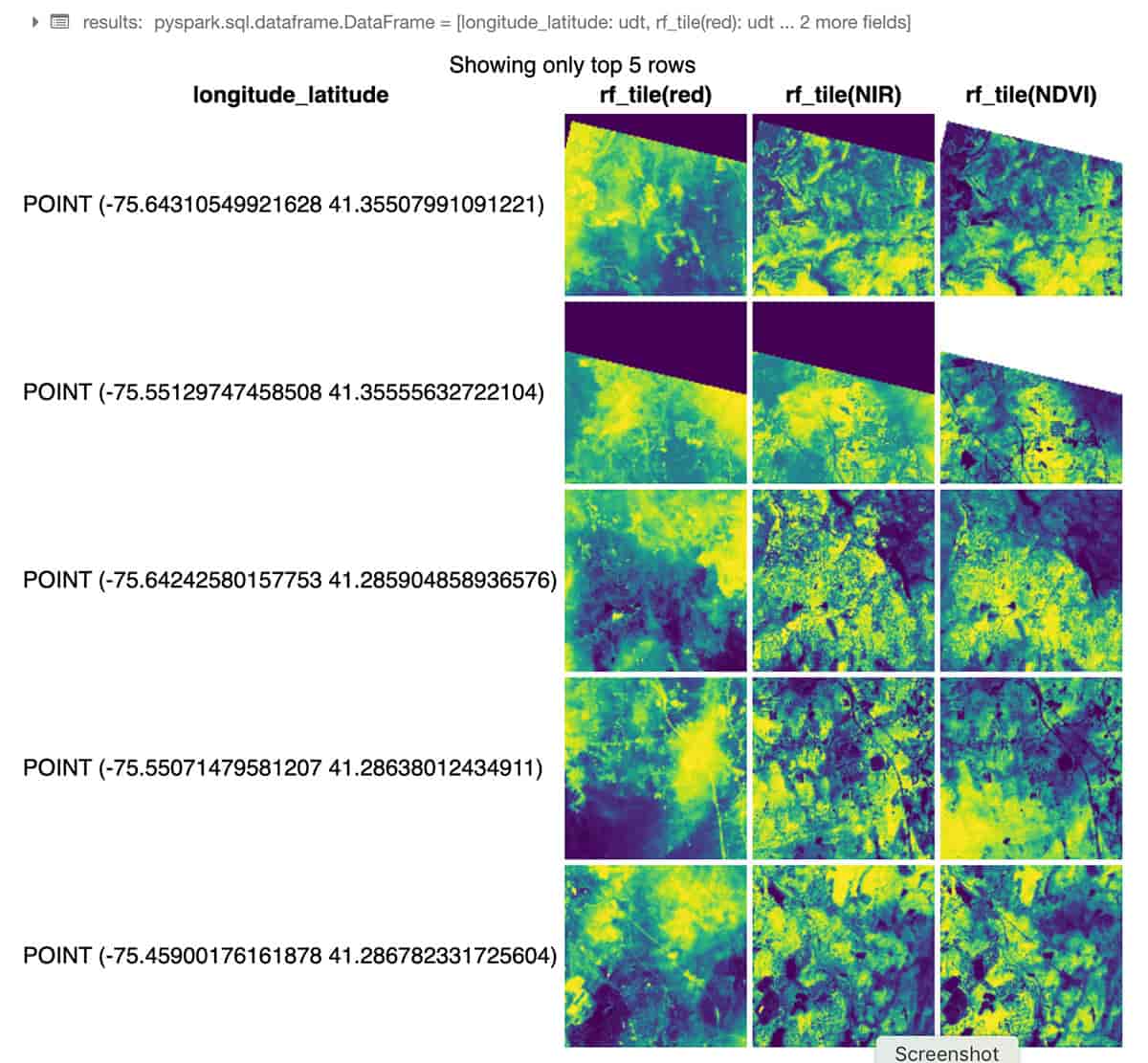
L'exemple Python suivant utilise RasterFrames, un framework d'analyse spatiale centré sur les DataFrames, pour lire deux bandes d'imagerie Landsat-8 GeoTIFF (rouge et proche infrarouge) et les combiner en un indice de végétation par différence normalisée. Nous pouvons utiliser ces données pour évaluer la santé des plantes autour de New York. Le module rf_ipython est utilisé pour manipuler le contenu de RasterFrame sous diverses formes visuellement utiles, comme ci-dessous, où les colonnes de tuiles rouge, NIR et NDVI sont rendues avec des rampes de couleurs, en utilisant la commande intégrée displayHTML(...) de Databricks pour afficher les résultats dans le notebook.
Grâce à sa source de données Spark personnalisée, RasterFrames peut lire divers formats raster, notamment GeoTIFF, JP2000, MRF et HDF, à partir d'un tableau de services. Il prend également en charge la lecture des formats vectoriels GeoJSON et WKT/WKB. Le contenu de RasterFrame peut être filtré, transformé, résumé, rééchantillonné et rasterisé grâce à plus de 200 fonctions raster et vectorielles, telles que st_reproject(...) et st_centroid(...) utilisées dans l'exemple ci-dessus. Il fournit des API pour Python, SQL et Scala, ainsi qu'une interopérabilité avec Spark ML.
GeoDatabases
Les bases de données géographiques peuvent être basées sur des fichiers pour des données à petite échelle ou accessibles via des connexions JDBC / ODBC pour des données à moyenne échelle. Vous pouvez utiliser Databricks pour interroger de nombreuses bases de données SQL avec la source de données JDBC / ODBC intégrée. La connexion à PostgreSQL est montrée ci-dessous, couramment utilisée pour les charges de travail à petite échelle en appliquant les extensions PostGIS. Ce modèle de connectivité permet aux clients de maintenir un accès tel quel aux bases de données existantes.
Démarrer avec l'analyse géospatiale sur Databricks
Les entreprises et les agences gouvernementales cherchent à utiliser des données référencées spatialement en conjonction avec des sources de données d'entreprise pour tirer des enseignements exploitables et réaliser un large éventail de cas d'utilisation innovants. Dans ce blog, nous avons démontré comment la plateforme d'analyse de données unifiée Databricks peut mettre à l'échelle facilement les charges de travail géospatiales, permettant à nos clients d'exploiter la puissance du cloud pour capturer, stocker et analyser des données de taille massive.
Dans un prochain article de blog, nous approfondirons des sujets plus avancés pour le traitement géospatial à grande échelle avec Databricks. Vous trouverez des détails supplémentaires sur les formats spatiaux et les frameworks mis en évidence en consultant le notebook de préparation des données, le notebook GeoMesa + H3, le notebook GeoSpark, le notebook GeoPandas et le notebook Rasterframes. Restez également à l'écoute pour une nouvelle section dans notre documentation spécifiquement dédiée aux sujets géospatiaux d'intérêt.
Prochaines étapes
- Rejoignez notre prochain webinaire Analyse géospatiale et IA dans le secteur public pour voir une démo en direct couvrant un certain nombre de cas d'utilisation populaires
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.