Qu'est-ce que l'analyse du Big Data ?
Analyser des ensembles de données massifs et variés provenant d'objets connectés, de médias sociaux et de sites de commerce électronique afin de découvrir des tendances cachées, des corrélations et des informations exploitables.
- Analyse les données structurées, semi-structurées et non structurées, de l'ordre du téraoctet au zettaoctet, grâce à des techniques avancées telles que l'apprentissage automatique, le traitement automatique du langage naturel et l'apprentissage profond.
- Exploite des frameworks distribués comme Hadoop, Spark et Hive pour traiter les données sur l'ensemble des réseaux, s'affranchissant ainsi des limitations des méthodes ETL traditionnelles et de la lenteur du traitement par lots.
- Permet de réduire les coûts grâce au cloud computing, facilite la prise de décision en temps réel grâce à l'analyse en mémoire et contribue à identifier les nouveaux produits, les tendances du marché et les préférences des clients.

Qu’est-ce que l’analytique Big Data ?
L’analytique Big Data est un processus complexe impliquant l’examen minutieux de volumes considérables et variés de données provenant de différentes sources (e-commerce, appareils mobiles, réseaux sociaux, IoT, etc.). L’objectif est d’unifier diverses sources de données, de transformer des données non structurées en données structurées et de générer des insights grâce à l’utilisation d’outils et de techniques spécialisés qui répartissent le traitement des données sur l’ensemble d’un réseau.
La quantité de données digitales augmente rapidement, doublant environ tous les deux ans. L'Analytique Big Data propose une approche différente pour gérer et analyser toutes ces sources de données. Bien que les principes de l’analytique de données classique restent valables, l’ampleur et la complexité de l’analytique Big Data ont exigé la mise au point de nouvelles approches de stockage et de traitement de quantités massives de données, qu’elles soient structurées ou non.
Processus et méthodes principaux
La demande de vitesses plus élevées et de capacités de stockage supérieures a créé un vacuum technologique qui n'a pas tardé à être comblé par différentes approches, notamment :
- Des méthodes de stockage telles que data warehouseet data lake
- Bases de données non relationnelles comme NoSQL
- Technologies et frameworks de traitement et de gestion des données, tels qu'Apache Hadoop open source, Spark et Hive.
L’analytique Big Data utilise des techniques avancées pour analyser des datasets vraiment volumineux provenant de différentes sources. Ces données peuvent être structurées, semi-structurées ou non-structurées, et être de tailles variées, du téraoctet au zettaoctet.
Analytique de données traditionnelle vs. Analytique Big Data
Avant Hadoop, les technologies sur lesquelles reposaient les systèmes modernes de stockage et de traitement étaient assez rudimentaires. C’est pourquoi les entreprises se limitaient à l’analyse de petits volumes de données. Même cette forme d'analytique pourrait être difficile, surtout l'intégration de nouvelles sources de données. Avec l'analytique de données traditionnelle, qui repose sur des bases de données relationnelles de données structurées, chaque octet de données brutes doit être formaté d'une manière spécifique avant de pouvoir être ingéré dans la base de données pour analyse. Pour toute nouvelle source de données, il est nécessaire de passer par le processus ETL (Extraire, transformer et charger) qui peut parfois être fastidieux et prendre du temps. Ce processus en trois étapes nécessite beaucoup de temps et de travail. Les data scientists et les ingénieurs ont souvent besoin d’environ 18 mois pour le mettre en place ou le modifier. C’est le principal problème de cette méthode.
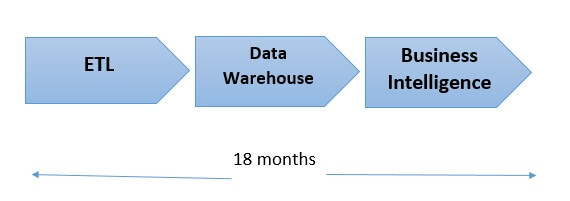
Cependant, les analystes peuvent facilement interroger et analyser les données une fois qu’elles sont stockées dans la base. Cependant, l’avènement d’Internet, du e-commerce, des réseaux sociaux, des appareils mobiles, de l’automatisation du marketing, des dispositifs IoT (Internet des objets) et de bien d’autres technologies, a généré une quantité considérable de données brutes. Cette masse est devenue si importante que la plupart des institutions ne sont plus en mesure de l'analyser dans le cadre de leurs activités courantes, à l’exception d’un petit groupe de privilégiées.
Le guide pratique de l'IA agentique pour l'entreprise

Types de données les plus courants en Analytique Big Data
- Les données Web : il s’agit d’informations recueillies sur le comportement en ligne des utilisateurs telles que le nombre de visites, les pages visitées, les recherches effectuées, les achats réalisés, et bien plus encore.
- Les données textuelles : il s’agit des données issues de sources de textes telles que les e-mails, les articles d’actualité, les flux Facebook ou les documents Word, etc. Elles sont parmi les données non structurées les plus importantes et les plus utilisées.
- Données temporelles et de localisation, ou données géospatiales : les GPS et les téléphones portables, ainsi que les connexions Wi-Fi, font des informations temporelles et de localisation une source croissante de données intéressantes. Il peut également s’agir de données géographiques relatives aux routes, bâtiments, lacs, adresses, personnes, lieux de travail et itinéraires de transport. Elles sont créées à partir de systèmes d’information géographique.
- Les médias en temps réel : les sources de données en temps réel peuvent inclure des données de streaming en temps réel ou des données basées sur des événements.
- Les données des réseaux intelligents et des capteurs : les capteurs installés sur les véhicules, pipelines, éoliennes et autres équipements peuvent générer des données à une fréquence extrêmement élevée.
- Données des réseaux sociaux : Le texte non structuré (commentaires, mentions J'aime, etc.) provenant des réseaux sociaux tels que Facebook, LinkedIn, Instagram, etc. est en pleine croissance. Il est même possible de faire une analyse des liens pour découvrir le réseau d’un utilisateur donné.
- Les données de connexion : ces informations sont obtenues à l’aide de technologies courantes du Web, telles que HTTP, RDF, SPARQL et URL.
- Les données de réseau : les données concernant les réseaux sociaux populaires comme Facebook et Twitter, ainsi que les réseaux technologiques tels que l’Internet, les réseaux téléphoniques et les réseaux de transport.
L’analytique Big Data aide les organisations à exploiter leurs données en utilisant des techniques avancées de la data science, notamment le traitement du langage naturel, le deep learning et le machine learning. De cette manière, elles peuvent identifier des modèles cachés, des corrélations inconnues et des tendances du marché, mais aussi mettre au jour les préférences de leurs clients. Cette approche les aide à saisir de nouvelles opportunités et à prendre des décisions commerciales plus éclairées.
Quelques avantages à utiliser l’analytique Big Data sont :
- La réduction des coûts : les technologies de stockage et de cloud computing comme AWS (Amazon Web Services) et Microsoft Azure, ainsi que le trio de logiciels Apache Hadoop, Spark et Hive, offrent l’avantage de réduire les coûts pour les entreprises souhaitant stocker et analyser de larges volumes de données.
- L’amélioration de la prise de décision : grâce à la rapidité de Spark et de l’analyse en mémoire, combinée à la capacité à analyser rapidement de nouvelles sources de données, les entreprises peuvent générer instantanément des insights exploitables pour prendre des décisions en temps réel.
- De nouveaux produits et services : grâce aux outils d’analytique Big Data, les entreprises sont en mesure de mieux comprendre les besoins de leur clientèle, simplifiant ainsi leur aptitude à fournir les produits et services adéquats.
- La détection des fraudes : l’analytique Big Data est également utilisée pour lutter contre la fraude, notamment dans le secteur des services financiers. Tous les autres secteurs d’activité s’en servent également de plus en plus.
Ressources supplémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.