Le lakehouse, une réponse aux problèmes courants des data warehouses
par Ryan Boyd
Lisez « Rise of the Data Lakehouse » pour découvrir avec Bill Inmon, le père du data warehouse, pourquoi les lakehouses constituent l'architecture de données du futur.
Note de la rédaction : il s'agit du premier d'une série d'articles largement basés sur l'article du CIDR Lakehouse: A New Generation of Open Platforms that Unify entreposage des données and Advanced analytique, avec l'autorisation des auteurs.
Les data analyst, les data scientist et les experts en intelligence artificielle sont souvent frustrés par le manque fondamental de données de haute qualité, fiables et à jour disponibles pour leur travail. Certaines de ces frustrations sont dues aux inconvénients connus de l'architecture de données à deux niveaux que l'on observe aujourd'hui dans la grande majorité des entreprises du Fortune 500. L'architecture lakehouse ouverte et la technologie sous-jacente peuvent améliorer considérablement la productivité des équipes de données et donc l'efficacité des entreprises qui les emploient.
Défis de l'architecture de données à deux niveaux
Dans cette architecture populaire, les données de toute l'organisation sont extraites des bases de données opérationnelles et chargées dans un data lake, parfois appelé marécage de données en raison du manque de soin apporté pour garantir que ces données sont utilisables et fiables. Ensuite, un autre processus ETL (Extraire, transformer et charger) est exécuté de manière planifiée pour déplacer des sous-ensembles de données importants vers un data warehouse à des fins de Business Intelligence et de prise de décision.
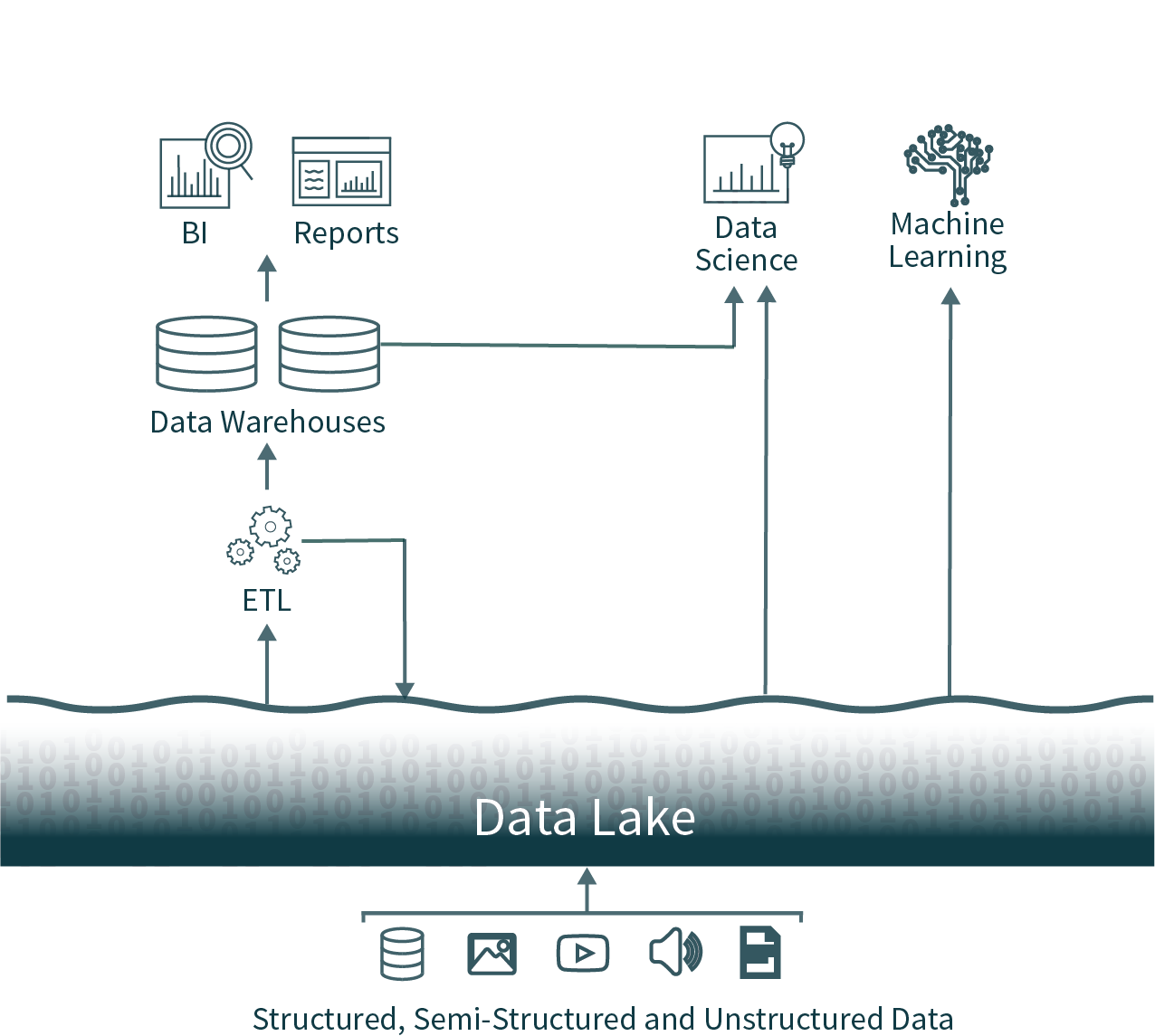
Cette architecture impose aux data analysts un choix quasi impossible : utiliser des données actuelles mais peu fiables provenant du data lake, ou des données obsolètes mais de haute qualité provenant du data warehouse. En raison des formats fermés des solutions d'entreposage des données populaires, il est également très difficile d'utiliser les principaux frameworks d'analyse de données open source sur des sources de données de haute qualité sans introduire une autre opération ETL et ajouter une obsolescence supplémentaire.
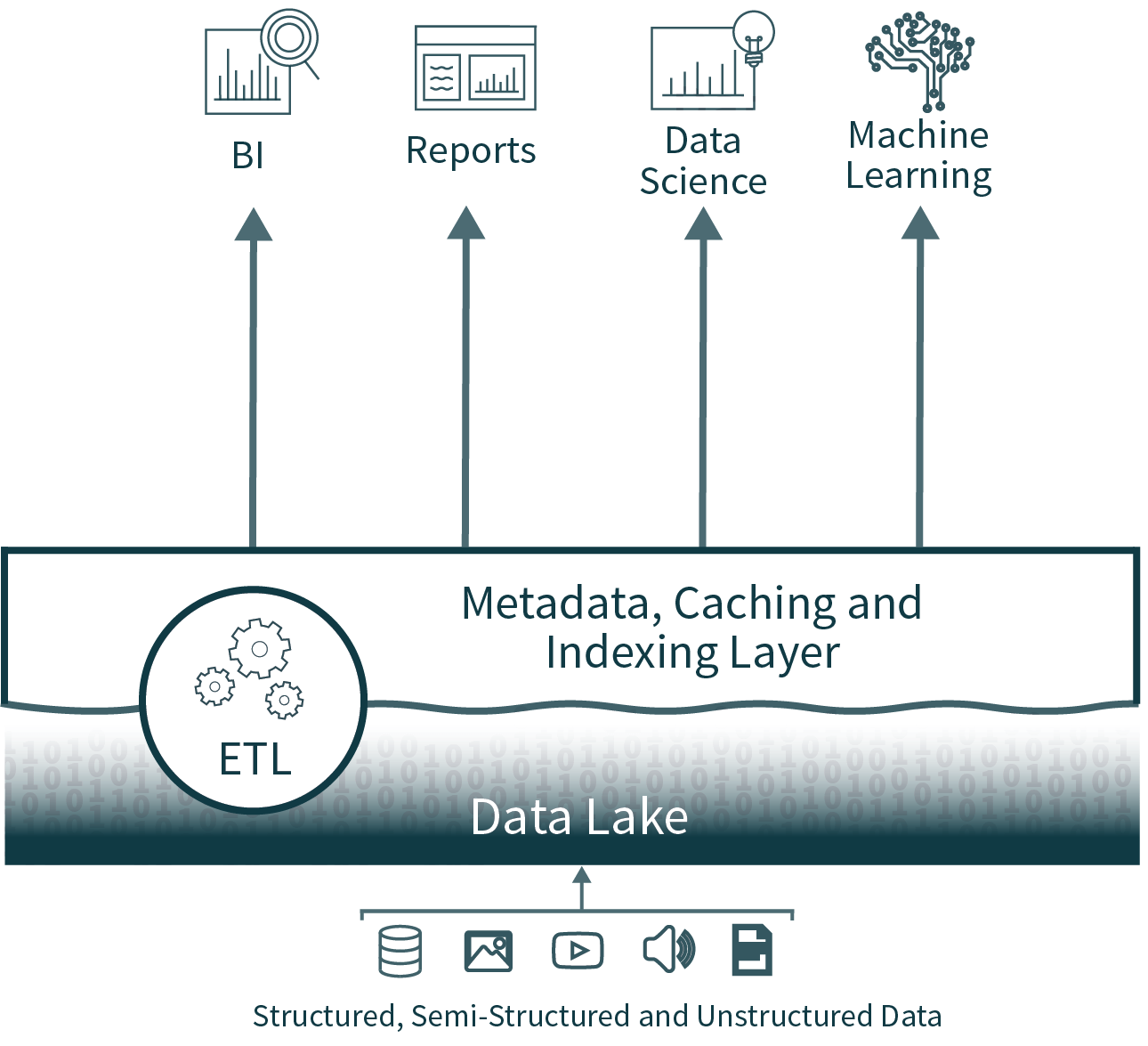
Nous pouvons faire mieux : voici le Data Lakehouse.
Ces architectures de données à deux niveaux, aujourd'hui courantes dans les entreprises, sont très complexes tant pour les utilisateurs que pour les data engineers qui les développent, qu'elles soient hébergées on-premise ou dans le cloud.
L'architecture Lakehouse réduit la complexité, le coût et la charge opérationnelle en offrant bon nombre des avantages en matière de fiabilité et de performances de la couche de data warehouse directement sur le lac de données, éliminant ainsi la couche de warehouse.
FIABILITÉ DES DONNÉES
La cohérence des données est un défi de taille lorsque vous devez synchroniser plusieurs copies de données. Il existe de multiples processus ETL, qui déplacent les données des bases de données opérationnelles vers le data lake, puis du data lake vers le data warehouse. Chaque processus supplémentaire apporte son lot de complexité, de retards et de modes de défaillance.
En éliminant la deuxième couche, l'architecture Data Lakehouse supprime l'un des processus ETL, tout en ajoutant la prise en charge de l'application des schémas et de l'évolution directement sur le lac de données. Il prend également en charge des fonctionnalités telles que time travel pour permettre la validation historique de la propreté des données.
Obsolescence des données
Comme le data warehouse est alimenté à partir du data lake, il est souvent obsolète. Selon une enquête récente de Fivetran, cela oblige 86 % des analystes à utiliser des données obsolètes.

Si l'élimination de la couche d'entrepôt de données résout ce problème, un lakehouse peut également prendre en charge une fusion efficace, facile et fiable du streaming en temps réel et du traitement par lots, afin de garantir que les données les plus récentes sont toujours utilisées pour l'analyse.
Prise en charge limitée de l'analytique avancée
L'analytique avancée, y compris le machine learning et l'analytique prédictive, nécessite souvent le traitement de très grands datasets. Les outils courants, tels que TensorFlow, PyTorch et XGBoost, facilitent la lecture des lacs de données brutes dans des formats de données ouverts. Cependant, ces outils ne peuvent pas lire la plupart des formats de données propriétaires utilisés par les données traitées par ETL dans les data warehouses. Les fournisseurs de Warehouse recommandent donc d'exporter ces données dans des fichiers pour les traiter, ce qui entraîne une troisième étape ETL ainsi qu'une complexité et une obsolescence accrues.
Alternativement, dans l'architecture lakehouse ouverte, ces ensembles d'outils courants peuvent fonctionner directement sur des données de haute qualité et à jour stockées dans le data lake.
Coût total de possession
Alors que les coûts de stockage dans le cloud diminuent, cette architecture à deux niveaux pour l'analyse de données possède en réalité trois copies en ligne d'une grande partie des données de l'entreprise : une dans les bases de données opérationnelles, une dans le data lake et une dans le data warehouse.
Le coût total de possession (TCO) augmente encore lorsque l'on ajoute les coûts de Data Engineering importants liés à la synchronisation des données aux coûts de stockage.
L'architecture data lakehouse élimine l'une des copies de données les plus coûteuses, ainsi qu'au moins un processus de synchronisation associé.
Qu'en est-il des performances pour la Business Intelligence ?
Business Intelligence et l'aide à la décision nécessitent une exécution haute performance des queries d'analyse exploratoire des données (EDA), ainsi que des queries alimentant les tableaux de bord, les visualisations de données et d'autres systèmes critiques. Les problèmes de performance expliquaient souvent pourquoi les entreprises conservaient un data warehouse en plus d'un data lake. La Technologie d'optimisation des queries sur les data lakes s'est considérablement améliorée au cours de l'année écoulée, rendant la plupart de ces problèmes de performance sans objet.
Les Lakehouses prennent en charge l'indexation, les contrôles de localité, l'optimisation des requêtes et la mise en cache des données chaudes pour améliorer les performances. Il en résulte des performances SQL sur le data lake qui dépassent celles des principaux data warehouse cloud sur TPC-DS, tout en offrant la flexibilité et la gouvernance attendues des data warehouse.
Conclusion et prochaines étapes
Les entreprises et les technologues avant-gardistes ont examiné l'architecture à deux niveaux utilisée aujourd'hui et se sont dit : « Il doit y avoir une meilleure solution. » Cette meilleure solution est ce que nous appelons le data lakehouse ouvert, qui combine l'ouverture et la flexibilité du lac de données avec la fiabilité, les performances, la faible latence et la high concurrency des entrepôts de données traditionnels.
Je détaillerai les améliorations des performances des data lakes dans un prochain article de cette série.
Bien sûr, vous pouvez tricher et prendre de l'avance en lisant l'article complet du CIDR, ou en regardant une série de vidéos qui plonge dans la technologie sous-jacente du lakehouse moderne.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.