Apache Spark et Photon reçoivent des prix SIGMOD
par Reynold Xin et Matei Zaharia
Cette semaine, un grand nombre des ingénieurs et chercheurs les plus influents de la Communauté de la gestion de données se réunissent en personne à Philadelphie pour la conférence ACM SIGMOD, après deux ans de réunions virtuelles. Dans le cadre de cet événement, nous avons été ravis de voir les deux récompenses suivantes :
- Apache Spark a reçu le prix SIGMOD Systems Award.
- Databricks Photon a reçu le prix du meilleur article de l'industrie
Nous avons pensé que ce serait une bonne occasion de discuter du contexte et de la manière dont nous en sommes arrivés là.
Qu'est-ce que l'ACM SIGMOD et quelles sont les récompenses ?
ACM SIGMOD signifie Association of Computing Machinery’s Special Interest Group in the Management of Data. On sait, le nom est long. Tout le monde dit simplement SIGMOD. C'est la conférence la plus prestigieuse pour les chercheurs et les ingénieurs en bases de données, car bon nombre des idées les plus fondamentales dans le domaine des bases de données, des magasins de colonnes aux optimisations de requêtes, ont été publiées lors de cette conférence.
Le prix SIGMOD Systems Award est décerné chaque année à un « système dont les contributions techniques ont eu un impact significatif sur la théorie ou la pratique des systèmes de gestion de données à grande échelle ». Ces systèmes ont tendance à avoir des applications concrètes à grande échelle et à influencer la conception des futurs systèmes de bases de données. Les lauréats précédents incluent Postgres, SQLite, BerkeleyDB et Aurora.
Le prix du meilleur article du secteur d'activité est décerné chaque année à un article en fonction de la combinaison de son impact concret, de son innovation et de la qualité de sa présentation.
Apache Spark : les origines de la data et de l'IA
Il y a une dizaine d'années, Netflix a démarré un concours appelé le Prix Netflix, dans lequel l'entreprise a anonymisé sa vaste collection d'évaluations de films par les utilisateurs et a demandé aux concurrents de proposer des algorithmes pour prédire comment les utilisateurs évalueraient les films. Le trophée de 1 million de dollars américains reviendrait à l'équipe possédant le meilleur modèle de machine learning.
Un groupe de doctorants de l'UC Berkeley a décidé de participer à un concours. Le premier défi auquel ils ont été confrontés était que les outils n'étaient tout simplement pas assez performants. Pour créer de meilleurs modèles, ils avaient besoin d'un moyen rapide et itératif de nettoyer, d'analyser et de traiter de grandes quantités de données (qui ne tenaient pas sur l'ordinateur portable d'un étudiant), ainsi que d'un framework suffisamment expressif pour composer des algorithmes de ML expérimentaux.
Les data warehouses, qui constituaient la norme pour les données d'entreprise, ne pouvaient pas traiter les données non structurées et manquaient d'expressivité. Ils ont discuté de ce défi avec un autre doctorant, Matei Zaharia. Ensemble, ils ont conçu un nouveau framework de calcul parallèle appelé Spark, avec une nouvelle structure de données distribuées innovante appelée RDDs. Spark permettait à ses utilisateurs d'exécuter rapidement et de manière concise des opérations de données parallèles.
Autrement dit, il est rapide à la fois pour écrire le code et pour l'exécuter. La rapidité d'écriture est importante, car elle rend le programme plus compréhensible et permet de composer plus facilement des algorithmes plus complexes. Une exécution rapide signifie que les utilisateurs peuvent obtenir un retour plus rapidement et construire leurs modèles en utilisant des données en constante augmentation.

Il s'est avéré que les étudiants n'étaient pas seuls. C'était les débuts des applications de données et d'IA dans les secteurs d'activité, et tout le monde était confronté à des défis similaires. Suite à la demande générale, le projet a été transféré à l'Apache Software Foundation et s'est développé pour devenir une immense communauté.
Aujourd'hui, Spark est la norme de facto pour le traitement des données, et son adoption est en pleine croissance :
- Il a été téléchargé 45 millions de fois le mois dernier, uniquement sur PyPI et Maven Central. Cela représente une croissance de 90 % des downloads d'une année sur l'autre.
- Il est utilisé dans au moins 204 pays et régions.
- Elle est classée n°1 des technologies les mieux rémunérées dans l'enquête 2021 de Stack Overflow auprès des développeurs.
Le SIGMOD Systems Award est une reconnaissance de l'adoption du projet, ainsi que de son influence sur les générations de systèmes à venir pour les amener à considérer les données et l'IA comme un package unifié.
Photon : Nouvelles charges de travail et Lakehouse
Avec la popularité croissante d'Apache Spark, nous avons constaté que les organisations voulaient faire plus que du traitement de données à grande échelle et du machine learning avec cet outil : elles voulaient exécuter des applications traditionnelles d'entreposage des données interactives sur les mêmes datasets qu'elles utilisaient ailleurs dans leur entreprise, éliminant ainsi la nécessité de gérer plusieurs systèmes de données. Cela a conduit au concept de systèmes lakehouse : un magasin de données unique capable d'effectuer un traitement à grande échelle et des requêtes SQL interactives, combinant les avantages des systèmes d'entrepôt de données et de lac de données.
Pour prendre en charge ces types de cas d'utilisation, nous avons développé Photon, un moteur d'exécution vectoriel rapide en C++ pour les charges de travail Spark et SQL, qui s'exécute en arrière-plan des interfaces de programmation existantes de Spark. Photon permet des requêtes interactives beaucoup plus rapides ainsi qu'une simultanéité beaucoup plus élevée que Spark, tout en prenant en charge les mêmes API et charges de travail, y compris les applications SQL, Python et Java. Nous avons obtenu d'excellents résultats avec Photon sur des charges de travail de toutes tailles, que ce soit pour établir le record du monde dans le benchmark d'entrepôt de données à grande échelle TPC-DS l'année dernière ou pour offrir des performances 3 fois supérieures sur les petites requêtes simultanées.
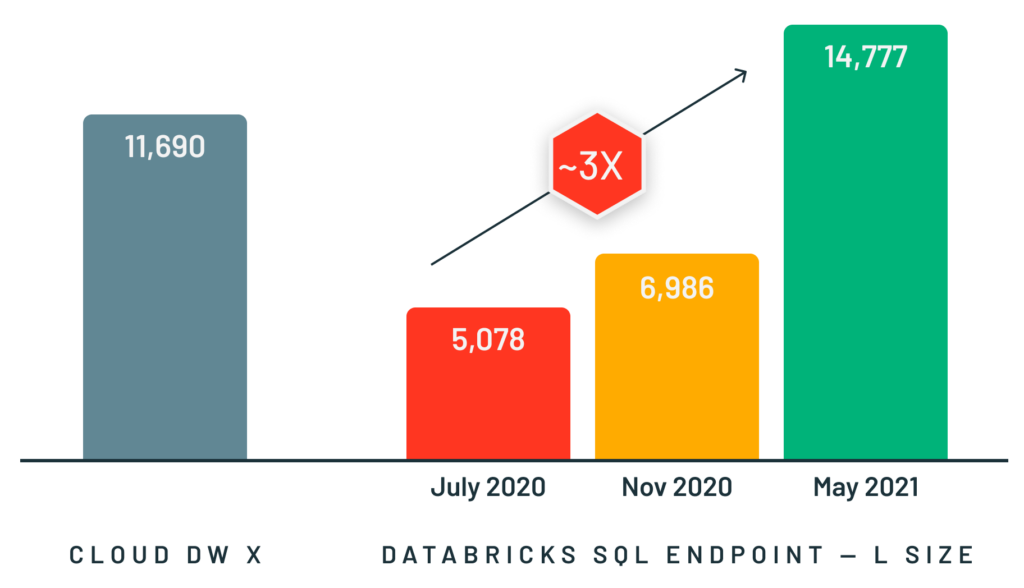
La conception et l'implémentation de Photon ont représenté un défi, car le moteur devait conserver l'expressivité et la flexibilité de Spark (pour prendre en charge le large éventail d'applications), n'être jamais plus lent (pour éviter les régressions de performance) et être nettement plus rapide pour nos charges de travail cibles. De plus, contrairement à un moteur de data warehouse traditionnel qui part du principe que toutes les données ont été chargées dans un format propriétaire, Photon devait fonctionner dans l'environnement lakehouse, en traitant les données dans des formats ouverts tels que Delta Lake et Apache Parquet, avec un minimum d'hypothèses sur le processus d'ingestion (p. ex., la disponibilité d'index ou de statistiques de données). Notre article SIGMOD décrit comment nous nous sommes attaqués à ces défis ainsi que de nombreux détails techniques de l'implémentation de Photon.
Nous avons été ravis de voir ce travail récompensé par le prix du meilleur article de l'industrie (Best Industry Paper) et nous espérons qu'il donnera aux ingénieurs et chercheurs en bases de données de bonnes idées sur les défis de ce nouveau modèle de systèmes lakehouse. Bien sûr, nous sommes également très enthousiasmés par ce que nos clients ont accompli jusqu'à présent avec Photon -- le nouveau moteur représente déjà une part importante de notre charge de travail.
Si vous participez à SIGMOD, passez au stand de Databricks et venez nous saluer. Nous serions ravis de discuter avec vous de l'avenir des systèmes de données. En échange, nous vous offrirons un t-shirt « the best data warehouse is a lakehouse » !

Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.