Databricks établit un record officiel de performance pour l'entreposage des données
par Reynold Xin et Mostafa Mokhtar
Aujourd'hui, nous sommes fiers d'annoncer que Databricks SQL a établi un nouveau record du monde au benchmark TPC-DS de 100 To, la référence absolue en matière de performances pour l'entreposage des données. Databricks SQL a surclassé le précédent record de 2,2x. Contrairement à la plupart des autres annonces de benchmarks, ce résultat a été officiellement audité et examiné par le conseil TPC.
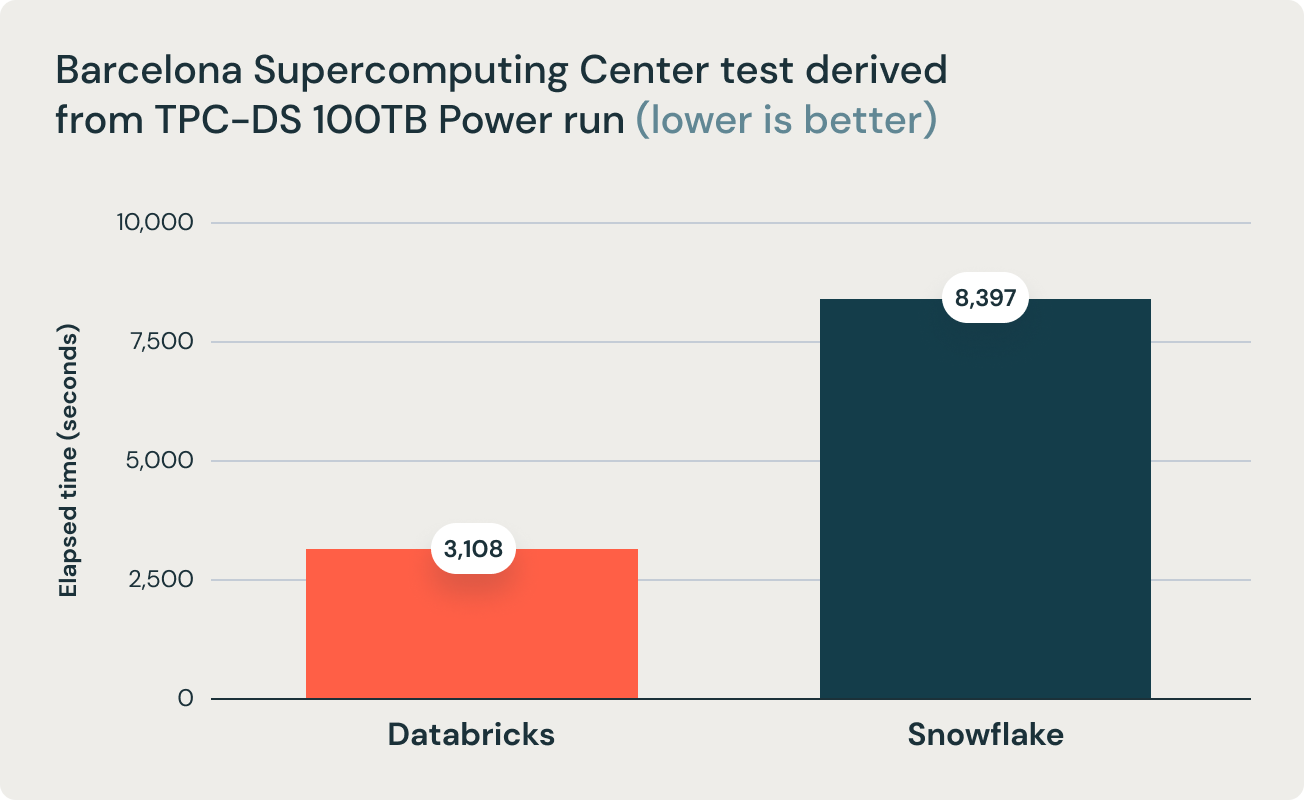
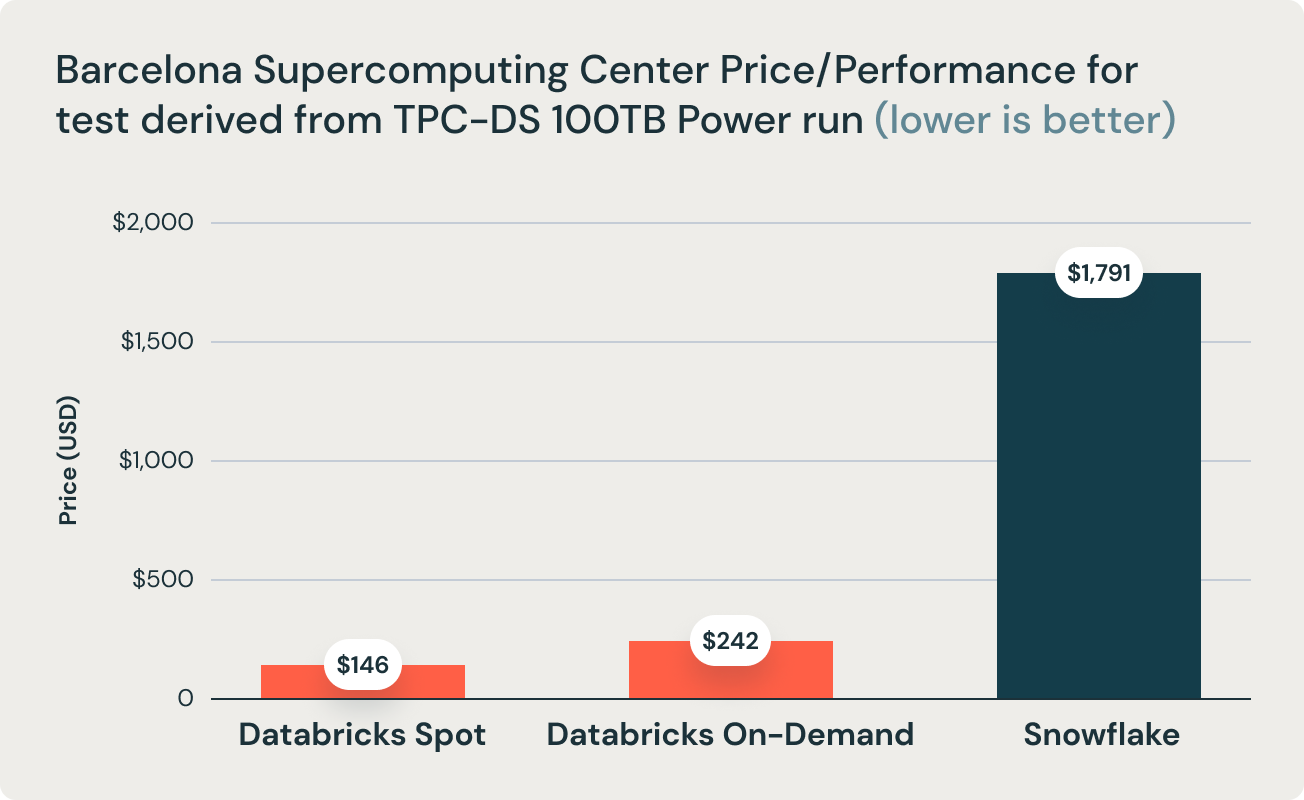
Ces résultats ont été corroborés par les recherches du Barcelona Supercomputing Center, qui exécute fréquemment des benchmarks dérivés de TPC-DS sur des data warehouses populaires. Leurs dernières recherches ont comparé les performances de Databricks et Snowflake et ont révélé que Databricks était 2,7 fois plus rapide et 12 fois plus performant en termes de rapport prix/performance. Ce résultat a validé la thèse selon laquelle les data warehouse tels que Snowflake deviennent d'un coût prohibitif à mesure que la taille des données augmente en production.
Databricks a développé rapidement des fonctionnalités complètes d'entreposage des données directement sur les data lakes, combinant le meilleur des deux mondes dans une architecture de données baptisée le data lakehouse. Nous avons annoncé notre suite complète de fonctionnalités d'entreposage des données sous le nom de Databricks SQL en novembre 2020. La question qui restait en suspens depuis lors était de savoir si une architecture ouverte basée sur un lakehouse pouvait offrir les performances, la vitesse et le coût des data warehouses classiques. Ce résultat prouve sans l'ombre d'un doute que c'est possible et réalisable avec l'architecture lakehouse.
Plutôt que de nous contenter de partager les résultats, nous souhaitons vous raconter comment nous avons atteint un tel niveau de performance et les efforts que cela a nécessité. Mais commençons par les résultats :
Record du monde TPC-DS
Databricks SQL a atteint 32 941 245 QphDS @ 100 To. Ce résultat bat de 2,2 fois le précédent record du monde détenu par le système personnalisé d'Alibaba, qui avait atteint 14 861 137 QphDS @ 100 To. (Alibaba disposait d'un système impressionnant prenant en charge la plus grande plateforme d'e-commerce au monde). Non seulement Databricks SQL a largement battu le précédent record, mais il l'a fait en réduisant le coût total du système de 10 % (sur la base des Tarifs publics affichés, sans aucune remise).
Il est tout à fait normal que vous ne sachiez pas ce que signifie l'unité QphDS. (Nous non plus, sans regarder la formule.) QphDS est la métrique principale pour TPC-DS, qui représente les performances d'une combinaison de charges de travail, notamment (1) le chargement du jeu de données, (2) le traitement d'une séquence de queries (test de puissance), (3) le traitement de plusieurs streams de queries simultanés (test de throughput) et (4) l'exécution de fonctions de maintenance des données qui insèrent et suppriment des données.
Cette conclusion est également étayée par l'équipe de recherche du Barcelona Supercomputing Center (BSC) qui a récemment exécuté un benchmark différent dérivé de TPC-DS comparant Databricks SQL et Snowflake, et a constaté que Databricks SQL était 2,7 fois plus rapide qu'une configuration Snowflake de taille similaire.
Qu'est-ce que TPC-DS ?
TPC-DS est un benchmark d'entreposage des données défini par le Transaction Processing Performance Council (TPC). TPC est une organisation à but non lucratif créée par la communauté des bases de données à la fin des années 80, qui se concentre sur la création de benchmarks qui émulent des scénarios réels et qui, par conséquent, peuvent être utilisés objectivement pour mesurer les performances des systèmes de bases de données. TPC a eu un impact profond dans le domaine des bases de données, avec des « guerres de benchmarking » de plusieurs décennies entre des fournisseurs établis comme Oracle, Microsoft et IBM qui ont fait progresser le domaine.
Le "DS" de TPC-DS signifie "aide à la décision". Il comprend 99 queries de complexité variable, allant d'agrégations très simples à l'exploration de motifs complexes. Il s'agit d'un benchmark relativement nouveau (les travaux ont commencé au milieu des années 2000) qui reflète la complexité croissante de l'analytique. Au cours de la dernière décennie, TPC-DS est devenu le benchmark de facto de l'entreposage des données, adopté par la quasi-totalité des fournisseurs.
Cependant, en raison de sa complexité, de nombreux systèmes data warehouse, même ceux conçus par les fournisseurs les plus établis, ont modifié le benchmark officiel afin que leurs propres systèmes obtiennent de bonnes performances. (Parmi les ajustements courants, on trouve la suppression de certaines fonctionnalités SQL telles que les rollups ou la modification de la distribution des données pour supprimer l'asymétrie). C'est l'une des raisons pour lesquelles il y a eu très peu de soumissions au benchmark officiel TPC-DS, malgré plus de 4 millions de pages sur Internet à propos de TPC-DS. Ces ajustements expliquent aussi ostensiblement pourquoi la plupart des fournisseurs semblent battre tous les autres selon leurs propres benchmarks.
Comment y sommes-nous parvenus ?
Comme mentionné précédemment, la question s'est posée de savoir si Databricks SQL pouvait surpasser les data warehouses en termes de performances SQL. La plupart des défis peuvent se résumer aux quatre problèmes suivants :
- Les data warehouse exploitent des formats de données propriétaires et, par conséquent, peuvent les faire évoluer rapidement, tandis que Databricks (basé sur lakehouse) s'appuie sur des formats ouverts (tels qu'Apache Parquet et Delta Lake) qui n'évoluent pas aussi rapidement. Par conséquent, les EDW auraient un avantage inhérent.
- D'excellentes performances SQL requièrent l'architecture MPP (traitement massivement parallèle), et Databricks et Apache Spark n'étaient pas MPP.
- Le compromis classique entre le throughput et la latence implique qu'un système peut être excellent soit pour les grandes queries (axées sur le throughput), soit pour les petites queries (axées sur la latence), mais pas pour les deux. Comme Databricks se concentrait sur les queries volumineuses, nos performances devaient être moins bonnes pour les queries de petite taille.
- Même si c'est possible, l'opinion générale veut qu'il faille une décennie ou plus pour construire un système de data warehouse. Il est impossible de progresser aussi rapidement.
Dans la suite de ce billet de blog, nous les aborderons un par un.
Formats de données propriétaires ou ouverts
L'un des principes clés de l'architecture Lakehouse est le format de stockage ouvert. "Open" non seulement évite le verrouillage propriétaire, mais permet également le développement d'un écosystème d'outils indépendamment du fournisseur. L'un des principaux avantages des formats ouverts est la standardisation. Grâce à cette standardisation, la plupart des données d'entreprise se trouvent dans des data lakes ouverts et Apache Parquet est devenu la norme de facto pour le stockage des données. En apportant des performances dignes d'un data warehouse aux formats ouverts, nous espérons minimiser les déplacements de données et simplifier l'architecture des données pour les charges de travail BI et IA.
Une critique évidente à l'encontre du format "ouvert" est que les formats ouverts sont difficiles à modifier et, par conséquent, difficiles à améliorer. Bien qu'en théorie cet argument soit logique, il n'est pas exact en pratique.
Tout d'abord, il est tout à fait possible que les formats ouverts évoluent. Parquet, le format ouvert le plus populaire pour le stockage de données volumineuses, a connu plusieurs itérations d'améliorations. L'une des principales motivations qui nous ont poussés à introduire Delta Lake était d'apporter des fonctionnalités supplémentaires qu'il était difficile de mettre en œuvre au niveau de la couche Parquet. Delta Lake a apporté une indexation et des statistiques supplémentaires à Parquet.
Deuxièmement, le système Databricks transcode automatiquement les données brutes Delta Lake et Parquet dans un format plus efficace lors du chargement des données depuis les object stores vers les SSD NVMe locaux (sans intervention de l'utilisateur). Cela ouvre la voie à de nouvelles possibilités d'optimisation.
Cela dit, pour la plupart des charges de travail d'entreposage des données, Delta Lake et Parquet fournissent déjà des optimisations suffisantes par rapport aux formats propriétaires utilisés par les data warehouses. Pour ces charges de travail, les opportunités d'optimisation proviennent principalement de la capacité à traiter les requêtes plus rapidement, plutôt que de scanner davantage de données plus rapidement. En fait, pour TPC-DS, l'interrogation de données mises en cache dans un format interne plus optimisé n'est que 10 % plus rapide que l'interrogation de données froides dans S3 (nous avons constaté que cela était vrai à la fois pour les data warehouses que nous avons benchmarkés et pour Databricks).
Architecture MPP
Une idée reçue courante est que les data warehouses emploient l'architecture MPP, qui est idéale pour les performances SQL, tandis que Databricks ne le fait pas. L'architecture MPP fait référence à la capacité d'exploiter plusieurs nœuds pour traiter une seule query. C'est exactement ainsi que Databricks SQL est architecturé. Elle n'est pas basée sur Apache Spark, mais plutôt sur Photon, une réécriture complète d'un moteur, développé à partir de zéro en C++, pour le matériel SIMD moderne et qui effectue un traitement parallèle intensif des requêtes. Photon est donc un moteur MPP.
Compromis entre Throughput et latence
Le compromis entre Throughput et latence est un classique des systèmes informatiques, ce qui signifie qu'un système ne peut pas obtenir simultanément un throughput élevé et une faible latence. Si une conception privilégie le débit (par ex. en traitant les données par lots), elle devra sacrifier la latence. Dans le contexte des systèmes de données, cela signifie qu'un système ne peut pas traiter efficacement et simultanément les requêtes volumineuses et les petites requêtes.
Nous ne nions pas que ce compromis existe. En fait, nous en discutons souvent dans nos documents de conception technique. Cependant, les systèmes de pointe actuels, y compris le nôtre et tous les populaires warehouse, sont loin de la frontière optimale aussi bien sur le front du throughput que de la latence.
Par conséquent, il est tout à fait possible de proposer une nouvelle conception et une nouvelle implémentation qui améliorent simultanément son débit et sa latence. C'est exactement ainsi que nous avons développé la quasi-totalité de nos Technologies clés au cours des deux dernières années : Photon, Delta Lake et de nombreuses autres Technologies de pointe ont amélioré les performances des queries, petites et grandes, repoussant les limites pour atteindre un nouveau record de performance.
Temps et concentration
Enfin, l'opinion générale est qu'il faudrait au moins une décennie pour qu'un système de base de données arrive à maturité. Étant donné l'accent récent mis par Databricks sur le Lakehouse (pour prendre en charge les charges de travail SQL), il faudrait un effort supplémentaire pour que SQL soit performant. C'est exact, mais laissez-nous vous expliquer comment nous y sommes parvenus beaucoup plus rapidement qu'on pourrait s'y attendre.
Avant tout, cet investissement n'a pas commencé il y a seulement un an ou deux. Depuis la création de Databricks, nous avons investi dans diverses technologies fondamentales pour prendre en charge les workloads SQL, qui profiteraient également aux workloads d'IA sur Databricks. Cela inclut un optimiseur de requêtes complet basé sur les coûts, un moteur d'exécution vectoriel natif et diverses fonctionnalités telles que les fonctions de fenêtrage. La grande majorité des charges de travail sur Databricks s'exécutent par leur intermédiaire grâce à l'API DataFrame de Spark, qui est mappée sur son moteur SQL, de sorte que ces composants ont bénéficié d'années de tests et d'optimisation. En revanche, nous avons moins mis l'accent sur les charges de travail SQL. Le changement de positionnement vers le Lakehouse est récent et motivé par le désir de nos clients de simplifier leurs architectures de données.
Deuxièmement, le modèle SaaS a accéléré les cycles de développement logiciel. Par le passé, la plupart des fournisseurs avaient des cycles de publication annuels, puis un autre cycle de plusieurs années pour que les clients installent et adoptent l'outil. Avec le SaaS, notre équipe d'ingénierie peut concevoir un nouveau design, l'implémenter et le mettre à la disposition d'un sous-ensemble de clients en quelques jours seulement. Ce cycle de développement raccourci a permis aux équipes d'obtenir rapidement des retours et d'innover plus vite.
Troisièmement, Databricks pourrait se concentrer beaucoup plus sur ce problème, tant en termes de ressources de direction que de capital. Les tentatives passées de création d'un nouveau système de data warehouse ont été menées soit par des Startups, soit par une nouvelle équipe au sein d'une grande entreprise. Il n'y a jamais eu de startup de base de données aussi bien financée que Databricks (plus de 3,5 milliards de dollars levés) pour attirer les talents nécessaires à sa construction. Une nouvelle initiative au sein d'une grande entreprise ne serait qu'une initiative de plus et n'obtiendrait pas toute l'attention de la direction.
Notre situation était unique : nous nous sommes d'abord concentrés sur le développement de notre activité, non pas sur l'entreposage des données, mais sur des domaines connexes (Data Science et l'IA) qui partageaient de nombreux problèmes technologiques communs. Ce succès initial nous a ensuite permis de financer la constitution de l'équipe SQL la plus ambitieuse de l'histoire ; en peu de temps, nous avons constitué une équipe dotée d'une vaste expérience en matière de data warehouse, un exploit qui prendrait une dizaine d'années à de nombreuses autres entreprises. Parmi eux figurent des ingénieurs et concepteurs principaux de certains des systèmes de données les plus performants, notamment Amazon Redshift ; BigQuery de Google, F1 (le système de data warehouse interne de Google) et Procella (le système de data warehouse interne de YouTube) ; Oracle ; IBM DB2 ; et Microsoft SQL Server.
Pour résumer, il faut plusieurs années pour obtenir d'excellentes performances SQL. Non seulement nous avons accéléré ce processus en tirant parti de notre situation unique, mais nous avons également commencé il y a des années, même si nous n'avons pas crié notre plan sur tous les toits.
Charges de travail réelles des clients
Nous sommes ravis de voir ces résultats de benchmark validés par nos clients. Plus de 5 000 organisations mondiales exploitent la plateforme Databricks Lakehouse pour résoudre certains des problèmes les plus complexes au monde. Par exemple :
- Bread Finance est une plateforme de paiement axée sur la technologie avec des cas d'utilisation Big Data tels que le reporting financier, la détection de la fraude, le risque de crédit, l'estimation des pertes et un moteur de recommandation full-funnel. Sur la plateforme Databricks Lakehouse, elles sont en mesure de passer de traitements par lots nocturnes à une ingestion en temps quasi réel, et de réduire le temps de traitement des données de 90 %. De plus, la plateforme de données peut monter en charge jusqu'à 140 fois le volume de données pour seulement 1,5 fois le coût.
- Shell utilise notre Plateforme lakehouse pour permettre à des centaines de data analysts d'exécuter des queries rapides sur des datasets à l'échelle du pétaoctet à l'aide d'outils de BI standard, ce qui, selon eux, "change la donne".
- Regeneron accélère l'identification de cibles médicamenteuses, fournissant des informations plus rapides aux biologistes computationnels en réduisant le temps d'exécution des requêtes sur l'ensemble de leurs dataset de 30 minutes à 3 secondes – soit une amélioration de 600 fois.
Résumé
Databricks SQL, basé sur l'architecture lakehouse, est le data warehouse le plus rapide du marché et offre le meilleur rapport prix/performance. Vous pouvez désormais obtenir d'excellentes performances sur toutes vos données avec une faible latence dès que de nouvelles données sont ingérées, sans avoir à les exporter vers un autre système.
Cela témoigne de la vision du Lakehouse, qui consiste à apporter des performances d'entreposage des données de classe mondiale aux data lakes. Bien sûr, nous n'avons pas seulement construit un data warehouse. L'architecture Lakehouse permet de couvrir toutes les charges de travail de données, de l'entreposage de données à la data science et au machine learning.
Mais nous n'avons pas encore terminé. Nous avons réuni la meilleure équipe du marché, et elle met tout en œuvre pour offrir la prochaine avancée majeure en matière de performances. En plus des performances, nous travaillons également sur de nombreuses améliorations concernant la facilité d'utilisation et la gouvernance. Attendez-vous à d'autres annonces de notre part au cours de l'année à venir.
Le TPC n'audite ni ne valide les résultats des benchmarks dérivés du TPC-DS et ne considère pas les résultats des benchmarks dérivés comme étant comparables aux résultats TPC-DS publiés.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.