Photon
Le moteur de nouvelle génération pour le lakehouse
Photon est un moteur de nouvelle génération sur la plateforme lakehouse Databricks. En termes d'importation, d'ETL, de streaming, de data science et de requêtes interactives, il délivre des performances de requête exceptionnelles à un tarif compétitif, directement dans votre data lake. Photon est compatible avec les API Apache Spark™, donc il suffit de l'activer pour commencer à l'utiliser. Aucun code requis, aucune dépendance vis-à-vis d'un fournisseur.
Cheaper and faster
Built from the ground up for the fastest performance at lower cost, Photon provides up to 80% TCO savings while accelerating data and analytics workloads — up to 12x speedups.
Built for all use cases
Photon is the first engine that enables data teams to standardize on one set of APIs for all workloads — ETL, analytics and data science — in batch or streaming.
No code changes
Photon is an ANSI-compliant engine designed to be compatible with modern Apache Spark APIs and just works with your existing code — SQL, Python, R, Scala and Java — no rewrite required.
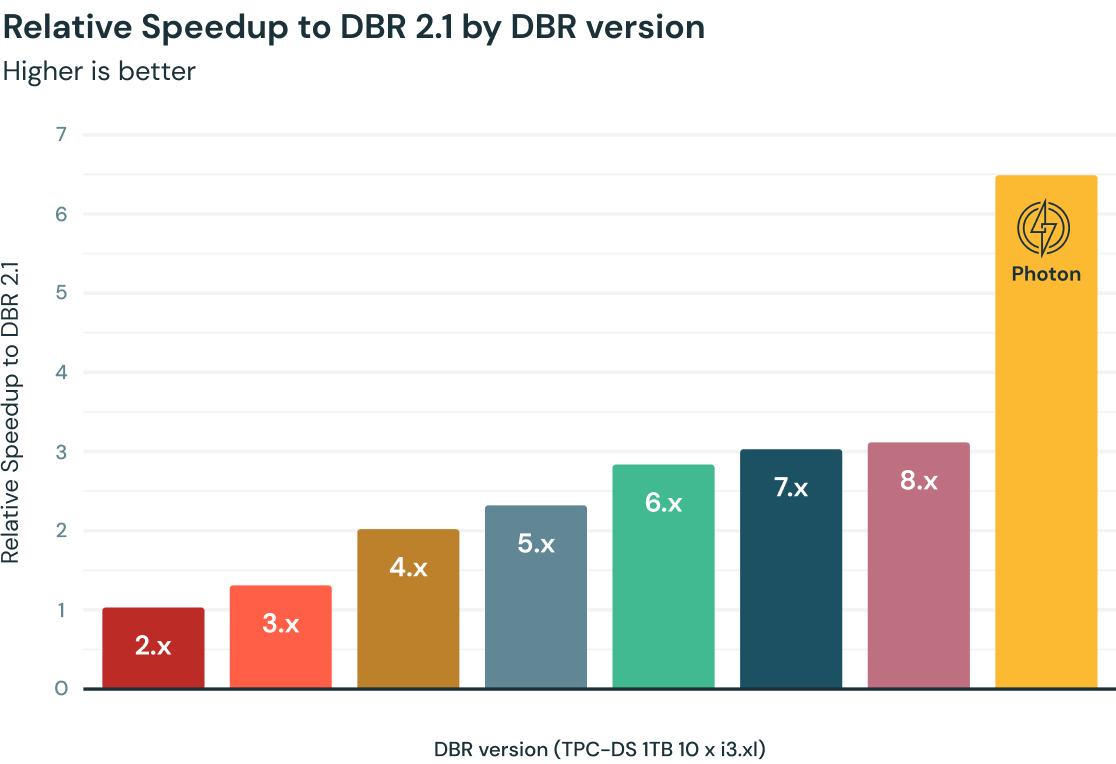
Pourquoi choisir Photon ?
Les performances des requêtes dans Databricks ont régulièrement augmenté au fil des ans, grâce à Apache Spark et aux milliers d'optimisations packagées dans les runtimes Databricks (DBR). Nouveau moteur vectorisé natif, entièrement écrit en C++, Photon multiplie par deux la vitesse d'exécution selon le benchmark TPC-DS 1 To. Sur la base de leurs charges de travail, des clients ont même observé une accélération moyenne de 3 à 8 fois par rapport aux versions précédentes de DBR.
Cas d’utilisation

Production jobs
Accelerate large-scale production jobs on SQL and Spark DataFrames

IoT applications
Faster time-series analysis using Photon compared to Spark and traditional Databricks Runtime

Data privacy and compliance
Query petabyte-scale data sets to identify and delete records without duplicating data with Delta Lake, production jobs and Photon

Loading data into Delta Lake and Parquet
Photon’s vectorized I/O speeds up data loads for Delta Lake and Parquet tables, lowering overall runtime and the cost of data engineering jobs
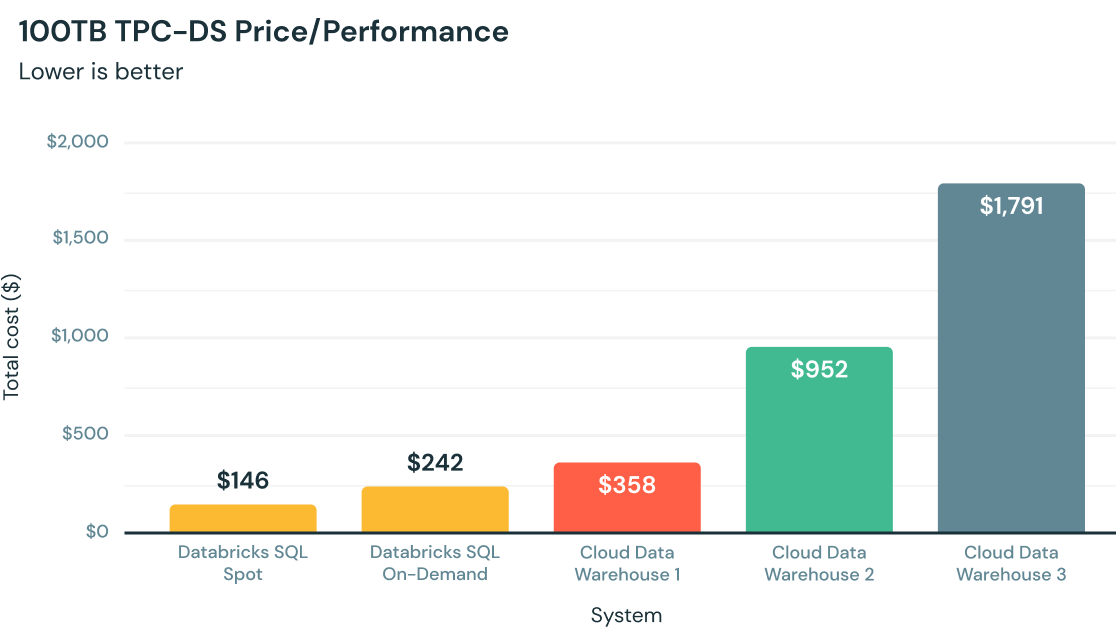
Comment ça marche ?
Le meilleur rapport performance/prix pour l'analytique dans le cloud
Entièrement développé en C++, Photon exploite les performances du matériel moderne pour exécuter les requêtes plus rapidement. Il affiche ainsi un rapport performance/prix jusqu'à 12 fois supérieur à celui des autres data warehouses cloud, directement au sein de votre lac de données.
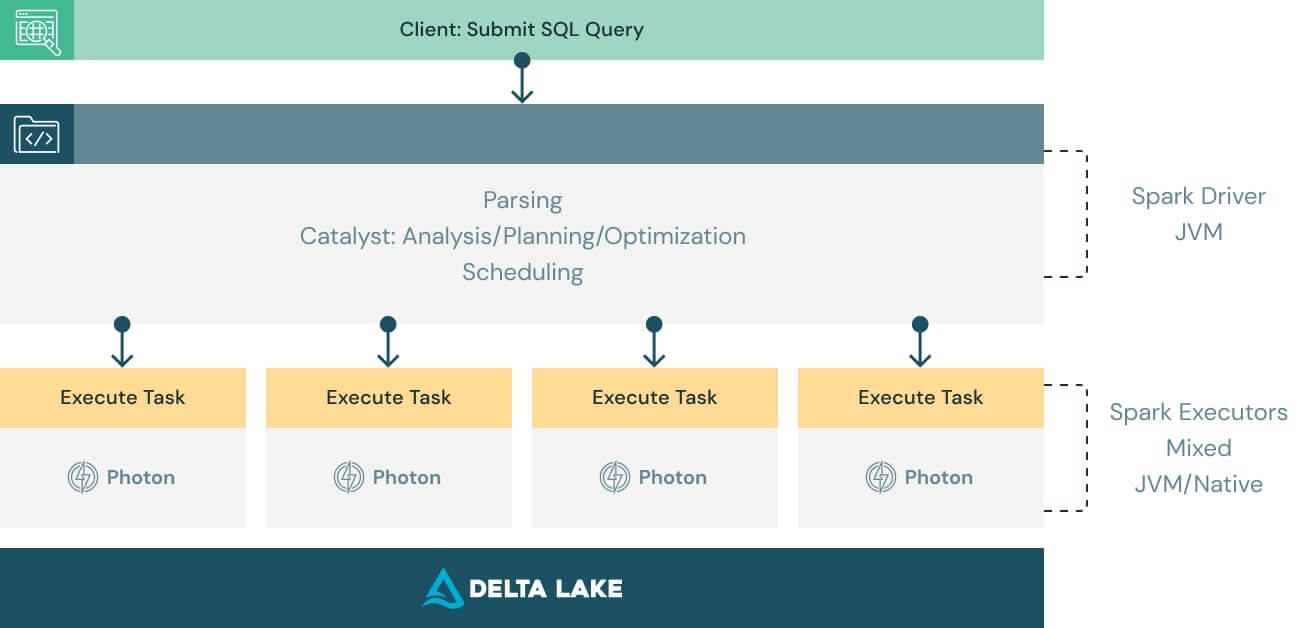
Fonctionne avec votre code actuel et préserve votre indépendance
Photon est conçu pour être compatible avec les API DataFrame Apache Spark et SQL, tout en offrant une exécution transparente des charges de travail, sans aucune modification du code. Pour profiter de la puissance de Photon, il vous suffit de l'activer. Photon coordonne les tâches et les ressources en toute fluidité pour accélérer des portions de vos requêtes SQL et Spark. Sans aucun ajustement ni aucune intervention de l'utilisateur.

Optimisation pour tous les cas d'usage et toutes les charges de données
Au départ, nous avons essentiellement axé Photon sur SQL pour offrir à nos clients des performances d'entreposage des données exceptionnelles sur leur data lakes. Mais depuis, nous avons considérablement élargi le champ des sources d'importation, des formats, des API et des méthodes pris en charge par Photon. Les clients ont ainsi pu profiter d'économies considérables sur les coûts d'infrastructure, ainsi que d'une accélération du traitement de toutes leurs charges de travail Spark (Spark SQL et DataFrame notamment) avec Photon.
Ressources
Ressources
Articles
Événements
Blogs
Prêt à vous lancer?