Administration de l’espace de travail Databricks – Bonnes pratiques pour les administrateurs de compte, d’espace de travail et de métastore
Le récit de trois administrateurs
par Anindita Mahapatra, Mohan Mathews et Greg Wood
Ce blog fait partie de notre série Admin Essentials, où nous abordons des sujets pertinents pour les administrateurs Databricks. D'autres blogs incluent nos Meilleures pratiques d'organisation de l'espace de travail, Stratégies de reprise après sinistre avec Terraform, et bien plus encore ! Gardez un œil sur le nouveau contenu à venir. Dans les blogs précédents axés sur l'administration, nous avons discuté de la manière d'établir et de maintenir une organisation solide de l'espace de travail grâce à une conception préalable et à l'automatisation d'aspects tels que la reprise après sinistre, l'intégration et le déploiement continus (CI/CD) et les vérifications de l'état du système. Un aspect tout aussi important de l'administration est la manière dont vous vous organisez au sein de vos espaces de travail, en particulier lorsqu'il s'agit des nombreux types de personas d'administrateurs qui peuvent exister au sein d'un Lakehouse. Dans ce blog, nous aborderons les considérations administratives de la gestion d'un espace de travail, notamment comment :
- Configurer des politiques et des garde-fous pour pérenniser l'intégration de nouveaux utilisateurs et cas d'utilisation
- Gouverner l'utilisation des ressources
- Assurer un accès aux données autorisé
- Optimiser l'utilisation du calcul pour tirer le meilleur parti de votre investissement
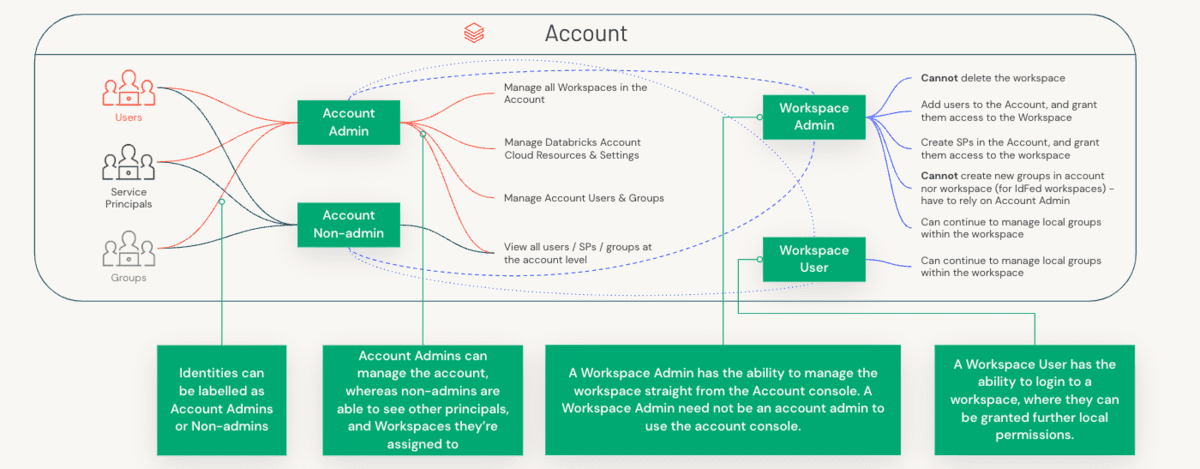
Pour comprendre la répartition des rôles, nous devons d'abord comprendre la distinction entre un administrateur de compte et un administrateur d'espace de travail, ainsi que les composants spécifiques que chacun de ces rôles gère.
Administrateurs de compte vs Administrateurs d'espace de travail vs Administrateurs de metastore
Les préoccupations administratives sont réparties entre les comptes (une construction de haut niveau qui est souvent mappée 1:1 avec votre organisation) et les espaces de travail (un niveau d'isolation plus granulaire qui peut être mappé de diverses manières, par exemple, par unité commerciale). Examinons la séparation des tâches entre ces trois rôles.
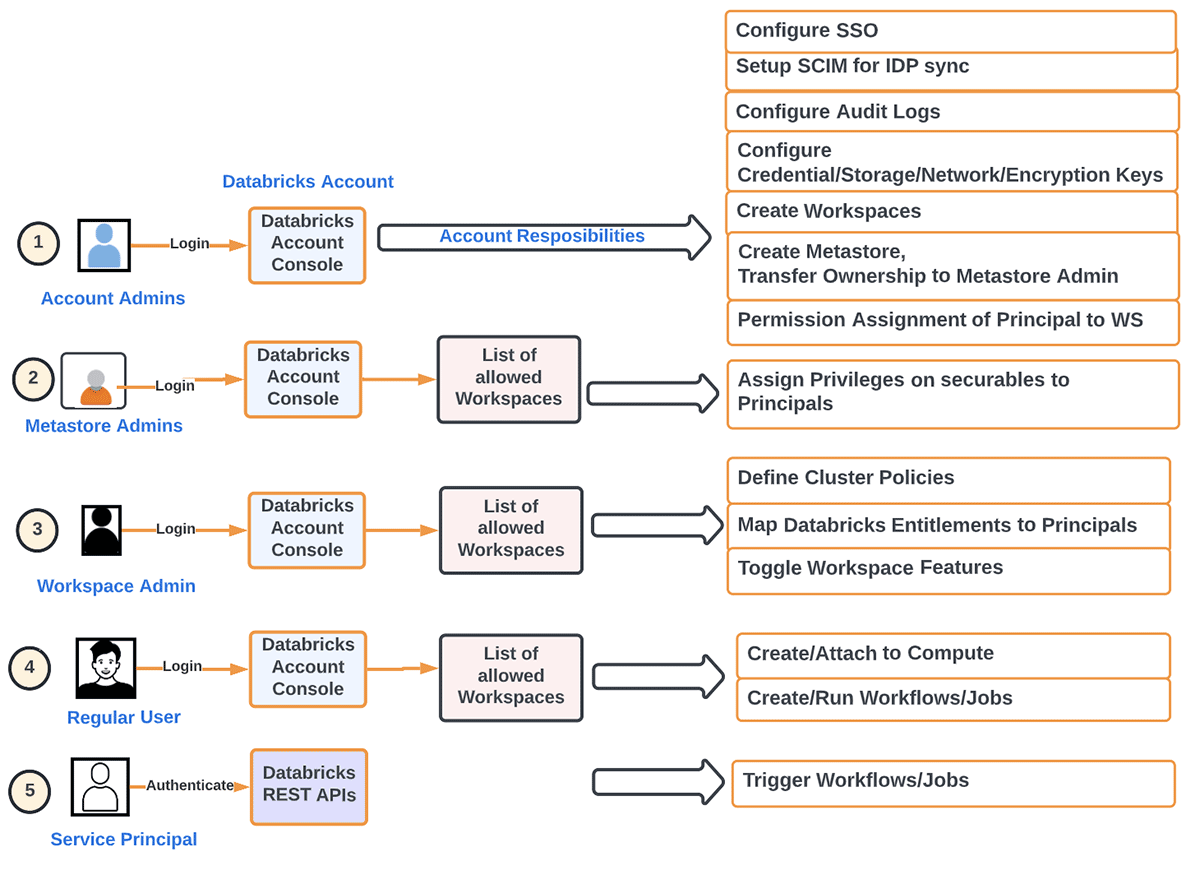
Pour le dire autrement, nous pouvons décomposer les principales responsabilités d'un administrateur de compte comme suit :
- Provisionnement des principaux (groupes/utilisateurs/service) et du SSO au niveau du compte. Fédération d'identité fait référence à l'attribution d'identités de niveau compte à des espaces de travail directement depuis le compte.
- Configuration des metastores
- Configuration du journal d'audit
- Surveillance de l'utilisation au niveau du compte (DBU, facturation)
- Création d'espaces de travail selon la méthode d'organisation souhaitée
- Gestion d'autres objets de niveau espace de travail (stockage, identifiants, réseau, etc.)
- Automatisation des charges de travail de développement à l'aide de l'infrastructure en tant que code (IaaC) pour supprimer l'élément humain dans les charges de travail de production
- Activation/désactivation des fonctionnalités au niveau du compte, telles que les charges de travail serverless, le partage Delta
D'autre part, les principales préoccupations d'un administrateur d'espace de travail sont :
- Attribution des rôles appropriés (utilisateur/administrateur) au niveau de l'espace de travail aux principaux
- Attribution des droits d'accès appropriés (ACL) au niveau de l'espace de travail aux principaux
- Configuration facultative du SSO au niveau de l'espace de travail
- Définition des politiques de cluster pour autoriser les principaux à
- Définir les ressources de calcul (clusters/entrepôts/pools)
- Définir l'orchestration (tâches/pipelines/flux de travail)
- Activation/désactivation des fonctionnalités au niveau de l'espace de travail
- Attribution de droits d'accès aux principaux
- Accès aux données (lors de l'utilisation d'un metastore Hive interne/externe)
- Gérer l'accès des principaux aux ressources de calcul
- Gestion des URL externes pour des fonctionnalités telles que Repos (y compris la liste blanche)
- Contrôle de la sécurité et de la protection des données
- Désactiver/restreindre DBFS pour éviter l'exposition accidentelle de données entre les équipes
- Empêcher le téléchargement des données de résultats (depuis les notebooks/DBSQL) pour éviter l'exfiltration de données
- Activer le contrôle d'accès (objets d'espace de travail, clusters, pools, tâches, tables, etc.)
- Définition de la livraison des journaux au niveau du cluster (par exemple, configuration du stockage pour les journaux de cluster, idéalement via les politiques de cluster)
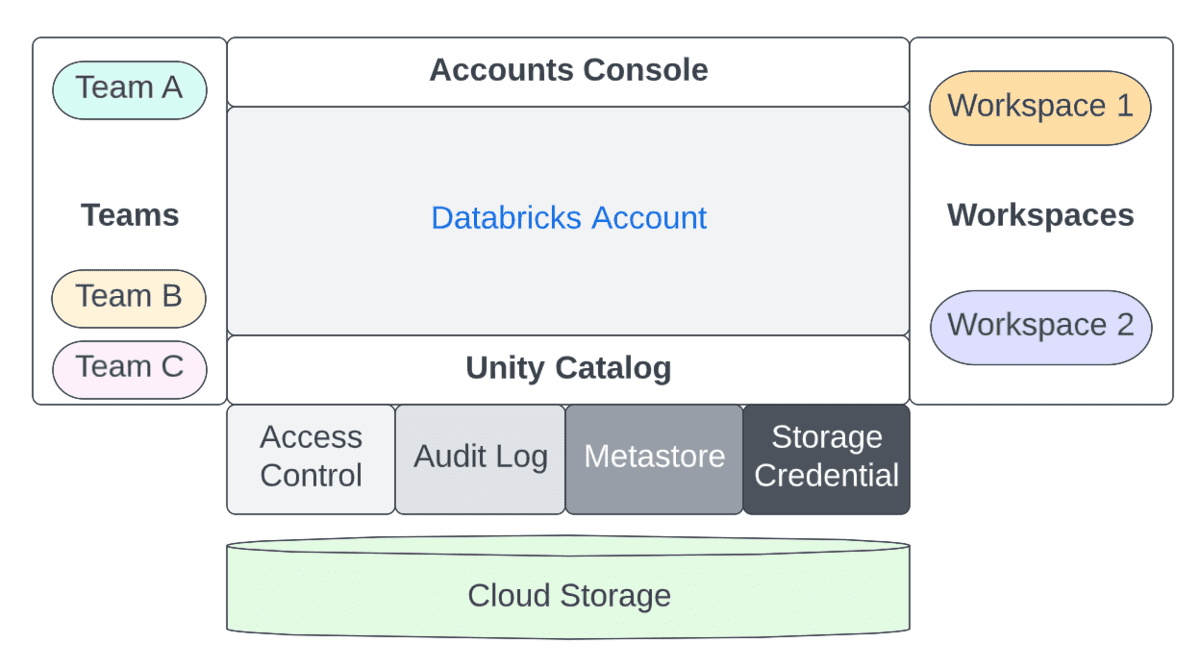
Pour résumer les différences entre l'administrateur de compte et l'administrateur d'espace de travail, le tableau ci-dessous capture la séparation entre ces deux personas pour quelques dimensions clés :
| Administrateur de compte | Administrateur de metastore | Administrateur d'espace de travail | |
|---|---|---|---|
| Gestion de l'espace de travail | - Créer, mettre à jour, supprimer des espaces de travail - Peut ajouter d'autres administrateurs |
Non applicable | - Gère uniquement les actifs au sein d'un espace de travail |
| Gestion des utilisateurs | - Créer des utilisateurs, des groupes et des principaux de service ou utiliser SCIM pour synchroniser les données des fournisseurs d'identité (IDP). - Accorder des droits d'accès aux principaux aux espaces de travail avec l'API d'attribution de permissions |
Non applicable | - Nous recommandons l'utilisation de UC pour la gouvernance centralisée de tous vos actifs de données (sécurisables). La fédération d'identité sera activée pour tout espace de travail lié à un metastore Unity Catalog (UC). - Pour les espaces de travail activés sur la fédération d'identité, configurez SCIM au niveau du compte pour tous les principaux et arrêtez SCIM au niveau de l'espace de travail. - Pour les espaces de travail non-UC, vous pouvez utiliser SCIM au niveau de l'espace de travail (mais ces utilisateurs seront également promus au niveau des identités du compte). - Les groupes créés au niveau de l'espace de travail seront considérés comme des groupes "locaux" de niveau espace de travail et n'auront pas accès à Unity Catalog |
| Accès et gestion des données | - Créer des metastores - Lier des espaces de travail à un metastore - Transférer la propriété du metastore à l'administrateur/groupe de metastore |
Avec Unity Catalog : - Gérer les privilèges sur tous les sécurisables (catalogue, schéma, tables, vues) du metastore - ACCORDER (déléguer) l'accès aux catalogues, schémas (bases de données), tables, vues, emplacements externes et identifiants de stockage aux responsables de données/propriétaires |
- Aujourd'hui, avec les metastores Hive, les clients utilisent une variété de constructions pour protéger l'accès aux données, telles que les profils d'instance sur AWS, les principaux de service dans Azure, les ACL de table, le passage d'identifiants, entre autres. - Avec Unity Catalog, cela est défini au niveau du compte et les GRANTS ANSI seront utilisés pour contrôler l'accès à tous les sécurisables |
| Gestion des clusters | Non applicable | Non applicable | - Créer des clusters pour diverses personas/tailles pour les personas DE/ML/SQL pour les charges de travail S/M/L - Supprimer le droit d'accès allow-cluster-create du groupe users par défaut. - Créer des politiques de cluster, accorder l'accès aux politiques aux groupes appropriés - Donner le droit d'accès Can_Use aux groupes pour les entrepôts SQL |
| Gestion des flux de travail | Non applicable | Non applicable | - S'assurer que les politiques de cluster pour les tâches/DLT/tous usages existent et que les groupes y ont accès - Pré-créer des clusters d'applications que les utilisateurs peuvent redémarrer |
| Gestion du budget | - Définir des budgets par espace de travail/SKU/balises de cluster - Surveiller l'utilisation par balises dans la console des comptes (feuille de route) - Table système d'utilisation facturable à interroger via DBSQL (feuille de route) |
Non applicable | Non applicable |
| Optimiser / Ajuster | Non applicable | Non applicable | - Maximiser le calcul ; Utiliser la dernière version de DBR ; Utiliser Photon - Travailler en collaboration avec les équipes Line Of Business/Center Of Excellence pour suivre les meilleures pratiques et optimisations afin de tirer le meilleur parti de l'investissement infrastructurel |
Dimensionner un espace de travail pour répondre aux besoins de calcul de pointe
Le nombre maximum de nœuds de cluster (indirectement le plus gros travail ou le nombre maximum de travaux simultanés) est déterminé par le nombre maximum d'adresses IP disponibles dans le VPC. Le dimensionnement correct du VPC est donc une considération de conception importante. Chaque nœud utilise 2 adresses IP (sur Azure, AWS). Voici les détails pertinents pour le cloud de votre choix : AWS, Azure, GCP. Nous utiliserons un exemple de Databricks sur AWS pour illustrer cela. Utilisez ceci pour mapper CIDR à IP. La plage CIDR du VPC autorisée pour un espace de travail E2 est /25 - /16. Au moins 2 sous-réseaux privés dans 2 zones de disponibilité différentes doivent être configurés. Les masques de sous-réseau doivent être compris entre /16 et /17. Les VPC sont des unités d'isolation logiques et tant que 2 VPC n'ont pas besoin de communiquer, c'est-à-dire d'être mis en relation, ils peuvent avoir la même plage. Cependant, s'ils le font, il faut veiller à éviter les chevauchements d'adresses IP. Prenons l'exemple d'un VPC avec une plage CIDR /16 :
| Plage CIDR VPC /16 | Nombre max d'IP pour ce VPC : 65 536 | Les clusters à nœud unique/multi-nœuds sont démarrés dans un sous-réseau |
| 2 AZ | Si chaque AZ est /17 : => 32 768 * 2 = 65 536 IP, aucun autre sous-réseau n'est possible | 32 768 IP => maximum de 16 384 nœuds dans chaque sous-réseau |
| Si chaque AZ est /23 à la place : => 512 * 2 = 1 024 IP, 65 536 - 1 024 = 64 512 IP restantes | 512 IP => maximum de 256 nœuds dans chaque sous-réseau | |
| 4 AZ | Si chaque AZ est /18 : 16 384 * 4 = 65 536 IP, aucun autre sous-réseau n'est possible | 16 384 IP => maximum de 8192 nœuds dans chaque sous-réseau |
Équilibrer contrôle et agilité pour les administrateurs d'espace de travail
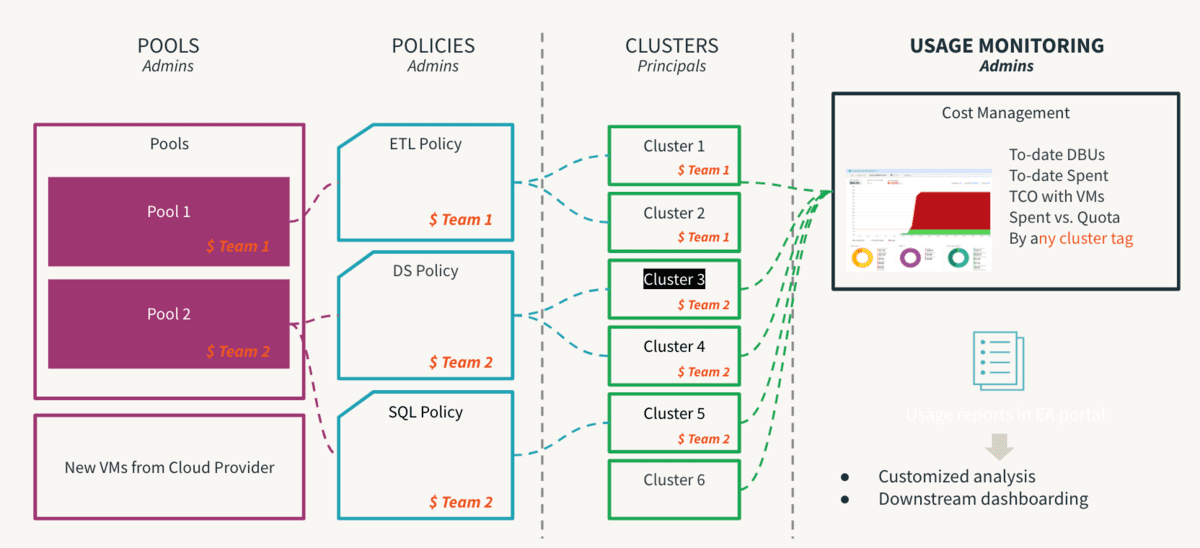
Le calcul est le composant le plus coûteux de tout investissement dans l'infrastructure cloud. La démocratisation des données mène à l'innovation et la facilitation du libre-service est la première étape vers l'autonomisation d'une culture axée sur les données. Cependant, dans un environnement multi-locataire, un utilisateur inexpérimenté ou une erreur humaine involontaire pourrait entraîner des coûts incontrôlables ou une exposition involontaire. Si les contrôles sont trop stricts, cela créera des goulots d'étranglement d'accès et étouffera l'innovation. Les administrateurs doivent donc définir des garde-fous pour permettre le libre-service sans les risques inhérents. De plus, ils devraient être en mesure de surveiller le respect de ces contrôles. C'est là que les Politiques de Cluster sont utiles, où les règles sont définies et les droits mappés afin que l'utilisateur opère dans des périmètres autorisés et que son processus de prise de décision soit grandement simplifié. Il convient de noter que les politiques doivent être soutenues par un processus pour être vraiment efficaces, de sorte que les exceptions ponctuelles puissent être gérées par le processus pour éviter un chaos inutile. Une étape critique de ce processus consiste à supprimer le droit allow-cluster-create du groupe users par défaut dans un espace de travail afin que les utilisateurs ne puissent utiliser que le calcul régi par les Politiques de Cluster. Les recommandations suivantes sont les meilleures pratiques pour les Politiques de Cluster et peuvent être résumées comme suit :
- Utiliser des tailles de T-shirt pour fournir des modèles de cluster standard
- Par taille de charge de travail (petite, moyenne, grande)
- Par persona (DE/ ML/ BI)
- Par niveau de compétence (citoyen/avancé)
- Gérer la gouvernance en imposant l'utilisation de
- Tags : attribution par équipe, utilisateur, cas d'utilisation
- la dénomination doit être standardisée
- rendre certains attributs obligatoires aide à obtenir des rapports cohérents
- Tags : attribution par équipe, utilisateur, cas d'utilisation
- Contrôler la consommation en limitant
- Taux de consommation DBU et objectif de la politique
- Délai d'arrêt automatique, taille minimale/maximale de mise à l'échelle
Considérations relatives au calcul
Contrairement à l'infrastructure de calcul fixe sur site, le cloud nous offre à la fois l'élasticité et la flexibilité nécessaires pour faire correspondre le bon calcul à la charge de travail et au SLA considérés. Le schéma ci-dessous présente les différentes options. Les entrées sont des paramètres tels que le type de charge de travail ou d'environnement, et la sortie est le type et la taille du calcul qui convient le mieux.
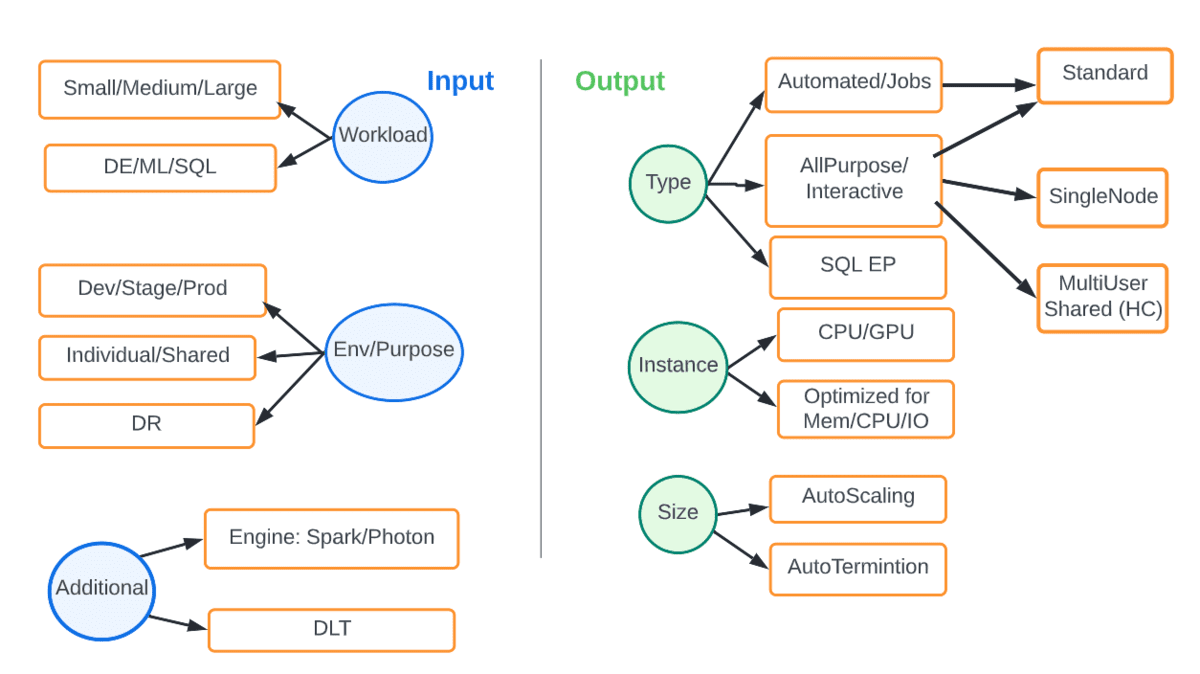
Par exemple, une charge de travail de Data Engineering (DE) en production doit toujours être exécutée sur des clusters de tâches automatisés, de préférence avec la dernière version de DBR, avec mise à l'échelle automatique et en utilisant le moteur Photon. Le tableau ci-dessous présente quelques scénarios courants.
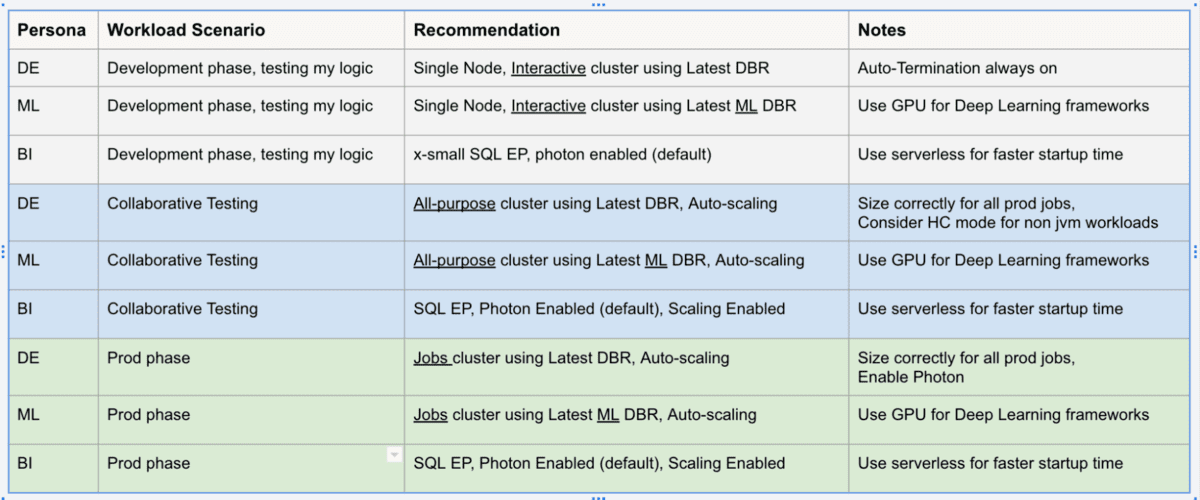
Considérations relatives aux flux de travail
Maintenant que les besoins en calcul ont été formalisés, nous devons examiner :
- Comment les flux de travail seront définis et déclenchés
- Comment les tâches peuvent réutiliser le calcul entre elles
- Comment les dépendances des tâches seront gérées
- Comment les tâches échouées pourront être retentées
- Comment les mises à niveau de version (Spark, bibliothèque) et les correctifs sont appliqués
Ce sont des considérations de Data Engineering et DevOps qui sont centrées sur le cas d'utilisation et relèvent généralement directement d'un administrateur. Il existe des tâches d'hygiène qui peuvent être surveillées, telles que :
- Un espace de travail a une limite maximale sur le nombre total de travaux configurés. Mais beaucoup de ces travaux peuvent ne pas être invoqués et doivent être nettoyés pour faire place à des travaux légitimes. Un administrateur peut effectuer des vérifications pour déterminer la liste d'éviction valide des travaux défunts.
- Tous les travaux de production doivent être exécutés en tant que principal de service et l'accès utilisateur à un environnement de production doit être très restreint. Examinez les permissions des travaux.
- Les travaux peuvent échouer, donc chaque travail doit être configuré pour des alertes d'échec et éventuellement pour des tentatives. Examinez les propriétés email_notifications, max_retries et autres ici
- Chaque travail doit être associé à des politiques de cluster et correctement tagué pour l'attribution.
DLT : Exemple de framework idéal pour des pipelines fiables à grande échelle
En travaillant avec des milliers de clients, grands et petits, dans différents secteurs d'activité, des défis communs en matière de données pour le développement et l'opérationnalisation sont devenus apparents, c'est pourquoi Databricks a créé Delta Live Tables (DLT). Il s'agit d'une offre de plateforme gérée visant à simplifier le développement et la maintenance des charges de travail ETL en permettant la création de pipelines déclaratifs où vous spécifiez le 'quoi' et non le 'comment'. Cela simplifie les tâches d'un ingénieur de données, entraînant moins de scénarios de support pour les administrateurs.
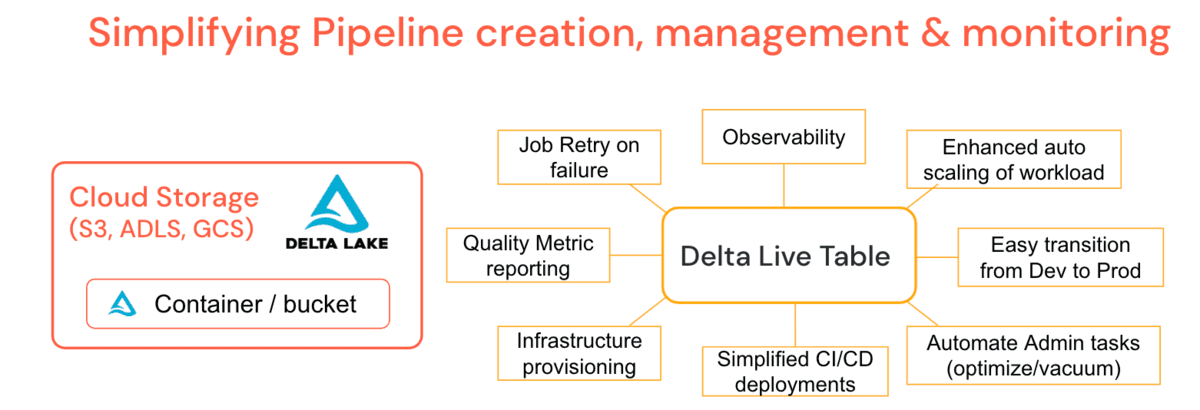
DLT intègre des fonctionnalités d'administration courantes telles que les tâches périodiques d'*optimize* & *vacuum* directement dans la définition du pipeline avec une tâche de maintenance qui garantit leur exécution sans surveillance supplémentaire. DLT offre une observabilité approfondie des pipelines pour des opérations simplifiées telles que la lignée, la surveillance et les vérifications de la qualité des données. Par exemple, si le cluster se termine, la plateforme réessaie automatiquement (en mode Production) au lieu de s'appuyer sur l'ingénieur de données pour l'avoir provisionné explicitement. L'Auto-Scaling amélioré peut gérer les pics de données soudains qui nécessitent une augmentation de la taille du cluster et une réduction progressive. En d'autres termes, la mise à l'échelle automatique des clusters et la tolérance aux pannes des pipelines sont une fonctionnalité de la plateforme. Les latences de table tournante vous permettent d'exécuter des pipelines en mode batch ou streaming et de passer facilement des pipelines de développement à la production en gérant la configuration plutôt que le code. Vous pouvez contrôler le coût de vos pipelines en utilisant les politiques de cluster spécifiques à DLT. DLT met également à jour automatiquement votre moteur d'exécution, retirant ainsi la responsabilité des administrateurs ou des ingénieurs de données, et vous permettant de vous concentrer uniquement sur la génération de valeur commerciale.
UC : Exemple de framework idéal de gouvernance des données
Unity Catalog (UC) permet aux organisations d'adopter un modèle de sécurité commun pour les tables et les fichiers pour tous les espaces de travail sous un seul compte, ce qui n'était pas possible auparavant par de simples instructions GRANT. En accordant et en auditant tous les accès aux données, tables ou fichiers, depuis un cluster DE/DS ou un entrepôt SQL, les organisations peuvent simplifier leur stratégie d'audit et de surveillance sans dépendre des primitives par cloud. Les principales capacités offertes par UC incluent :
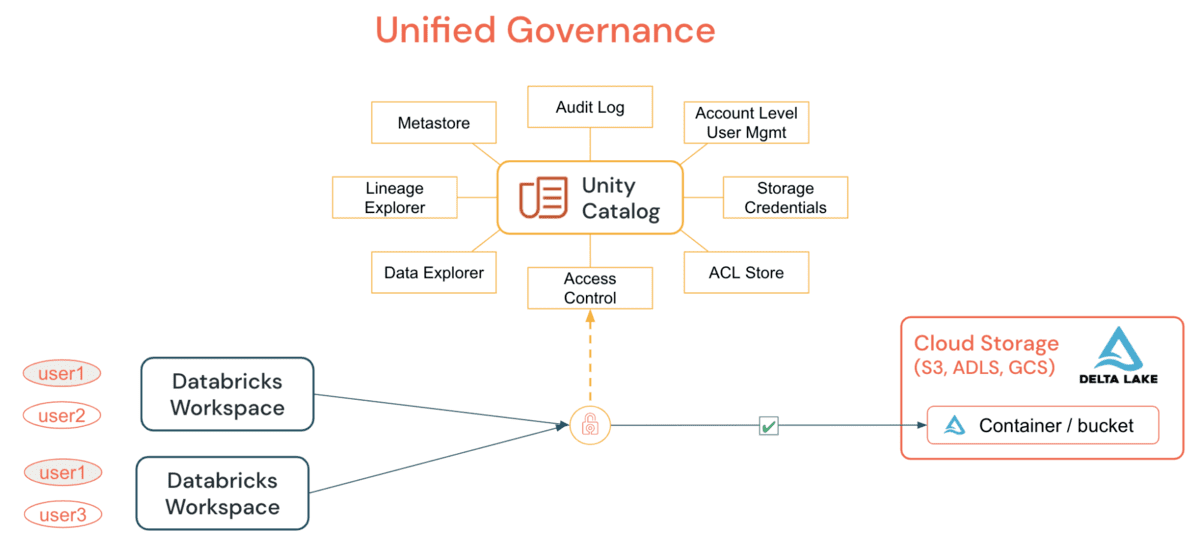
UC simplifie le travail d'un administrateur (aux niveaux du compte et de l'espace de travail) en centralisant les définitions, la surveillance et la découvrabilité des données dans le metastore, et en facilitant le partage sécurisé des données quel que soit le nombre d'espaces de travail qui y sont connectés. En utilisant le modèle Définir une fois, Sécuriser partout, cela présente l'avantage supplémentaire d'éviter l'exposition accidentelle des données dans le cas où les privilèges d'un utilisateur seraient involontairement mal représentés dans un espace de travail, ce qui pourrait lui donner une porte dérobée pour accéder à des données qui ne lui étaient pas destinées. Tout cela peut être accompli facilement en utilisant les Identités au niveau du compte et les Permissions sur les données. La journalisation d'audit UC permet une visibilité complète sur toutes les actions de tous les utilisateurs à tous les niveaux sur tous les objets, et si vous configurez la journalisation d'audit détaillée, alors chaque commande exécutée, depuis un notebook ou Databricks SQL, est capturée. L'accès aux éléments sécurisables peut être accordé par un administrateur de metastore, le propriétaire d'un objet, ou le propriétaire du catalogue ou du schéma contenant l'objet. Il est recommandé que l'administrateur au niveau du compte délègue le rôle de metastore en nommant un groupe comme administrateurs de metastore dont le seul but est d'accorder les bons privilèges.
Recommandations et meilleures pratiques
- Les rôles et responsabilités des administrateurs de compte, des administrateurs de metastore et des administrateurs d'espace de travail sont bien définis et complémentaires. Les flux de travail tels que l'automatisation, les demandes de changement, les escalades, etc. devraient être dirigés vers les propriétaires appropriés, que les espaces de travail soient configurés par une unité commerciale ou gérés par un centre d'excellence centralisé.
- Les Identités au niveau du compte doivent être activées car cela permet une gestion centralisée des principaux pour tous les espaces de travail, simplifiant ainsi l'administration. Nous recommandons de configurer des fonctionnalités telles que le SSO, le SCIM et les journaux d'audit au niveau du compte. Le SSO au niveau de l'espace de travail est toujours requis, jusqu'à ce que la fonctionnalité de fédération SSO soit disponible.
- Les Politiques de cluster sont un levier puissant qui fournit des garde-fous pour un libre-service efficace et simplifie grandement le rôle d'un administrateur d'espace de travail. Nous fournissons des exemples de politiques ici. L'administrateur du compte doit fournir des politiques par défaut simples basées sur le persona principal/la taille, idéalement par le biais de l'automatisation telle que Terraform. Les administrateurs d'espace de travail peuvent ajouter à cette liste pour des contrôles plus précis. Combiné à un processus adéquat, tous les scénarios d'exception peuvent être gérés avec succès.
- Le suivi de la consommation en cours pour tous les types de charges de travail dans tous les espaces de travail est visible par les administrateurs de compte via la console des comptes. Nous recommandons de configurer la livraison des journaux d'utilisation facturable afin que tout soit envoyé vers votre stockage cloud central pour la refacturation et l'analyse. L'API Budget (en aperçu) doit être configurée au niveau du compte, ce qui permet aux administrateurs de compte de créer des seuils au niveau des espaces de travail, des SKU et des balises de cluster, et de recevoir des alertes sur la consommation afin que des mesures rapides puissent être prises pour rester dans les budgets alloués. Utilisez un outil tel que Overwatch pour suivre l'utilisation à un niveau encore plus granulaire afin d'identifier les domaines d'amélioration en matière d'utilisation des ressources de calcul.
- La plateforme Databricks continue d'innover et de simplifier le travail des différentes personas de données en abstrayant les fonctionnalités d'administration courantes dans la plateforme. Notre recommandation est d'utiliser Delta Live Tables pour les nouveaux pipelines et Unity Catalog pour toute votre gestion des utilisateurs et le contrôle d'accès aux données.
Enfin, il est important de noter que pour la plupart de ces bonnes pratiques, et en fait, la plupart des choses que nous mentionnons dans ce blog, la coordination et le travail d'équipe sont primordiaux pour le succès. Bien qu'il soit théoriquement possible pour les administrateurs de compte et d'espace de travail d'exister en vase clos, cela va non seulement à l'encontre des principes généraux du Lakehouse, mais complique la vie de toutes les personnes impliquées. La suggestion la plus importante à retenir de cet article est peut-être de connecter les administrateurs de compte/d'espace de travail + les chefs de projet/données + les utilisateurs au sein de votre propre organisation. Des mécanismes tels qu'un canal Teams/Slack, une liste de diffusion par alias d'e-mail et/ou une réunion hebdomadaire ont fait leurs preuves. Les organisations les plus efficaces que nous observons ici chez Databricks sont celles qui adoptent l'ouverture non seulement dans leur technologie, mais aussi dans leurs opérations. Gardez un œil sur les prochains blogs axés sur les administrateurs, des recommandations de journalisation et d'exfiltration aux résumés passionnants de nos fonctionnalités de plateforme axées sur la gestion.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.