Création de produits de données géospatiales
par Milos Colic
Ce blog est obsolète. Veuillez consulter ce blog sur Spatial SQL pour des approches à jour sur le stockage et le traitement des données géospatiales au sein de votre Databricks Lakehouse.
Les données géospatiales sont un moteur d'innovation depuis des siècles, grâce à l'utilisation des cartes, de la cartographie et, plus récemment, du contenu numérique. Par exemple, la plus ancienne carte connue a été gravée sur un morceau de défense de mammouth et date d'environ 25000 av. J.-C. Cela fait des données géospatiales l'une des plus anciennes sources de données utilisées par la société pour prendre des décisions. Un exemple plus récent, considéré comme la naissance de l'analyse spatiale, est celui de Charles Picquet en 1832 qui a utilisé des données géospatiales pour analyser les épidémies de choléra à Paris. Quelques décennies plus tard, John Snow en 1854 a suivi la même approche pour les épidémies de choléra à Londres. Ces deux individus ont utilisé des données géospatiales pour résoudre l'un des problèmes les plus difficiles de leur époque et, par conséquent, sauver d'innombrables vies. En accélérant jusqu'au 20e siècle, le concept des systèmes d'information géographique (SIG) a été introduit pour la première fois en 1967 à Ottawa, Canada, par le ministère des Forêts et du Développement rural.
Aujourd'hui, nous sommes au milieu de la révolution de l'industrie du cloud computing - une échelle de supercalcul disponible pour toute organisation, virtuellement infiniment évolutive pour le stockage et le calcul. Des concepts tels que le data mesh et le data marketplace émergent au sein de la communauté des données pour répondre à des questions telles que la fédération de plateformes et l'interopérabilité. Comment pouvons-nous adopter ces concepts pour les données géospatiales, l'analyse spatiale et les systèmes SIG ? En adoptant le concept de produits de données et en abordant la conception des données géospatiales comme un produit.
Dans ce blog, nous présenterons un point de vue sur la manière de concevoir des produits de données géospatiales évolutifs, modernes et robustes. Nous discuterons de la manière dont la plateforme Databricks Lakehouse peut être utilisée pour libérer tout le potentiel des produits géospatiaux, qui sont l'un des atouts les plus précieux pour résoudre les problèmes les plus difficiles d'aujourd'hui et de demain.
Qu'est-ce qu'un produit de données ? Et comment en concevoir un ?
La définition la plus large et la plus concise d'un « produit de données » a été formulée par DJ Patil (le premier scientifique en chef des données des États-Unis) dans Data Jujitsu: The Art of Turning Data into Product : « un produit qui facilite un objectif final grâce à l'utilisation des données ». La complexité de cette définition (comme l'a admis Patil lui-même) est nécessaire pour englober la diversité des produits possibles, pour inclure les tableaux de bord, les rapports, les feuilles de calcul Excel, et même les extraits CSV partagés par e-mail. Vous remarquerez peut-être que les exemples fournis se détériorent rapidement en termes de qualité, de robustesse et de gouvernance.
Quels sont les concepts qui différencient un produit réussi d'un produit non réussi ? Est-ce l'emballage ? Est-ce le contenu ? Est-ce la qualité du contenu ? Ou est-ce seulement l'adoption du produit sur le marché ? Forbes définit les 10 qualités indispensables d'un produit réussi. Un bon cadre pour résumer cela est la pyramide de valeur.
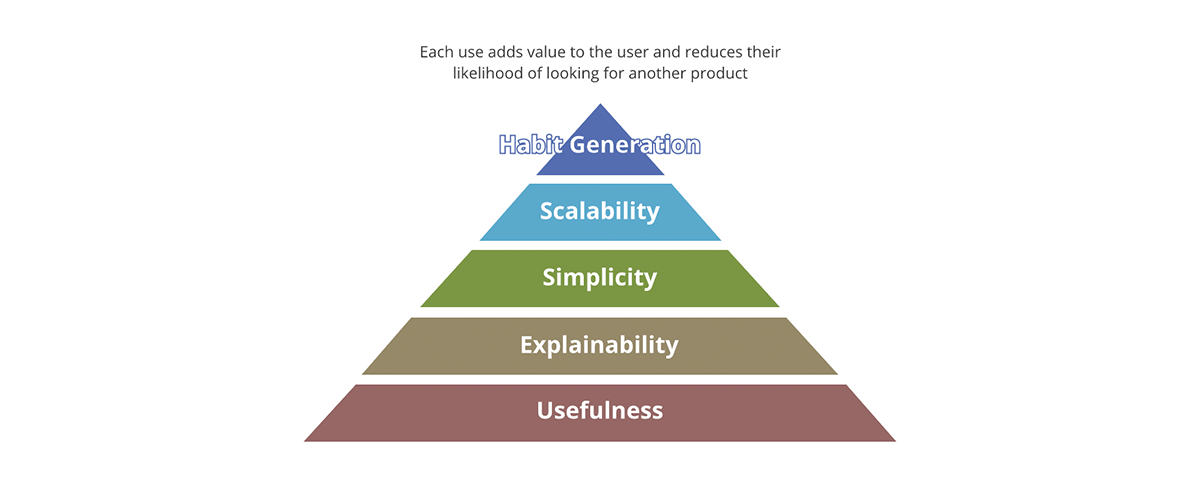
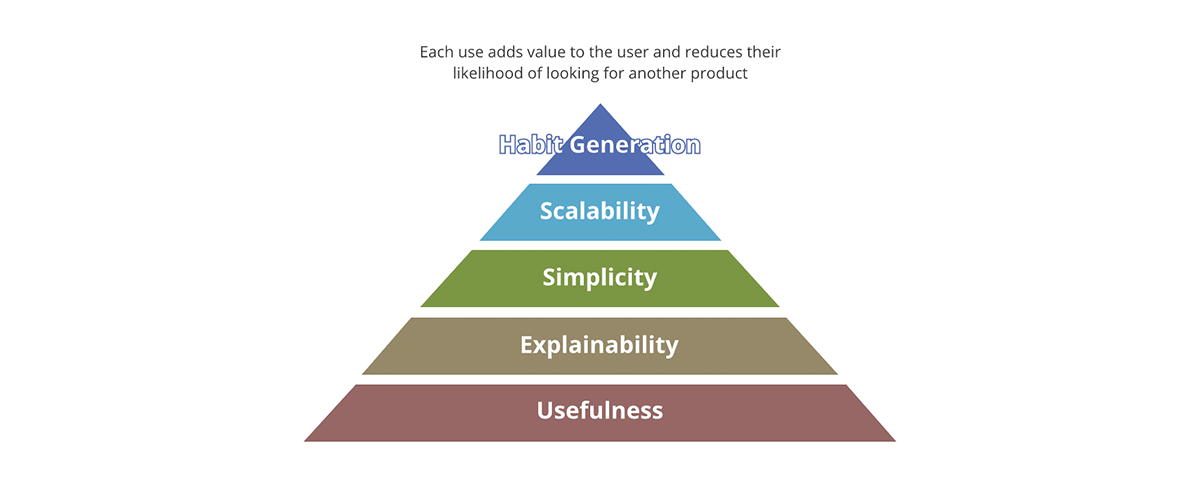{kind=link}
La pyramide de valeur donne une priorité à chaque aspect du produit. Toutes les questions de valeur que nous posons sur le produit n'ont pas le même poids. Si le résultat n'est pas utile, aucun des autres aspects n'a d'importance - le résultat n'est pas vraiment un produit mais devient plutôt un polluant de données dans le pool de résultats utiles. De même, la scalabilité n'a d'importance qu'une fois que la simplicité et l'explicabilité ont été abordées.
Comment la pyramide de valeur se rapporte-t-elle aux produits de données ? Chaque sortie de données, pour être un produit de données :
- Doit avoir une utilité claire. La quantité de données que la société génère n'a d'égale que la quantité de polluants de données que nous générons. Ce sont des sorties manquant de valeur et d'utilité claires, encore moins une stratégie sur ce qu'il faut en faire.
- Doit être explicable. Avec l'émergence de l'IA/ML, l'explicabilité est devenue encore plus importante pour la prise de décision basée sur les données. Les données ne valent que par les métadonnées qui les décrivent. Pensez-y en termes de nourriture - le goût est important, mais un facteur plus important est la valeur nutritionnelle des ingrédients.
- Doit être simple. Un exemple de mauvaise utilisation d'un produit est d'utiliser une fourchette pour manger des céréales au lieu d'une cuillère. De plus, la simplicité est essentielle mais pas suffisante ; au-delà de la simplicité, les produits doivent être intuitifs. Chaque fois que possible, les utilisations prévues et imprévues des données doivent être évidentes.
- Doit être évolutive. Les données sont l'une des rares ressources qui croissent avec l'utilisation. Plus vous traitez de données, plus vous avez de données. Si les entrées et les sorties du système sont illimitées et en croissance constante, le système doit être évolutif en termes de puissance de calcul, de capacité de stockage et de puissance d'expression de calcul. Les plateformes de données cloud comme Databricks sont dans une position unique pour répondre à ces trois aspects.
- Doit générer des habitudes. Dans le domaine des données, nous ne nous préoccupons pas de la fidélisation de la clientèle comme c'est le cas pour les produits de détail. Cependant, la valeur de la génération d'habitudes est évidente si elle est appliquée aux meilleures pratiques. Les systèmes et les sorties de données doivent présenter les meilleures pratiques et les promouvoir - il doit être plus facile d'utiliser les données et le système de la manière prévue que le contraire.
Les données géospatiales doivent adhérer à tous les aspects susmentionnés, tout comme tout produit de données. En plus de cette tâche ardue, les données géospatiales ont des besoins spécifiques.
Normes relatives aux données géospatiales
Les normes relatives aux données géospatiales sont utilisées pour garantir que les données géographiques sont collectées, organisées et partagées de manière cohérente et fiable. Ces normes peuvent inclure des directives pour le formatage des données, les systèmes de coordonnées, les projections cartographiques et les métadonnées. Le respect des normes facilite le partage des données entre différentes organisations, permettant une plus grande collaboration et un accès plus large aux informations géographiques.
La Geospatial Commission (Gouvernement britannique) a défini le Registre national des normes de données géospatiales du Royaume-Uni comme un référentiel central pour les normes de données à appliquer dans le cas des données géospatiales. De plus, la mission de ce registre est de :
- « Garantir que les données géospatiales du Royaume-Uni sont plus cohérentes, harmonisées et utilisables dans un plus large éventail de systèmes. » - Ces concepts soulignent l'importance de l'explicabilité, de l'utilité et de la génération d'habitudes (potentiellement d'autres aspects de la pyramide de valeur).
- « Permettre à la communauté géospatiale du Royaume-Uni de s'engager davantage avec les normes et les organismes de normalisation pertinents. » - La génération d'habitudes au sein de la communauté est aussi importante que la conception robuste et critique de la norme. Si elles ne sont pas adoptées, les normes sont inutiles.
- « Promouvoir la compréhension et l'utilisation des normes de données géospatiales dans d'autres secteurs du gouvernement. » - La pyramide de valeur s'applique également aux normes - des concepts tels que la facilité d'adhésion (utilité/simplicité), le but de la norme (explicabilité/utilité), l'adoption (génération d'habitudes) sont essentiels à la génération de valeur d'une norme.
Un outil essentiel pour atteindre la mission des normes de données est les principes des données FAIR :
- Facile à trouver (Findable) - La première étape pour (ré)utiliser des données est de les trouver. Les métadonnées et les données doivent être faciles à trouver pour les humains et les ordinateurs. Les métadonnées lisibles par machine sont essentielles à la découverte automatique des jeux de données et des services.
- Accessible - Une fois que l'utilisateur trouve les données requises, il doit savoir comment y accéder, y compris éventuellement l'authentification et l'autorisation.
- Intéroperable - Les données doivent généralement être intégrées à d'autres données. De plus, les données doivent être interopérables avec des applications ou des workflows pour l'analyse, le stockage et le traitement.
- Réutilisable - L'objectif ultime de FAIR est d'optimiser la réutilisation des données. Pour ce faire, les métadonnées et les données doivent être bien décrits afin qu'ils puissent être répliqués et/ou combinés dans différents contextes.
Nous partageons la conviction que les principes FAIR sont cruciaux pour la conception de produits de données scalables auxquels nous pouvons faire confiance. Pour être juste, FAIR repose sur le bon sens, alors pourquoi est-il essentiel à nos considérations ? "Ce que je vois dans FAIR n'est pas nouveau en soi, mais ce qu'il fait bien, c'est d'articuler, d'une manière accessible, le besoin d'une approche holistique de l'amélioration des données. Cette facilité de communication est la raison pour laquelle FAIR est de plus en plus utilisé comme un parapluie pour l'amélioration des données - et pas seulement dans la communauté géospatiale." - A FAIR wind sets our course for data improvement.
Pour soutenir davantage cette approche, le Federal Geographic Data Committee a développé le National Spatial Data Infrastructure (NSDI) Strategic Plan qui couvre les années 2021-2024 et a été approuvé en novembre 2020. Les objectifs du NSDI sont essentiellement les principes FAIR et transmettent le même message de conception de systèmes qui favorisent l'économie circulaire des données - des produits de données qui circulent entre les organisations en suivant des normes communes et à chaque étape de la chaîne d'approvisionnement des données débloquent une nouvelle valeur et de nouvelles opportunités. Le fait que ces principes imprègnent différentes juridictions et soient adoptés par différents régulateurs témoigne de la robustesse et de la solidité de l'approche.

{kind=link}
Les concepts FAIR s'intègrent très bien à la conception des produits de données. En fait, FAIR traverse toute la pyramide de valeur du produit et forme un cycle de valeur. En adoptant à la fois la pyramide de valeur et les principes FAIR, nous concevons des produits de données avec une perspective interne et externe. Cela favorise la réutilisation des données par opposition à l'accumulation de données.
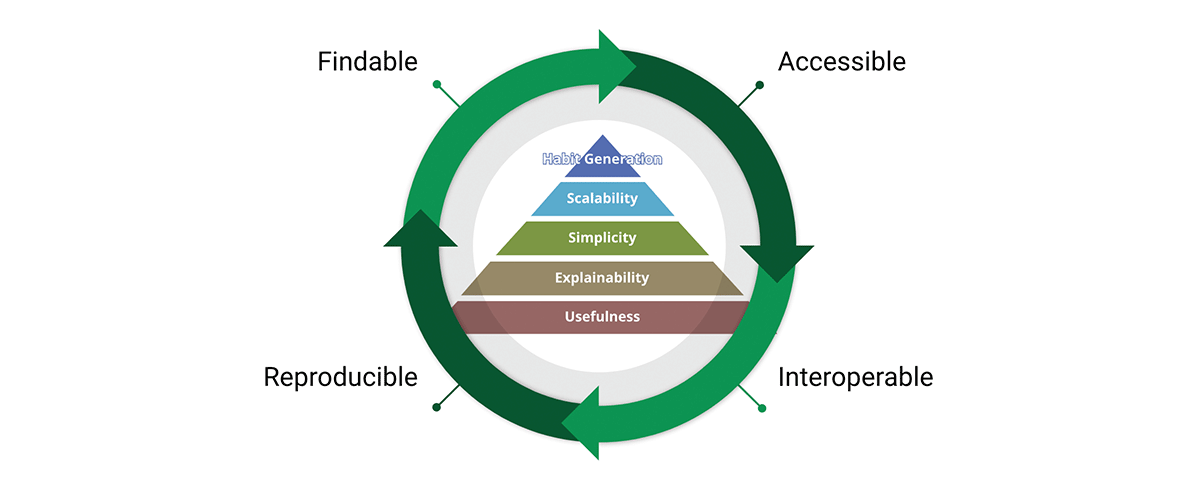
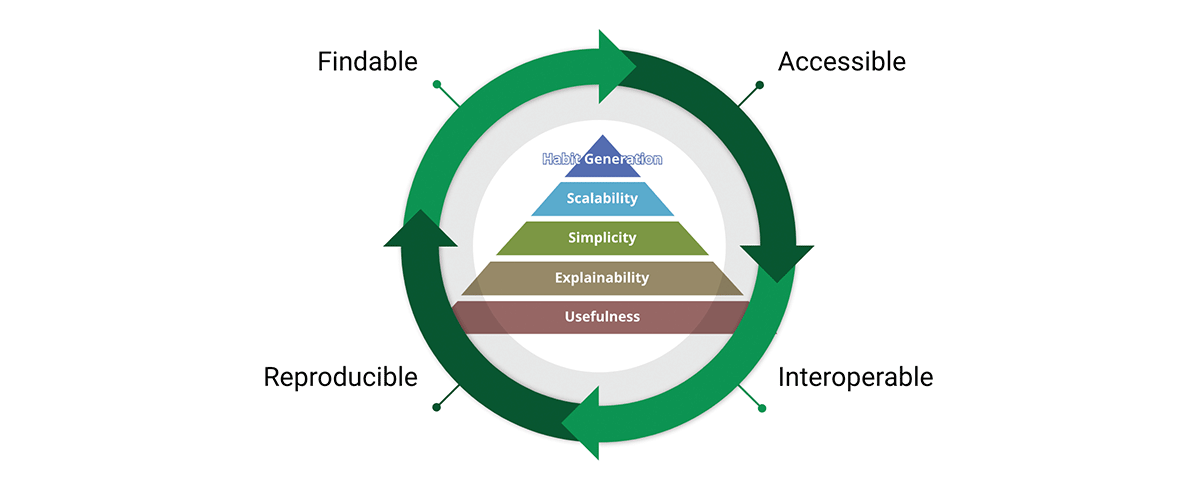{kind=link}
Pourquoi les principes FAIR sont-ils importants pour les données géospatiales et les produits de données géospatiales ? FAIR transcende les données géospatiales, il transcende en fait les données, c'est un système simple mais cohérent de principes directeurs pour une bonne conception - et cette bonne conception peut être appliquée à n'importe quoi, y compris aux données géospatiales et aux systèmes géospatiaux.
Systèmes d'indexation par grille
Dans les solutions SIG traditionnelles, la performance des opérations spatiales est généralement obtenue en construisant des structures arborescentes (arbres KD, arbres à boules, arbres quadtree, etc.). Le problème avec les approches arborescentes est qu'elles finissent par violer le principe de scalabilité - lorsque les données sont trop volumineuses pour être traitées afin de construire l'arbre et que le calcul requis pour construire l'arbre est trop long et va à l'encontre de l'objectif. Cela affecte également négativement l'accessibilité des données, si nous ne pouvons pas construire l'arbre, nous ne pouvons pas accéder à l'ensemble des données et, par conséquent, nous ne pouvons pas reproduire les résultats. Dans ce cas, les systèmes d'indexation par grille offrent une solution.
Les systèmes d'indexation par grille sont construits dès le départ en tenant compte des aspects de scalabilité des données géospatiales. Plutôt que de construire des arbres, ils définissent une série de grilles qui couvrent la zone d'intérêt. Dans le cas de H3 (pionnier par Uber), la grille couvre la zone de la Terre, dans le cas des systèmes d'indexation par grille locaux (par exemple, le British National Grid), ils peuvent seulement couvrir la zone d'intérêt spécifique. Ces grilles sont composées de cellules qui ont des identifiants uniques. Il existe une relation mathématique entre la localisation et la cellule dans la grille. Cela rend les systèmes d'indexation par grille très scalables et de nature parallèle.
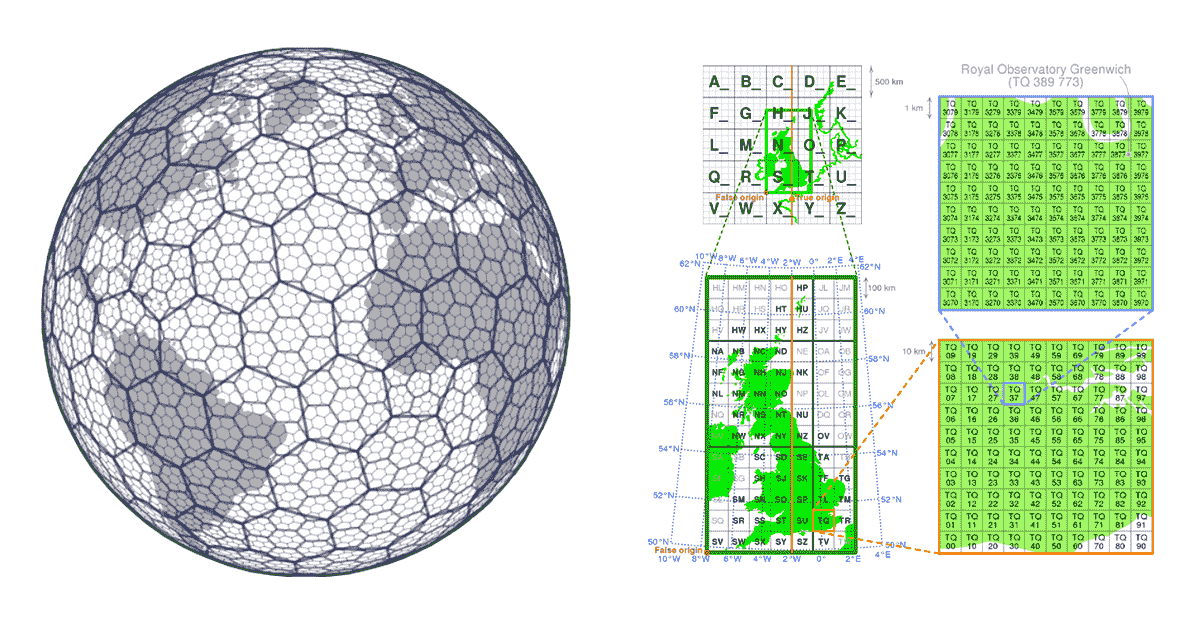
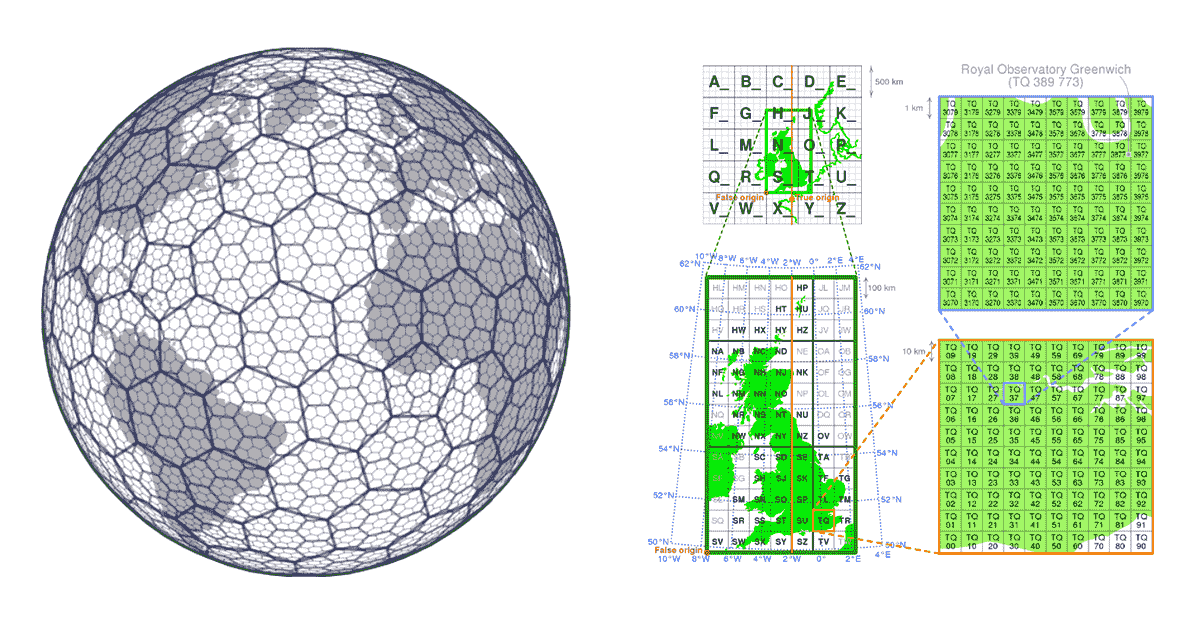{kind=link}
Un autre aspect important des systèmes d'indexation par grille est qu'ils sont open source, permettant aux valeurs d'index d'être universellement exploitées par les producteurs et les consommateurs de données. Les données peuvent être enrichies avec les informations d'index de grille à n'importe quelle étape de leur parcours dans la chaîne d'approvisionnement des données. Cela fait des systèmes d'indexation par grille un exemple de normes de données pilotées par la communauté. Les normes de données pilotées par la communauté ne nécessitent par nature aucune application forcée, ce qui adhère pleinement à l'aspect de génération d'habitudes de la pyramide de valeur et aborde de manière significative les principes d'interopérabilité et d'accessibilité de FAIR.
{kind=link}
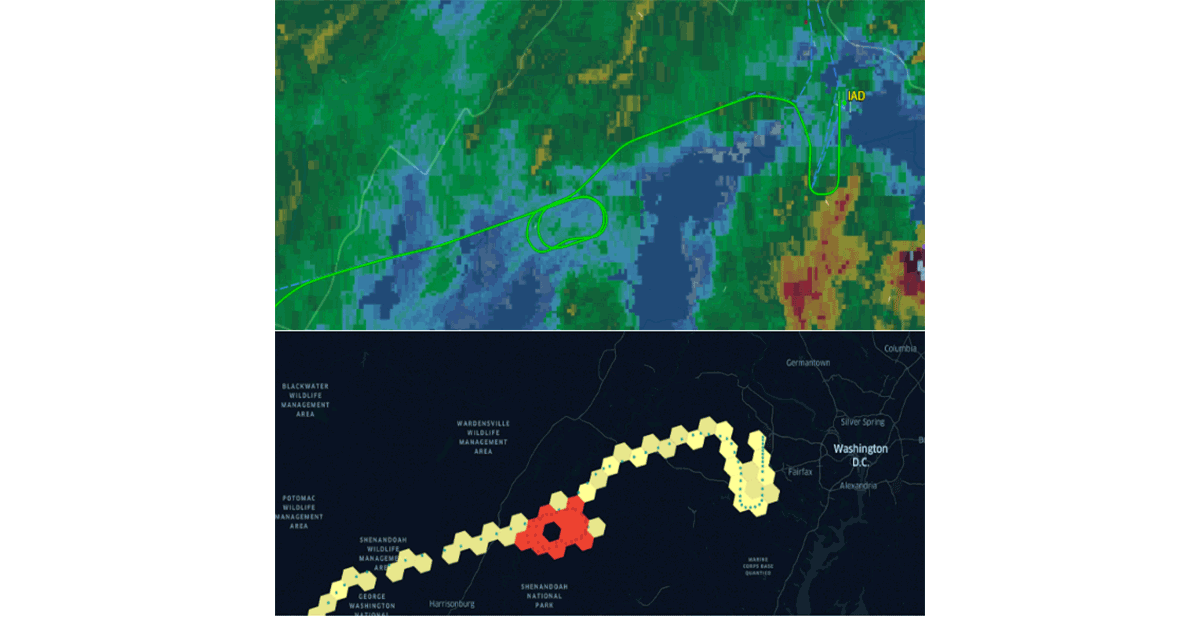
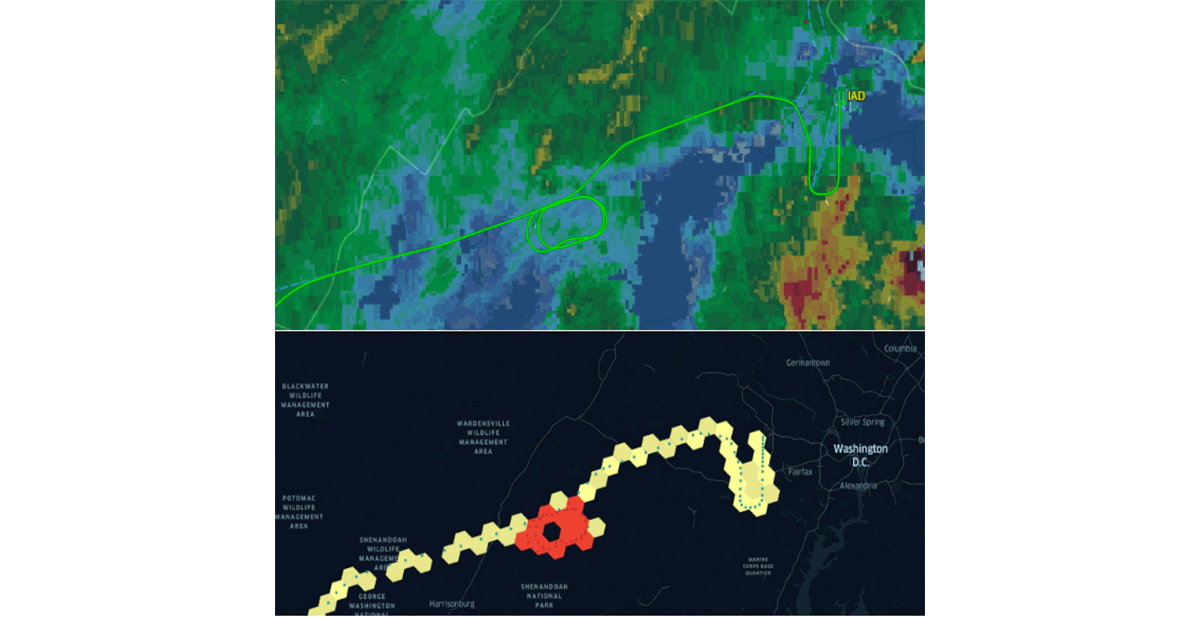
Databricks a récemment annoncé la prise en charge native du système d'indexation par grille H3 en suivant la même proposition de valeur. L'adoption de normes communes de l'industrie pilotées par la communauté est la seule façon de générer correctement des habitudes et d'assurer l'interopérabilité. Pour renforcer cette déclaration, des organisations comme CARTO, ESRI et Google promeuvent l'utilisation de systèmes d'indexation par grille pour la conception de systèmes SIG scalables. De plus, le projet Databricks Labs Mosaic prend en charge le British National Grid en tant que système d'indexation par grille standard largement utilisé dans le gouvernement britannique. Les systèmes d'indexation par grille sont essentiels pour la scalabilité du traitement des données géospatiales et pour la conception appropriée de solutions pour des problèmes complexes (par exemple, figure 5 - schémas d'attente de vol utilisant H3).
Diversité des données géospatiales
Les normes de données géospatiales consacrent un effort considérable à la standardisation des formats de données, et le format est d'ailleurs l'une des considérations les plus importantes en matière d'interopérabilité et de reproductibilité. De plus, si la lecture de vos données est complexe, comment pouvons-nous parler de simplicité ? Malheureusement, les formats de données géospatiales sont généralement complexes, car les données peuvent être produites dans un certain nombre de formats, y compris des formats open source et spécifiques à un fournisseur. En ne considérant que les données vectorielles, nous pouvons nous attendre à ce que les données arrivent en WKT, WKB, GeoJSON, CSV web, CSV, Shape File, GeoPackage, et bien d'autres. D'autre part, si nous considérons les données raster, nous pouvons nous attendre à ce que les données arrivent dans un certain nombre de formats tels que GeoTiff, netCDF, GRIB, ou GeoDatabase ; pour une liste complète des formats, veuillez consulter ce blog.
Le domaine des données géospatiales est très diversifié et s'est développé organiquement au fil des ans autour des cas d'utilisation qu'il traitait. L'unification d'un écosystème aussi diversifié représente un défi de taille. Un effort récent du Open Geospatial Consortium (OGC) pour se standardiser sur Apache Parquet et sa spécification de schéma géospatial GeoParquet est un pas dans la bonne direction. La simplicité est l'un des aspects clés de la conception d'un produit évolutif et robuste - l'unification conduit à la simplicité et aborde l'une des principales sources de friction dans l'écosystème - l'ingestion des données. La standardisation sur GeoParquet apporte une grande valeur qui répond à tous les aspects des données FAIR et de la pyramide de valeur.
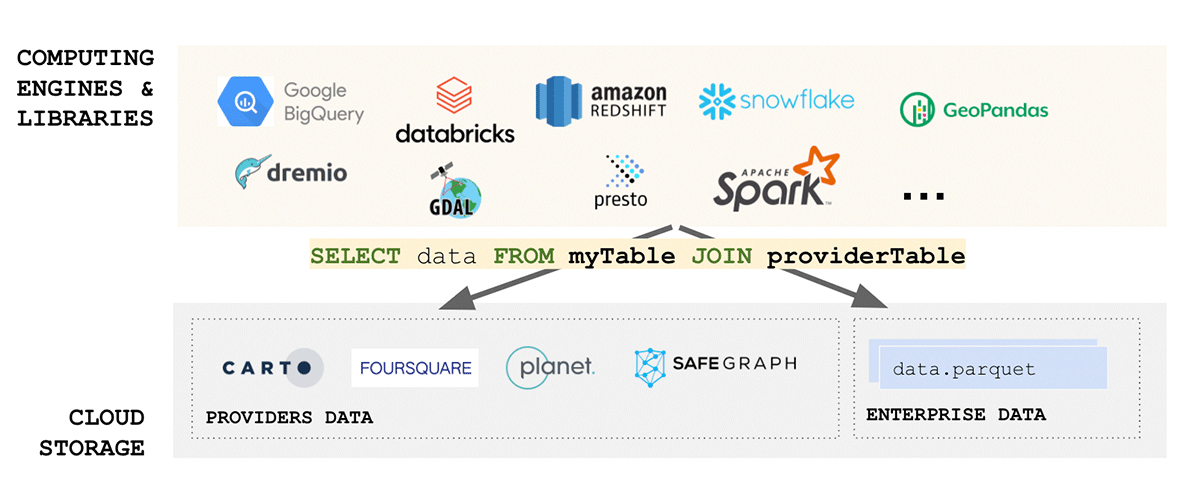
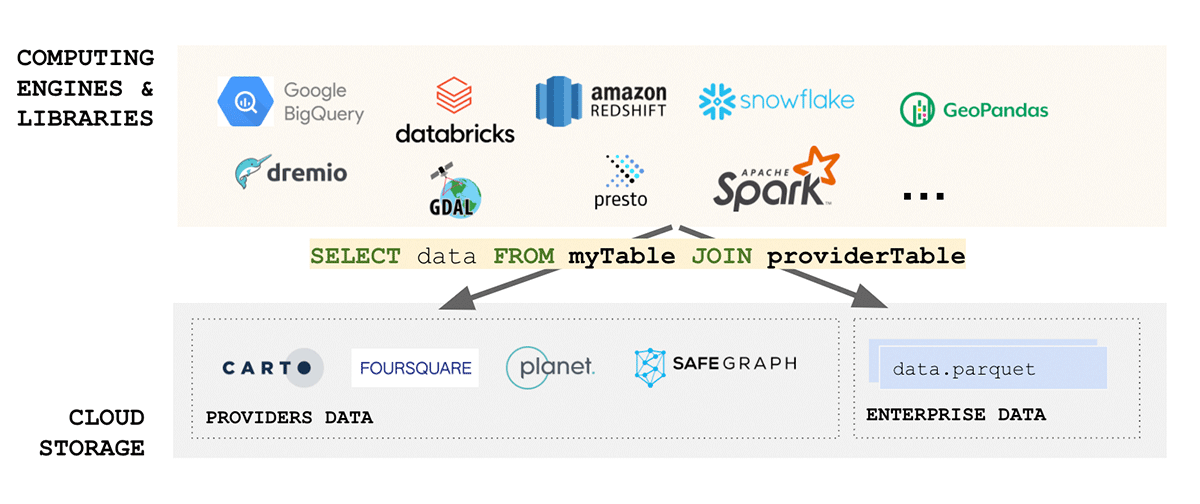{kind=link}
Pourquoi introduire un autre format dans un écosystème déjà complexe ? GeoParquet n'est pas un nouveau format - c'est une spécification de schéma pour le format Apache Parquet qui est déjà largement adopté et utilisé par l'industrie et la communauté. Parquet, en tant que format de base, prend en charge les colonnes binaires et permet le stockage de charges utiles de données arbitraires, tout en prenant en charge les colonnes de données structurées qui peuvent stocker des métadonnées avec la charge utile des données. Cela en fait un choix qui favorise l'interopérabilité et la reproductibilité. Enfin, le format Delta Lake a été construit sur parquet et apporte les propriétés ACID à la table. Les propriétés ACID d'un format sont cruciales pour la reproductibilité et pour des résultats fiables. De plus, Delta est le format utilisé par la solution de partage de données évolutive Delta Sharing. Delta Sharing permet le partage de données à l'échelle de l'entreprise entre n'importe quel cloud public utilisant Databricks (des options DIY pour le cloud privé sont disponibles en utilisant des blocs de construction open source). Delta Sharing abstrait complètement le besoin d'API REST personnalisées pour exposer des données à d'autres tiers. Tout actif de données stocké dans Delta (en utilisant le schéma GeoParquet) devient automatiquement un produit de données qui peut être exposé à des parties externes de manière contrôlée et gouvernée. Delta Sharing a été conçu dès le départ en tenant compte des meilleures pratiques de sécurité.
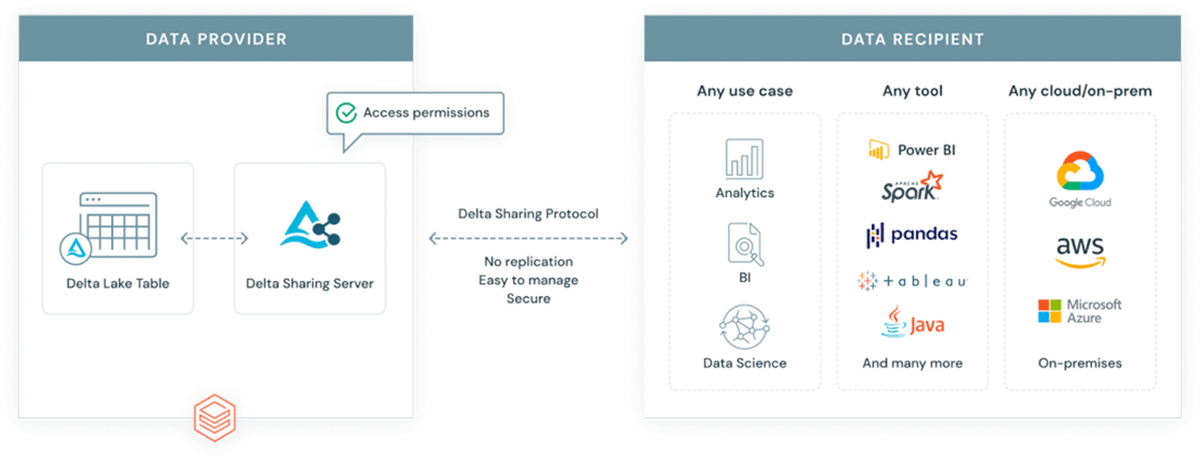
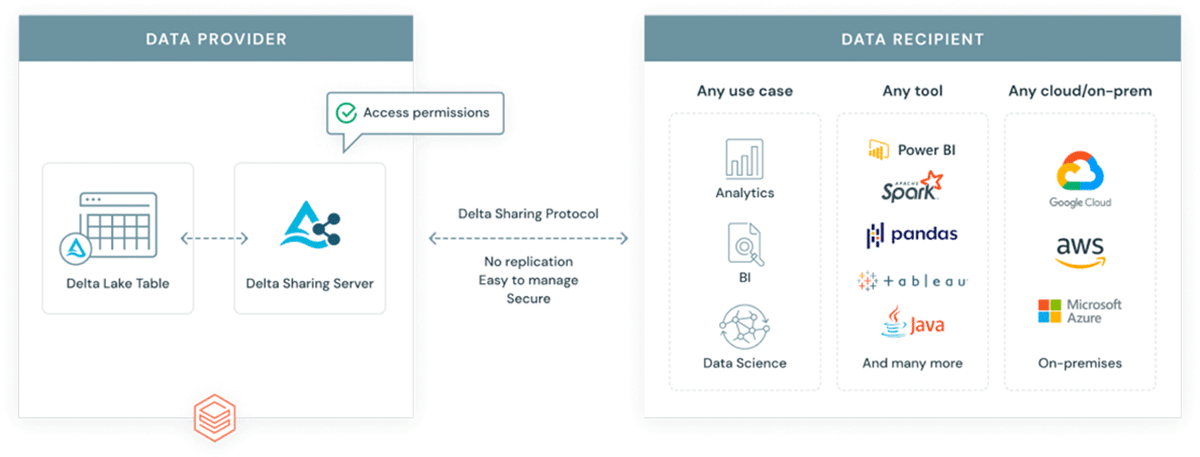{kind=link}
Économie circulaire des données
En empruntant les concepts du domaine de la durabilité, nous pouvons définir une économie circulaire des données comme un système dans lequel les données sont collectées, partagées et utilisées de manière à maximiser leur valeur tout en minimisant les déchets et les impacts négatifs, tels que le temps de calcul inutile, les informations peu fiables ou les actions biaisées basées sur des polluants de données. La réutilisabilité est le concept clé dans cette considération, comment pouvons-nous minimiser la "réinvention de la roue". Il existe d'innombrables actifs de données dans la nature qui représentent la même zone, les mêmes concepts avec de légères altérations pour mieux correspondre à un cas d'utilisation spécifique. Est-ce dû aux optimisations réelles ou au fait qu'il était plus facile de créer une nouvelle copie des actifs que de réutiliser ceux existants ? Ou était-il trop difficile de trouver les actifs de données existants, ou peut-être était-il trop complexe de définir les modèles d'accès aux données.
La duplication des actifs de données a de nombreux aspects négatifs tant pour les considérations FAIR que pour la pyramide de valeur des données - avoir de nombreux actifs de données similaires (mais différents) qui représentent la même zone et les mêmes concepts peut détériorer les considérations de simplicité du domaine des données - il devient difficile d'identifier l'actif de données auquel nous pouvons réellement faire confiance. Cela peut également avoir des implications très négatives sur la génération d'habitudes, de nombreuses communautés de niche émergeront qui se standardiseront elles-mêmes en ignorant les meilleures pratiques de l'écosystème élargi, ou pire encore, elles ne se standardiseront pas du tout.
Dans une économie circulaire des données, les données sont traitées comme une ressource précieuse qui peut être utilisée pour créer de nouveaux produits et services, ainsi que pour améliorer ceux qui existent déjà. Cette approche encourage la réutilisation et le recyclage des données, plutôt que de les traiter comme une marchandise jetable. Encore une fois, nous utilisons l'analogie de la durabilité au sens littéral - nous soutenons que c'est la bonne façon d'aborder le problème. Les polluants de données constituent un véritable défi pour les organisations, tant en interne qu'en externe. Un article du Guardian indique que moins de 1 % des données collectées sont réellement analysées. Il y a trop de duplication de données, la majorité des données sont difficiles d'accès et en tirer de la valeur est trop fastidieux. L'économie circulaire des données promeut les meilleures pratiques et la réutilisabilité des actifs de données existants, permettant une interprétation et des informations plus cohérentes dans l'écosystème de données élargi.
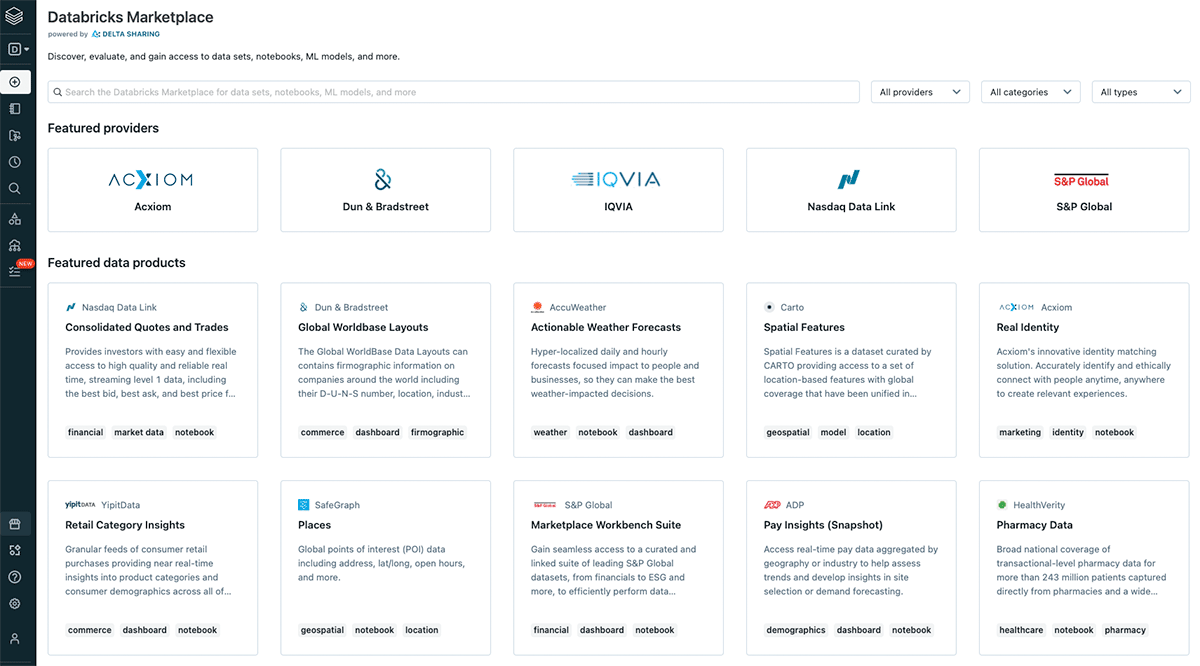
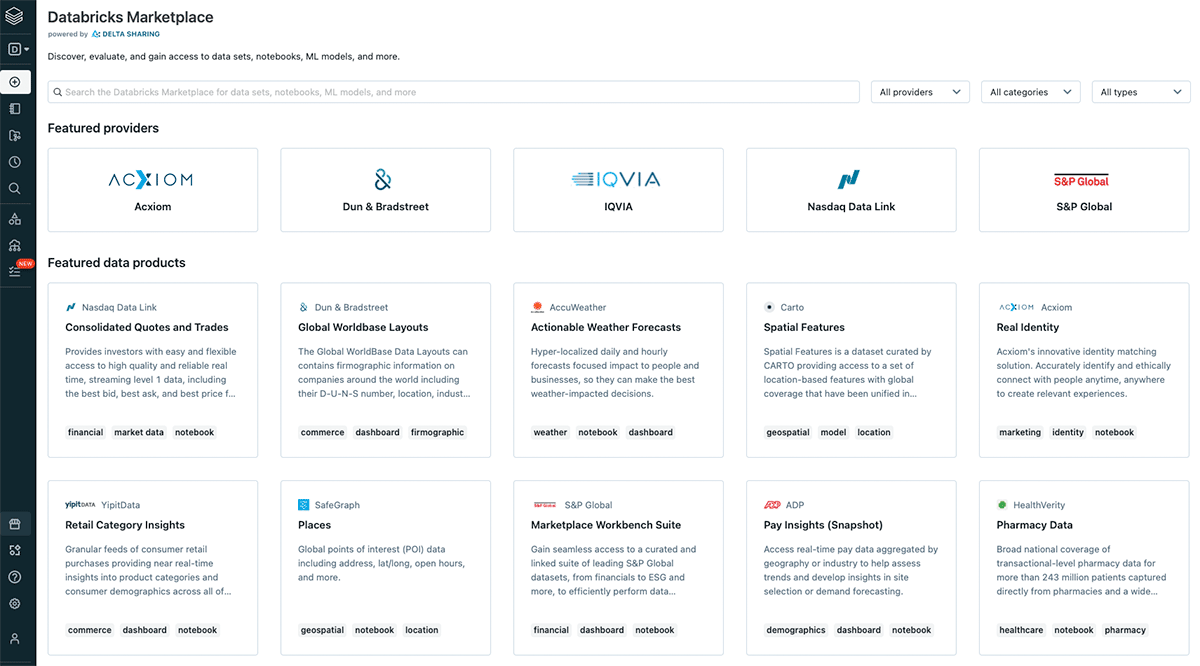{kind=link}
L'interopérabilité est une composante clé des principes des données FAIR, et de l'interopérabilité découle la question de la circularité. Comment pouvons-nous concevoir un écosystème qui maximise l'utilisation et la réutilisation des données ? Encore une fois, FAIR et la pyramide de valeur apportent des réponses. La trouvabilité des données est la clé de la réutilisation des données et de la résolution du problème de la pollution des données. Avec des actifs de données facilement découvrables, nous pouvons éviter la recréation des mêmes actifs de données à plusieurs endroits avec de légères altérations, au lieu de cela, nous obtenons un écosystème de données cohérent avec des données qui peuvent être facilement combinées et réutilisées. Databricks a récemment annoncé le Databricks Marketplace. L'idée derrière le marketplace s'aligne sur la définition originale de produit de données par DJ Patel. Le marketplace prendra en charge le partage de jeux de données, de notebooks, de tableaux de bord et de modèles d'apprentissage automatique. L'élément constitutif essentiel d'un tel marketplace est le concept de Delta Sharing - le canal évolutif, flexible et robuste pour partager n'importe quelle donnée - y compris les données géospatiales.
La conception de produits de données évolutifs qui vivront sur le Marketplace est cruciale. Afin de maximiser la valeur ajoutée de chaque produit de données, il convient de considérer sérieusement les principes FAIR et la pyramide de valeur du produit. Sans ces principes directeurs, nous ne ferons qu'aggraver les problèmes déjà présents dans les systèmes actuels. Chaque produit de données doit résoudre un problème unique et le résoudre de manière simple, reproductible et robuste.
Vous pouvez en savoir plus sur la façon dont la plateforme Databricks Lakehouse peut vous aider à accélérer la valorisation de vos produits de données dans l'eBook - Une nouvelle approche du partage de données.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.