Bilan 2025 : Databricks SQL, plus rapide pour toutes les charges de travail
Des analytique et des charges de travail d'IA plus rapides, même lorsque le volume de données, la gouvernance des données et l'utilisation montent en charge
par Tad Rosenberg, Jeremy Lewallen, Mostafa Mokhtar, Chris Stevens et Ina Felsheim
- En 2025, Databricks SQL a fourni des performances jusqu'à 40 % plus rapides sur les charges de travail de production, avec des améliorations appliquées automatiquement.
- Les performances des requêtes se sont améliorées dans les domaines de la BI, de l'ETL, de l'analyse spatiale et de l'IA, même avec des données gouvernées et partagées en place et avec une simultanéité plus élevée.
- Tous ces gains sont disponibles dès aujourd'hui dans Databricks SQL Serverless, améliorant les performances et la rentabilité des charges de travail existantes sans réglage ni réécriture.
Pour la plupart des équipes de données, la performance ne se résume plus à un réglage ponctuel. Il s'agit d'accélérer l'analytique à mesure que les données, les utilisateurs et la gouvernance montent en charge, sans augmenter les coûts.
Avec Databricks SQL (DBSQL), cette attente est intégrée à la plateforme. En 2025, les performances moyennes des charges de travail de production ont été améliorées jusqu'à 40 %, sans réglage, sans réécriture de requête et sans intervention manuelle.
Le contexte général va au-delà d'un simple benchmark. Les performances ont été améliorées sur l'ensemble de la plateforme, depuis des chargements de tableaux de bord plus rapides et des pipelines plus efficaces jusqu'à des queries qui restent réactives même avec la gouvernance et le partage de données en place, tandis que les fonctions d'analytique géospatiale et d'IA continuent de Monter en charge sans complexité supplémentaire.
L'objectif reste simple : accélérer les charges de travail et réduire le coût total par défaut. Avec DBSQL Serverless, les tables gérées Unity Catalog et l'optimisation prédictive, les améliorations s'appliquent automatiquement à l'ensemble de votre environnement, de sorte que les charges de travail existantes bénéficient de l'évolution du moteur.
Cet article présente en détail les gains de performance réalisés en 2025 pour le moteur de requêtes, Unity Catalog, Delta Sharing, le stockage, Spatial SQL et les fonctions d'IA.
Performances de requêtes rapides pour toutes les charges de travail
Databricks SQL mesure les performances à l'aide de millions de requêtes de clients réels qui s'exécutent de manière répétée en production. En suivant l'évolution de ces charges de travail au fil du temps, nous mesurons l'impact réel des améliorations et des optimisations de la plateforme plutôt que des benchmarks isolés.
En 2025, Databricks SQL a fourni des gains de performance constants pour tous les principaux types de charges de travail. Ces améliorations s'appliquent par défaut grâce à des optimisations au niveau du moteur telles que Predictive Query Execution et Photon Vectorized Shuffle, sans nécessiter de modification de la configuration.
- Les charges de travail exploratoires ont connu les gains les plus importants, s'exécutant en moyenne 40 % plus rapidement et permettant aux analystes et aux data scientists d'itérer plus rapidement sur de grands datasets.
- Les charges de travail de la Business Intelligence se sont améliorées d'environ 20 %, ce qui se traduit par des tableaux de bord plus réactifs et une analyse interactive plus fluide en accès simultané.
- Les charges de travail ETL ont également bénéficié d'améliorations, s'exécutant environ 10 % plus rapidement et réduisant les temps d'exécution des pipelines sans remaniement.
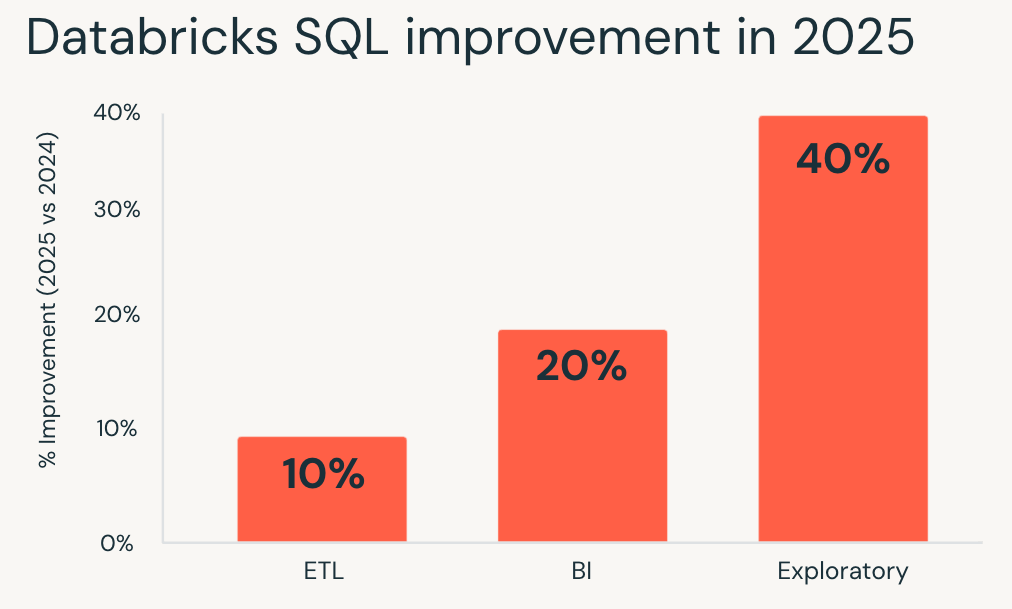
Si vous avez évalué Databricks SQL il y a un an, vos charges de travail existantes s'exécutent déjà plus rapidement aujourd'hui.
Une analytique qui reste rapide à mesure que la gouvernance monte en charge avec Unity Catalog.
À mesure que les parcs de données s'agrandissent, la gouvernance devient souvent une source de latence cachée. Les vérifications d'autorisations, l'accès aux métadonnées et les recherches de lignage peuvent ralentir les requêtes, en particulier dans les environnements interactifs et à forte concurrence.
En 2025, Unity Catalog a considérablement réduit cette surcharge. La latence de bout en bout du catalogue a été améliorée jusqu'à 10 fois, grâce à des optimisations apportées au service de catalogue, à la pile réseau, au client Databricks Runtime et aux services dépendants.
Le résultat est visible là où ça compte le plus :
- Les tableaux de bord restent réactifs même avec des contrôles d'accès précis.
- Les charges de travail à haute concurrence montent en charge sans les goulots d'étranglement liés à l'accès aux métadonnées.
- L'analytique interactive semble plus rapide lorsque les utilisateurs explorent des données gouvernées en Monter en charge.
Les équipes n'ont plus à choisir entre une gouvernance forte et les performances. Avec Unity Catalog, l'analytique reste rapide à mesure que la gouvernance s'étend à davantage de données et d'utilisateurs.
Delta Sharing, des données partagées aussi performantes que des données natives
Le partage de données entre les équipes ou les organisations a traditionnellement eu un coût. Les requêtes sur les tables partagées s'exécutaient souvent plus lentement et les optimisations étaient appliquées de manière inégale par rapport aux données natives.
En 2025, Databricks SQL a comblé cet écart. Grâce à des améliorations de l'exécution des requêtes et de la propagation des statistiques, les requêtes sur les tables partagées via Delta Sharing se sont exécutées jusqu'à 30 % plus rapidement, ce qui a permis d'aligner les performances des données partagées sur celles des tables natives.

Ce changement est particulièrement important dans les scénarios où les données externes doivent se comporter comme des données internes. Les marketplaces de données, l'analytique interorganisationnelle et le reporting piloté par les Partenaires peuvent désormais s'exécuter sur des datasets partagés sans sacrifier l'interactivité ou la prévisibilité.
Avec Delta Sharing, les équipes peuvent partager des données gouvernées à grande échelle tout en préservant les attentes en matière de performances pour l'analytique moderne.
Coût de stockage réduit, optimisations automatiques intégrées
À mesure que les volumes de données augmentent, l'efficacité du stockage représente une part plus importante du coût total. La compression joue un rôle essentiel, mais le choix des formats et la gestion des migrations ont traditionnellement entraîné une surcharge opérationnelle.
En 2025, Databricks a fait de la compression Zstandard la norme par défaut pour toutes les nouvelles tables gérées Unity Catalog. Zstandard est un format de compression open source qui permet de réaliser jusqu'à 40 % d'économies sur les coûts de stockage par rapport aux formats plus anciens, sans dégrader les performances des requêtes.

Ces avantages s'appliquent automatiquement aux nouvelles tables, et les tables existantes peuvent également être migrées vers Zstandard, avec des outils de migration simples qui seront bientôt disponibles. Les grandes tables de faits, les datasets à longue conservation et les domaines à croissance rapide bénéficient de réductions de coûts immédiates sans qu'il soit nécessaire de modifier la façon dont les queries sont écrites ou exécutées.
Il en résulte une réduction des coûts de stockage par défaut, obtenue sans sacrifier les performances ni ajouter de nouvelles étapes de réglage.
Analytique géospatiale sans systèmes spécialisés
L'analytique géospatiale sollicite fortement l'exécution des requêtes. Les jointures spatiales, les requêtes de plage et les calculs géométriques sont gourmands en ressources de calcul et, à l'échelle de la montée en charge, ils nécessitent souvent des systèmes spécialisés ou un réglage minutieux.
En 2025, Databricks SQL a considérablement amélioré les performances de ces charges de travail. Lesrequêtes SQL spatiales se sont exécutées jusqu'à 17x plus rapidement, grâce à des optimisations au niveau du moteur telles que l'indexation R-tree, les jointures spatiales optimisées dans Photon et l'optimisation intelligente des jointures de plage.
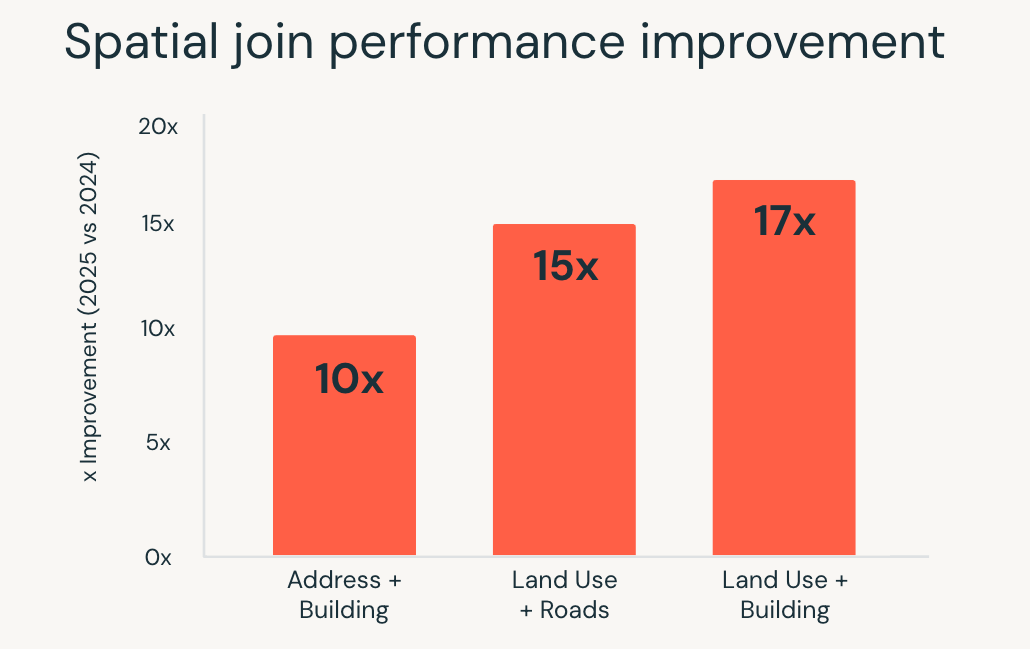
Ces améliorations permettent aux équipes de travailler avec des données de localisation en utilisant le SQL standard, tandis que le moteur gère automatiquement la complexité de l'exécution. Les cas d'usage tels que l'analyse de localisation en temps réel, le géorepérage à grande échelle et l'enrichissement géographique s'exécutent plus rapidement et de manière plus cohérente à mesure que les volumes de données augmentent.
L'analytique spatiale ne nécessite plus d'outils distincts ni d'optimisation manuelle. Les charges de travail géospatiales complexes montent en charge directement dans Databricks SQL.
AI Functions, une IA évolutive directement en SQL
L'application de l'IA aux données a traditionnellement nécessité un travail en dehors de l'entrepôt de données. La classification de texte, l'analyse de documents et la traduction impliquaient souvent la création de pipelines distincts, la gestion de l'infrastructure des modèles et la réintégration des résultats dans les workflows d'analyse.
AI Functions simplifient ce modèle en intégrant l'IA directement dans SQL. En 2025, Databricks SQL a considérablement étendu la montée en charge et les performances de ces fonctionnalités. Une nouvelle infrastructure optimisée pour le batch a permis d'atteindre des performances jusqu'à 85 fois plus rapides pour des fonctions telles que ai_classify, ai_summarize et ai_translate, permettant à de volumineux batchs Jobs, qui prenaient autrefois des heures, de s'achever en quelques minutes.
Databricks a également introduit ai_parse_document et l'a rapidement optimisé pour une utilisation à grande échelle. Des modèles spécialement conçus pour la compréhension de documents, hébergés sur Databricks Model Serving, ont offert des performances jusqu'à 30 fois plus rapides que les alternatives génériques, ce qui permet de traiter de grands volumes de contenu non structuré directement dans les workflows d'analyse.
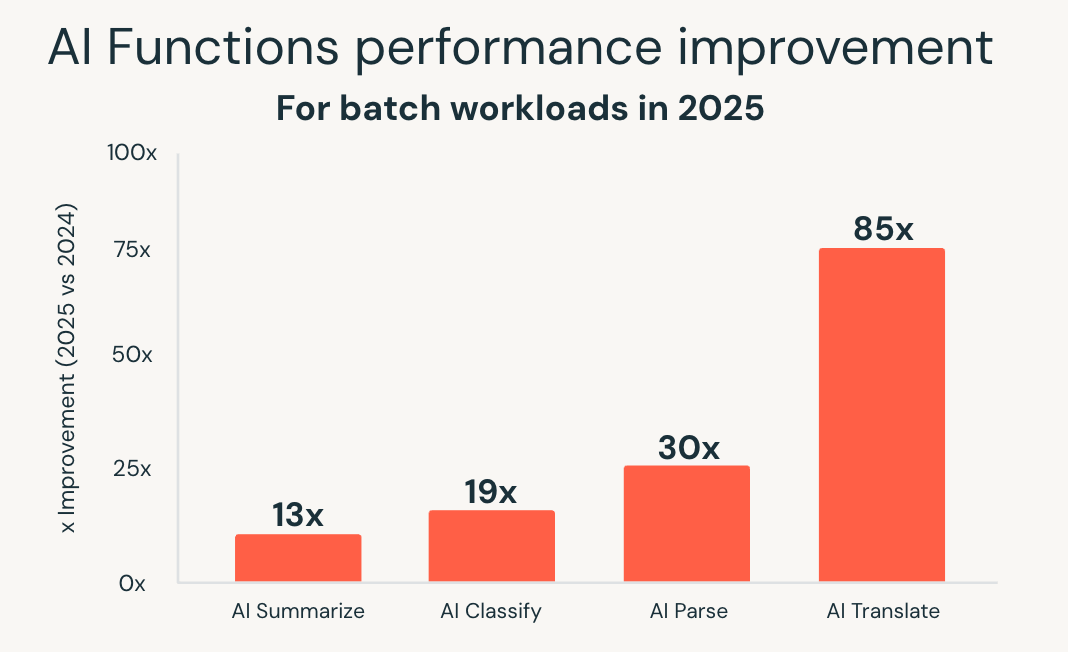
Ces améliorations permettent le traitement intelligent des documents, l'extraction d'insights à partir de données non structurées et l'analytique prédictive à l'aide d'interfaces SQL familières. Les charges de travail d'IA montent en charge parallèlement aux charges de travail analytiques, sans nécessiter de systèmes distincts ou de pipelines personnalisés.
Avec les AI Functions, Databricks SQL s'étend au-delà de l'analytique aux charges de travail basées sur l'IA, tout en conservant la simplicité et les performances attendues du warehouse.
Démarrer
Toutes ces améliorations sont déjà disponibles dans Databricks SQL Serverless, sans qu'il soit nécessaire d'activer quoi que ce soit et sans qu'aucune configuration ne soit requise.
Si vous n'avez pas essayé DBSQL Serverless, créez un warehouse serverless et start à exécuter des requêtes. Les charges de travail existantes bénéficient immédiatement d'améliorations des performances et des coûts, appliquées automatiquement à mesure que la plateforme continue d'évoluer.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.