Raisonnement Agentique en Pratique : Comprendre les Données Structurées et Non Structurées
Les données d'entreprise sont rarement utiles isolément. Répondre à des questions telles que « Quels produits ont connu une baisse des ventes au cours des trois derniers mois et quels problèmes potentiellement liés sont soulevés dans les avis clients sur divers sites vendeurs ? » nécessite un raisonnement sur un mélange de sources de données structurées et non structurées, y compris les lacs de données, les données d'avis et les systèmes de gestion des informations sur les produits. Dans ce blog, nous démontrons comment le Databricks Agent Bricks Supervisor Agent (SA) peut aider à ces tâches complexes et réalistes grâce à un raisonnement en plusieurs étapes basé sur un hybride de données structurées et non structurées.
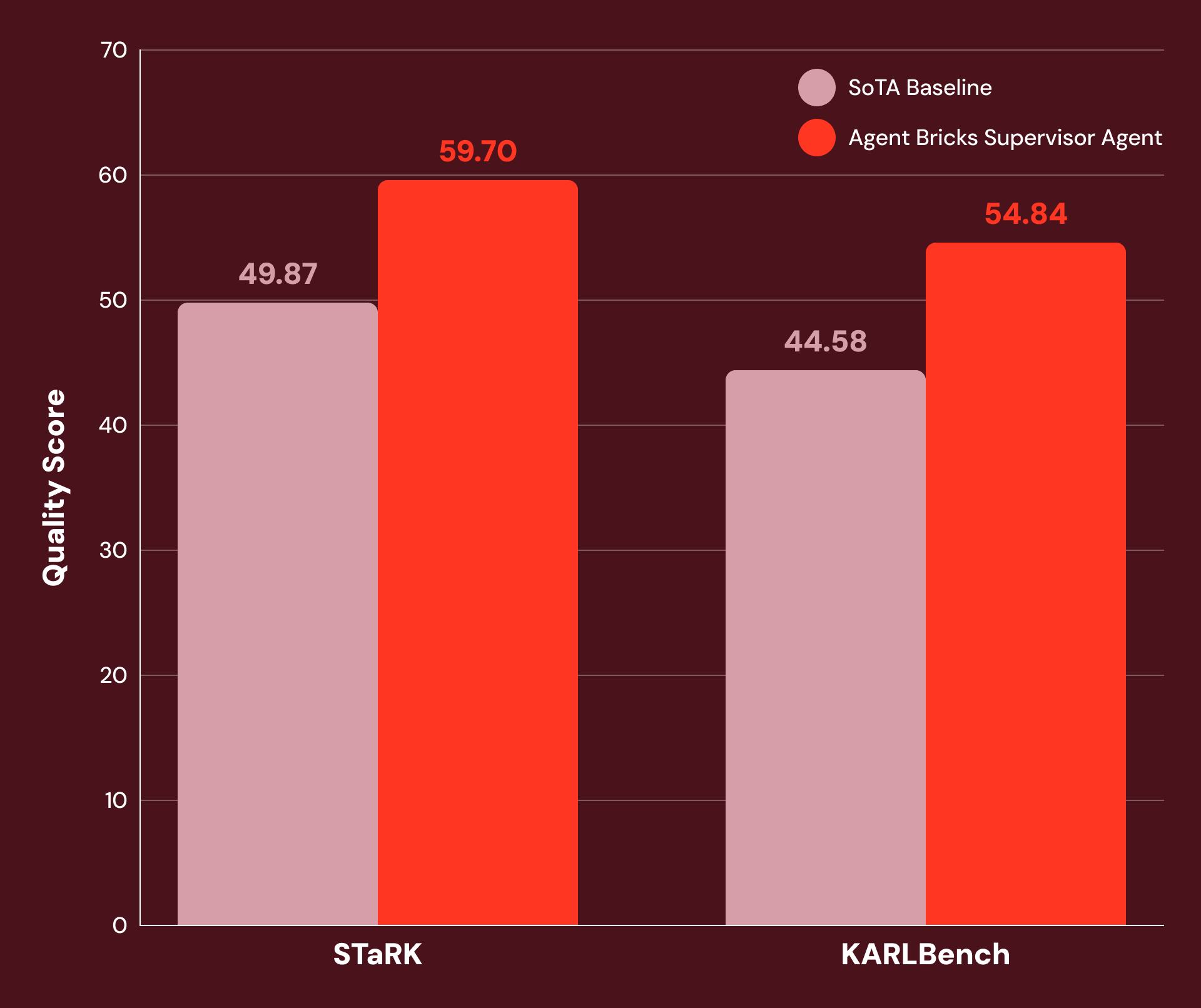
Avec des instructions ajustées et une configuration d'outils soignée, nous constatons que le SA est très performant sur un large éventail de tâches d'entreprise à forte intensité de connaissances. La Figure 1 montre que le SA obtient une amélioration de 20 % ou plus par rapport aux baselines SoTA sur :
- STaRK : une suite de trois tâches de récupération semi-structurées publiées par des chercheurs de Stanford.
- KARLBench : une suite de benchmarks pour le raisonnement complexe ancré, récemment publiée par Databricks.
Supervisor Agent démontre des gains significatifs sur un large éventail de tâches économiquement précieuses : de la récupération académique (+21 % sur STaRK-MAG) au raisonnement biomédical (+38 % sur STaRK Prime) en passant par l'analyse financière (+23 % sur FinanceBench).
Configuration de l'agent
Agent Bricks Supervisor Agent est un constructeur d'agents déclaratif qui orchestre les agents et les outils. Il est construit sur aroll — un framework interne d'agents pour construire, évaluer et déployer des workflows LLM multi-étapes à grande échelle.1 aroll et SA ont été spécifiquement conçus pour les cas d'utilisation avancés d'agents que nos clients rencontrent fréquemment.
aroll permet d'ajouter de nouveaux outils et des instructions personnalisées par de simples changements de configuration, peut gérer des milliers de conversations simultanées et d'exécutions d'outils parallèles, et intègre des techniques avancées d'orchestration d'agents et de gestion de contexte pour affiner les requêtes et récupérer des réponses partielles. Tout cela est difficile à réaliser avec les systèmes SoTA à tour unique aujourd'hui.
Étant donné que SA est construit sur cette architecture flexible, sa qualité peut être continuellement améliorée par une simple curation utilisateur, telle que l'ajustement des instructions de haut niveau ou le raffinement des descriptions d'agents, sans avoir besoin d'écrire de code personnalisé.
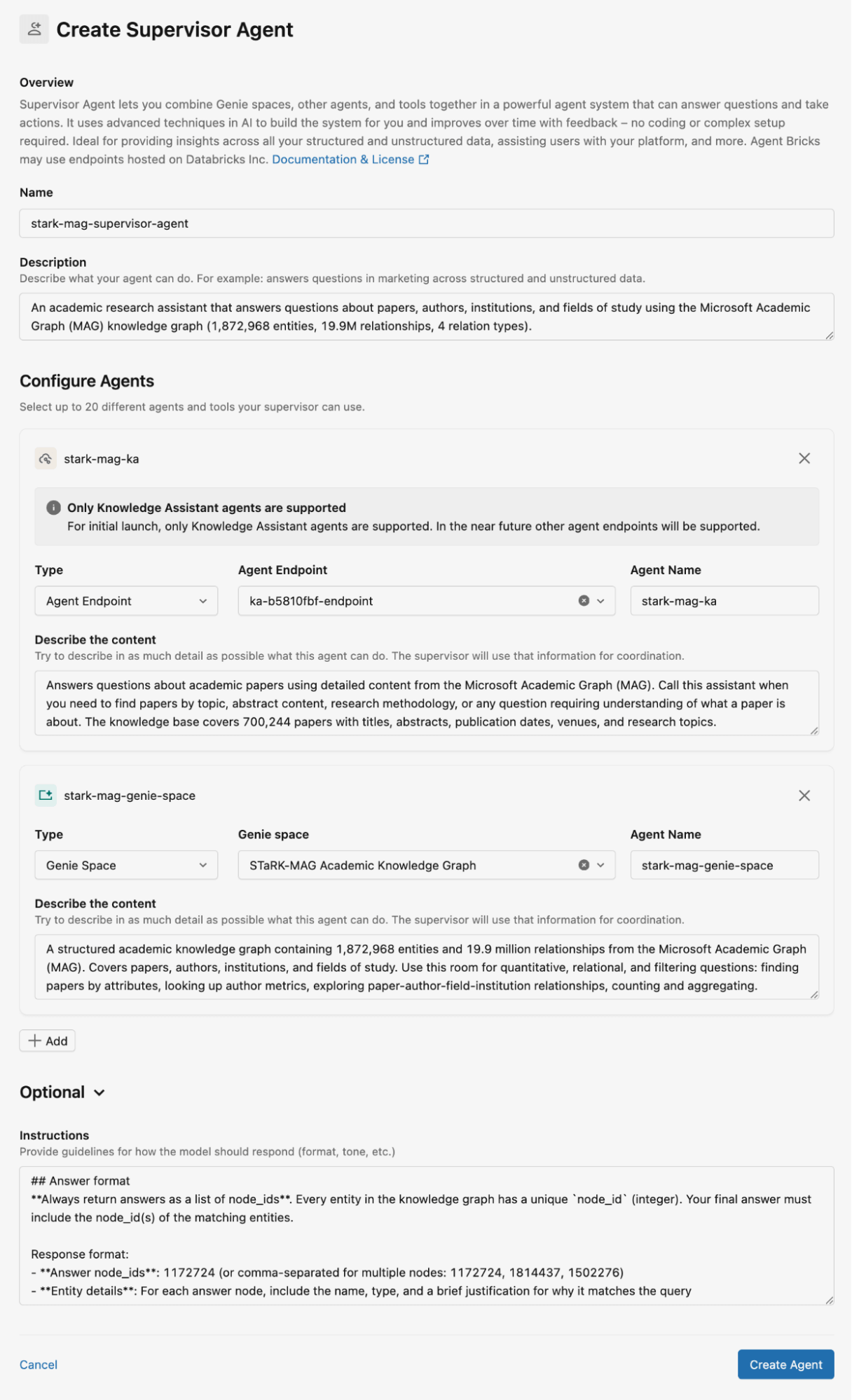
La Figure 2 montre comment nous avons configuré le Supervisor Agent pour le dataset STaRK-MAG. Dans ce blog, nous utilisons les espaces Genie pour stocker les bases de connaissances relationnelles et les Assistants de Connaissances pour stocker les documents non structurés pour la récupération. Nous fournissons des descriptions détaillées pour tous les Assistants de Connaissances et les espaces Genie, ainsi que des instructions pour les réponses de l'agent.
Raisonnement Hybride : Le Structuré Rencontre le Non Structuré
Pour évaluer le raisonnement ancré basé sur un hybride de données structurées et non structurées, nous utilisons le benchmark STaRK, qui comprend trois domaines :
- Amazon : attributs des produits (structurés) et avis (non structurés)
- MAG : réseaux de citations (structurés) et articles académiques (non structurés)
- Prime : entités biomédicales (structurées) et littérature (non structurée)
Par exemple, « Trouvez-moi un article écrit par un co-auteur ayant 115 articles et portant sur l'atome de Rydberg » nécessite que le système combine un filtrage structuré (« co-auteur avec 115 articles ») avec une compréhension non structurée (« sur l'atome de Rydberg »). Les meilleures baselines publiées utilisent la recherche par similarité vectorielle avec un reranker basé sur LLM — une approche solide à tour unique, mais qui ne peut pas décomposer les requêtes entre les types de données. Pour assurer une comparaison équitable, nous avons réexécuté cette baseline avec le modèle fondamental SoTA actuel, fournissant une baseline substantiellement plus solide.
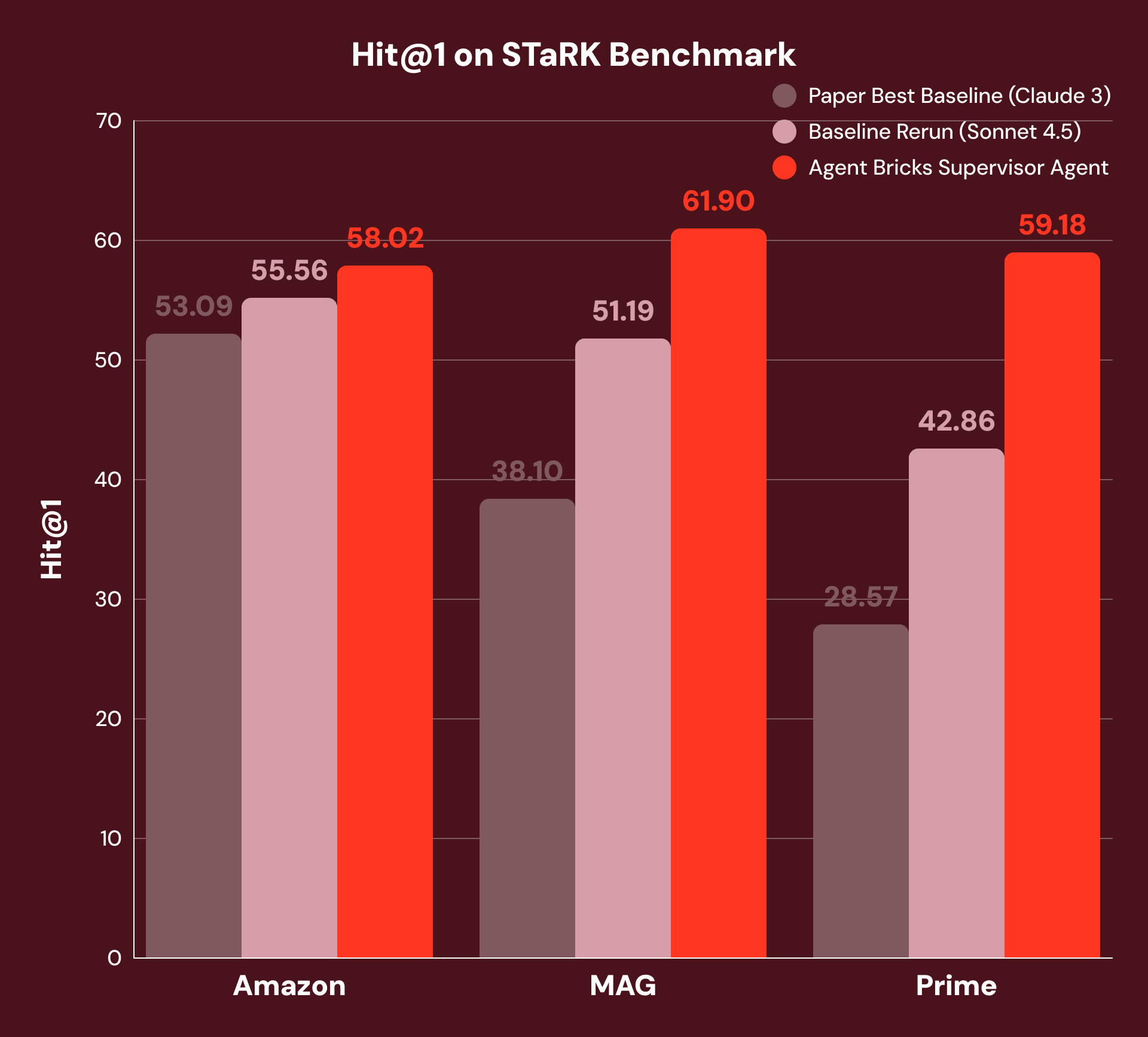
Avec notre approche, SA décompose chaque question, achemine les sous-questions vers l'outil approprié et synthétise les résultats sur plusieurs étapes de raisonnement. Comme le montre la Figure 3, cela permet d'obtenir +4 % de Hit@1 sur Amazon, +21 % sur MAG et +38 % sur Prime par rapport aux meilleures baselines originales et à nos baselines réexécutées avec le modèle fondamental SoTA actuel. Nous observons les meilleures améliorations sur MAG et Prime, où la réponse nécessite l'intégration la plus étroite des données structurées et non structurées.
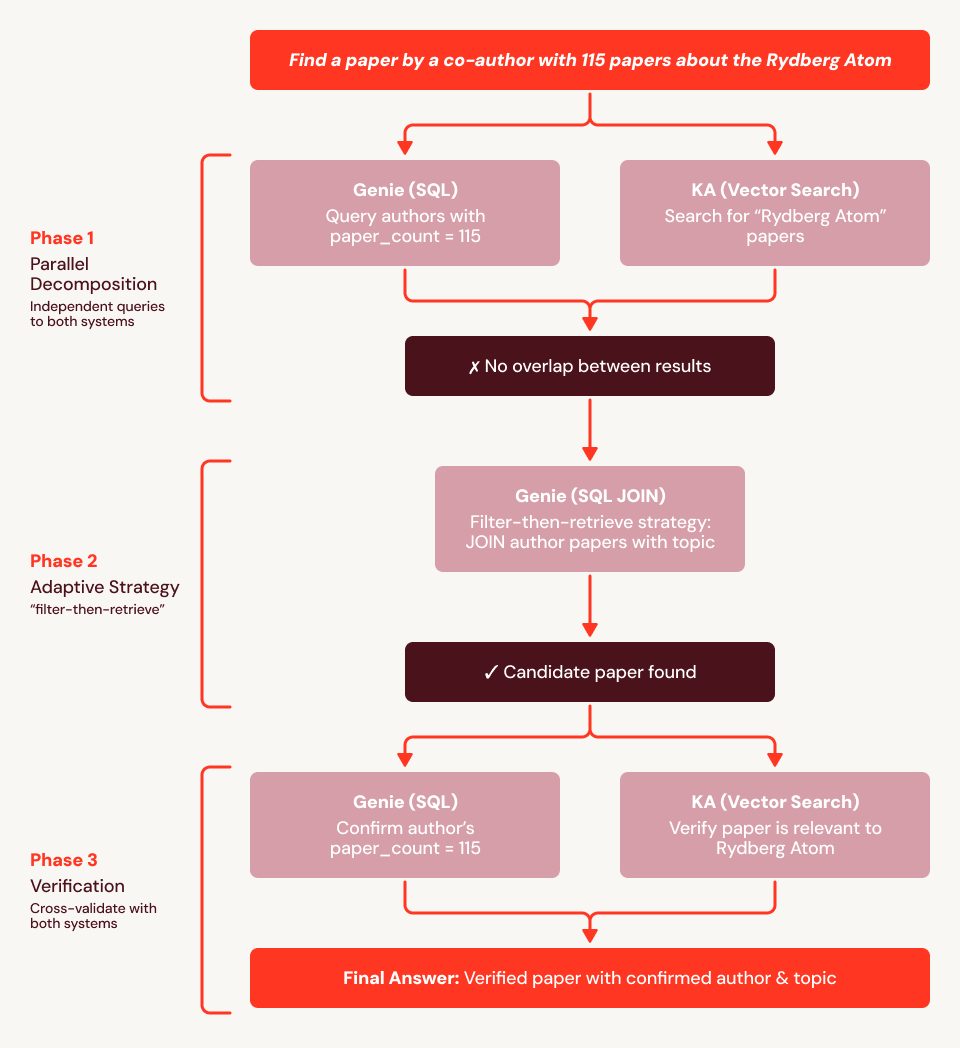
En utilisant notre exemple de question (« Trouvez-moi un article écrit par un co-auteur ayant 115 articles et portant sur l'atome de Rydberg »), nous constatons que la baseline échoue car les embeddings ne peuvent pas encoder la contrainte structurelle (« le co-auteur a exactement 115 articles »). Dans la Figure 4, nous montrons une trace d'exécution pour SA : il utilise d'abord Genie pour trouver les 759 auteurs ayant 115 articles et Knowledge Assistant pour récupérer les articles sur le Rydberg, puis croise les deux ensembles. Lorsqu'aucun chevauchement n'est trouvé, SA s'adapte : il émet une jointure SQL de la liste des auteurs ayant 115 articles contre tous les articles mentionnant « Rydberg » dans le titre ou le résumé, extrayant la réponse directement des données structurées. Il appelle ensuite Knowledge Assistant pour vérifier la pertinence et Genie pour confirmer le nombre d'articles de l'auteur, et renvoie avec succès l'article correct.
L'Avantage Agentique sur les Tâches à Forte Intensité de Connaissances
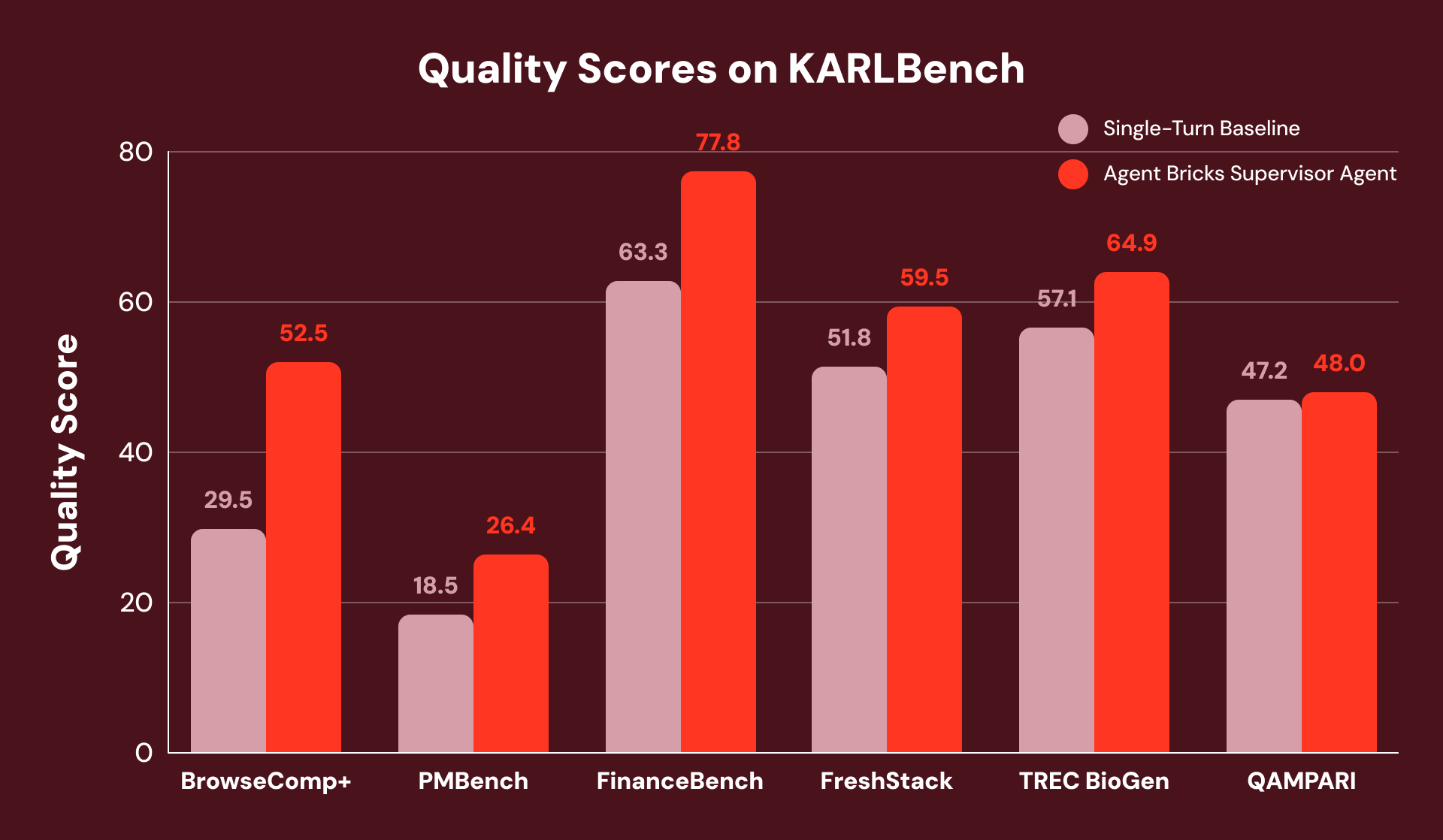
Pour comparer les performances d'Agent Bricks SA avec une baseline solide à tour unique (similaire à la meilleure baseline publiée pour STaRK) où aucune donnée structurée n'est requise, nous les évaluons en utilisant KARLBench, une suite de benchmarks de raisonnement ancré qui teste collectivement différentes capacités de récupération et de raisonnement :
- BrowseComp+ : recherche d'entités par élimination
- TREC BioGen : synthèse de littérature biomédicale
- FinanceBench : raisonnement numérique sur des documents financiers
- QAMPARI : rappel exhaustif d'entités
- FreshStack : dépannage technique sur la documentation
- PMBench : compréhension de documents d'entreprise interne à Databricks
Globalement, le Supervisor Agent obtient des gains constants sur les six benchmarks, avec les plus grandes améliorations sur les tâches qui exigent soit une analyse exhaustive, soit une auto-correction. Sur FinanceBench, il récupère d'une récupération initiale incomplète en détectant des lacunes et en reformulant les requêtes, ce qui se traduit par une amélioration globale de +23 %.
Par exemple, les questions de BrowseComp+ comportent chacune 5 à 10 contraintes interdépendantes, telles que « Trouvez un joueur qui a quitté un club russe (2015-2020), naturalisé européen (2010-2016), taille 1,95-2,06 m. Quel a été son taux de réussite de blocage aux Jeux Olympiques reportés à cause de la COVID ? » La baseline à tour unique émet une requête large qui identifie correctement le joueur mais ne parvient pas à trouver les documents de statistiques granulaires et échoue à la question.
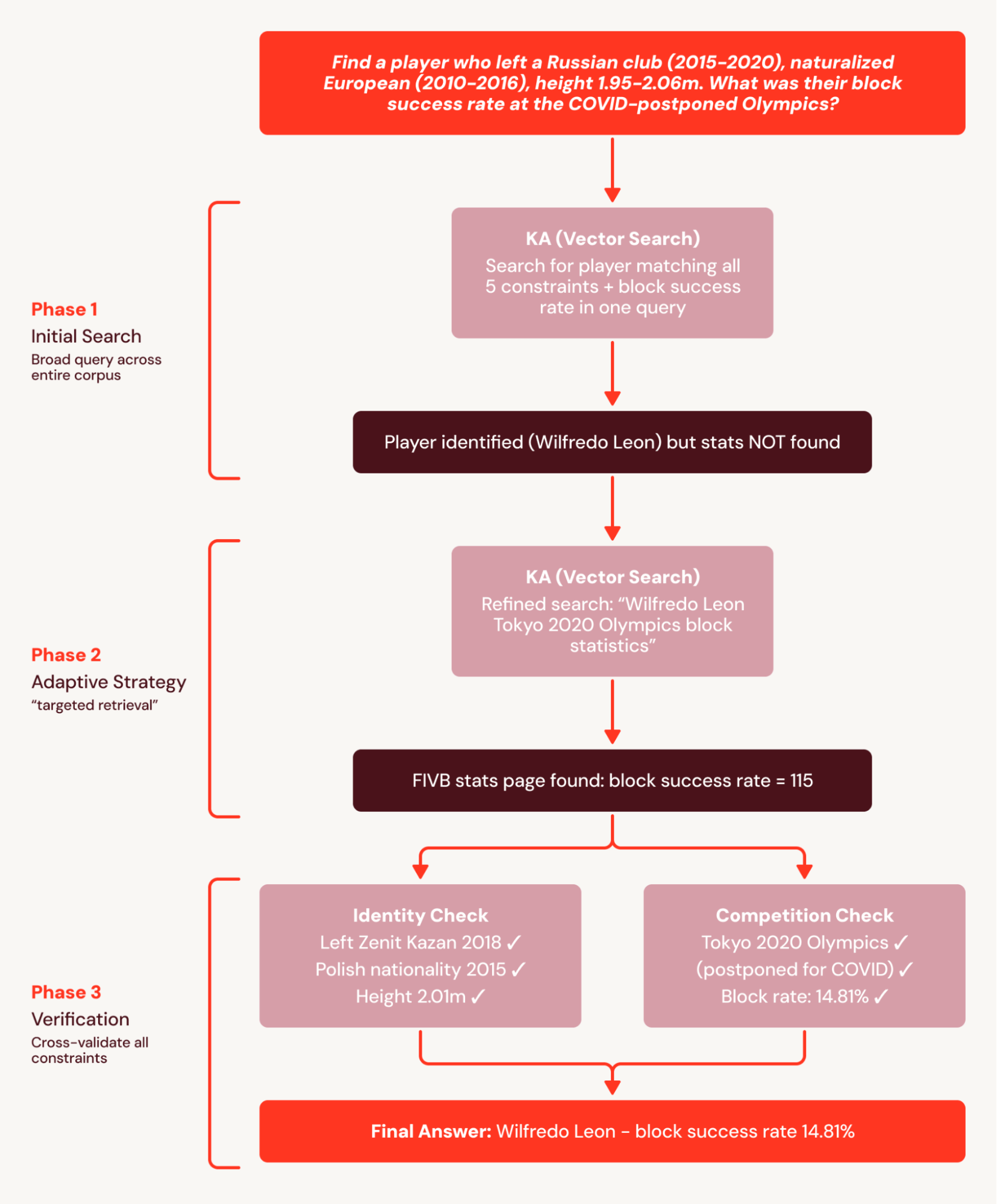
SA décompose cette tâche en un plan de recherche coordonné et divise le plan en sous-ensembles recherchables. Cela évite l'échec de la baseline à tour unique où les statistiques ne sont pas trouvées car elles sont récupérées dans une recherche ultérieure. En conséquence, SA obtient une amélioration relative de +78 %.
Dans un autre exemple de PMBench, l'une des questions est « quels sont les types de garde-fous utilisés par les clients », ce qui nécessite 26 éléments (voir la définition dans le rapport KARL) dans plus de 10 documents de conversation client pour une réponse exhaustive. La baseline à tour unique ne trouve qu'une seule mention client car elle ne peut pas rechercher dans toutes les catégories de garde-fous en une seule question. SA recherche chaque catégorie de garde-fous séparément (« détection PII », « hallucination », « toxicité », « injection de prompt »), et fait remonter progressivement de plus en plus de mentions client au cours du processus.
Ce que nous avons appris
Les résultats de nos expériences pointent vers quelques conclusions clés :
- Les agents de raisonnement ancrés peuvent bénéficier d'un hybride de récupération de données structurées et non structurées s'ils ont accès aux bons outils et représentations de données.
- Pour les scénarios de récupération de haute qualité, la création de pipelines RAG personnalisés sur des ensembles de données hétérogènes doit être évitée, même si les modèles SoTA sont utilisés pour l'étape de re-classement. Le raisonnement en plusieurs étapes où, à chaque étape, l'agent sélectionne la bonne source de données et réfléchit à son utilité, est crucial pour améliorer les performances.
- Une approche déclarative de la construction d'agents, telle que celle mise en œuvre par l'agent superviseur Databricks, offre un bon compromis entre facilité d'utilisation et qualité.
Nous utilisons l'agent superviseur Databricks pour construire des agents pour les trois domaines STaRK et six ensembles de données non structurées dans KARLBench. Les seules choses qui diffèrent entre ces neuf tâches sont les instructions et les outils — aucun code personnalisé n'a été nécessaire pour traiter ces divers ensembles de données. Ainsi, la construction d'un agent performant pour une nouvelle tâche d'entreprise relève en grande partie de la rédaction d'instructions précises et de son équipement avec les bons outils, plutôt que de la construction d'un nouveau système à partir de zéro.
L'agent superviseur Agent Bricks est disponible pour tous nos clients. Vous pouvez commencer avec Agent Bricks SA simplement en créant un agent et en le connectant à vos agents, outils et serveurs MCP existants. Explorez la documentation pour voir comment l'agent superviseur s'intègre dans vos flux de travail de production.
Auteurs : Xinglin Zhao, Arnav Singhvi, Mark Rizkallah, Jonathan Li, Jacob Portes, Elise Gonzales, Sabhya Chhabria, Kevin Wang, Yu Gong, Moonsoo Lee, Michael Bendersky et Matei Zaharia.
1Consultez notre récente publication « KARL : Knowledge Agents via Reinforcement Learning » pour plus de détails sur la façon dont aroll est utilisé pour la génération de données synthétiques, la formation RL évolutive et l'inférence en ligne pour les tâches d'agent.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.