Annonce de Native Lakehouse Sync depuis Lakebase
Ouvrir les données Lakebase aux modèles, à l'analyse et à d'autres moteurs
par Pranav Aurora, Hristo Stoyanov et Cheng Chen
- Native Lakehouse Sync (préversion publique) réplique automatiquement les données Lakebase Postgres dans les tables gérées par Unity Catalog, sans pipelines ni calcul externe.
- Les piles CDC traditionnelles échouent sous les charges de travail pilotées par des agents. Parce que Lakebase et le Lakehouse partagent le même stockage ouvert, la synchronisation devient une propriété native de la base de données sans impact sur les performances de Postgres, sans coût supplémentaire et avec une propagation automatique du schéma.
- Fonctionnalités ML en direct basées sur l'état actuel de l'application, données opérationnelles comme couche Bronze d'une architecture en médaillon avec un historique SCD Type 2 complet, et capture d'audit intégrée pour chaque modification.
Aujourd'hui, nous sommes ravis d'annoncer la préversion publique de Native Lakehouse Sync, une capacité essentielle de Lakebase Postgres qui réplique les données Lakebase vers les tables gérées par Unity Catalog, sans aucune pipeline ni calcul externe. Native Lakehouse Sync est disponible dans toutes les régions Lakebase sur AWS et Azure.
Pourquoi nous l'avons créé
Les applications fonctionnaient auparavant sur une seule base de données opérationnelle. À mesure que les cas d'utilisation se sont étendus, une seule base de données n'a plus suffi. L'analyse, le ML et la recherche vivent tous en dehors de la base de données opérationnelle, ce qui signifie que les données doivent être déplacées.
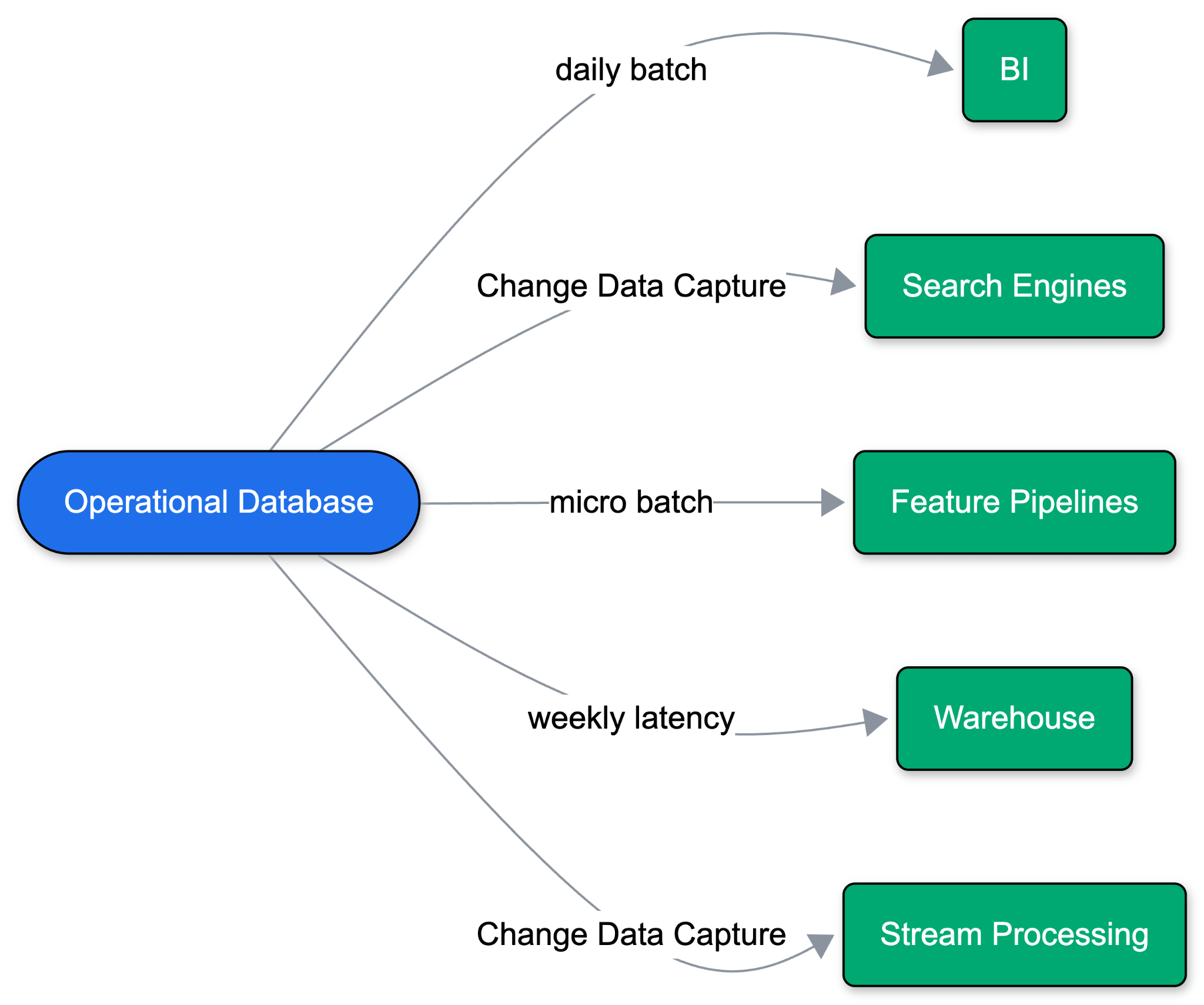
Historiquement, cela signifiait des déchargements quotidiens par lots vers un entrepôt de données, ce qui a finalement évolué vers la capture de données modifiées (CDC). Les hyperscalers ont présenté cela comme des synchronisations « gérées » (« zéro-ETL »), déployant des pipelines de données aux côtés de la base de données. Mais ces synchronisations gérées reposent sur des hypothèses héritées : des charges de travail toujours actives, des schémas stables, des volumes de requêtes prévisibles et un seul entrepôt de destination. Le problème s'aggrave avec chaque nouvelle destination de données : les performances opérationnelles se dégradent, les schémas dérivent et les points de défaillance se multiplient à travers la pile.
Le développement axé sur les agents rompt entièrement ce modèle. Les agents ramifient rapidement les données pour itérer en toute sécurité, s'adaptent à zéro entre les tâches et créent des environnements éphémères. Gérer un pipeline personnalisé pour chaque branche et chaque destination ne s'adapte tout simplement pas.
L'intégration dans un entrepôt est la mauvaise approche. Les consommateurs en aval sont rarement de simples tableaux de bord ; ils intègrent des modèles, des LLM, des services de prédiction et des pipelines de fonctionnalités. Les formats de table ouverts comme Delta Lake et Apache Iceberg™ offrent le primitif idéal : stocker les données une seule fois dans un stockage objet bon marché pour alimenter chaque charge de travail sans duplication. C'est une évidence : vous avez besoin d'un Lakehouse, et vous voulez des données opérationnelles fraîches à l'intérieur.
Mais l'écriture de données opérationnelles dans un Lakehouse a créé de nouveaux défis. Les équipes ont été contraintes de configurer des slots de réplication Postgres, des connecteurs Debezium, des moteurs de traitement de flux pour écrire dans des formats ouverts, et un calcul séparé juste pour optimiser les tables. Chaque saut ajoute un point de défaillance.
La synchronisation comme propriété de Lakebase
Lakebase est construit sur une hypothèse fondamentalement différente : une base de données opérationnelle devrait fonctionner sur le même stockage cloud ouvert et à faible coût que votre Lakehouse. Parce que l'OLTP et l'OLAP partagent cette fondation de stockage unifiée, nous pouvons éliminer entièrement le pipeline ETL. Le mouvement des données devient une propriété native de la base de données elle-même.
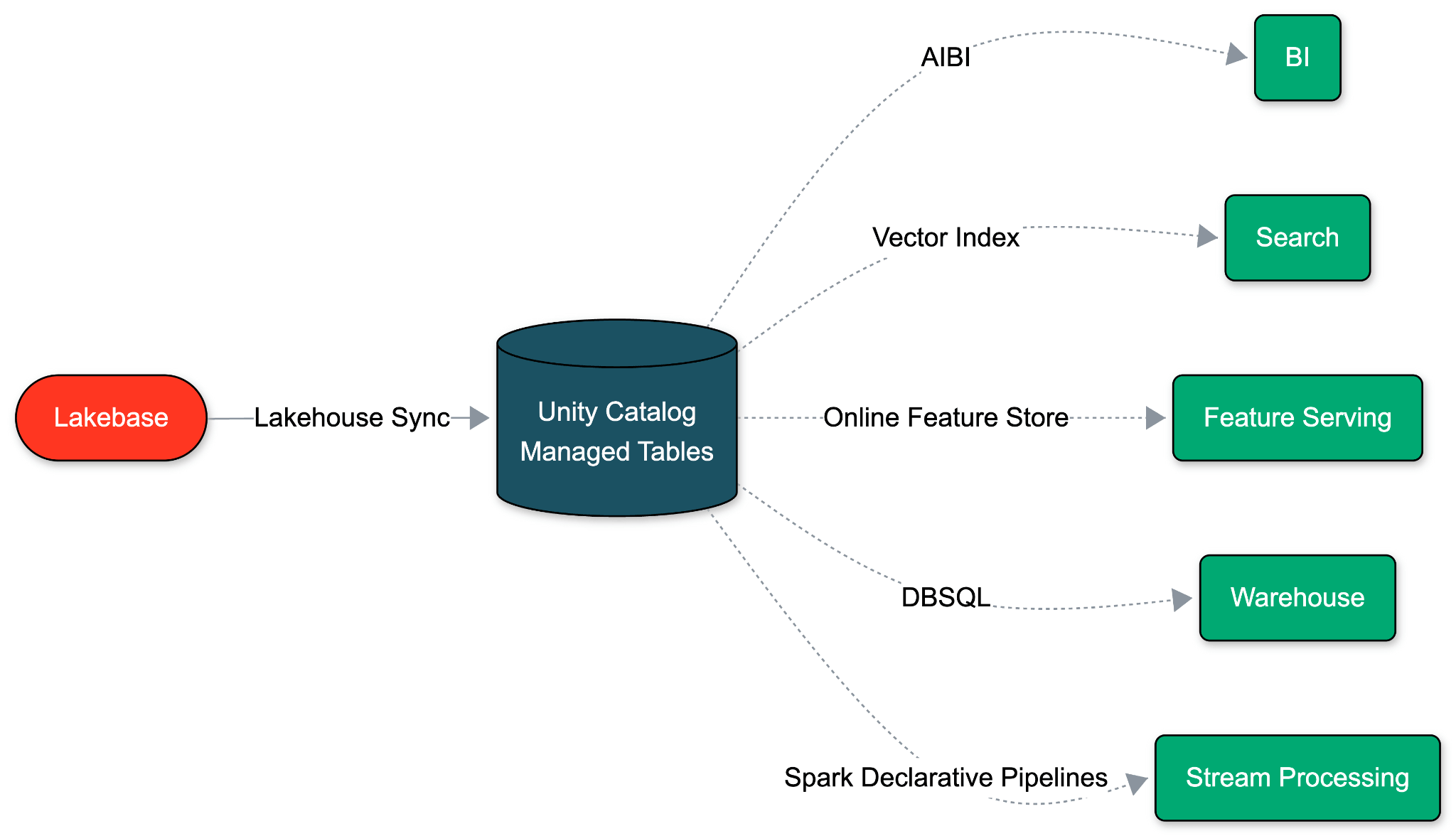
Avec Native Lakehouse Sync, Lakebase décode son journal de transactions (WAL) et écrit directement dans les tables gérées par Unity Catalog. Un simple interrupteur au niveau du schéma l'active en moins d'une minute. Cette synchronisation n'a aucun impact sur les performances de Postgres et n'entraîne aucun coût supplémentaire. Et comme Databricks contrôle les deux extrémités, les modifications de schéma sont propagées automatiquement, éliminant ainsi la dérive et le décalage.
Priorité aux agents de bout en bout
Les agents construisent des applications sur Lakebase. Des agents comme Databricks Genie analysent les données. Pour maintenir ce cycle de vie entièrement autonome, Native Lakehouse Sync est intégré comme une propriété essentielle de Lakebase. Il hérite des comportements exacts dont les agents ont besoin pour fonctionner de manière transparente :
- Mise à l'échelle à zéro : La synchronisation se met en pause lorsque la base de données passe à zéro et reprend à partir du dernier LSN au réveil.
- Gestion du calcul zéro : La synchronisation fait partie intégrante de Lakebase. Toute la surveillance et l'observabilité restent au sein de votre projet Lakebase.
- Propagation automatique du schéma : Les modifications de schéma sont propagées automatiquement. L'ajout d'une colonne est instantanément propagé. La suppression d'une colonne la conserve sur la destination. Les agents n'ont jamais à recréer la synchronisation.
Primitives Lakehouse côté destination
Parce que la destination est une table gérée par Unity Catalog, chaque capacité Lakehouse est disponible sur les données synchronisées dès leur arrivée.
- Analyse native de l'IA : Immédiatement disponible pour l'interrogation, l'analyse et la génération de pipelines par des agents comme Databricks Genie et Genie Code.
- Lisibilité universelle : Lisible par Databricks SQL, Apache Spark, Lakeflow Spark Declarative Pipelines, les notebooks ML et tout outil compatible Delta ou Iceberg.
- Gouvernance unifiée : La lignée, les politiques d'accès, les balises et les audits sont hérités de Unity Catalog.
- Optimisation automatique : L'optimisation prédictive et le Liquid Clustering s'appliquent sans aucune configuration.
- Versionnement par défaut : Chaque insertion, mise à jour et suppression est enregistrée comme historique SCD Type 2. Les journaux d'audit, les retours en arrière et la sémantique CDF sont intégrés.
Ce que vous pouvez construire avec Native Lakehouse Sync
Ensemble, ces comportements source et destination débloquent trois modèles qui nécessitaient auparavant une pile de capture de données modifiées (CDC) personnalisée :
Mémoire agentique et fonctionnalités ML en direct. Les écritures d'applications arrivent dans Unity Catalog en moins d'une minute, de sorte que les modèles se réentraînent et évaluent l'état actuel de l'application sans pipeline d'ingestion séparé.
Données opérationnelles dans l'architecture en médaillon. Utilisez Lakebase comme tables Bronze dans l'architecture en médaillon. Les mises à jour à haute vélocité se produisent dans Postgres, et l'historique complet des modifications est automatiquement transféré dans le Lakehouse en tant que SCD Type 2.
Conformité et audit. Chaque insertion, mise à jour et suppression est capturée comme une ligne d'historique dans Unity Catalog. Pas de suivi d'historique côté application, pas de pipeline d'audit séparé.
Commencer
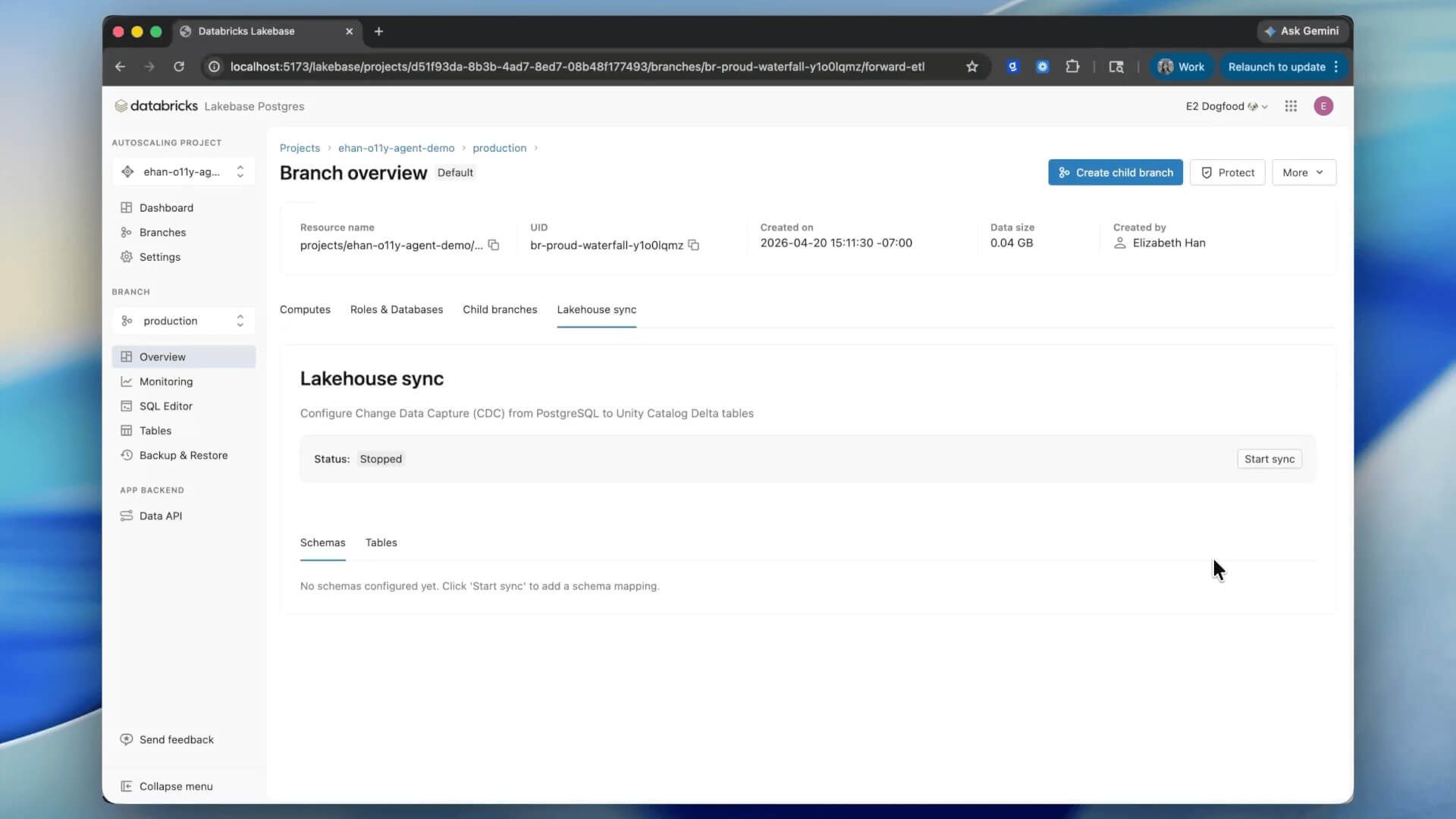
Native Lakehouse Sync est en préversion publique. Le démarrage d'un Lakebase est instantané. Activez la synchronisation sur un schéma une seule fois, et chaque table existante et future apparaîtra dans Unity Catalog en moins d'une minute.
Lakebase est construit sur la même fondation de données ouverte que le Lakehouse. Native Lakehouse Sync concrétise cette vision, permettant aux données Lakebase de s'intégrer automatiquement dans des formats ouverts sans pipeline séparé.
La prochaine étape : apporter cette même ouverture du Lakehouse aux tables Lakebase. Restez à l'écoute.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.