Créer des produits de données fiables et de haute qualité avec Databricks
par Amr Ali, Bernhard Walter, Fran Medina Castro, Glenn Wiebe, Karthik Subbarao, Lexy Kassan, Magnus Pierre et Pawarit Laosunthara
Introduction
Les organisations qui visent à devenir axées sur l'IA et les données doivent souvent fournir à leurs équipes internes des produits de données fiables et de haute qualité. La création de tels produits de données garantit que les organisations établissent des normes et une base de confiance pour leurs objectifs en matière de données et d'IA. Une approche pour mettre la qualité et l'utilisabilité au premier plan consiste à utiliser le paradigme de la data mesh pour démocratiser la propriété et la gestion des actifs de données. Nos articles de blog (Partie 1, Partie 2) fournissent des conseils sur la manière dont les clients peuvent exploiter Databricks dans leur entreprise pour aborder les piliers fondamentaux de la data mesh, dont l'un est "les données en tant que produit".
Bien que l'idée de traiter les données comme des produits ait gagné en popularité avec l'émergence de la data mesh, nous avons observé que l'application de la pensée produit résonne même auprès des clients qui n'ont pas choisi d'adopter la data mesh. Quelle que soit la structure organisationnelle ou l'architecture des données, la prise de décision basée sur les données reste un principe directeur universel. La qualité et l'utilisabilité des données sont primordiales pour garantir que ces décisions soient prises sur la base d'informations valides. Ce blog présentera certaines de nos recommandations pour la création de produits de données prêts pour l'entreprise, à la fois de manière générale et spécifiquement avec Databricks.
Les produits de données apportent de la valeur lorsque les utilisateurs et les applications disposent des bonnes données au bon moment, avec la bonne qualité, dans le bon format. Si cette valeur a traditionnellement été réalisée sous la forme d'opérations plus efficaces grâce à des coûts réduits, des processus plus rapides et des risques atténués, les produits de données modernes peuvent également ouvrir la voie à de nouvelles offres à valeur ajoutée et à des opportunités de partage de données au sein de l'industrie ou de l'écosystème de partenaires d'une organisation.
Produits de données
Bien que les produits de données puissent être définis de diverses manières, ils correspondent généralement à la définition trouvée dans Data Jujitsu: The Art of Turning Data into Product de DJ Patil : "Pour commencer, ..., une bonne définition d'un produit de données est un produit qui facilite un objectif final grâce à l'utilisation des données". En tant que tels, les produits de données ne se limitent pas aux données tabulaires ; ils peuvent également être des modèles ML, des tableaux de bord, etc. Pour appliquer cette pensée produit aux données, il est fortement recommandé que chaque produit de données ait un propriétaire de produit de données.
{kind=link}
Les propriétaires de produits de données gèrent le développement et surveillent l'utilisation et les performances de leurs produits de données. Pour ce faire, ils doivent comprendre l'activité sous-jacente et être capables de traduire les exigences des consommateurs de données en une conception pour un produit de données de haute qualité et facile à utiliser. En collaboration avec d'autres personnes au sein de l'organisation, ils comblent le fossé entre les collègues commerciaux et techniques, tels que les ingénieurs de données. Le propriétaire du produit de données est responsable de garantir que les produits de son portefeuille s'alignent sur les normes organisationnelles en matière de fiabilité.
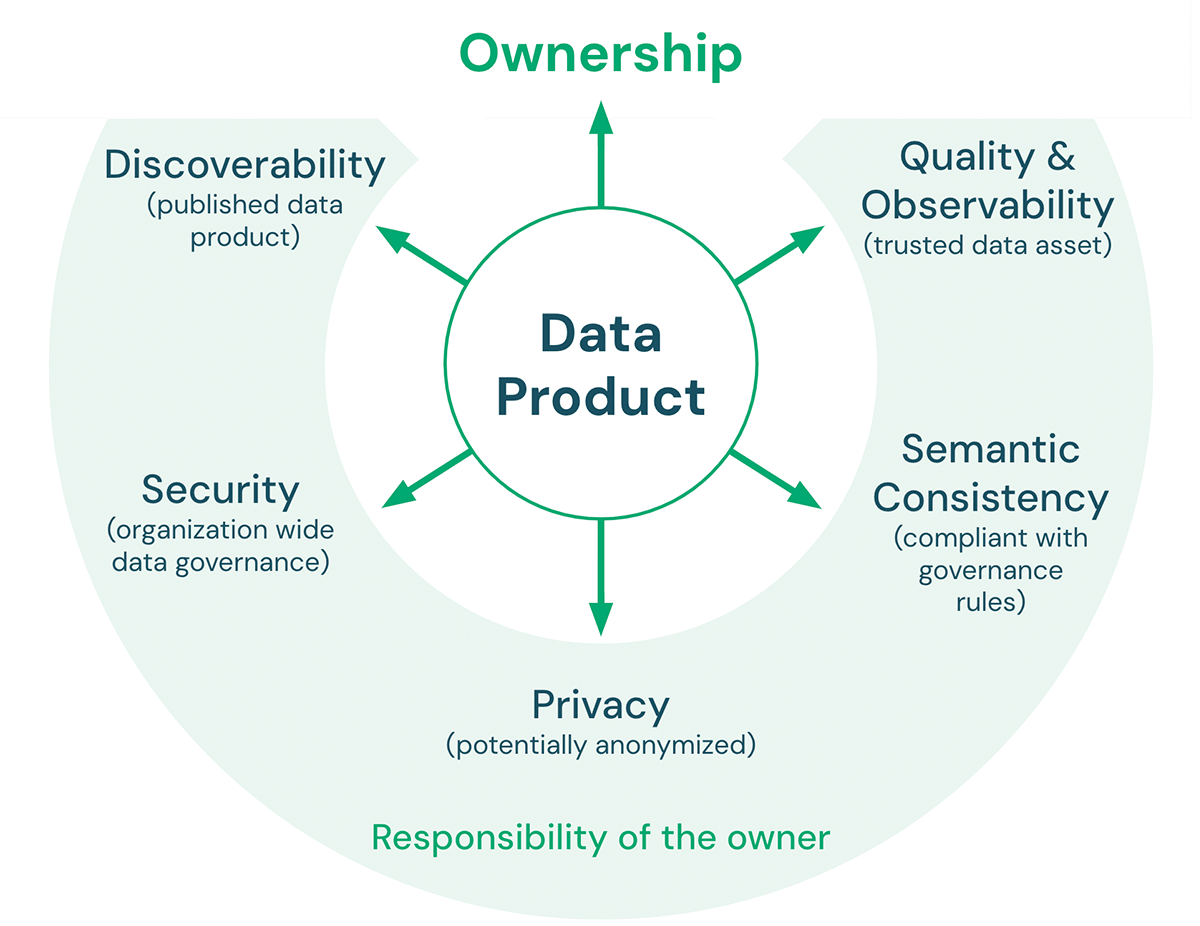
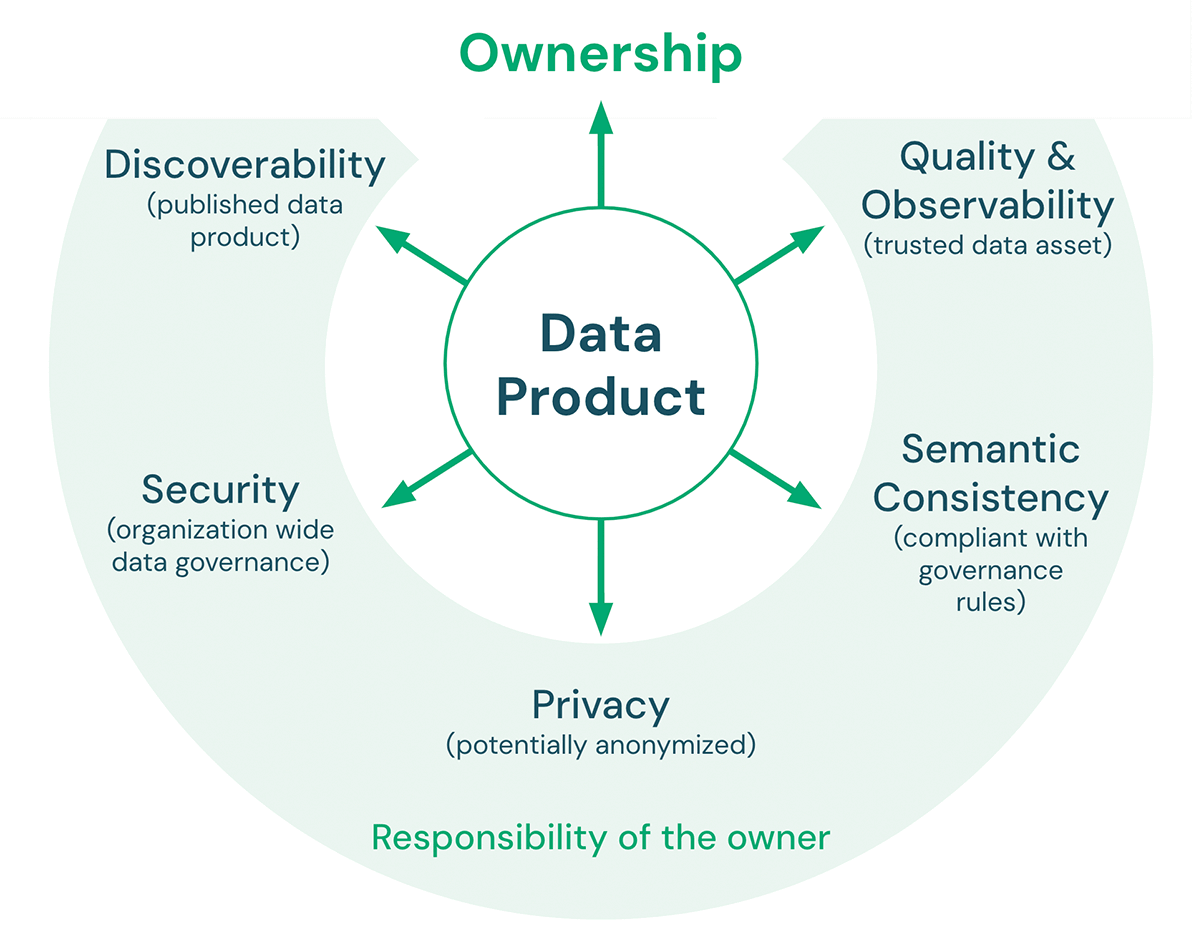
Il y a cinq caractéristiques clés qu'un produit de données doit respecter :
- Qualité et Observabilité : La qualité des données comprend l'exactitude, la cohérence, la fiabilité, la ponctualité, ainsi que la clarté de la documentation. Les métriques de qualité définies concernant le produit de données peuvent être surveillées et exposées pour garantir que la qualité des données attendue est maintenue au fil du temps. L'objectif général est de faire du produit de données une source fiable pour les consommateurs de données.
- Cohérence sémantique : L'objectif d'une architecture lakehouse est de faciliter l'utilisation des données. Par conséquent, les produits de données destinés à être utilisés ensemble doivent être sémantiquement cohérents. En d'autres termes, ils doivent suivre les règles de gouvernance convenues et avoir des définitions communes de la terminologie afin que les consommateurs puissent combiner ces produits de données de manière significative et correcte.
- Confidentialité : La confidentialité concerne la confidentialité et la sécurité des informations, concernant la manière dont les données sont collectées, partagées et utilisées. La confidentialité des données est généralement régie par des réglementations et des lois (par exemple, RGPD, CCPA). La conformité aux règles de confidentialité des données peut inclure des sujets tels que l'anonymisation, le chiffrement, la résidence des données, le marquage des données (par exemple, PII), la limitation du stockage à des environnements spécifiques et la limitation de l'accès à un petit nombre d'employés.
- Sécurité : En plus de disposer d'une plateforme de données approuvée par la sécurité informatique, les propriétaires de produits de données doivent toujours définir, par exemple, les autorisations d'accès (qui peut accéder aux données, avec quels partenaires les données peuvent être partagées, etc.) et les politiques d'utilisation acceptable pour leurs produits de données.
- Découvrabilité : Les produits de données doivent être publiés de manière à ce que tout le monde dans l'organisation puisse les trouver. Cela peut inclure des endroits tels qu'un catalogue de données central ou un marché de données interne. Les propriétaires de produits de données doivent inclure des actifs avec le produit publié qui facilitent la compréhension des données et la manière de les combiner avec d'autres produits de données (par exemple, des exemples de notebooks, des tableaux de bord, etc.).
Cycle de vie du produit de données
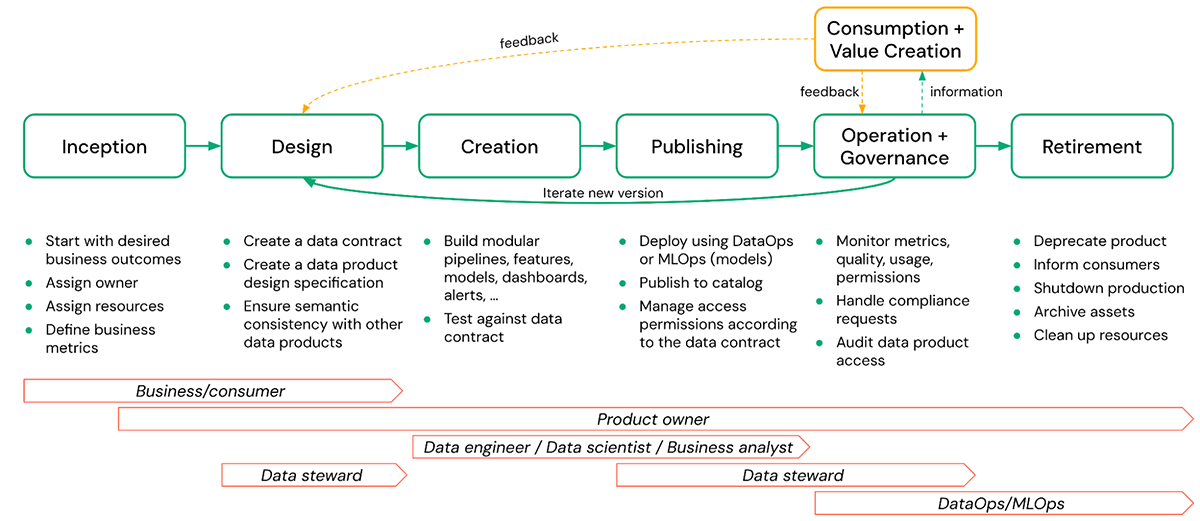
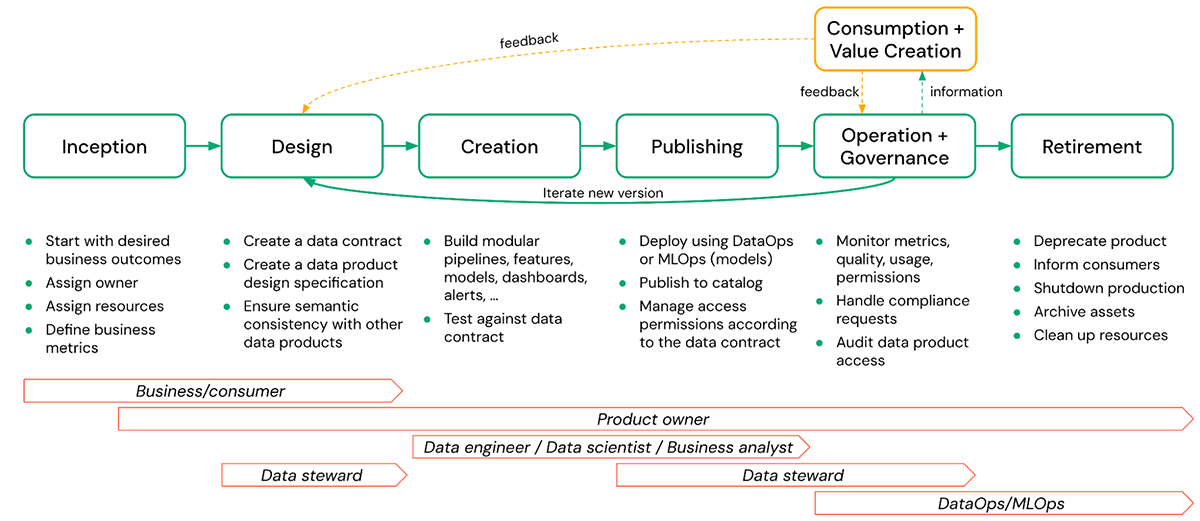
Un cycle de vie typique d'un produit de données comprend les phases suivantes :
- Conception initiale - C'est là que la valeur commerciale d'un produit de données souhaité est définie et qu'un propriétaire est attribué. Les métriques de performance et de qualité doivent également être définies à des fins de surveillance.
- Conception - Dans cette phase, des détails concrets tels que la spécification de conception et les contrats de données sont créés, garantissant la cohérence avec les autres produits de données.
- Création - La création du produit de données réel peut inclure des schémas, des tables, des vues, des modèles, des fichiers arbitraires (volumes), des tableaux de bord, etc., ainsi que les pipelines qui les créent. Cette phase comprend également le test du produit de données résultant par rapport au contrat de données défini.
- Publication - La création et la publication d'un produit de données sont souvent considérées comme identiques, mais elles sont très différentes. Cette phase comprend des activités telles que le déploiement de modèles, la publication d'un schéma dans un catalogue partagé, la gestion des autorisations d'accès conformément au contrat de données, etc. La publication doit impliquer la gestion des versions pour les modifications apportées aux produits de données publiés.
- Exploitation et Gouvernance - L'exploitation implique des activités continues telles que la surveillance de la qualité, des autorisations et des métriques d'utilisation. La partie gouvernance comprend le traitement des demandes liées à la conformité et l'audit de l'accès aux produits de données, etc.
- Consommation et Création de valeur - Le produit de données est utilisé dans l'entreprise pour résoudre une variété de problèmes. Les consommateurs peuvent fournir des commentaires au propriétaire du produit de données en fonction de leur expérience d'utilisation du produit et recommander des améliorations qui pourraient faciliter une création de valeur supplémentaire à l'avenir.
- Retrait - Il peut y avoir plusieurs raisons de retirer un produit de données, comme un manque d'utilisation, le produit de données n'étant plus conforme, etc. Dans tous les cas, le produit de données doit être retiré en douceur. Cela signifie déprécier le produit, informer les consommateurs, archiver les actifs et nettoyer les ressources. Ici, la visibilité sur l'utilisation en aval sera souvent importante et sera grandement facilitée si la lignée est capturée automatiquement.
{kind=link}
Dans la figure ci-dessus, le propriétaire du produit de données est responsable de toutes les phases, de la conception initiale au retrait d'un produit de données. Néanmoins, la responsabilité des tâches individuelles peut être partagée avec d'autres parties prenantes telles que les stewards de données, les ingénieurs de données, etc.
Bonnes pratiques pour l'implémentation de produits de données
La mise en œuvre de produits de données de haute qualité avec Databricks nécessite une approche réfléchie au-delà de la simple exécution technique. Commencez par établir une propriété claire, avec des propriétaires de produits de données dédiés qui comprennent à la fois les besoins commerciaux et les exigences techniques. Définissez des contrats de données complets à l'avance qui incluent des métriques de qualité, des définitions de schéma, des politiques d'utilisation et des paramètres de sécurité pour assurer l'alignement entre les producteurs et les consommateurs.
Lors de la création de pipelines, utilisez Delta Live Tables (DLT) avec des contrôles de qualité implémentés directement dans votre code, en tirant parti des attentes et des contraintes intégrées pour valider les données à chaque étape. Mettez en œuvre une approche de développement par étapes avec des environnements de développement, de test et de production distincts pour garantir la qualité avant la publication. Automatisez la surveillance à l'aide de Lakehouse Monitoring, en configurant des alertes pour les seuils de métriques de qualité afin de détecter les problèmes à un stade précoce.
Documentez en détail dans Unity Catalog, en utilisant à la fois les spécifications techniques et le contexte métier pour aider les utilisateurs à comprendre et à utiliser correctement vos produits de données. Pour une gouvernance efficace, standardisez les conventions de nommage et les métadonnées sur l'ensemble des produits de données afin d'améliorer la découvrabilité et l'interopérabilité. Enfin, mettez en place une boucle de rétroaction formelle avec les consommateurs pour améliorer continuellement vos produits de données en fonction des modèles d'utilisation réels et des besoins des utilisateurs.
La plateforme Databricks Data Intelligence peut être utilisée pour plusieurs des activités impliquées dans le cycle de vie des produits de données :
- Pipelines ETL - Delta Live Tables (DLT) peut être utilisé pour construire des pipelines de données robustes et contrôlés en qualité. Auto Loader et les tables de streaming peuvent être utilisés pour intégrer des données de manière incrémentielle dans la couche Bronze pour les pipelines DLT ou les requêtes Databricks SQL.
- Gouvernance - Unity Catalog de Databricks est riche en fonctionnalités et conçu pour permettre une gouvernance simple et unifiée à l'échelle d'une entreprise. Catalog Explorer peut être utilisé pour la découverte de données et les mécanismes de contrôle d'accès facilitent la publication des produits de données aux consommateurs ciblés. La lignée et les tables système sont automatiquement suivies et essentielles à la gouvernance opérationnelle.
- Surveillance - La surveillance du Lakehouse fournit une solution unique et unifiée pour surveiller la qualité des actifs de données et d'IA. Une telle approche proactive est nécessaire pour satisfaire les termes du contrat de données.
Pour certaines des activités du cycle de vie des produits de données, telles que la conception du produit de données et du contrat de données, Databricks ne dispose pas actuellement de fonctionnalités pour les prendre en charge. Ces processus doivent être effectués en dehors de la plateforme Databricks et les résultats doivent ensuite être documentés dans Unity Catalog une fois le produit de données publié.
Contrats de données
Un contrat de données est un moyen formel d'aligner les domaines et de mettre en œuvre une gouvernance fédérée. Le producteur de données doit le fournir ; cependant, il doit être conçu en tenant compte du consommateur. Le contrat doit être formulé de manière à être consommable par tous les types d'utilisateurs.
Un contrat de données typique a les attributs suivants :
- Description des données (nom, description, systèmes sources, sélection d'attributs, …)
- Schéma des données (tables, colonnes, informations d'anonymisation et de chiffrement, filtres, masques, …) et formats de données (données semi-structurées et non structurées)
- Politiques d'utilisation (balises, PII, directives, résidence des données, …)
- Qualité des données (contrôles de qualité et contraintes appliqués, métriques de qualité, …)
- Sécurité (qui est autorisé à utiliser le produit de données)
- SLA de données (dernière mise à jour, dates d'expiration, durée de conservation, …)
- Responsabilités (propriétaire, mainteneur, contact d'escalade, processus de changement, …)
En outre, des actifs de support tels que des notebooks, des tableaux de bord, etc. peuvent être fournis afin d'aider le consommateur à comprendre et à analyser le produit de données, facilitant ainsi une adoption plus aisée.
Équipe de gouvernance des données
Une équipe de gouvernance des données dans une entreprise se compose généralement de représentants de différents groupes tels que les propriétaires métier, les experts en conformité et sécurité, et les professionnels des données. Cette équipe doit agir comme un Centre d'Excellence (CoE) pour les questions de conformité et de sécurité des données et soutenir le propriétaire du produit de données qui est responsable du produit de données. Ils jouent un rôle crucial dans la définition du contrat de données en étendant les politiques d'utilisation ainsi qu'en influençant la décision de qui est autorisé à utiliser le produit de données. Pour les grandes organisations, une telle équipe peut aider à piloter et à standardiser le processus de définition du contrat de données en alignement avec les fonctions mondiales telles qu'un bureau de gestion des données.
Publication et certification
Malgré les contrats de données établis, la gouvernance des produits de données reste un sujet vaste, englobant des aspects tels que les contrôles d'accès, la classification des informations personnelles identifiables (PII) et diverses politiques d'utilisation, qui peuvent tous différer selon les organisations. Cependant, une tendance constante que nous avons observée concerne la publication des produits de données. À mesure que les consommateurs rencontrent un nombre croissant de jeux de données, ils exigent souvent l'assurance que les données sont organisées, standardisées et officiellement approuvées pour utilisation. Par exemple, un cas d'utilisation de reporting ou de gestion des données de référence au sein d'une grande organisation pourrait nécessiter un degré élevé de cohérence sémantique et d'interopérabilité entre les divers actifs de données de l'entreprise.
C'est là que le concept de 'certification' d'un produit de données peut devenir précieux pour certains produits de données. Dans ce processus, les producteurs de données peuvent d'abord proposer une spécification de contrat de données, généralement soumise à l'examen d'un responsable ou d'une équipe de gouvernance des données. Après approbation, des processus d'intégration et de déploiement continus (CI/CD) peuvent être exécutés pour déployer des pipelines de production qui écrivent physiquement les données sur les comptes de stockage cloud du client. Ces données peuvent ensuite être publiées et facilement découvertes via des tables, des vues ou même des volumes pour les données non tabulaires dans Unity Catalog. Dans ce contexte, Unity Catalog prend en charge l'utilisation de balises ainsi que de markdown pour indiquer le statut de certification et les détails d'un produit de données.
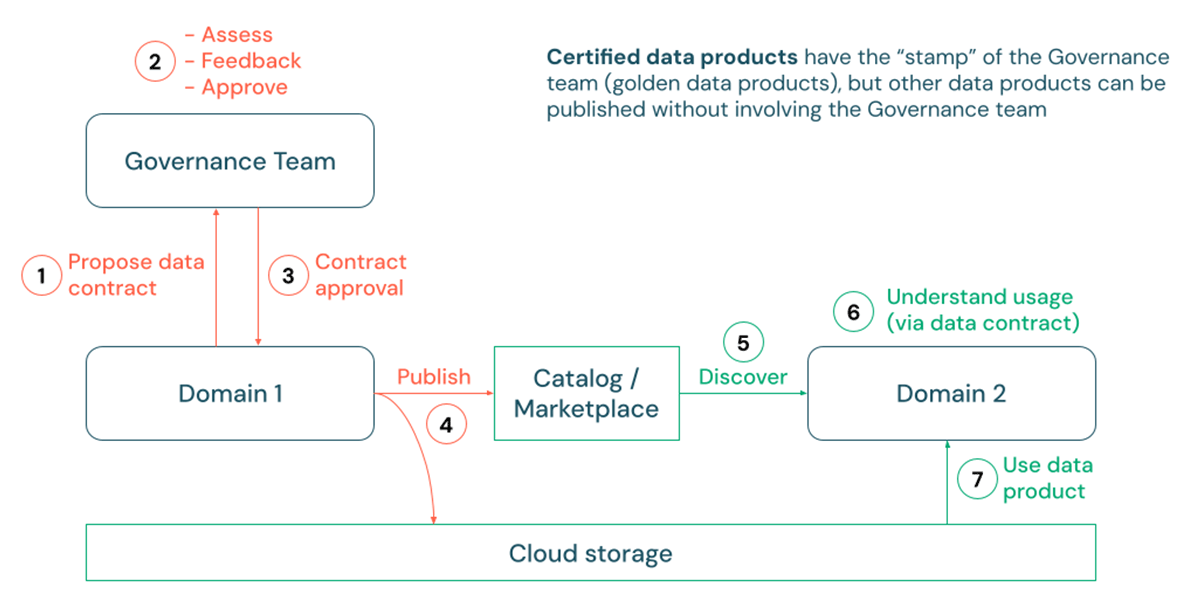
{kind=link}
Certains clients peuvent même choisir de promouvoir leurs produits de données certifiés en publiant une liste privée correspondante sur le Databricks Marketplace avec des guides complets et des exemples d'utilisation. De plus, les API REST de Databricks et les intégrations avec des solutions de catalogue d'entreprise telles qu'Alation, Atlan et Collibra facilitent également la découvrabilité des produits de données certifiés via plusieurs canaux, même ceux extérieurs à Databricks.
Cas d'utilisation et réussites
Automobile : Plateforme d'intelligence véhicule de Rivian
Rivian, le fabricant de véhicules électriques, utilise Databricks pour traiter les données des capteurs IoT de plus de 25 000 véhicules en circulation, chacun générant des téraoctets de données par jour. Leur équipe de systèmes avancés d'aide à la conduite (ADAS) utilise cette plateforme pour analyser les données télémétriques, y compris les informations sur l'inclinaison, le roulis, la vitesse, la suspension et l'activité des airbags, ce qui aide Rivian à comprendre les performances du véhicule et les modèles de conduite. En tirant parti de la plateforme Databricks Lakehouse, ils ont obtenu une augmentation de 30 % à 50 % des performances d'exécution, ce qui a permis d'obtenir des informations plus rapides et une meilleure précision des modèles. Cette approche axée sur les données permet à Rivian de mettre en œuvre la maintenance prédictive, d'optimiser la fiabilité des composants et d'améliorer continuellement l'expérience de conduite du client.
Santé : Personnalisation des ordonnances de Walgreens
Walgreens, l'une des plus grandes chaînes de pharmacies d'Amérique, a transformé son expérience client en utilisant Databricks pour traiter les données de prescription à grande échelle. Avec plus de 825 millions d'ordonnances délivrées annuellement dans près de 9 000 points de vente, Walgreens a construit sa plateforme d'information, de données et d'analyse (IDI) sur Databricks pour traiter 40 000 événements de données par seconde. Cela a optimisé leur chaîne d'approvisionnement en ajustant les niveaux de stock pour économiser des millions de dollars et a augmenté la productivité des pharmaciens de 20 %. La plateforme permet aux pharmaciens de fournir de meilleurs soins grâce à des profils patients robustes qui incluent des alertes d'interaction médicamenteuse, des changements dans les profils médicamenteux et d'autres informations critiques pour une gestion plus sûre des ordonnances.
Fabrication : Analyses alimentées par l'IA de Mahindra
Mahindra & Mahindra Limited, un conglomérat manufacturier mondial, a mis en œuvre des solutions d'IA au niveau de l'entreprise en utilisant Databricks pour améliorer ses opérations commerciales. Leur bot GenAI pour les analystes financiers a permis de réduire de 70 % le temps consacré aux tâches routinières, permettant aux équipes de se concentrer sur des initiatives stratégiques à plus forte valeur ajoutée. L'entreprise utilise la plateforme Databricks Data Intelligence pour de nombreux cas d'utilisation, y compris un chatbot Voix du Client construit avec le LLM open source DBRX de Databricks qui intègre des données internes via Delta Lake et des données externes provenant de sites Web et de médias sociaux. Cette approche complète aide Mahindra à stimuler la croissance, à améliorer l'expérience client et à optimiser l'efficacité opérationnelle.
Télécommunications : L'architecture Data Mesh de T-Mobile
T-Mobile a mis en œuvre avec succès une architecture data mesh en utilisant Databricks pour démocratiser l'accès aux données tout en maintenant la sécurité et la gouvernance. Le géant des télécommunications a intégré son lakehouse dans un Data Mesh en utilisant Unity Catalog et Delta Sharing, permettant aux équipes de toute l'entreprise d'accéder et d'utiliser les données tout en maintenant un modèle de sécurité rationnel et facile à comprendre. Cette approche a permis aux équipes de domaine de créer et de gérer leurs propres produits de données tout en assurant une gouvernance cohérente, accélérant les initiatives d'analyse dans toute l'organisation et améliorant la prise de décision basée sur les données.
Tendances futures des produits de données
L'avenir des produits de données est façonné par plusieurs tendances émergentes qui auront un impact sur la manière dont les organisations exploitent des plateformes comme Databricks. Les produits de données en temps réel gagnent en importance à mesure que les entreprises exigent des informations de plus en plus actuelles, les architectures de streaming devenant la norme pour les produits de données opérationnels critiques. Nous assistons également à l'essor de la création de produits de données en libre-service, où les experts du domaine métier utilisent des interfaces low-code/no-code pour définir et construire des produits de données tout en maintenant des garde-fous de gouvernance.
Les produits de données enrichis par l'IA, qui intègrent automatiquement des fonctionnalités et des informations de machine learning, deviennent plus courants, brouillant la frontière entre les données traditionnelles et les actifs d'IA. Les architectures data mesh arrivent à maturité, les organisations mettant en œuvre une gouvernance informatique fédérée qui équilibre les normes centrales et l'autonomie des domaines. Des produits de données inter-organisationnels qui s'étendent en toute sécurité au-delà des frontières de l'entreprise émergent, les data clean rooms et le calcul préservant la confidentialité permettant de nouvelles informations collaboratives.
Les contrats de données évoluent pour inclure des garanties de qualité, des contrôles de confidentialité et des droits d'utilisation plus sophistiqués, devenant des spécifications exécutables plutôt que de la documentation statique. L'analytique embarquée dans les applications opérationnelles se développe, avec des produits de données conçus spécifiquement pour alimenter les informations dans l'application plutôt que des environnements analytiques séparés. Enfin, des métriques de durabilité sont intégrées aux produits de données, suivant l'impact environnemental aux côtés des KPI commerciaux traditionnels pour soutenir les rapports ESG et les initiatives vertes.
Conclusion
La formulation de produits de données et de contrats de données peut devenir un exercice complexe au sein d'une grande entreprise. Compte tenu de l'émergence de nouvelles technologies pour interagir avec les données, associée aux exigences commerciales et réglementaires modernes, les spécifications des produits de données et des contrats évoluent continuellement. Aujourd'hui, Databricks Marketplace et Unity Catalog servent de composants essentiels pour l'expérience de découverte et d'intégration des données pour les consommateurs de données. Pour les producteurs de données, Unity Catalog offre des fonctionnalités de gouvernance d'entreprise essentielles, notamment la lignée, l'audit et les contrôles d'accès.
Alors que les produits de données s'étendent au-delà des simples tables ou tableaux de bord pour englober les modèles d'IA, les flux et plus encore, les clients peuvent bénéficier d'une expérience de gouvernance unifiée et cohérente sur Databricks pour tous les principaux personas utilisateurs.
Les aspects clés des produits de données d'entreprise mis en évidence dans ce blog peuvent servir de principes directeurs pour aborder le sujet. Pour en savoir plus sur la construction de produits de données de haute qualité à l'aide de la plateforme Databricks Data Intelligence, contactez votre représentant Databricks.
FAQ
Quelle est la différence entre un produit de données et un jeu de données ordinaire ?
Un produit de données va au-delà de la simple fourniture de données ; il est conçu en tenant compte des besoins spécifiques des utilisateurs, comprend des garanties de qualité, de la documentation et des éléments de support. Contrairement à un jeu de données ordinaire, un produit de données a une propriété claire, des SLA définis et est géré activement tout au long de son cycle de vie pour s'assurer qu'il continue de répondre aux besoins des consommateurs.
Qui devrait posséder les produits de données dans notre organisation ?
Les produits de données doivent être détenus par des personnes qui comprennent à la fois le domaine métier et les aspects techniques des données. Ces propriétaires de produits de données sont responsables de la qualité, de l'utilisabilité et de l'alignement avec les objectifs commerciaux. Selon votre structure organisationnelle, ils peuvent se trouver au sein des domaines métier (dans une approche data mesh) ou au sein d'une équipe de données centrale.
Comment mesurer le succès de nos produits de données ?
Les métriques de succès doivent inclure à la fois des aspects techniques (qualité, disponibilité, performance) et des mesures d'impact commercial. Suivez les modèles d'utilisation, la satisfaction des utilisateurs, le temps nécessaire pour obtenir des informations pour les consommateurs et les résultats commerciaux directs permis par le produit de données. Établissez des métriques de référence avant la mise en œuvre et mesurez les améliorations au fil du temps.
Quel rôle Unity Catalog joue-t-il dans la gestion des produits de données ?
Unity Catalog sert de base à la gouvernance des produits de données en fournissant une gestion centralisée des métadonnées, des contrôles d'accès, un suivi de la lignée et des capacités de découverte. Il vous permet de mettre en œuvre des contrats de données grâce à des fonctionnalités telles que le balisage, les commentaires et les définitions de schéma, tout en fournissant l'auditabilité et les contrôles de conformité nécessaires aux produits de données d'entreprise.
Comment gérer les modifications apportées aux produits de données publiés ?
Mettez en œuvre des processus formels de versioning et de gestion des modifications pour les produits de données. Communiquez les modifications aux consommateurs à l'avance, maintenez la compatibilité ascendante dans la mesure du possible et fournissez des chemins de migration pour les modifications non rétrocompatibles. Utilisez les fonctionnalités d'Unity Catalog pour suivre les versions et gérer la transition entre elles.
Pouvons-nous créer des produits de données sans adopter une architecture data mesh complète ?
Absolument. Bien que le data mesh mette l'accent sur la propriété du domaine des produits de données, vous pouvez appliquer la pensée produit à vos actifs de données, quelle que soit votre structure organisationnelle. Concentrez-vous sur les besoins des utilisateurs, la qualité et l'utilisabilité de vos données, et mettez en œuvre une propriété et une gouvernance claires — ces principes créent de la valeur même sans une mise en œuvre complète du data mesh.
Comment garantir que nos produits de données restent conformes aux réglementations évolutives ?
Intégrez la conformité dans le cycle de vie de vos produits de données, avec des revues régulières par votre équipe de gouvernance. Mettez en œuvre des contrôles basés sur les métadonnées dans Unity Catalog pour appliquer automatiquement les politiques, et utilisez les fonctionnalités de lignée pour comprendre l'impact des changements réglementaires sur vos produits de données. Documentez les exigences de conformité dans vos contrats de données et surveillez leur respect grâce aux journaux d'audit.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.