Création d'une application en quasi-temps réel avec Zerobus Ingest et Lakebase
Découvrez comment simplifier l'ingestion de données pour les cas d'usage IoT, clickstream et télémétriques sur Databricks
par Grant Doyle et Benjamin Nwokeleme
- Découvrez comment Zerobus Ingest élimine les architectures à sauts multiples pour les cas d'usage de l'IoT, des flux de clics et de la télémétrie
- Découvrez comment Lakebase élimine les pipelines ETL complexes et personnalisés et intègre les données transactionnelles pour les cas d'usage opérationnels
- Créez un tableau de bord en temps quasi réel à l'aide de Zerobus Ingest, Lakebase et Databricks Apps
Les données événementielles de l'IoT, des flux de clics et de la télémétrie des applications alimentent des analytiques et une IA critiques en temps réel lorsqu'elles sont associées à la Databricks Data Intelligence Platform. Traditionnellement, l'ingestion de ces données nécessitait plusieurs sauts de données (bus de messages, tâches Spark) entre la source de données et le lakehouse. Cela ajoute une surcharge opérationnelle, une duplication des données, requiert une expertise spécialisée et s'avère généralement inefficace lorsque le lakehouse est la seule destination pour ces données.
Une fois que ces données arrivent dans le lakehouse, elles sont transformées et organisées pour des cas d'utilisation analytiques en aval. Cependant, les équipes ont souvent besoin de fournir ces données analytiques pour des cas d'utilisation opérationnels, et la création de ces applications personnalisées peut être un processus laborieux. Ils doivent provisionner et maintenir des composants d'infrastructure essentiels comme une instance de base de données OLTP dédiée (avec le réseau, le monitoring, les sauvegardes, etc.). De plus, elles doivent gérer le processus de reverse ETL pour les données analytiques dans la base de données afin de les réexposer dans l'application en temps réel. Cela exigerait que l'équipe construise des pipelines supplémentaires pour transférer les données du lakehouse vers la base de données opérationnelle externe. Ces pipelines s'ajoutent à l'infrastructure que les développeurs doivent configurer et maintenir, ce qui détourne leur attention de l'objectif principal : créer les applications pour leur entreprise.
Comment Databricks simplifie-t-il à la fois l'ingestion des données dans le lakehouse et la fourniture de données gold pour prendre en charge les charges de travail opérationnelles ?
Découvrez Zerobus Ingest et Lakebase.
À propos de Zerobus Ingest
Zerobus Ingest, qui fait partie de Lakeflow Connect, est un ensemble d'API qui offre un moyen simplifié de transférer directement les données événementielles dans le lakehouse. En éliminant entièrement la couche de bus de messages à récepteur unique, Zerobus Ingest réduit l'infrastructure, simplifie les Opérations et permet une ingestion quasi en temps réel à grande échelle. Ainsi, Zerobus Ingest rend plus facile que jamais l'exploitation de la valeur de vos données.
L'application productrice de données doit spécifier une table cible pour l'écriture des données, s'assurer que les messages correspondent correctement au schéma de la table, puis lancer un flux pour envoyer les données à Databricks. Côté Databricks, l'API valide les schémas du message et de la table, écrit les données dans la table cible et envoie un accusé de réception au client indiquant que les données ont été persistées.
Principaux avantages de Zerobus Ingest :
- Architecture simplifiée : élimine le besoin de flux de travail complexes et de duplication des données.
- Performances à grande échelle : prend en charge l'ingestion en quasi-temps réel (jusqu'à 5 secondes) et permet à des milliers de clients d'écrire dans la même table (débit jusqu'à 100 Mo/s par client).
- Intégration avec la Data Intelligence Platform : accélère la création de valeur en permettant aux équipes d'appliquer des outils d'analytique et d'IA, tels que MLflow pour la détection de fraude, directement sur leurs données.
Capacité d'ingestion Zerobus | Spécifications |
Latence d'ingestion | Quasi-temps réel (≤5 secondes) |
Débit maximal par client | Jusqu'à 100 Mo/s |
Clients simultanés | Plusieurs milliers par table |
Latence de synchronisation continue (Delta → Lakebase) | 10–15 secondes |
Latence d'écriture foreach en temps réel | 200–300 millisecondes |
À propos de Lakebase
Lakebase est une base de données Postgres entièrement managée, serverless, évolutive et intégrée à la Databricks Platform, conçue pour les charges de travail opérationnelles et transactionnelles à faible latence qui s'exécutent directement sur les mêmes données que celles qui alimentent les cas d'usage analytiques et d'IA.
La séparation complète du compute et du stockage permet un provisionnement rapide et une mise à l'échelle automatique élastique. L'intégration de Lakebase à la Databricks Platform est un différenciateur majeur par rapport aux bases de données traditionnelles, car Lakebase rend les données du Lakehouse directement accessibles aux applications en temps réel et à l'IA, sans nécessiter de pipelines de données personnalisés complexes. Il est conçu pour répondre aux exigences de création de bases de données, de latence des requêtes et de simultanéité afin d'alimenter les applications d'entreprise et les charges de travail agentiques. Enfin, il permet aux développeurs de contrôler facilement les versions et de brancher des bases de données comme du code.
Principaux avantages de Lakebase :
- Synchronisation automatique des données : Capacité à synchroniser facilement les données depuis le Lakehouse (couche analytique) vers Lakebase de manière instantanée, planifiée ou continue, sans avoir besoin de pipelines externes complexes.
- Intégration avec la Databricks Platform : Lakebase s'intègre avec Unity Catalog, Lakeflow Connect, Spark Declarative Pipelines, Databricks Apps, et plus encore.
- Autorisations et gouvernance intégrées : Gestion cohérente des rôles et des autorisations pour les données opérationnelles et analytiques. Les autorisations natives de Postgres peuvent toujours être maintenues via le protocole Postgres.
Ensemble, ces outils permettent aux clients d'ingérer des données de plusieurs systèmes directement dans des tables Delta et de mettre en œuvre des cas d'usage ETL inversé à grande échelle. Ensuite, nous allons voir comment utiliser ces technologies pour implémenter une application en temps quasi réel !
Comment créer une application en quasi-temps réel
À titre d'exemple pratique, aidons « Data Diners », une entreprise de livraison de repas, à doter son personnel d'encadrement d'une application permettant de suivre l'activité des drivers et les livraisons de commandes en temps réel. Actuellement, ils manquent de cette visibilité, ce qui limite leur capacité à atténuer les problèmes lorsqu'ils surviennent pendant les livraisons.
En quoi une application en temps réel est-elle précieuse ?
- Visibilité opérationnelle : la direction peut voir instantanément où se trouve chaque chauffeur et la progression de ses livraisons. Cela signifie moins d'angles morts en cas de commandes en retard ou lorsqu'un chauffeur a besoin d'aide.
- Atténuation des problèmes : les données de localisation et de statut en temps réel permettent aux répartiteurs de réaffecter les chauffeurs, d'ajuster les priorités ou de contacter les clients de manière proactive en cas de retard, réduisant ainsi les livraisons manquées ou tardives.
Voyons comment construire cela avec Zerobus Ingest, Lakebase et Databricks Apps sur la Data Intelligence Platform !
Vue d'ensemble de l'architecture de l'application
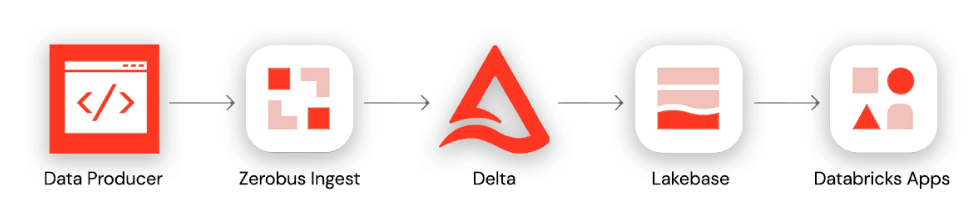
Cette architecture de bout en bout se déroule en quatre étapes : (1) Un producteur de données utilise le SDK Zerobus pour écrire des événements directement dans une table Delta dans Databricks Unity Catalog. (2) Un pipeline de synchronisation continue pousse les enregistrements mis à jour de la table Delta vers une instance Lakebase Postgres. (3) Un backend FastAPI se connecte à Lakebase via des WebSockets pour streamer des mises à jour en temps réel. (4) Une application front-end basée sur Databricks Apps visualise les données en direct pour les utilisateurs finaux.
Pour commencer avec notre producteur de données, l'application « data diner » sur le téléphone du driver émet des données de télémétrie GPS sur sa position (coordonnées de latitude et de longitude) pendant la livraison des commandes. Ces données seront envoyées à une passerelle d'API, qui les enverra finalement au service suivant dans l'architecture d'ingestion.
Avec le SDK Zerobus, nous pouvons rapidement écrire un client pour transférer les événements de la passerelle API vers notre table cible. La table cible étant mise à jour en quasi-temps réel, nous pouvons ensuite créer un pipeline de synchronisation continue pour mettre à jour nos tables Lakebase. Enfin, en tirant parti de Databricks Apps, nous pouvons déployer un backend FastAPI qui utilise des WebSockets pour stream les mises à jour en temps réel depuis Postgres, ainsi qu'une application front-end pour visualiser le flux de données en direct.
Avant l'introduction du SDK Zerobus, l'architecture de streaming aurait inclus plusieurs sauts avant d'arriver dans la table cible. Notre passerelle API aurait dû décharger les données dans une zone de transit comme Kafka, et nous aurions eu besoin de Spark Structured Streaming pour écrire les transactions dans la table cible. Tout cela ajoute une complexité inutile, d'autant plus que la seule destination est le Lakehouse. L'architecture ci-dessus montre plutôt comment la Databricks Data Intelligence Platform simplifie le développement d'applications d'entreprise de bout en bout — de l'ingestion des données à l'analytique en temps réel et à la mise en œuvre d'applications interactives.
Démarrer
Prérequis : ce dont vous avez besoin
- Lakebase: désormais disponible sur AWS et Azure.
- Zerobus Ingest: Disponibilité générale sur AWS et Azure
- Databricks Apps: Vérifiez que vous disposez des autorisations nécessaires pour créer des Databricks Apps.
Étape 1 : Créer une table cible dans Databricks Unity Catalog
Les données d'événement produites par les applications clientes seront stockées dans une table Delta. Utilisez le code ci-dessous pour créer cette table cible dans le catalogue et le schéma de votre choix.
Étape 2 : S'authentifier à l'aide d'OAUTH
Étape 3 : Créer le client Zerobus et ingérer les données dans la table cible
Le code ci-dessous envoie les données des événements de télémétrie dans Databricks à l'aide de l'API Zerobus.
Limitation et solution de contournement du flux de données modifiées (CDF)
À ce jour, Zerobus Ingest ne prend pas en charge CDF. CDF permet à Databricks d'enregistrer les événements de modification pour les nouvelles données écrites dans une table delta. Ces événements de modification peuvent être des insertions, des suppressions ou des mises à jour. Ces événements de modification peuvent ensuite être utilisés pour mettre à jour les tables synchronisées dans Lakebase. Pour synchroniser les données avec Lakebase et poursuivre notre projet, nous allons écrire les données de la table cible dans une nouvelle table et activer le CDF sur cette table.
Étape 4 : Provisionner Lakebase et synchroniser les données avec l'instance de base de données
Pour alimenter l'application, nous allons synchroniser les données de cette nouvelle table compatible CDF dans une instance Lakebase. Nous synchroniserons cette table en continu pour alimenter notre tableau de bord en temps quasi réel.
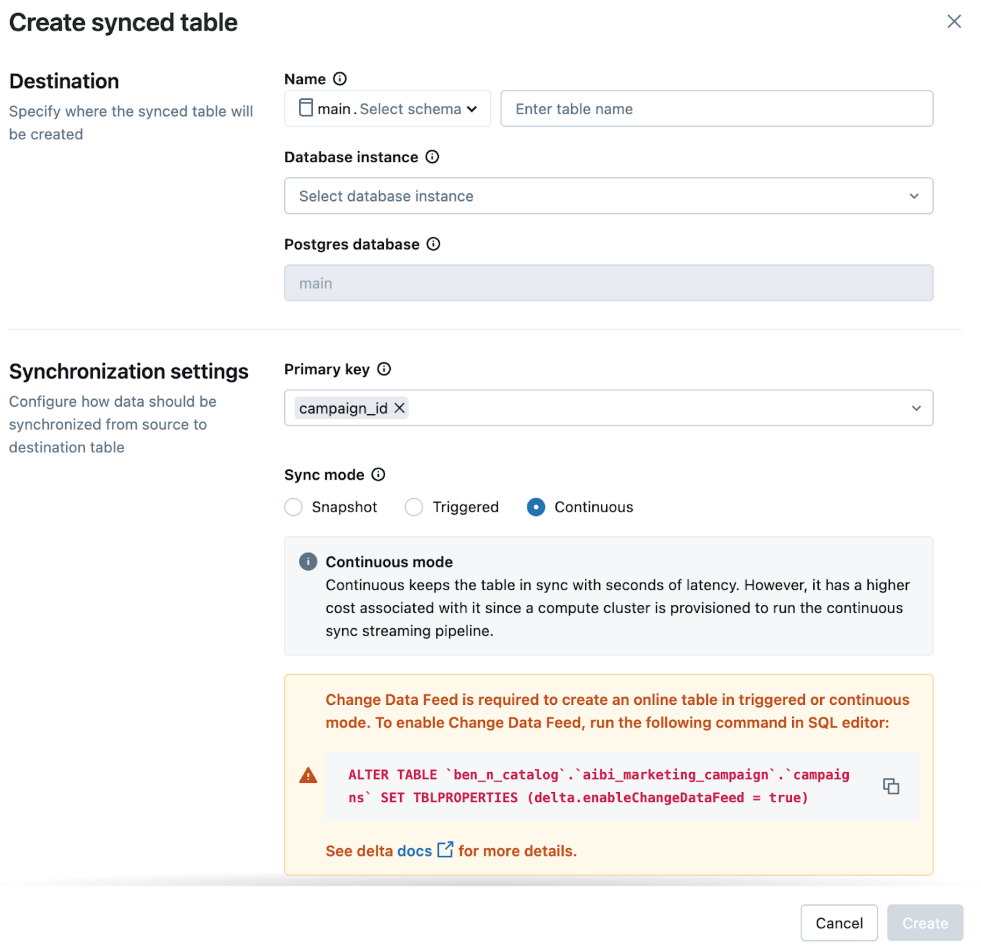
Dans l'interface utilisateur, nous sélectionnons :
- Mode de synchronisation : Continu pour des mises à jour à faible latence
- Clé primaire : table_primary_key
Cela garantit que l'application reflète les données les plus récentes avec un délai minimal.
Remarque : Vous pouvez également créer le pipeline de synchronisation par programmation à l'aide du SDK Databricks.
Mode temps réel via foreach writer
Les synchronisations continues de Delta vers Lakebase ont une latence de 10 à 15 secondes. Par conséquent, si vous avez besoin d'une latence plus faible, envisagez d'utiliser le mode temps réel via l'enregistreur ForeachWriter pour synchroniser les données directement depuis un DataFrame vers une table Lakebase. Les données seront ainsi synchronisées en quelques millisecondes.
Consultez le code Lakebase ForeachWriter sur Github.
Étape 5 : Créer l'application avec FastAPI ou un autre framework de votre choix
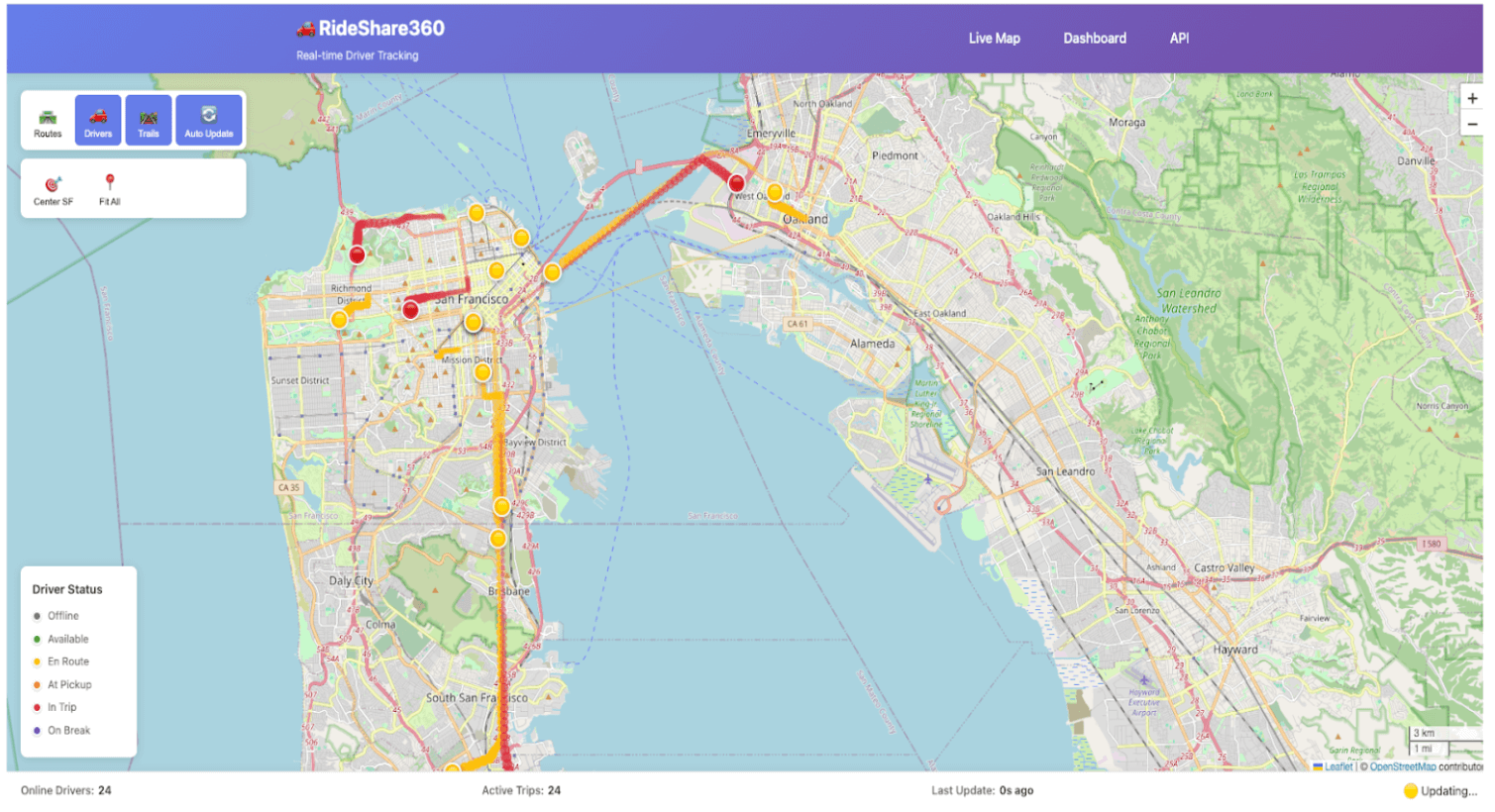
Une fois vos données synchronisées avec Lakebase, vous pouvez maintenant déployer votre code pour créer votre application. Dans cet exemple, l'application récupère les données d'événements de Lakebase et les utilise pour mettre à jour une application en temps réel afin de suivre l'activité d'un driver pendant ses livraisons de repas. Lisez la documentation Prise en main des Databricks Apps pour en savoir plus sur la création d'applications sur Databricks.
Ressources supplémentaires
Consultez d'autres tutoriels, démos et accélérateurs de solution pour créer vos propres applications pour vos besoins spécifiques.
- Créez une application de bout en bout : un simulateur de navigation en temps réel suit une flotte de voiliers à l'aide du SDK Python et de l'API REST, avec Databricks Apps et Databricks Asset Bundles. Lire l'article de blog
- Créez une solution de jumeaux digital : Découvrez comment optimiser l'efficacité opérationnelle, accélérer les insight en temps réel et la maintenance prédictive avec les Databricks Apps et Lakebase. Lire l'article de blog
En savoir plus sur Zerobus Ingest, Lakebase et Databricks Apps dans la documentation technique. Vous pouvez également consulter le Databricks Apps Cookbook et la Cookbook Resource Collection.
Conclusion
L'IoT, le clickstream, la télémétrie et les applications similaires génèrent des milliards de points de données chaque jour, qui sont utilisés pour alimenter des applications critiques en temps réel dans plusieurs Secteurs d'activité. Par conséquent, il est primordial de simplifier l'ingestion à partir de ces systèmes. Zerobus Ingest offre un moyen simplifié d'envoyer les données d'événement directement de ces systèmes vers le lakehouse tout en garantissant des performances élevées. Il s'associe parfaitement à Lakebase pour simplifier le développement d'applications d'entreprise de bout en bout.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.