L'intelligence des opérations cliniques appartient au Lakehouse
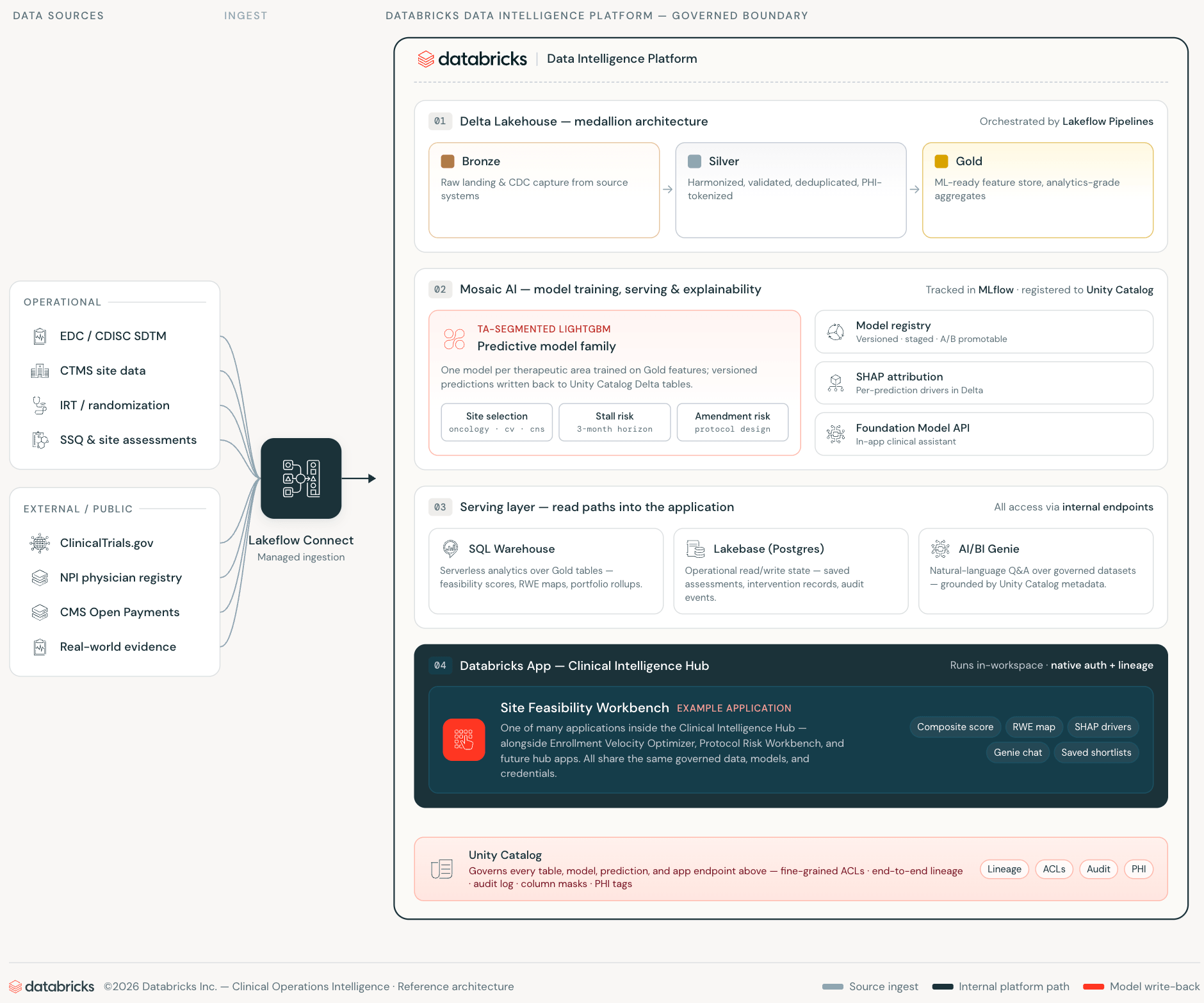
Comment les applications Databricks, Lakebase et AI/BI Genie éliminent la pile d'intégration entre les données cliniques et les applications de support de décision — et pourquoi ce changement d'architecture est ce qui manquait aux opérations cliniques.
- Ce que c'est : Le Site Feasibility Workbench est une application Databricks open-source qui exécute la sélection des sites d'essais cliniques entièrement dans l'espace de travail Databricks — combinant la notation des sites pilotée par l'IA, Lakebase pour l'état opérationnel et AI/BI Genie pour l'accès aux données en langage naturel, sans appels API externes ni pipelines de synchronisation.
- Le défi qu'il résout : 37 % des sites investigateurs n'atteignent pas leurs objectifs d'enrôlement, et la cause profonde est architecturale — les données des opérations cliniques et les applications qui les utilisent résident dans des systèmes déconnectés, forçant les décisions dans des feuilles de calcul et créant des frais d'intégration, une prolifération des identifiants et un décalage de synchronisation qui érodent la confiance dans les données.
- Résultats et retombées : Les modèles LightGBM segmentés par TA, entraînés sur l'historique de votre propre CTMS, EDC et IRT — et non sur des moyennes industrielles — produisent des scores qui s'améliorent à mesure que votre portefeuille grandit, avec des explications pilotées par SHAP stockées sous forme de tables Delta gouvernées et versionnées. Chaque prédiction porte une attribution pilotée par SHAP stockée sous forme de table Delta gouvernée, rendant la logique du modèle aussi auditable et versionnée que le score lui-même.
Le problème des données cliniques n'est pas un problème de stockage. La plupart des organisations disposent déjà d'un entrepôt de données, d'un CTMS, d'un EDC et, en aval, d'une couche BI. Le problème est qu'aucun de ces systèmes ne communique entre eux d'une manière qui soutienne les décisions réelles que les équipes cliniques doivent prendre — et donc les décisions sont prises dans des feuilles de calcul à la place.
Aujourd'hui, nous publions le Site Feasibility Workbench en tant qu'application Databricks entièrement open-source — pour montrer à quoi ressemble l'intelligence des opérations cliniques lorsque l'application, les modèles et les données résident sur la même plateforme. Le Tufts Center for the Study of Drug Development a documenté que 37 % des sites investigateurs activés ont recruté moins de patients que leurs objectifs, et 11 % supplémentaires n'ont recruté aucun patient — l'effet combiné étant que 53 % des essais ont dépassé leurs délais de recrutement prévus, un essai sur six prenant plus de deux fois plus de temps que prévu (Lamberti et al. ; les rapports d'impact ultérieurs du CSDD continuent de suivre les sous-performances à des niveaux similaires). Jusqu'à 500 000 $ par jour de ventes de médicaments non réalisées et 40 000 $ par jour de coûts directs d'essai, la sous-performance chronique des sites est l'un des moteurs de coûts les plus importants dans le développement de médicaments. Ce taux de sous-performance combiné est resté essentiellement stable pendant au moins deux décennies. Les outils ne sont pas le problème. L'architecture l'est.
Les équipes des opérations cliniques n'ont pas besoin de plus de tableaux de bord connectés aux systèmes existants. Elles ont besoin que leurs applications de support décisionnel résident là où se trouvent leurs données et leurs modèles — afin que la boucle de rétroaction entre une prédiction et le résultat opérationnel qui la valide se ferme réellement.
L'argument de l'architecture
L'approche conventionnelle du support décisionnel clinique ressemble à ceci : les données analytiques résident dans un entrepôt de données ou un Lakehouse. Une base de données d'applications distincte contient l'état opérationnel. Un pipeline les maintient lâchement synchronisés. Une application web se situe devant les deux, ajoutant une harmonisation sémantique dans la couche Silver. Chaque couche introduit une surcharge d'intégration, une surface d'attaque des identifiants et un décalage de synchronisation qui érode la confiance dans les données affichées par l'application.
Les applications Databricks, Lakebase et AI/BI Genie éliminent chacune de ces couches — non pas en les abstrayant, mais en les rendant inutiles.
Les applications Databricks exécutent l'application web à l'intérieur de l'espace de travail. L'application s'authentifie en tant que principal de service de l'espace de travail de première classe, interroge Unity Catalog via l'API d'instructions SQL et appelle AI/BI Genie via l'API REST de l'espace de travail — le tout sur des connexions internes. Les données des opérations cliniques ne franchissent jamais la limite de l'espace de travail. L'application hérite des contrôles d'accès d'Unity Catalog sans aucune configuration supplémentaire.
Lakebase est la couche de base de données opérationnelle — PostgreSQL géré qui peut passer à zéro lorsqu'il est inactif, provisionné et authentifié entièrement au sein du système d'identité de l'espace de travail. Alors qu'une application traditionnelle nécessiterait une instance RDS gérée séparément avec son propre schéma, ses travaux de synchronisation et sa rotation d'identifiants, Lakebase se trouve sur la même plateforme où résident les données et les modèles.
AI/BI Genie comble le dernier écart : accès en langage naturel aux données gouvernées, intégré directement dans le flux de travail de l'application. Les responsables d'études posent des questions en langage naturel sur les mêmes tables Unity Catalog sur lesquelles les modèles ML ont été entraînés, avec les mêmes contrôles d'accès appliqués.
Le résultat est une application d'opérations cliniques qui n'effectue aucun appel API externe, ne maintient aucune infrastructure de base de données opérationnelle distincte et ne nécessite aucun pipeline de synchronisation entre les couches analytiques et opérationnelles.
L'argument de l'auditabilité
L'approche standard de l'industrie pour la faisabilité des sites repose sur des produits de notation commerciaux de fournisseurs ou des plateformes d'analyse fournies par des CRO. Ces outils sont construits sur des données agrégées de l'industrie — utiles comme référence, mais aveugles aux spécificités de votre portefeuille. Un sponsor ayant une décennie d'historique CTMS, EDC et IRT possède des signaux importants sur la performance de ses sites sur ses protocoles.
Lorsque la pile ML réside sur Databricks, cette connaissance institutionnelle devient les données d'entraînement. Les modèles de ce workbench sont entraînés sur vos taux de recrutement historiques, votre historique de qualification de site, vos schémas d'échec de dépistage et votre dossier d'exécution de protocole — pas sur des moyennes de l'industrie. CMS Open Payments ajoute une couche de signal public qui, lorsqu'elle est utilisée de manière appropriée, est corrélée à l'engagement et à l'infrastructure de recherche et est librement disponible. À mesure que le portefeuille d'essais s'agrandit, les modèles s'améliorent sur la même infrastructure. C'est le rendement composé qu'une architecture à plateforme unique permet et qu'un produit de notation sous licence ne peut pas : chaque nouvel essai améliore la prédiction, et chaque nouvelle relation avec un site est reflétée dans la prochaine exécution d'entraînement. MLflow suit chaque exécution d'entraînement de modèle, les paramètres, les métriques et les artefacts — permettant la comparaison entre les versions de modèles, la reproductibilité à la demande et une piste d'audit complète, des enregistrements bruts CTMS et EDC à la prédiction déployée.
La dimension réglementaire est également importante ici. Le 21 CFR Part 11, ICH E6(R3), et les principes directeurs de la FDA sur les bonnes pratiques d'apprentissage automatique (GMLP), ainsi que l'accent croissant de la FDA sur la transparence dans le support décisionnel algorithmique, font de l'explicabilité des modèles et de la gouvernance des données des considérations matérielles, pas des fonctionnalités optionnelles. Étant donné que chaque prédiction est accompagnée d'une attribution SHAP stockée sous forme de table Delta gouvernée dans Unity Catalog — versionnée dans MLflow, tracée dans Unity Catalog, interrogeable — la justification derrière la sélection d'un site est aussi auditable que le score lui-même. Une équipe des affaires cliniques peut répondre à une question d'un comité de surveillance des données avec une requête SQL, pas avec un rapport de fournisseur boîte noire.
Ce que nous avons construit
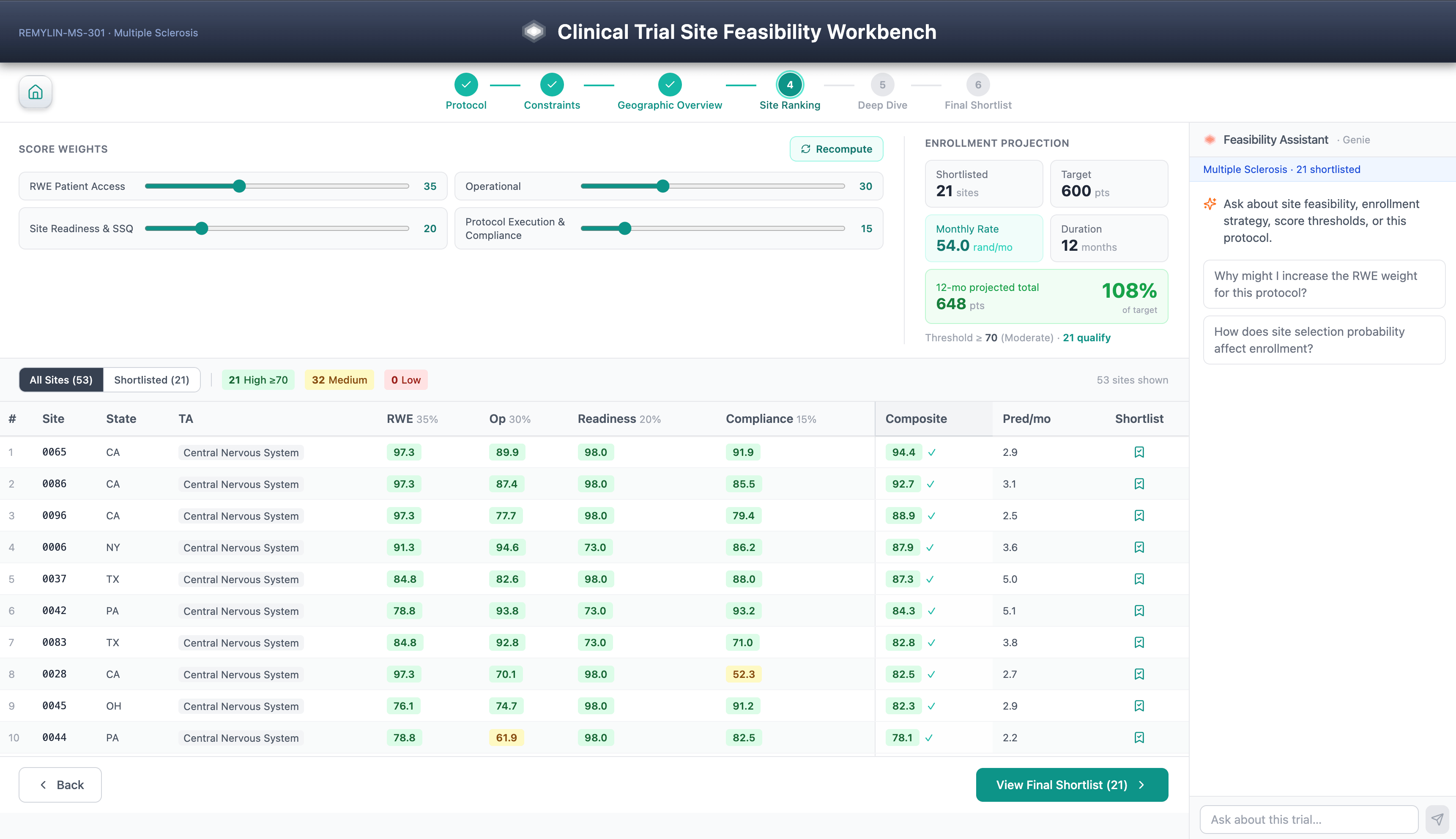
Le Site Feasibility Workbench est un flux de travail guidé en six étapes pour la sélection des sites d'essais cliniques : sélection du protocole, contraintes de score, aperçu géographique, classement des sites, analyse approfondie des sites basée sur SHAP et liste restreinte finale. Les considérations de diversité sont une dimension de notation de premier plan, alignée sur les attentes du plan d'action pour la diversité de la FDA en vertu du FDORA 2022.
Les scores de faisabilité composites combinent des preuves du monde réel, des données d'accès aux patients, des performances historiques des sites, l'historique de qualification des sites, le signal KOL Open Payments et des facteurs d'exécution de protocole — le tout piloté par des modèles LightGBM segmentés par TA entraînés sur l'historique CTMS, EDC et IRT de l'organisation.
La partie qui mérite d'être soulignée n'est pas les étapes du flux de travail ou les caractéristiques du modèle. Les données au niveau du patient héritent des contrôles d'accès d'Unity Catalog et la gestion des PHI suit la posture HIPAA Safe Harbor / Expert Determination du sponsor configurée au niveau du catalogue ou du schéma.
C'est ce que l'architecture rend possible : chaque prédiction est accompagnée d'une explication SHAP stockée sous forme de table Delta gouvernée à côté de la prédiction elle-même, rendant la logique du modèle aussi auditable et versionnée que le score qu'elle explique. Étant donné que chaque prédiction est décomposée en attributions SHAP gouvernées, les sponsors peuvent auditer les recommandations de sous-pondération systématique des sites communautaires, des établissements servant des minorités ou des investigateurs novices — transformant l'explicabilité en un contrôle d'équité.
Les listes restreintes enregistrées persistent dans Lakebase pour le partage en équipe. L'assistant AI/BI Genie répond aux questions inter-domaines sur les mêmes tables Unity Catalog en langage naturel. Rien de tout cela ne nécessite d'infrastructure en dehors de l'espace de travail.
Il s'agit d'une couche de support décisionnel, pas d'un système source de vérité. Le CTMS/EDC/IRT restent faisant autorité. Le workbench produit des prédictions dont la lignée est gouvernée dans Unity Catalog et MLflow.
L'application complète — backend FastAPI, frontend React, notebooks de départ et scripts de déploiement — est publiée en tant que dépôt open-source. Le déploiement dans un espace de travail Databricks existant avec Unity Catalog prend environ 30 minutes de temps de déploiement technique, avant l'examen de sécurité et la validation spécifiques au sponsor.
Un module d'une plateforme plus large
Le Site Feasibility Workbench est la première version publique d'une architecture plus large — le Databricks Clinical Operations Intelligence Hub — couvrant le cycle de vie complet des essais :
- Faisabilité et sélection des sites — ce que ce référentiel couvre
- Cohorte et recrutement des patients — construction de cohortes alignées sur le protocole à partir des données EHR et des données du monde réel à l'échelle du Lakehouse
- Optimiseur de vélocité d'inscription — prédiction de blocage ML par site et par mois avec un horizon de prévision de 1 à 3 mois
- Surveillance et conformité basées sur les risques — surveillance continue des anomalies d'inscription, des retards de données et des déviations de protocole
Les quatre se déploient en tant qu'applications Databricks. Les quatre interrogent directement Unity Catalog. Aucune ne fait d'appels API externes. Lorsque les applications cliniques vivent là où vos données et vos modèles vivent, la boucle de rétroaction se ferme. Les modèles de sélection de sites apprennent des résultats d'inscription. Les scores de risque sont mis à jour à mesure que l'historique des amendements s'étoffe. Chaque recommandation pilotée par l'IA porte une piste de lignage jusqu'aux enregistrements CTMS, EDC et IRT qui l'ont produite.
Pour commencer
Clonez le référentiel public. Déployez. Dites-nous ce que vous changez.
Pour le Clinical Operations Intelligence Hub complet — regardez l'enregistrement BrickTalk : Scaling BioPharma Intelligence + Databricks Agentic Clinical Ops.
Lakebase et Databricks Apps en production couvrent en profondeur les primitives de la plateforme.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.