Démystification de 8 mythes sur la disposition des données : pourquoi le regroupement liquide surpasse le partitionnement
La disposition des données pour le lakehouse moderne
par Jeffrey Gong, Yu Xu et Rahul Mahadev
- Le clustering liquide est la disposition des données pour les formats de table ouverts qui surpasse le partitionnement tout en évitant ses limitations
- 8 mythes courants maintiennent les équipes liées au partitionnement, et aucun d'entre eux ne tient plus la route
- Les clients utilisant le clustering liquide signalent des améliorations spectaculaires de la latence des requêtes, du débit d'écriture, de l'efficacité du stockage et de la fraîcheur des données, les gains les plus importants se composant à l'échelle des pétaoctets
Introduction
L'organisation des données est l'un des problèmes les plus anciens en informatique.
Depuis plus de 15 ans, avec l'avènement de Hadoop et Hive, le partitionnement a été la méthode standard pour organiser physiquement les données en vue de leur traitement et de leur analyse. Cependant, les Lakehouses actuels servent des agents, des pipelines en temps réel et des modèles de requêtes qui évoluent plus rapidement que ce qu'un humain peut re-partitionner.
Liquid Clustering est la norme moderne et les clients l'utilisent à toutes les échelles, y compris des dizaines de tables à l'échelle du pétaoctet en production. Dans ce blog, nous allons couvrir pourquoi Liquid Clustering est supérieur dans le Lakehouse. En chemin, nous allons démystifier 8 mythes courants sur l'organisation des données, examiner 3 exemples de réussite d'équipes convertissant des tables partitionnées en Liquid Clustering, prévisualiser ce qui arrive ensuite, et montrer comment commencer.
Pourquoi Liquid Clustering est supérieur dans le lakehouse moderne
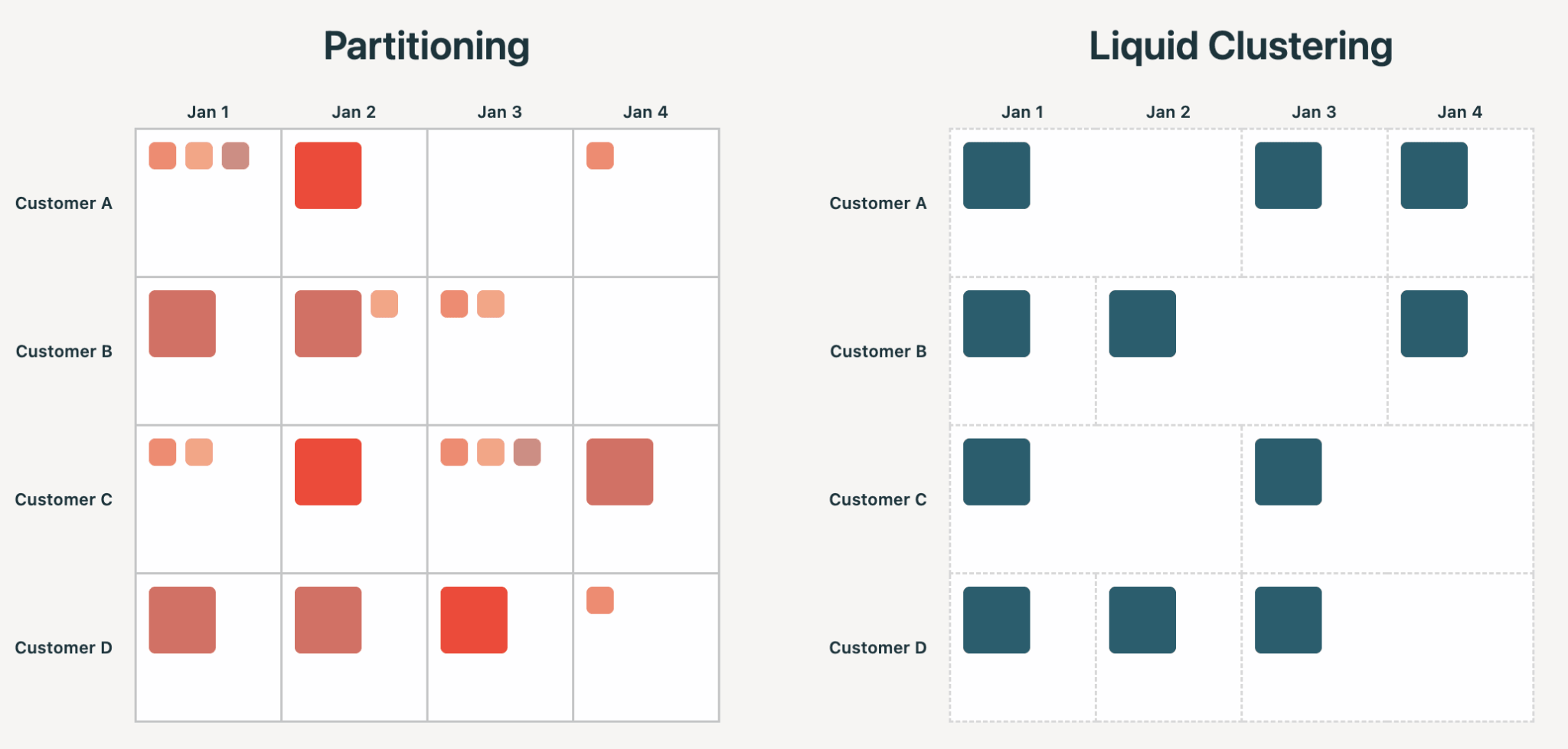
Le partitionnement de style Hive oblige les utilisateurs à s'engager, au moment de la création de la table, sur une organisation physique des données qui se manifeste dans la structure des fichiers. Choisissez une colonne avec une cardinalité trop élevée et vous obtiendrez des milliards de petits fichiers. Choisissez la mauvaise colonne et les requêtes peuvent ralentir, pas accélérer. Dans tous les cas, vous êtes bloqué à réécrire la table. Il est courant de se tromper : dans notre analyse, le partitionnement de style Hive entraîne une sur-partition et des problèmes de petits fichiers dans plus de 75 % des cas.
Liquid traite les clés de clustering comme une entrée que le moteur utilise pour guider l'organisation optimale des fichiers. Les clés peuvent être modifiées à tout moment, ou sélectionnées intelligemment via Automatic Liquid Clustering. La cardinalité n'est pas une contrainte, et l'organisation peut évoluer au fil du temps sans réécritures inutiles.
Les avantages de Liquid Clustering découlent tous du principe ci-dessus : meilleure gestion du déséquilibre, concurrence au niveau des lignes, pas de problèmes de petits fichiers, clustering multidimensionnel et amplification d'écriture réduite.
En 2026, l'organisation des données devrait être un détail d'implémentation de la table, chaque moteur qui lit ou écrit en bénéficiant. Ceci est de plus en plus important à mesure que les agents entrent dans le Lakehouse, générant et consommant plus de données que jamais. Les humains et les agents ont besoin d'interfaces indulgentes, exemptes des effets secondaires potentiels du partitionnement de style Hive.
Démystification de 8 mythes courants sur l'organisation des données
Liquid Clustering est devenu Généralement Disponible en 2024. Depuis lors, nous l'avons constamment amélioré avec des clients qui l'utilisent à grande échelle. Pendant ce temps, certains mythes courants sur Liquid Clustering et le partitionnement ont persisté, et aujourd'hui nous voulons les démystifier.
Mythe n°1 : Le partitionnement est plus rapide car il peut élaguer des répertoires au lieu de fichiers
Le mythe dit : Avec le partitionnement, Spark ou d'autres moteurs peuvent élaguer des répertoires entiers sans ouvrir de fichiers à l'intérieur.
Réalité : L'élagage de répertoires n'existe pas sur les formats de table ouverts modernes comme Delta et Iceberg. Delta, par exemple, utilise un journal de transactions pour suivre chaque fichier de données ainsi que des statistiques par colonne, et l'élagage se fait sur ces statistiques, pas sur la structure des répertoires. Le moteur ne liste jamais les répertoires pour planifier une requête. Il lit le journal de transactions, évalue les filtres par rapport aux statistiques et ignore les fichiers qui ne correspondent pas. Liquid Clustering utilise le même mécanisme. Que vos données résident dans `date=x/hour=y/` ou dans un répertoire plat de fichiers clusterisés, le moteur élague au niveau de granularité des fichiers. Il n'y a pas de raccourci au niveau du répertoire à perdre.
Mythe n°2 : Le partitionnement est meilleur lors du filtrage sur une colonne à faible cardinalité
Le mythe dit : Pour une colonne avec un petit nombre de valeurs distinctes, le partitionnement vous donne une séparation parfaite des données et une bonne taille de fichier.
Réalité : Liquid Clustering détecte automatiquement quand appliquer des optimisations de faible cardinalité. Par exemple, si vous clusterisez par (date, user_id), et que date a une faible cardinalité, le système vise à ce que chaque fichier contienne des lignes d'une seule date. Les colonnes à cardinalité plus élevée, comme user_id, sont ensuite automatiquement utilisées pour un tri plus fin dans chaque fichier de date, sans avoir à recourir à d'autres techniques de tri comme le Z-Ordering.
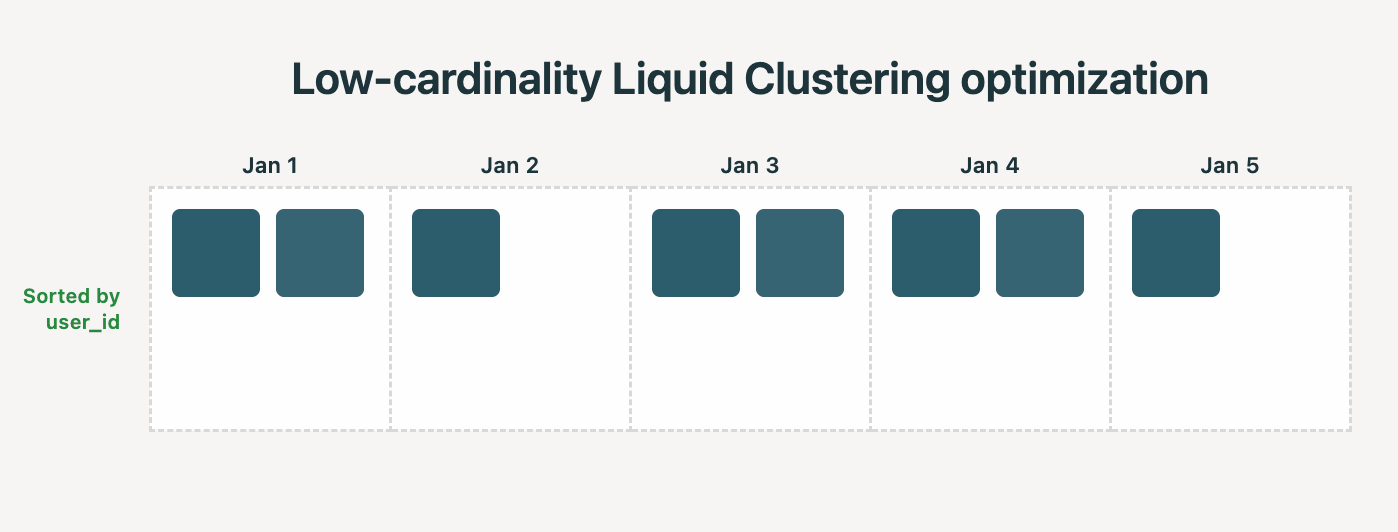
Nous avons constaté les améliorations suivantes lors de l'évaluation de cette optimisation Liquid sur un benchmark de data warehousing réel : 35 % de temps en moins pour le clustering et 22 % de temps de requête plus rapide.
De plus, Liquid Clustering est conçu pour être meilleur que le partitionnement lors du clustering sur une colonne à haute cardinalité, car il essaie toujours de créer des fichiers de bonne taille.
Mythe n°3 : Liquid Clustering ne prend pas en charge les opérations basées uniquement sur les métadonnées
Le mythe dit : Les opérations basées uniquement sur les métadonnées sont uniquement prises en charge par le partitionnement. Un DELETE aligné sur les limites de partition ne met à jour que les métadonnées de la table, et les agrégats sur les colonnes de partition peuvent être calculés sans scanner les fichiers. Liquid Clustering ne peut pas faire de même.
Réalité : Liquid Clustering prend également en charge les opérations basées uniquement sur les métadonnées, y compris les DELETE, les requêtes COUNT, DISTINCT et GROUP BY. Le moteur utilise les mêmes statistiques min/max par fichier qu'il utilise pour le saut de données afin de déterminer quand la réponse d'une requête peut être calculée à partir des métadonnées seules. Dans nos benchmarks, les DELETE basés uniquement sur les métadonnées sur des tables clusterisées par Liquid ont été ~90 % plus rapides que les DELETE avec réécriture complète. D'autres requêtes d'agrégation basées uniquement sur les métadonnées ont vu des accélérations allant jusqu'à 27x.
Mythe n°4 : Liquid Clustering ne fonctionne pas bien à l'échelle du pétaoctet
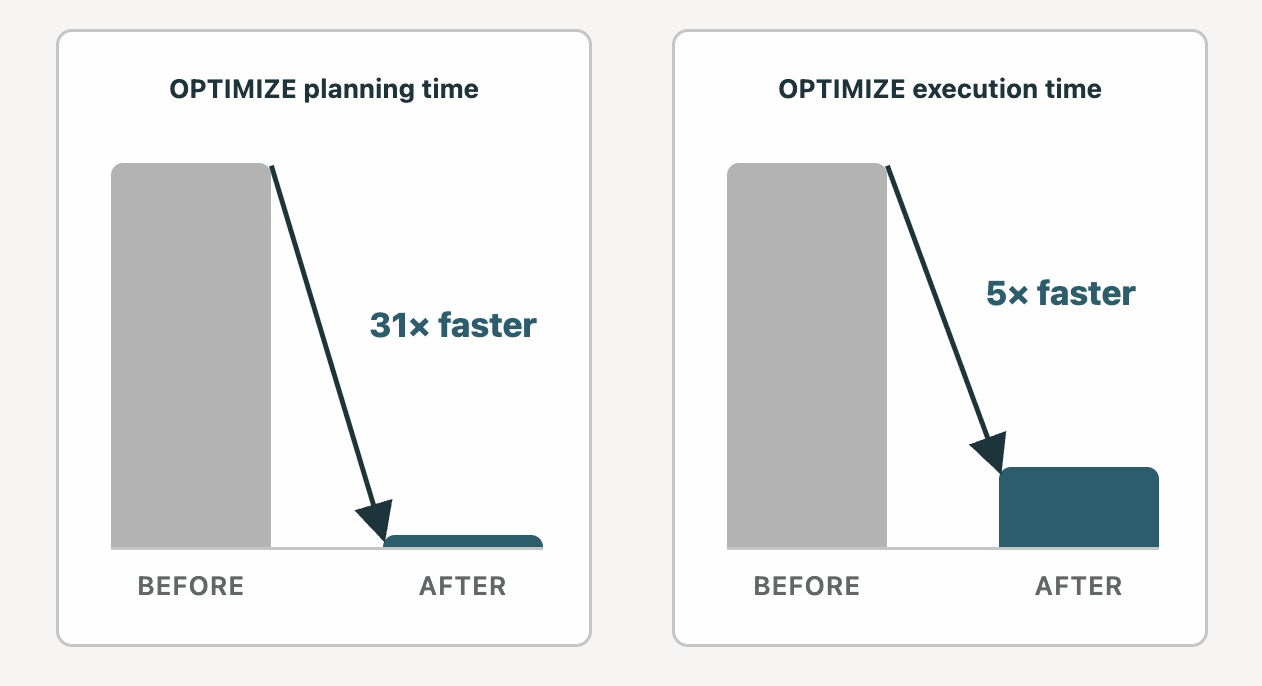
Le mythe dit : OPTIMIZE sur une table de la taille d'un PB peut prendre des heures, et le coût de maintenance est trop élevé.
Réalité : Nous avons apporté un certain nombre d'améliorations significatives à OPTIMIZE, et des dizaines de clients ont maintenant des tables Liquid Clustered à l'échelle du PB en production. Il y a deux ans, la planification, la première phase d'OPTIMIZE, pouvait prendre jusqu'à 12 heures sur une table Liquid de 10 PB dans certains cas. Nous avons passé le temps depuis à réduire le temps de planification à 23 minutes. L'exécution, la deuxième phase d'OPTIMIZE, est devenue 5 fois plus rapide sur un cluster DBSQL moyen.
Mythe n°5 : Liquid Clustering ne profite qu'à un sous-ensemble de lecteurs
Le mythe dit : Liquid Clustering n'est bénéfique que pour les lecteurs Databricks sur les tables Delta gérées par UC.
Réalité : Liquid Clustering est une optimisation côté écriture. C'est ainsi que le moteur organise les fichiers pour un saut de données efficace. La sortie est constituée de fichiers Parquet standard avec des statistiques min/max, écrits dans des formats de table ouverts comme Delta/Iceberg. Tout lecteur compatible (par exemple, Apache Spark open-source, DuckDB, etc.) peut utiliser ces statistiques pour sauter des fichiers. Liquid Clustering est disponible sur les tables externes/gérées et sur les tables Delta/ Iceberg, et le bénéfice est applicable quel que soit le lecteur.
Mythe n°6 : Le partitionnement est nécessaire pour l'ETL concurrent
Le mythe dit : L'ETL concurrent nécessite des limites d'écriture. Sans partitionnement, deux écrivains mettant à jour la même table risquent d'entrer en collision, et le contrôle de concurrence de Delta/Iceberg oblige l'un d'eux à réessayer ou à échouer. Partitionnez et donnez à chaque écrivain sa propre tranche de la table, de sorte que deux pipelines ne touchent jamais les mêmes fichiers.
Réalité : Fonctionner au niveau de granularité des partitions était une solution de contournement pour un ancien modèle de concurrence. Contrairement au partitionnement qui n'a qu'une concurrence au niveau des fichiers, Liquid offre une concurrence au niveau des lignes. Deux écrivains mettant à jour des lignes différentes n'entrent plus en conflit, même si ces lignes résident dans le même fichier. Cela supprime l'une des principales raisons pour lesquelles les équipes partitionnaient les tables : maintenir des limites d'écriture pour éviter la sérialisation. Avec Liquid Clustering, l'ETL peut facilement fonctionner simultanément sur la même table.
Mythe n°7 : Le Z-Ordering compense les lacunes du partitionnement
Le mythe dit : Le partitionnement gère les filtres de la colonne de partition, et le Z-Ordering gère le reste. En exécutant OPTIMIZE ZORDER BY, le moteur trie les données pour un saut optimal sur les filtres qui ne correspondent pas au schéma de partitionnement.
Réalité : Le Z-Ordering ne sauve pas le partitionnement. En fait, il a ses propres problèmes structurels.
- Le premier est une qualité de clustering médiocre. Le Z-Order ne maintient pas un véritable ordre sur toute la table. Les valeurs d'une même colonne peuvent être réparties sur de nombreux fichiers, de sorte que les plages min/max par fichier sont plus larges et les requêtes sautent moins de fichiers qu'avec Liquid.
- Le second est des réécritures inutiles. Le Z-Order doit être réexécuté périodiquement à mesure que de nouvelles données arrivent, et chaque réexécution réécrit de grandes quantités de données anciennes, potentiellement déjà clusterisées, pour restaurer la qualité du clustering. Avec l'ingestion continue, le coût du maintien d'un bon clustering des données avec Z-Order augmente avec la taille de la table.
Liquid clusterise de manière incrémentielle, y compris au moment de l'écriture, de sorte que la disposition reste optimale sans réécritures inutiles.
Mythe n°8 : Le partitionnement est nécessaire pour les remplacements sélectifs de données
Le mythe dit : La capacité à remplacer sélectivement des données n'est disponible que via les remplacements dynamiques de partitions.
Réalité : Les remplacements sélectifs fonctionnent nativement sur les tables Liquid. Databricks prend en charge REPLACE USING et REPLACE ON, deux syntaxes SQL pour remplacer sélectivement des données sur n'importe quelle disposition de données : tables Liquid Clustered, partitionnées ou simplement non clusterisées. Contrairement à Dynamic Partition Overwrite qui nécessite une configuration Spark, REPLACE USING et REPLACE ON peuvent être utilisés sur n'importe quel calcul : clusters classiques, entrepôts SQL et Serverless. L'opération est atomique et correspond à n'importe quelle colonne de votre choix.
Histoires de réussite : migration du partitionnement vers Liquid Clustering
Accélération des requêtes de 7,7x sur la table de télémétrie de sécurité de 3,8 Po d'Arctic Wolf
Arctic Wolf gère une table de télémétrie de sécurité de plus de 3,8 Po ingérant plus de 1 billion d'événements par jour, où les chasseurs de menaces dépendent de données fraîches pour détecter les attaques actives.
Après avoir migré du partitionnement vers Liquid Clustering sur des tables gérées par Unity Catalog avec Predictive Optimization, Arctic Wolf a constaté :
- Les requêtes sur 90 jours sont passées de 51 secondes à 6,6 secondes
- Le nombre de fichiers est passé de 4M à 2M
- La fraîcheur des données est passée de plusieurs heures à quelques minutes
Améliorations de la lecture et de l'écriture sur des tables CDC critiques pour Bolt
Bolt a récemment essayé Liquid Conversion (actuellement en aperçu privé), qui convertit les tables partitionnées en Liquid sur place en utilisant ALTER TABLE .. REPLACE PARTITIONED BY WITH CLUSTER BY. Ils ont observé les avantages suivants en lecture et écriture sur une table CDC à l'échelle du To après la conversion en Liquid Clustering :
- Le débit d'écriture (lignes/sec) a augmenté de 138 %
- Les temps de lecture ont été réduits jusqu'à 63 %, avec une réduction moyenne de 21 % sur 9 requêtes représentatives
Liquid Clustering a considérablement réduit le travail effectué par chaque écriture, augmentant considérablement notre débit sur notre table CDC la plus critique. Les lectures se sont également améliorées dans l'ensemble. La meilleure chose a été : nous avons effectué la conversion du partitionnement parallèlement à l'ingestion en direct, sans temps d'arrêt. Avec cela, Liquid Clustering nous a fourni exactement le type de performance et de fiabilité dont nous avions besoin à l'échelle de la plateforme. —Marcin, ingénieur plateforme senior chez Bolt
Accélération de 5,9x du temps de requête sur une charge de travail interne à l'échelle du pétaoctet
Nous gérons une table de 1,1 Po en interne qui est interrogée des milliers de fois par jour, principalement par des ingénieurs effectuant des investigations de production et des tableaux de bord d'observabilité. Initialement, elle était partitionnée par date et heure, en supposant que les analyses de plage horaire domineraient. Cependant, cette hypothèse s'est avérée incomplète. Bien que les analyses de plage horaire soient courantes, la table était également fréquemment interrogée par source et id, forçant le moteur à scanner chaque fichier dans les partitions de date et d'heure pertinentes pour trouver une poignée de lignes.
L'ajout de source et id comme partitions n'était pas viable, car il y avait trop de valeurs distinctes. Cela aurait créé des milliards de petits fichiers. Liquid Clustering a supprimé le compromis, permettant le clustering sur l'heure et les colonnes d'identifiant supplémentaires simultanément, tout en maintenant de bonnes tailles de fichiers.
| Disposition | |
|---|---|
| Avant | Partitionné par date, heure |
| Après | Regroupé par date, hour, source, id |
Les benchmarks ont montré des améliorations massives sur 16 requêtes de production représentatives :
| Métrique | Avant (partitionné) | Après (Liquid) | Améliorations |
|---|---|---|---|
| Temps d’horloge | 406s | 70s | Accélération 5,9x |
| Octets lus | 3,5 To | 0,48 To | 86 % d’octets lus en moins |
La table elle-même a également rétréci. La taille totale est passée de 1,1 Po à 0,8 Po, soit une réduction de 27 % sans modification des données sous-jacentes. Les fichiers mieux regroupés se compressent plus efficacement, et la taxe sur les petits fichiers due à la sur-partition disparaît.
Ce qui s’en vient pour Liquid Clustering
Optimisation des jointures Liquid-à-Liquid : jusqu’à 51 % plus rapides avec 87 % de mélange en moins
Aujourd’hui, joindre des tables Liquid sur leurs colonnes de regroupement peut nécessiter un mélange complet des données, même lorsque les données sont déjà organisées par ces colonnes. Les jointures co-regroupées (maintenant en aperçu privé) éliminent automatiquement ce mélange. Sur un benchmark d’entrepôt de données réel, une jointure Liquid-à-Liquid a été exécutée ~51 % plus rapidement (28 minutes → 14 minutes) et a mélangé 87 % de données en moins (1,2 Tio → 150 Gio) que la même requête sans l’optimisation.
Conversion Liquid facile des tables partitionnées
Auparavant, la conversion d’une table partitionnée en Liquid Clustering nécessitait une réécriture complète de la table et des changements majeurs en aval avec REPLACE TABLE ou une bascule avec des écritures doubles et une interruption planifiée. Nous introduisons une nouvelle commande (maintenant en aperçu privé) qui facilite cette conversion, minimisant à la fois les temps d’arrêt et les réécritures.
Commencer avec Liquid Clustering
Créez une table avec Liquid Clustering :
Ou, si vous utilisez des tables gérées UC avec Predictive Optimization, utilisez Automatic Liquid Clustering pour sélectionner intelligemment les clés de regroupement en fonction de votre charge de travail et de vos modèles de requête :
Liquid Clustering est la disposition du Lakehouse moderne. Essayez-le sur votre prochaine table, ou contactez votre équipe commerciale dès aujourd’hui pour essayer les aperçus privés de la conversion partitionnée-vers-Liquid et des jointures co-regroupées !
N’oubliez pas de nous retrouver à DAIS !
- Optimiser le coût et les performances du Lakehouse avec le stockage intelligent et Liquid Clustering
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.