L'architecture Liquid Clustering d'Arctic Wolf optimisée pour l'échelle du pétaoctet
par Justin Lai, Rajneesh Arora, Krishan Kumar et Cindy Jiang
- Arctic Wolf traite plus de mille milliards d'événements de sécurité chaque jour, générant plus de 260 milliards d'observations enrichies qui sont conservées dans un Delta Lake à l'échelle du pétaoctet. Notre architecture est conçue pour fournir un accès en quasi temps réel à ces données.
- Nous avons récemment migré vers l'utilisation du liquid clustering sur les tables gérées Unity Catalog avec l'Optimisation prédictive (PO), complétant nos tables externes partitionnées par un clustering incrémentiel et sensible à la charge de travail pour de meilleures performances de queries.
- Ensemble, le liquid clustering et la PO permettent de maintenir les tables optimisées pour des requêtes jusqu'à 8 fois plus rapides et une fraîcheur des données améliorée, passant de plusieurs heures à quelques minutes.
Chaque jour, Arctic Wolf traite plus d'un billion d'événements, distillant des milliards d'enregistrements enrichis en insights pertinentes pour la sécurité. Cela représente plus de 60 To de télémétrie compressée, alimentant la détection et la réponse aux menaces basées sur l'IA, 24h/24 et 7j/7, sans interruption. Pour alimenter la chasse aux menaces en temps réel, nous devions mettre ces données à la disposition des clients et du centre des opérations de sécurité le plus rapidement possible, avec pour objectif que la plupart des queries aboutissent en 15 secondes.
Par le passé, nous avons dû utiliser d'autres datastores rapides pour fournir un accès aux données récentes, car le partitionnement et le z-ordering ne pouvaient pas suivre le rythme. Lorsque nous détectons une activité suspecte, notre équipe peut immédiatement exploiter trois mois de contexte historique pour comprendre les schémas d'attaque, les mouvements latéraux et l'étendue complète de la compromission. Cette analyse historique en temps réel sur plus de 3,8 Po de données compressées est essentielle pour la chasse aux menaces moderne: la différence entre le confinement d'une brèche en quelques heures plutôt qu'en quelques jours peut représenter des millions de dommages évités.
Quand chaque seconde compte, la vitesse et la fraîcheur des données sont essentielles. Arctic Wolf devait accélérer l'accès à des datasets massifs sans augmenter les coûts d'ingestion ni ajouter de complexité. Le défi ? Les enquêtes étaient ralenties par de lourdes opérations d'E/S de fichiers et des données obsolètes. En repensant la manière dont les données sont organisées, notre architecture gère efficacement l'asymétrie des données multi-locataires, où une petite partie des clients génère la plupart des événements, tout en prenant également en charge les données qui arrivent tardivement et peuvent apparaître jusqu'à plusieurs semaines après leur ingestion initiale. Les avantages mesurables incluent la réduction du nombre de fichiers de plus de 4 millions à 2 millions, la diminution des temps de requête d'environ 50 % sur tous les centiles et la réduction des requêtes sur 90 jours de 51 secondes à seulement 6,6 secondes. La fraîcheur des données s'est améliorée, passant de quelques heures à quelques minutes, permettant un accès à la télémétrie de sécurité presque immédiatement.
Lisez la suite pour découvrir comment le liquid clustering et les tables gérées Unity Catalog ont rendu cela possible, en offrant des performances constantes et des insights en quasi temps réel à grande échelle.
Goulots d'étranglement hérités : pourquoi Arctic Wolf a tout reconstruit
Notre table héritée, partitionnée par date-heure d'occurrence et z-ordonnée par identifiant de locataire, ne pouvait pas être requêtée en quasi temps réel en raison du grand nombre de petits fichiers répartis sur les partitions. De plus, seules les données datant de plus de 24 heures sont disponibles, car nous avons dû exécuter OPTIMIZE avec Z-ordering avant de pouvoir les interroger.
Même dans ce cas, des problèmes de performance persistaient en raison de l'arrivée tardive des données. Cela se produit lorsqu'un système se déconnecte avant de transmettre des données, ce qui entraînerait l'arrivée de nouvelles données dans des partitions plus anciennes et affecterait les performances.
Les données obsolètes nous aveuglent. Ce délai fait la différence entre contenir un adversaire et lui permettre de se déplacer latéralement.
Pour atténuer ces problèmes de performance et fournir la fraîcheur des données dont nous avions besoin, nous avons dû dupliquer nos données chaudes dans un accélérateur de données et les fusionner par query avec les données de notre Data Lake pour satisfaire nos exigences métier. Ce système était coûteux à exécuter et nécessitait un effort de Data Engineering considérable pour sa maintenance.
Pour relever les défis liés à l'utilisation d'un accélérateur de données, nous avons repensé le layout de nos données afin de les répartir uniformément et de prendre en charge les données à arrivée tardive. Cela optimise les performances des requêtes et permet un accès en quasi-temps réel pour les cas d'utilisation d'IA agentique actuels et émergents.
Mettre en place la fondation pour les données en streaming avec le clustering liquide
Avec notre nouvelle architecture, notre objectif principal est de pouvoir requêter les données les plus récentes, de fournir des performances de query constantes quelle que soit la taille des clients, et que les requêtes renvoient des résultats en quelques secondes.
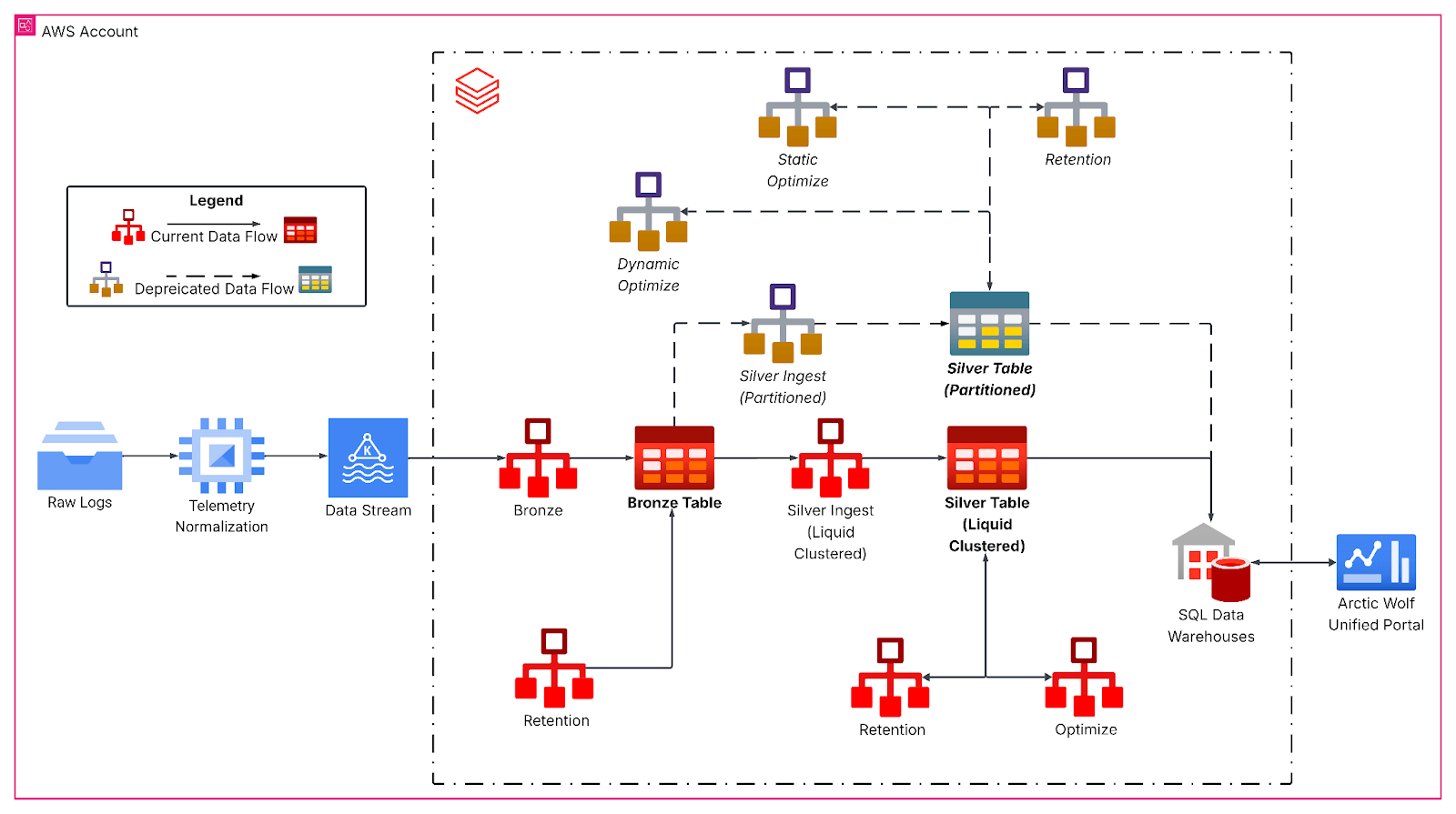
Le pipeline réarchitecturé suit une architecture médaillon, qui commence par une ingestion Kafka en continu dans une couche bronze pour les données d'événements brutes. Des Jobs de streaming structuré horaires aplatissent ensuite les charges utiles JSON imbriquées et écrivent dans des tables silver avec le liquid clustering, formant ainsi la base analytique principale. Ici, les transformations de bronze à silver gèrent l'évolution du schéma, génèrent des colonnes temporelles dérivées et préparent les données pour les charges de travail analytiques en aval avec des SLA de latence stricts.
Le clustering liquide a remplacé les schémas de partitionnement rigides par des clés de clustering multidimensionnelles et adaptées à la charge de travail, alignées sur les schémas de requête, notamment par l'identifiant du locataire et la granularité de la date, la taille de la table et les caractéristiques d'arrivée des données. La répartition plus uniforme des données et, dans notre cas, l'augmentation de la taille moyenne des fichiers à plus de 1 Go ont considérablement réduit le nombre de fichiers analysés lors des queries sur des fenêtres temporelles typiques pour notre table.
Analyse approfondie : les clusters à l'écriture
De plus, nos Jobs de streaming structuré exploitent le clustering à l'écriture pour maintenir le layout des fichiers à mesure que de nouvelles données arrivent. Cela fonctionne comme une Opérations OPTIMIZE localisée, en appliquant le clustering uniquement aux données nouvellement ingérées. Ainsi, les données ingérées sont déjà optimisées. Cependant, si les batches d'ingestion sont trop petits, ils produisent de nombreux petits fichiers bien clusterisés qui doivent encore l'être lors d'une opération OPTIMIZE globale pour obtenir un layout de données idéal. En revanche, si la taille du batch lors de l'ingestion se rapproche de la taille du batch requise par l'opération Optimize globale, une optimisation supplémentaire est souvent inutile.
Pour les charges de travail qui ingèrent de très grands volumes de données (p. ex., des téraoctets), nous recommandons le traitement par lots à la source, par exemple en utilisant foreachBatch avec maxBytesPerTrigger, afin de garantir un clustering et un layout des fichiers efficaces. Avec maxBytesPerTrigger, nous pouvons contrôler la taille des batchs, éliminant ainsi de nombreux petits îlots clusterisés qui nécessiteraient une réconciliation via une opération OPTIMIZE. Avec des tailles proches de celles sur lesquelles l'opération OPTIMIZE travaille, nous avons pu créer des batches optimaux pour réduire le travail supplémentaire requis par OPTIMIZE.
Impact sur l'analytique de sécurité d'Arctic Wolf
La migration d'Arctic Wolf vers Liquid Clustering a apporté des améliorations substantielles et quantifiables en matière de performances, de fraîcheur des données et d'efficacité opérationnelle. Les tables gérées d'UC avec optimisation prédictive ont également réduit le besoin de planifier la maintenance.
Le nombre de fichiers est passé de plus de 4 millions à 2 millions, ce qui a minimisé les opérations d'E/S de fichiers pendant les queries tout en maintenant une bonne qualité de cluster. En conséquence, les performances des requêtes se sont considérablement améliorées, permettant aux analystes de sécurité d'enquêter plus rapidement sur les incidents : ~50 % plus rapides sur tous les centiles et ~90 % plus rapides pour un grand nombre de nos clients, les requêtes sur 90 jours passant de 51 secondes à 6,6 secondes.
En implémentant le clustering à l'écriture, nous avons réduit le délai de fraîcheur des données de plusieurs heures à quelques minutes, accélérant ainsi le temps d'obtention d'insight d'environ ~90 %. Cette amélioration permet la détection des menaces en quasi-temps réel dans le Data Lake d'Arctic Wolf.
La transition vers le liquid clustering et les tables gérées par Unity Catalog a permis d'éliminer le partitionnement hérité, de réduire la dette technique et de débloquer des fonctionnalités avancées de gouvernance et de performance. Avec une architecture capable de traiter et d'interroger plus de 260 milliards de lignes par jour, nous offrons un accès plus rapide et plus efficace aux données de sécurité critiques provenant de toutes ces sources. Combiné à notre équipe Concierge Security® disponible 24h/24 et 7j/7 et à la détection des menaces en temps réel, cela permet une réponse aux menaces et une atténuation plus rapides et plus précises. Ces éléments différenciateurs aident nos clients à atteindre une posture de sécurité plus forte et plus agile, et à avoir une plus grande confiance dans la capacité d'Arctic Wolf à protéger leurs environnements et à soutenir la réussite continue de leur entreprise.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.