Comment créer des espaces Genie prêts pour la production et instaurer la confiance en cours de route
Un parcours de création d'un Genie space de A à Z jusqu'à sa mise en production, améliorant la précision grâce à une évaluation par benchmark et une optimisation systématique.
par Pulkit Pareek et Eric Lind
- Tirez parti des benchmarks pour mesurer l'état de préparation de votre espace Genie de manière objective, plutôt que subjective.
- Suivez un exemple de bout en bout pour le développement d'un espace Genie prêt pour la production, couvrant de nombreux scénarios de dépannage courants.
- Renforcez la confiance des utilisateurs finaux en partageant les résultats finaux en matière de précision pour les questions auxquelles il faut répondre correctement.
Le défi de la confiance dans l'analytique en libre-service
Genie est une fonctionnalité de Databricks qui permet aux équipes métier d'interagir avec leurs données en utilisant le langage naturel. Elle utilise une IA générative adaptée à la terminologie et aux données de votre organisation, avec la capacité de surveiller et d'affiner ses performances grâce aux retours des utilisateurs.
Un défi courant avec tout outil d'analytique en langage naturel est d'établir la confiance avec les utilisateurs finaux. Prenons l'exemple de Sarah, une experte du domaine du marketing, qui essaie Genie pour la première fois à la place de ses tableaux de bord.
Sarah : « Quel a été notre taux de clics au dernier trimestre ? »
Genie : 8,5 %
Réflexion de Sarah : Attends, je me souviens d'avoir fêté nos 6 % le trimestre dernier...
Il s'agit d'une question dont Sarah connaît la réponse, mais elle n'obtient pas le bon résultat. Peut-être que la query générée incluait des campagnes différentes, ou utilisait une définition de calendrier standard pour le « dernier trimestre » alors qu'elle aurait dû utiliser le calendrier fiscal de l'entreprise. Mais Sarah ne sait pas ce qui ne va pas. Ce moment d'incertitude a semé le doute. Sans une évaluation appropriée des réponses, ce doute quant à la facilité d'utilisation peut s'amplifier. Les utilisateurs se tournent de nouveau vers l'assistance des analystes, ce qui perturbe d'autres projets et augmente le coût et le délai de rentabilisation nécessaires pour générer un seul insight. L'investissement dans le libre-service reste sous-utilisé.
La question n'est pas seulement de savoir si votre espace Genie peut générer du SQL. Il s'agit de savoir si vos utilisateurs font suffisamment confiance aux résultats pour prendre des décisions en fonction de ceux-ci.
Gagner cette confiance exige d'aller au-delà de l'évaluation subjective ("cela semble fonctionner") pour passer à une validation mesurable ("nous l'avons testé systématiquement"). Nous démontrerons comment la fonctionnalité de benchmarks intégrée de Genie transforme une implémentation de base en un système prêt pour la production, sur lequel les utilisateurs comptent pour prendre des décisions critiques. Les benchmarks fournissent un moyen data-driven pour évaluer la qualité de votre espace Genie et vous aident à combler les lacunes lors de la curation de l'espace Genie.
Dans cet article de blog, nous vous présenterons un exemple de parcours de bout en bout pour créer un Genie space avec des benchmarks afin de développer un système fiable.
Les données : Analyse de campagne marketing
Notre équipe Marketing doit analyser les performances des campagnes sur quatre datasets interconnectés.
- Prospects - Informations sur l'entreprise, y compris les Secteurs d'activité et l'emplacement
- Contacts - Informations sur les destinataires, y compris le service et le type d'appareil
- Campagnes - Détails de la campagne, y compris le budget, le template et les dates
- Événements - Suivi des événements d'e-mail (envois, ouvertures, clics, signalements de spam)
Le flux de travail : Identifier les entreprises cibles (prospects) → trouver des contacts dans ces entreprises → envoyer des campagnes marketing → suivre la manière dont les destinataires réagissent à ces campagnes (événements).
Voici quelques exemples de questions auxquelles les utilisateurs devaient répondre :
- "Quelles campagnes ont généré le meilleur ROI par secteur d'activité ?"
- "Quel est notre risque de conformité pour les différents types de campagnes ?"
- "Comment les modèles d'engagement (CTR) diffèrent-ils par appareil et par département ?"
- "Quels Templates sont les plus performants pour des segments de prospects spécifiques ?"
Ces questions nécessitent de joindre des tables, de calculer des métriques spécifiques au domaine et d'appliquer des connaissances du domaine sur ce qui rend une campagne "réussie" ou "à haut risque". Il est important d'obtenir des réponses correctes, car elles influencent directement l'allocation budgétaire, la stratégie de campagne et les décisions de conformité. C'est parti !
Le parcours : du développement de la version de base à la mise en production
Il ne faut pas s'attendre à ce que l'ajout anecdotique de tables et de quelques invites de texte génère un Genie space suffisamment précis pour les utilisateurs finaux. Une compréhension approfondie des besoins de vos utilisateurs finaux, combinée à une connaissance des jeux de données et des fonctionnalités de la plateforme Databricks, vous permettra d'obtenir les résultats souhaités.
Dans cet exemple de bout en bout, nous évaluons la précision de notre espace Genie à l'aide de benchmarks, diagnostiquons les lacunes de contexte qui entraînent des réponses incorrectes et mettons en œuvre des correctifs. Considérez ce framework comme une approche pour le développement et les évaluations de votre Genie.
- Définissez votre suite de benchmarks (visez 10 à 20 questions représentatives). Ces questions devraient être déterminées par des experts du domaine et les utilisateurs finaux censés utiliser Genie pour l'analytique. Idéalement, ces questions sont créées avant tout développement réel de votre espace Genie.
- Établissez votre précision de référence. Exécutez toutes les questions de benchmark dans votre espace en ajoutant uniquement les objets de données de référence à l'espace Genie. Documentez la précision, ainsi que les questions qui réussissent, celles qui échouent et pourquoi.
- Optimisez systématiquement. Implémentez un ensemble de modifications (par ex. l'ajout de descriptions de colonnes). Réexécutez toutes les questions du benchmark. Mesurez l'impact et les améliorations, et poursuivez le développement itératif en suivant les meilleures pratiques publiées.
- Mesurer et communiquer. L'exécution des benchmarks fournit des critères d'évaluation objectifs indiquant que le Genie space répond suffisamment aux attentes, ce qui renforce la confiance des utilisateurs et des parties prenantes.
Nous avons créé une suite de 13 questions de référence qui représentent ce que les utilisateurs finaux cherchent comme réponses dans nos données marketing. Chaque question de référence est une question réaliste en anglais simple, associée à une query SQL validée qui répond à cette question.
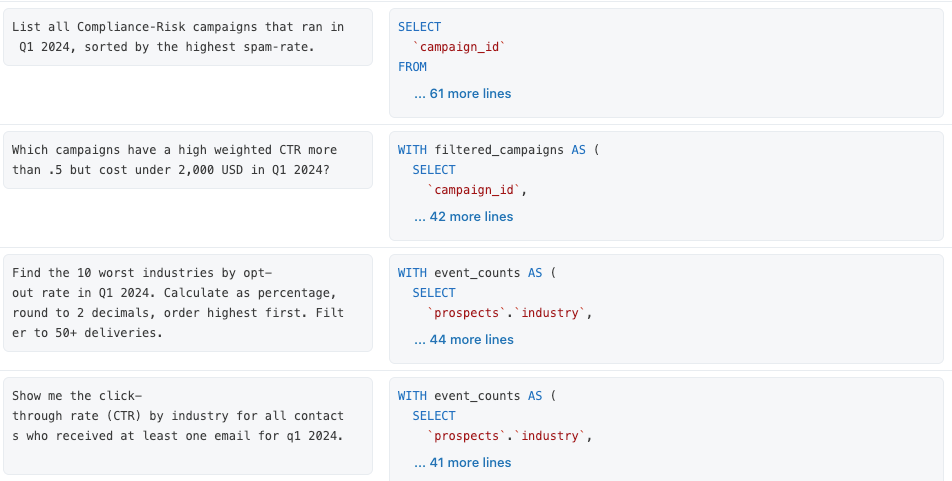
Par conception, Genie n'inclut pas ces requêtes SQL de référence comme contexte existant. Elles sont uniquement utilisées à des fins d'évaluation. Notre rôle est de fournir le bon contexte afin de pouvoir répondre correctly à ces questions. Allons-y !
Itération 0 : Établir la base de référence
Nous avons intentionnellement commencé avec de mauvais noms de table comme cmp et proc_delta, et des noms de colonne comme uid_seq (pour campaign_id), label_txt (pour campaign_name), num_val (pour cost) et proc_ts (pour event_date). Ce point de départ reflète ce à quoi de nombreuses organisations sont réellement confrontées : des données modélisées pour des conventions techniques plutôt que pour une signification métier.
Les tables seules ne fournissent pas non plus de contexte sur la manière de calculer les métriques et les KPI spécifiques au domaine. Genie sait comment exploiter des centaines de fonctions SQL intégrées, mais il a toujours besoin des bonnes colonnes et de la bonne logique à utiliser comme entrées. Alors, que se passe-t-il lorsque Genie n'a pas assez de contexte ?
Analyse comparative : Genie n'a pu répondre correctement à aucune de nos 13 questions de référence. Non pas parce que l'IA n'était pas assez puissante, mais parce qu'elle manquait de tout contexte pertinent, comme illustré ci-dessous.

Insight : Chaque question que les utilisateurs finaux posent repose sur la production d'une SQL query par Genie à partir des objets de données que vous fournissez. De mauvaises conventions de nommage des données affecteront donc chacune de ces requêtes générées. Vous ne pouvez pas faire l'impasse sur la qualité fondamentale des données et espérer gagner la confiance des utilisateurs finaux ! Genie ne génère pas de query SQL pour chaque question. Il le fait uniquement lorsqu'il dispose de suffisamment de contexte. Il s'agit d'un comportement attendu pour éviter les hallucinations et les réponses trompeuses.
Action suivante : De faibles scores de benchmark initiaux indiquent que vous devriez d'abord vous concentrer sur le nettoyage des objets Unity Catalog. Nous commençons donc par là.
Itération 1 : Significations de colonne ambiguës
Nous avons amélioré les noms des tables en campaigns, events, contacts et prospects, et ajouté des descriptions de table claires dans Unity Catalog.

Cependant, nous avons rencontré un autre défi connexe : des noms de colonnes ou des commentaires trompeurs qui suggèrent des relations qui n'existent pas.
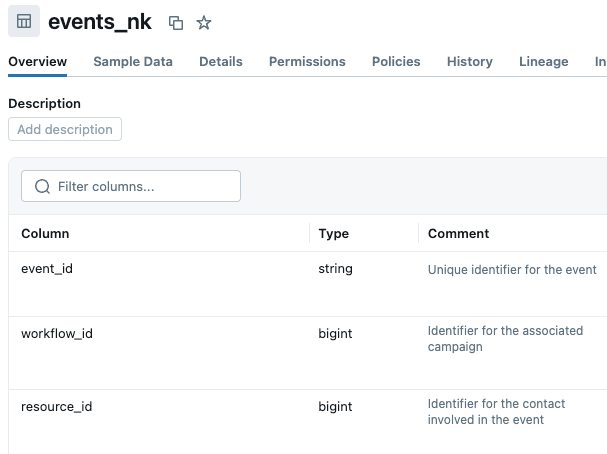
Par exemple, des colonnes comme workflow_id, resource_id et owner_id existent dans plusieurs tables. On pourrait croire qu'elles servent à relier des tables entre elles, mais ce n'est pas le cas. La table events utilise workflow_id comme clé étrangère vers les campagnes (et non une table de workflow distincte), et resource_id comme clé étrangère vers les contacts (et non une table de ressources distincte). Pendant ce temps, la table campaigns a sa propre colonne workflow_id qui n'a aucun rapport. Si les noms et les descriptions de ces colonnes ne sont pas correctement annotés, cela peut entraîner une utilisation incorrecte de ces attributs. Nous avons mis à jour les descriptions des colonnes dans Unity Catalog pour clarifier l'objectif de chacune de ces colonnes ambiguës. Remarque : si vous ne parvenez pas à modifier les métadonnées dans UC, vous pouvez ajouter des descriptions de table et de colonne dans la base de connaissances de l'espace Genie.
Analyse des benchmarks : les requêtes simples sur une seule table ont commencé à fonctionner grâce à des noms et des descriptions clairs. Des questions comme "Compter les événements par type en 2023" et "Quelles campagnes ont démarré au cours des trois derniers mois ?" ont désormais reçu des réponses correctes. Cependant, toute query nécessitant des jointures entre les tables échouait : Genie ne parvenait toujours pas à déterminer correctement quelles colonnes représentaient des relations.
Insight : Des conventions de dénomination claires sont utiles, mais sans définitions explicites des relations, Genie doit deviner quelles colonnes relient les tables entre elles. Lorsque plusieurs colonnes portent des noms comme workflow_id ou resource_id, ces suppositions peuvent conduire à des résultats inexacts. Des métadonnées correctes servent de base, mais les relations doivent être définies explicitement.
Action suivante : Définir les relations de jointure entre vos objets de données. Des noms de colonnes comme id ou resource_id apparaissent tout le temps. Clarifions exactement lesquelles de ces colonnes référencent d'autres objets de table.
Itération 2 : Modèle de données ambigu
La meilleure façon de clarifier les colonnes que Genie doit utiliser lors de la jointure de tables est d'utiliser des clés primaires et étrangères. Nous avons ajouté des contraintes de clé primaire et étrangère dans Unity Catalog, indiquant explicitement à Genie comment les tables se connectent : campaigns.campaign_id est liée à events.campaign_id, qui est liée à contacts.contact_id, qui se connecte à prospects.prospect_id. Cela élimine les approximations et dicte la manière dont les jointures multi-tables sont créées par défaut. Remarque : si vous ne pouvez pas modifier les relations dans UC, ou si la relation entre les tables est complexe (par ex. plusieurs conditions JOIN), vous pouvez les définir dans la base de connaissances de l'espace Genie.
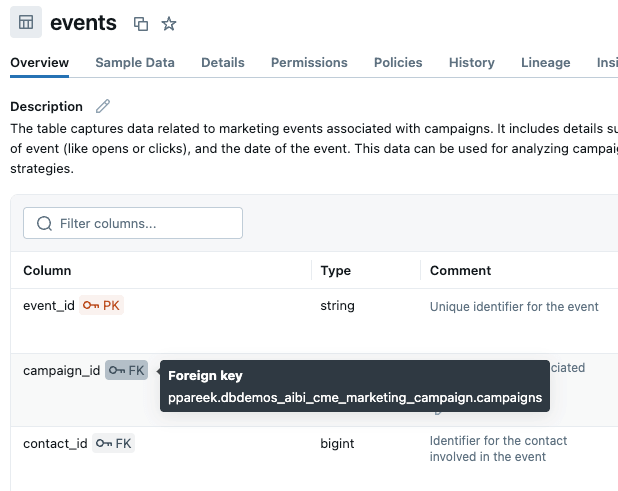
Alternativement, nous pourrions envisager de créer une vue de métrique qui peut inclure explicitement les détails de la jointure dans la définition de l'objet. Nous y reviendrons plus tard.
Analyse comparative : Progrès constants. Les questions nécessitant des jointures sur plusieurs tables ont commencé à fonctionner : « Afficher les coûts des campagnes par secteurs d'activité pour le T1 2024 » et « Quelles campagnes ont eu plus de 1 000 événements en janvier ? » réussissent maintenant.
insight : les relations permettent les requêtes multi-tables complexes qui apportent une réelle valeur commerciale. Genie génère du SQL correctement structuré et effectue correctement des opérations simples comme des sommes de coûts et des comptages d'événements.
Action : Parmi les benchmarks incorrects restants, beaucoup incluent des références à des valeurs que les utilisateurs ont l'intention d'utiliser comme filtres de données. La façon dont les utilisateurs finaux posent les questions ne correspond pas directement aux valeurs qui apparaissent dans le dataset.
Itération 3 : Compréhension des valeurs de données
Un espace Genie doit être organisé pour répondre à des questions spécifiques à un domaine. Cependant, les gens n'utilisent pas toujours exactement la même terminologie que celle qui apparaît dans nos données. Les utilisateurs peuvent dire "sociétés de bio-ingénierie", mais la valeur des données est "biotechnologie".
L'activation des dictionnaires de valeurs et de l'échantillonnage des données permet une recherche plus rapide et plus précise des valeurs telles qu'elles existent dans les données, plutôt que de laisser Genie utiliser uniquement la valeur exacte demandée par l'utilisateur final.

Les valeurs d'exemple et les dictionnaires de valeurs sont désormais activés par défaut, mais il est judicieux de vérifier que les colonnes appropriées couramment utilisées pour le filtrage sont activées et disposent de dictionnaires de valeurs personnalisés si nécessaire.
Analyse comparative : plus de 50 % des questions de référence obtiennent désormais des réponses correctes. Les questions portant sur des valeurs de catégories spécifiques comme « biotechnologie » ont commencé à identifier correctement les filtres appropriés. Le défi consiste maintenant à implémenter des métriques et des agrégations personnalisées. Par exemple, Genie fournit une estimation de la manière de calculer le CTR en se basant sur la valeur de donnée « clic » et sur sa compréhension des métriques basées sur un taux. Mais il n'est pas assez confiant pour simplement générer les queries :
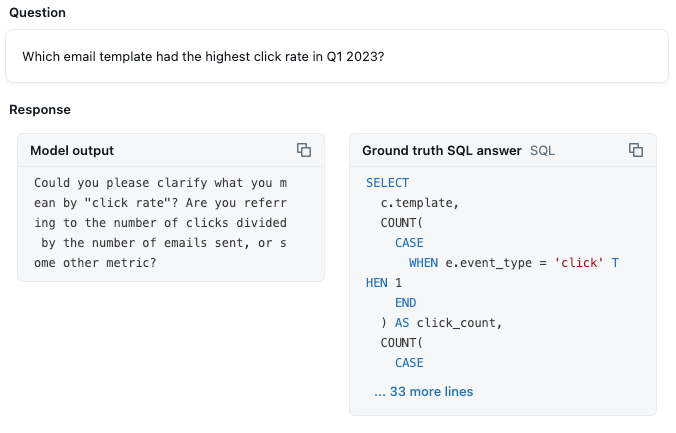
Il s'agit d'une métrique qui doit être calculée correctement 100 % du temps, nous devons donc clarifier ce détail pour Genie.
insight : L'échantillonnage de valeurs améliore la génération SQL de Genie en fournissant un accès aux valeurs de données réelles. Lorsque les utilisateurs posent des questions conversationnelles contenant des fautes d'orthographe ou une terminologie différente, l'échantillonnage de valeurs aide Genie à faire correspondre les invites aux valeurs de données réelles dans vos tables.
Action suivante : Le problème le plus courant actuellement est que Genie ne génère toujours pas le SQL correct pour nos métriques personnalisées. Définissons explicitement nos définitions de métriques pour obtenir des résultats plus précis.
Itération 4 : Définition de métriques personnalisées
À ce stade, Genie dispose du contexte pour les attributs de données catégorielles existant dans les données, peut filtrer nos valeurs de données et effectuer des agrégations simples à partir de fonctions SQL standard (par ex. « count events by type » utilise COUNT()). Pour clarifier la manière dont Genie doit calculer nos métriques, nous avons ajouté des exemples de requêtes SQL à notre genie space. Cet exemple illustre la définition correcte de la métrique pour le CTR :
Remarque : il est recommandé de laisser des commentaires dans vos requêtes SQL, car ils fournissent un contexte pertinent au code.
Analyse comparative : cela a permis d'obtenir la plus grande amélioration de la précision à ce jour. Considérez que notre objectif est de rendre Genie capable de répondre à des questions à un niveau très détaillé pour un public défini. On s'attend à ce que la majorité des questions des utilisateurs finaux s'appuient sur des métriques personnalisées, comme le CTR, les taux de spam, les métriques d'engagement, etc. Plus important encore, des variations de ces questions ont également fonctionné. Genie a appris la définition de notre métrique et l'appliquera à toute query à l'avenir.
Insight : Les exemples de requêtes enseignent une logique métier que les métadonnées seules ne peuvent pas transmettre. Un seul exemple de query bien conçu résout souvent simultanément toute une catégorie de lacunes de benchmark. Cela a apporté plus de valeur que toute autre étape d'itération unique jusqu'à présent.
Prochaine action : il ne reste que quelques questions de benchmark incorrectes. Après un examen plus approfondi, nous remarquons que les benchmarks restants échouent pour deux raisons :
- Les utilisateurs posent des questions sur des attributs de données qui n'existent pas directement dans les données. Par exemple, « combien de campagnes ont généré un CTR élevé au dernier trimestre ? » Genie ne sait pas ce que l'utilisateur entend par CTR « élevé », car cet attribut de données n'existe pas.
- Ces tables de données incluent des enregistrements que nous devrions exclure. Par exemple, nous avons de nombreuses campagnes de test qui ne sont pas envoyées aux clients. Nous devons exclure celles-ci de nos KPI.
Itération 5 : documenter les règles spécifiques au domaine
Ces lacunes restantes sont des éléments de contexte qui s'appliquent de manière globale à la façon dont toutes nos requêtes doivent être créées, et se rapportent à des valeurs qui n'existent pas directement dans nos données.
Prenons ce premier exemple concernant un CTR élevé, ou quelque chose de similaire comme les campagnes à coût élevé. Il n'est pas toujours facile, ni même recommandé, d'ajouter des données spécifiques au domaine à nos tables, et ce pour plusieurs raisons :
- Apporter des modifications, comme l'ajout d'un champ
campaign_cost_segmentation(élevé, moyen, faible), aux tables de données prendra du temps et aura un impact sur d'autres processus, car les schémas de table et les pipelines de données devront tous être modifiés. - Pour les calculs agrégés comme le CTR, les valeurs du CTR changeront à mesure que de nouvelles données arriveront. De toute façon, nous ne devrions pas précalculer ce résultat. Nous voulons que ce calcul soit effectué à la volée à mesure que nous précisons les filtres, comme les périodes et les campagnes.
Nous pouvons donc utiliser une instruction textuelle dans Genie pour effectuer cette segmentation spécifique au domaine.

De même, nous pouvons spécifier comment Genie doit toujours écrire les queries pour s'aligner sur les attentes métier. Cela peut inclure des éléments tels que des calendriers personnalisés, des filtres globaux obligatoires, etc. Par exemple, ces données de campagne incluent des campagnes de test qui devraient être exclues de nos calculs de KPI.


Analyse des benchmarks : Précision des benchmarks de 100 % ! Les cas limites et les questions basées sur des seuils ont commencé à fonctionner de manière cohérente. Les questions sur les « campagnes très performantes » ou les « campagnes à risque de non-conformité » appliquaient désormais correctement nos définitions métier.
Insight : les instructions textuelles sont un moyen simple et efficace de combler les lacunes restantes des étapes précédentes, afin de garantir que les bonnes requêtes sont générées pour les utilisateurs finaux. Toutefois, ce ne devrait pas être le premier ni le seul endroit sur lequel vous vous appuyez pour l'injection de contexte.
Notez qu'il n'est peut-être pas possible d'atteindre une précision de 100 % dans certains cas. Par exemple, les questions de benchmark nécessitent parfois des requêtes très complexes ou plusieurs invites pour générer la bonne réponse. Si vous ne parvenez pas à créer facilement un seul exemple de SQL query, notez simplement cet écart lorsque vous partagez les résultats de votre évaluation de benchmark avec d'autres. L'attente habituelle est que les benchmarks de Genie soient supérieurs à 80 % avant de passer aux tests d'acceptation par l'utilisateur (UAT).
Prochaine action : Maintenant que Genie a atteint le niveau de précision attendu sur nos questions de référence, nous allons passer à l'UAT et recueillir davantage de commentaires des utilisateurs finaux !
(Facultatif) Itération 6 : Pré-calcul des métriques complexes
Pour notre dernière itération, nous avons créé une vue personnalisée qui prédéfinit les métriques marketing clés et appliqué des classifications commerciales. Créer une vue ou une vue de métrique peut être plus simple dans les cas où vos datasets s'intègrent tous dans un seul modèle de données, et que vous avez des dizaines de métriques personnalisées. Il est plus facile d'intégrer tout cela dans une définition d'objet de données plutôt que d'écrire un exemple de requête SQL pour chacun d'eux, spécifique à l'espace Genie.
Résultat de l'analyse comparative : nous avons tout de même atteint une précision de 100 % dans l'analyse comparative en utilisant des vues au lieu de simples tables de base, car le contenu des métadonnées est resté le même.
Insight : au lieu d'expliquer des calculs complexes à l'aide d'exemples ou d'instructions, vous pouvez les encapsuler dans une vue ou une vue de métrique, définissant une source de vérité unique.
Ce que nous avons appris : L'impact du développement piloté par les benchmarks
Il n'y a pas de « solution miracle » pour la configuration d'un espace Genie qui résout tout. Une précision prête pour la production n'est généralement atteinte que lorsque vous disposez de données de haute qualité, de métadonnées enrichies de manière appropriée, d'une logique de métriques définie et d'un contexte spécifique au domaine injecté dans l'espace. Dans notre exemple de bout en bout, nous avons rencontré des problèmes courants qui couvraient tous ces domaines.
Les benchmarks sont essentiels pour évaluer si votre espace répond aux attentes et est prêt pour les retours des utilisateurs. Cela a également guidé nos efforts de développement pour combler les lacunes dans l'interprétation des questions par Genie. En résumé :
- Itérations 1 à 3 - 54 % de précision du benchmark. Ces itérations visaient à permettre à Genie de prendre plus clairement conscience de nos données et métadonnées. L'implémentation de noms de table, de descriptions de table, de descriptions de colonne, de clés de jointure appropriés et l'activation de valeurs d'exemple sont autant d'étapes fondamentales pour tout espace Genie. Grâce à ces capacités, Genie devrait identifier correctement la bonne table, les bonnes colonnes et les bonnes conditions de jointure, qui affectent toute requête qu'il génère. Il peut également effectuer des agrégations et un filtrage simples. Genie a pu répondre correctement à plus de la moitié de nos questions de benchmark spécifiques au domaine avec seulement ces connaissances de base.
- Itération 4 - Précision du benchmark de 77 %. Cette itération s'est concentrée sur la clarification des définitions de nos métriques personnalisées. Par exemple, le CTR ne fait pas partie de toutes les questions du benchmark, mais c'est un exemple de métrique non standard (c.-à-d. sum(), avg(), etc.) qui doit être traitée correctement à chaque fois.
- Itération 5 : 100 % de précision du benchmark. Cette itération a démontré l'utilisation d'instructions textuelles pour combler les lacunes restantes en matière d'imprécisions. Ces instructions ont permis de prendre en compte des scénarios courants, tels que l'inclusion de filtres globaux sur les données à des fins d'analyse, et des définitions spécifiques au domaine (par ex. ce qui constitue une campagne à fortengagement), ainsi que des informations spécifiées sur les calendriers fiscaux.
En suivant une approche systématique pour évaluer notre Genie space, nous avons détecté un comportement de requête inattendu de manière proactive, plutôt que d'en entendre parler par Sarah de manière réactive. Nous avons transformé une évaluation subjective ("ça semble fonctionner") en une mesure objective ("nous avons validé que cela fonctionne pour 13 scénarios représentatifs couvrant nos principaux cas d'utilisation, tels que définis initialement par les utilisateurs finaux").
La voie à suivre
Instaurer la confiance dans l'analytique en libre-service ne consiste pas à atteindre la perfection dès le premier jour. Il s'agit d'une amélioration systématique avec une validation mesurable. Il s'agit de détecter les problèmes avant les utilisateurs.
La fonctionnalité Benchmarks fournit la couche de mesure qui rend cela possible. Elle transforme l'approche itérative recommandée par la documentation de Databricks en un processus quantifiable qui renforce la confiance. Récapitulons ce processus de développement systématique et basé sur les benchmarks :
- Créez des questions de benchmark (visez-en 10 à 15) qui représentent les questions réalistes de vos utilisateurs.
- Testez votre espace pour établir la précision de base.
- Améliorez la configuration en suivant l'approche itérative que Databricks recommande dans nos meilleures pratiques
- Testez à nouveau tous les benchmarks après chaque modification pour en mesurer l'impact et identifier les lacunes de contexte à partir des questions incorrectes. Documentez la progression de votre précision pour renforcer la confiance des parties prenantes.
Commencez avec de solides fondations pour Unity Catalog. Ajoutez un contexte métier. Testez de manière exhaustive à l'aide de points de référence. Mesurez chaque changement. Renforcez la confiance grâce à une précision validée.
Vous et vos utilisateurs finaux en bénéficierez !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.