Comment passer d'Apache Airflow® à Databricks Lakeflow Jobs
Un guide pratique qui met en correspondance les pratiques courantes d'Airflow avec les tâches Lakeflow Jobs de Databricks, avec des exemples de code côte à côte.
par Zanita Rahimi, Zach Hasen, Lorenzo Rubio et Saad Ansari
- Apprenez comment les modèles d'orchestration Apache Airflow courants correspondent directement aux capacités de Lakeflow Jobs, l'orchestrateur intégré de Databricks.
- Comprenez comment le flux de contrôle, les déclencheurs, les paramètres et l'exécution dynamique fonctionnent lorsque l'orchestration est intégrée au lakehouse.
- Utilisez des exemples de code copiables pour migrer progressivement des DAGs réels d'Airflow vers Lakeflow Jobs.
Dans l'article précédent, From Apache Airflow® to Lakeflow: Data-First Orchestration, l'orchestration a été redéfinie autour des données et du lakehouse au lieu de planificateurs externes. Cet article s'appuie sur cette base et se concentre sur les détails d'exécution pour les équipes qui exécutent déjà Airflow en production et souhaitent passer à l'orchestrateur natif de Databricks, Lakeflow Jobs.
Ce guide est écrit à la fois pour les praticiens migrant d'Airflow et pour les agents de programmation générant des flux de travail Lakeflow Jobs. L'objectif est de montrer comment ces mêmes flux de travail peuvent être exprimés naturellement lorsque l'orchestration fait partie du lakehouse lui-même au sein de Databricks.
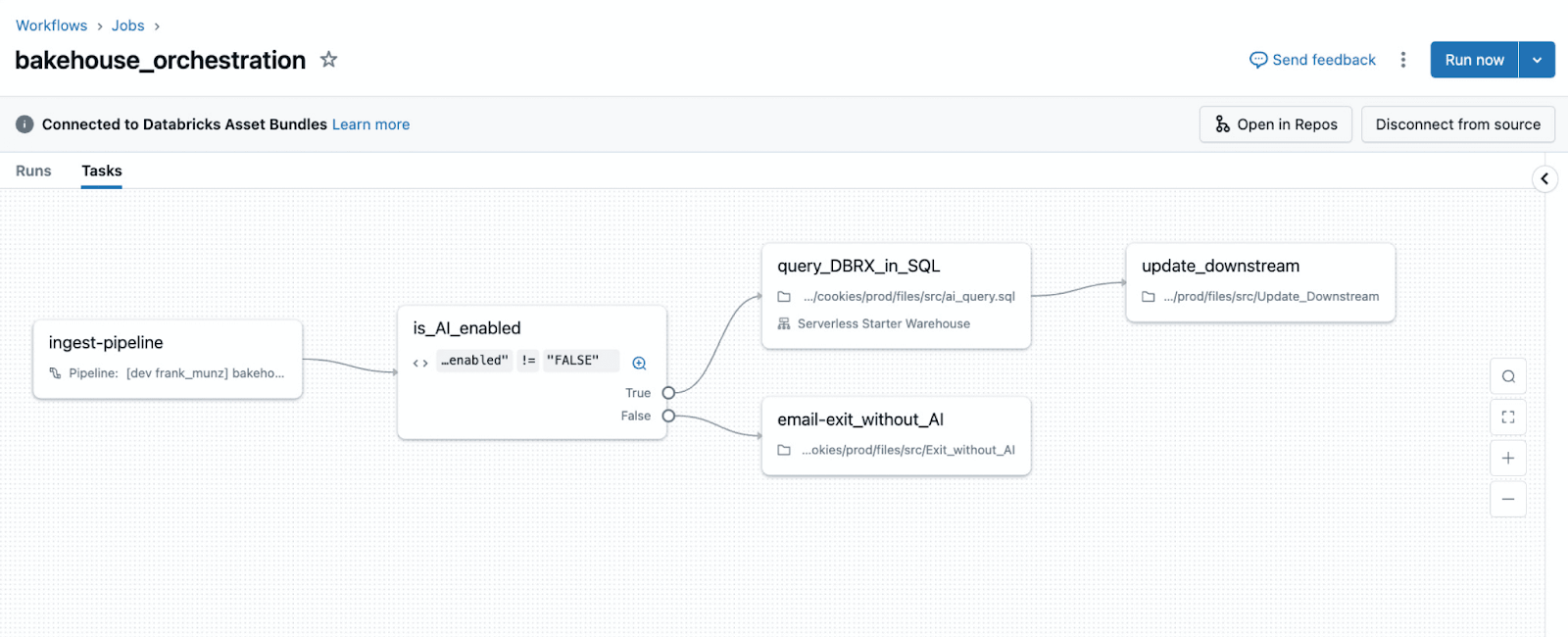
Carte de migration d'Airflow vers Lakeflow Jobs
Le tableau ci-dessous résume comment les modèles d'orchestration courants d'Airflow se traduisent en Lakeflow Jobs, et si la migration est une traduction directe ou un refactoring conceptuel.
Modèle Airflow | Utilisation principale | Équivalent Lakeflow Jobs | Conseils de migration |
XComs | Transférer de petites métadonnées de contrôle entre les tâches | Utiliser les valeurs de tâche pour les petites métadonnées ; déplacer les données réelles dans les tables Unity Catalog | |
Capteurs (Sensors) | Attendre des fichiers ou des conditions | Déclencheurs d'arrivée de fichier / déclencheurs de mise à jour de table | Remplacer les capteurs par interrogation par des déclencheurs intégrés |
Rétro-remplissages (Backfills) | Réexécuter pour des dates historiques | Rétro-remplissages de tâches backfills + paramètres | Traiter le temps comme des données, utiliser des rétro-remplissages paramétrés |
Branchement (Branching) | Exécution conditionnelle de tâches | Tâches conditionnelles (SI/NON) (if/else) | Remplacer task.branch par des tâches If-Else |
Mappage dynamique de tâches (Dynamic task mapping) | Fan-out à l'exécution | Tâches Pour-chaque (For-each) | Utiliser Pour-chaque lorsque le nombre de tâches dépend des données d'exécution |
Stratégie de migration : incrémentale, pas tout d'un coup
La plupart des équipes migrent progressivement plutôt que de remplacer Airflow en bloc. Les approches courantes incluent :
- Commencer par des flux de travail autonomes ou pilotés par événement
- Migrer tôt les déclencheurs d'arrivée de fichier et les déclencheurs pilotés par les données
- Laisser les pipelines Airflow stables inchangés initialement
- Éviter de réécrire les tâches matures à faible risque
Lakeflow Jobs est conçu pour coexister pendant la migration et pour reprendre les responsabilités d'orchestration là où il apporte le plus de valeur.
Liste de contrôle
XComs avec de petites métadonnées → valeurs de tâche ; XComs avec des données → tables Unity Catalog ou volumes.
- Capteurs/actifs de fichier → déclencheurs d'arrivée de fichier ou de mise à jour de table lorsque les données sont dans UC.
Macros de date d'exécution (
ds, etc.) → paramètres explicites + exécutions de rétro-remplissage.Branchement (
@task.branch) → tâches conditionnelles.Mappage dynamique de tâches → tâches pour-chaque lorsque le fan-out est piloté par les données.
(Optionnel) Tâches et schémas gérés via des paquets d'actifs Python pour des environnements cohérents.
Présentation de Lakeflow Jobs
Lors de la migration depuis Airflow, il est utile d'intégrer quelques hypothèses fondamentales qui façonnent le fonctionnement de Lakeflow Jobs :
Plan de contrôle vs plan de données
Les opérations dans le plan de données (requêtes, lectures, écritures et transformations) entraînent l'utilisation du calcul. Les opérations du plan de contrôle telles que les déclencheurs, les valeurs de tâche et les paramètres n'en entraînent pas.
Les tâches sont l'unité d'orchestration
- Les tâches encapsulent les tâches et les dépendances ; la coordination entre les tâches utilise généralement des données (tables, fichiers), pas des signaux inter-DAG
- Cela déplace la conception de « DAG parlant à DAG » à « le producteur écrit une table, la tâche consommatrice se déclenche lorsque cette table change ».
- Une tâche Run Job existe pour les cas où l'invocation de tâche à tâche est intentionnelle, mais elle complète plutôt qu'elle ne remplace le modèle de coordination piloté par les données.
Les déclencheurs sont de première classe
- Les déclencheurs d'arrivée de fichier et de mise à jour de table sont des fonctionnalités intégrées, non implémentées via des capteurs de longue durée.
- Cela déplace l'orchestration de l'interrogation par défaut à l'événementiel.
Ces hypothèses expliquent pourquoi certains modèles Airflow se traduisent directement, tandis que d'autres sont intentionnellement simplifiés ou remplacés.
Étapes de migration
1. XComs vers valeurs de tâche pour le contrôle, tables pour les données
Airflow : XComs pour les petites métadonnées de contrôle
Dans Apache Airflow, les XComs sont utilisés pour passer de petits morceaux de métadonnées entre les tâches au sein d'une exécution de DAG. Un exemple minimal d'Airflow qui passe une petite valeur entre les tâches :
Cela fonctionne bien pour les petits identifiants, valeurs, drapeaux et comptes, mais devient difficile à raisonner lorsque de nombreuses tâches dépendent des XComs ou lorsque de grandes charges utiles sont poussées.
Lakeflow : valeurs de tâche pour le contrôle, tables pour les données
Dans Lakeflow Jobs, les valeurs de tâche jouent le rôle de XCom pour les métadonnées de contrôle. Les tâches et les tâches sont généralement définies via des paquets d'actifs, et leurs implémentations résident dans des notebooks ou des fichiers Python. Extrait de paquet (Python) définissant deux tâches et une dépendance :
Notebook producteur :
Notebook consommateur :
Les valeurs de tâche sont visibles dans l'interface utilisateur des tâches Lakeflow par exécution et sont limitées aux petites charges utiles, ce qui les rend idéales pour les indicateurs, les compteurs et les identifiants. Pour les objets plus volumineux ou les sorties réutilisables, les tâches doivent écrire dans les tables ou vues de Unity Catalog :
💡 Règle générale : Utilisez les valeurs de tâche uniquement pour les métadonnées de contrôle ; placez tout ce qui ressemble à des données dans des tables, des vues ou des volumes.
Conseils de migration
- XComs simples → valeurs de tâche.
- XComs qui transportent des dataframes ou du JSON volumineux → lectures/écritures dans Unity Catalog à la place.
- Évitez de reproduire des DAGs lourds en XCom ; appuyez-vous sur le lakehouse comme état partagé.
2. Capteurs et actifs vers des déclencheurs de fichiers et de tables
Airflow : capteurs de fichiers et actifs
Modèle Airflow typique pour un pipeline piloté par des fichiers :
Cela maintient un slot de travail occupé à interroger et se combine souvent avec le suivi d'actifs personnalisé lorsque plusieurs consommateurs dépendent des mêmes données.
Lakeflow : déclencheurs d'arrivée de fichiers
Extrait montrant un déclencheur d'arrivée de fichier
Implémentation du notebook
La plateforme gère l'état du déclencheur, le त्यांच्या debounce et le cooldown, et vous n'avez plus besoin de capteurs de longue durée ou de planificateurs externes pour surveiller les fichiers.
Lakeflow : déclencheurs de mise à jour de table (planification de style actif)
Lorsque les producteurs écrivent dans les tables Unity Catalog, les consommateurs peuvent se déclencher sur les mises à jour de table au lieu des planifications basées sur le temps.
💡Règle générale : Déclenchez les tâches sur les arrivées de fichiers ou les mises à jour de table chaque fois que possible ; utilisez les planifications uniquement lorsque vous en avez vraiment besoin.
Conseils de migration
- Capteurs de fichiers → déclencheurs d'arrivée de fichiers sur les emplacements UC ou les volumes.
- Registres d'actifs → tables Unity Catalog avec déclencheurs de mise à jour de table.
- Événements non-données → déclencheurs externes explicites ou paramètres.
3. Dates d'exécution vers paramètres et exécutions de rétro-programmation
Airflow : date d'exécution et ds
Airflow encourage la mise en modèle de la logique avec les dates d'exécution :
Les rétro-programmation sont pilotées par le planificateur d'Airflow et les dates d'exécution ; la logique dépend implicitement du concept de temps du planificateur.
Lakeflow : paramètres explicites et rétro-programmation
Dans Lakeflow Jobs, la « date d'exécution logique » doit être modélisée comme un paramètre. Définition de tâche (bundles) avec un paramètre :
Note : vous pouvez également utiliser {{ job.trigger.time.iso_date }} si vous souhaitez utiliser le style Airflow {{ds}} ou {{ execution_date }} au lieu de données codées en dur dans l'exemple ci-dessus.
SQL utilise le paramètre :
Pour la rétro-programmation, vous définissez un ensemble de valeurs de paramètres et exécutez des rétro-programmation sur celles-ci dans l'interface utilisateur ou via l'API, plutôt que de vous fier à la rattrapage implicite du planificateur. Les paramètres sont définis une fois et remplacés au moment de l'exécution lors du déclenchement d'une exécution de rétro-programmation
💡Règle générale : Traitez le temps comme des données ; modélisez-le comme un paramètre, transmettez-le explicitement aux tâches et pilotez les rétro-programmation via des plages de paramètres.
Conseils de migration
- Remplacez
{{ ds }}et les macros associées par des paramètres (par exemple, :run_date). - Rendez les tâches idempotentes pour un ensemble de paramètres donné afin que les rétro-programmation restent sûres.
- Utilisez les exécutions de rétro-programmation Lakeflow plutôt que de recréer la logique de rattrapage pilotée par le planificateur.
4. Branchement et mappage dynamique vers des tâches de condition et for-each
Airflow : branchement et mappage dynamique de tâches
Branchement avec @task.branch :
Mappage dynamique de tâches pour le fan-out à l'exécution à l'aide de expand() :
Lakeflow : tâches conditionnelles
Les tâches Lakeflow utilisent des tâches conditionnelles pour le branchement piloté par les données
le notebook check_quality émet une valeur de tâche :
Le graphe montre explicitement la branche, et la logique de décision est exprimée via des données (valeurs de tâches) plutôt que par un flux de contrôle Python intégré.
💡Règle générale : Utilisez des tâches conditionnelles lorsqu'une expression booléenne sur des paramètres ou des valeurs de tâches détermine le chemin.
Lakeflow : tâches for-each pour le fan-out à l'exécution
Les tâches For-each implémentent le fan-out lorsque le nombre de tâches dépend des données d'exécution.
notebook generate_items :
le notebook process_item voit l'élément actuel comme {{input}} (ou la variable d'exécution équivalente en fonction de l'encapsuleur de langage).
💡Règle générale : Utilisez for-each lorsque le fan-out est piloté par des données d'exécution ; gardez les tâches statiques lorsque le fan-out est fixé au moment de la conception.
Conseils de migration
@task.branch→ tâches conditionnelles utilisant des valeurs de tâches ou des paramètres.- Mappage dynamique de tâches → tâches for-each pilotées par des valeurs de tâches ou des tables.
- Métadonnées d'itération volumineuses → tables/volumes ; petits ID/index → valeurs de tâches.
5. (Optionnel) Génération programmatique avec les bundles d'actifs Python
De nombreux déploiements Airflow génèrent des DAG dynamiquement (un DAG par table ou fichier SQL) et gèrent les différences d'environnement via des conventions et des scripts. Les bundles d'actifs Python offrent un moyen structuré de générer des tâches et des ressources associées par programme.
Exemple : une tâche par fichier SQL :
Vous pouvez combiner cela avec des mutateurs pour ajuster les notifications, les identités d'exécution ou les nouvelles tentatives par environnement, en centralisant les normes tout en gardant les définitions de tâches en Python.
💡 Règle générale : Utilisez la génération programmatique pour coder les conventions de la plateforme, pas pour masquer des solutions de contournement ponctuelles.
Prochaines étapes
Si vous utilisez actuellement Airflow, choisissez un DAG qui repose sur des capteurs, des XComs ou un mappage dynamique de tâches et réimplémentez-le en utilisant un déclencheur, une tâche for-each et des paramètres explicites. C'est généralement suffisant pour internaliser le modèle mental des tâches Lakeflow.
Clonez et exécutez les exemples de travail complets utilisés dans ce guide
En savoir plus sur l'orchestration axée sur les données
Explorez la documentation des tâches Lakeflow
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.