Présentation d'AI Runtime : des GPU NVIDIA évolutifs et sans serveur sur Databricks pour l'entraînement et le réglage fin
Entraînez les derniers LLM avec des GPU NVIDIA H100 instantanément disponibles connectés à votre Lakehouse
par Tejas Sundaresan, Jianwei Xie, Bandish Shah et Hanlin Tang
- Avec AI Runtime, Databricks prend désormais en charge les GPU NVIDIA dans Serverless Compute, permettant un accès à la demande aux GPU NVIDIA A10 et H100 évolutifs sans surcharge d'infrastructure.
- Entraînez des modèles de vision par ordinateur, des LLM, des systèmes de recommandation basés sur l'apprentissage profond, et d'autres modèles avec notre runtime dédié à l'entraînement distribué – le tout prêt à l'emploi.
- AI Runtime est intégré à un chargement de données à haute vitesse depuis les données du Lakehouse, à l'orchestration des workflows avec Lakeflow, et à la gouvernance avec Unity Catalog.
Les GPU alimentent les charges de travail d'IA les plus avancées d'aujourd'hui, de la prévision et des recommandations aux modèles fondamentaux multimodaux. Cependant, les équipes ont du mal à se procurer et à gérer l'infrastructure GPU, à configurer des environnements d'entraînement distribué et à déboguer les goulots d'étranglement du chargement des données. Les chercheurs en apprentissage profond préfèrent se concentrer sur la modélisation, pas sur le dépannage de l'infrastructure.
Nous sommes ravis d'annoncer la préversion publique de AI Runtime (AIR), une nouvelle pile d'entraînement qui permet l'entraînement distribué de GPU à la demande sur les A10 et H100. AI Runtime contient toute la technologie utilisée pour l'entraînement à grande échelle des LLM tels que MPT et DBRX. Même en version bêta, plusieurs centaines de clients, dont Rivian, Factset et YipitData, ont utilisé AIR pour entraîner et déployer des modèles d'apprentissage profond en production. Les cas d'utilisation vont des modèles de vision par ordinateur aux systèmes de recommandation en passant par les LLM affinés pour des tâches d'agent. Notre propre équipe de recherche en IA de Databricks a utilisé AIR pour l'apprentissage par renforcement de modèles tels que dans notre récent article sur KARL.
Avec AI Runtime, les utilisateurs de Databricks disposent désormais de :
- GPU NVIDIA sans serveur et à la demande : Configurez simplement votre notebook en 2-3 clics et obtenez une connexion rapide aux GPU A10 et H100 sans serveur pour commencer l'entraînement – aucun cluster nécessaire. Ne payez que pour les GPU que vous utilisez, sans vous soucier de l'utilisation du temps d'inactivité.
- Outils d'orchestration robustes : Utilisez toute la puissance de la suite d'orchestration de Databricks avec Lakeflow Jobs et la prise en charge de DABs pour les charges de travail GPU de longue durée
- Entraînement distribué optimisé : AIR regroupe des améliorations de performance GPU distribuées, telles que RDMA et le chargement de données haute performance
- Gouvernance et observabilité centralisées : exécutez, observez et gouvernez les charges de travail GPU exactement là où résident vos données, avec une gestion intégrée des expériences via MLflow, une gestion des accès avec Unity Catalog et un débogage assisté par agent
GPU NVIDIA H100 et A10 à la demande dans les notebooks
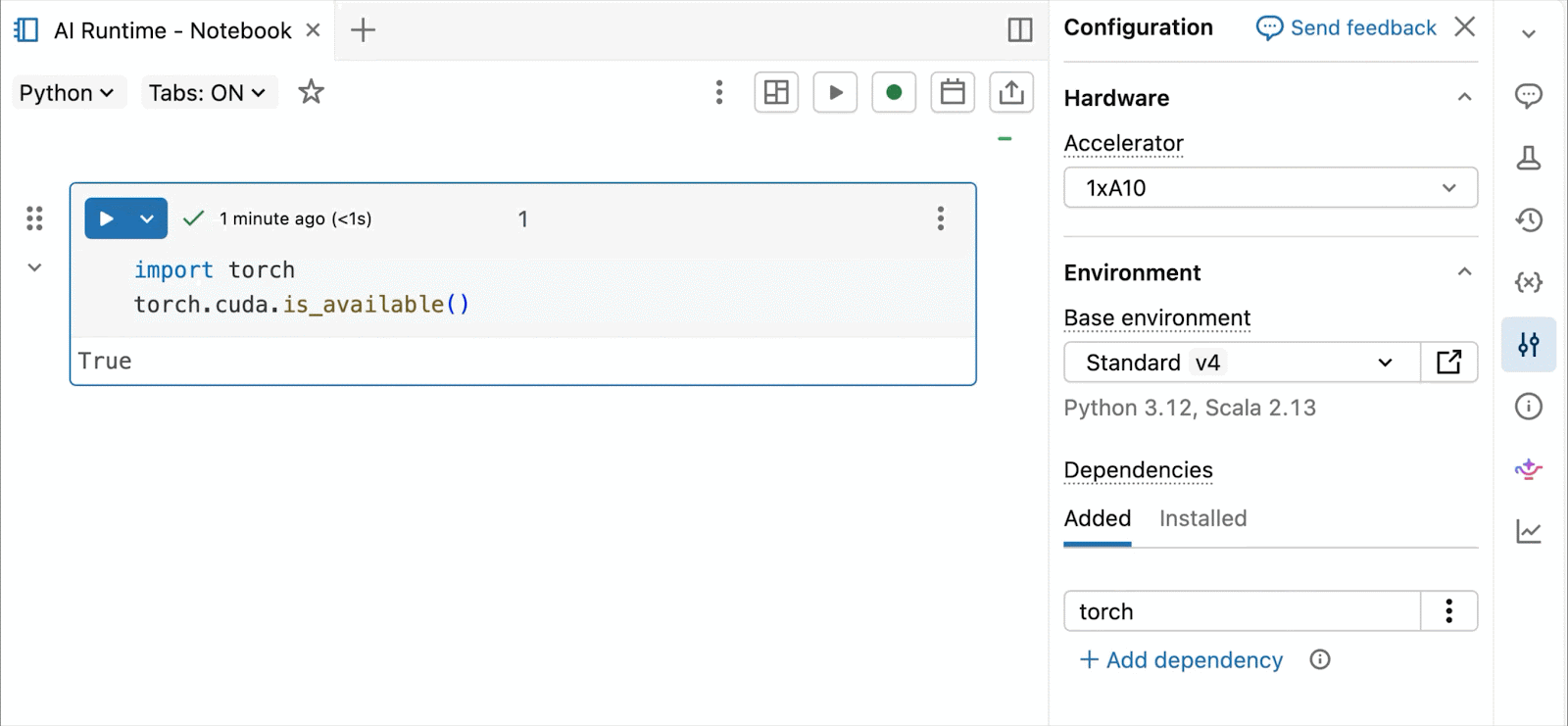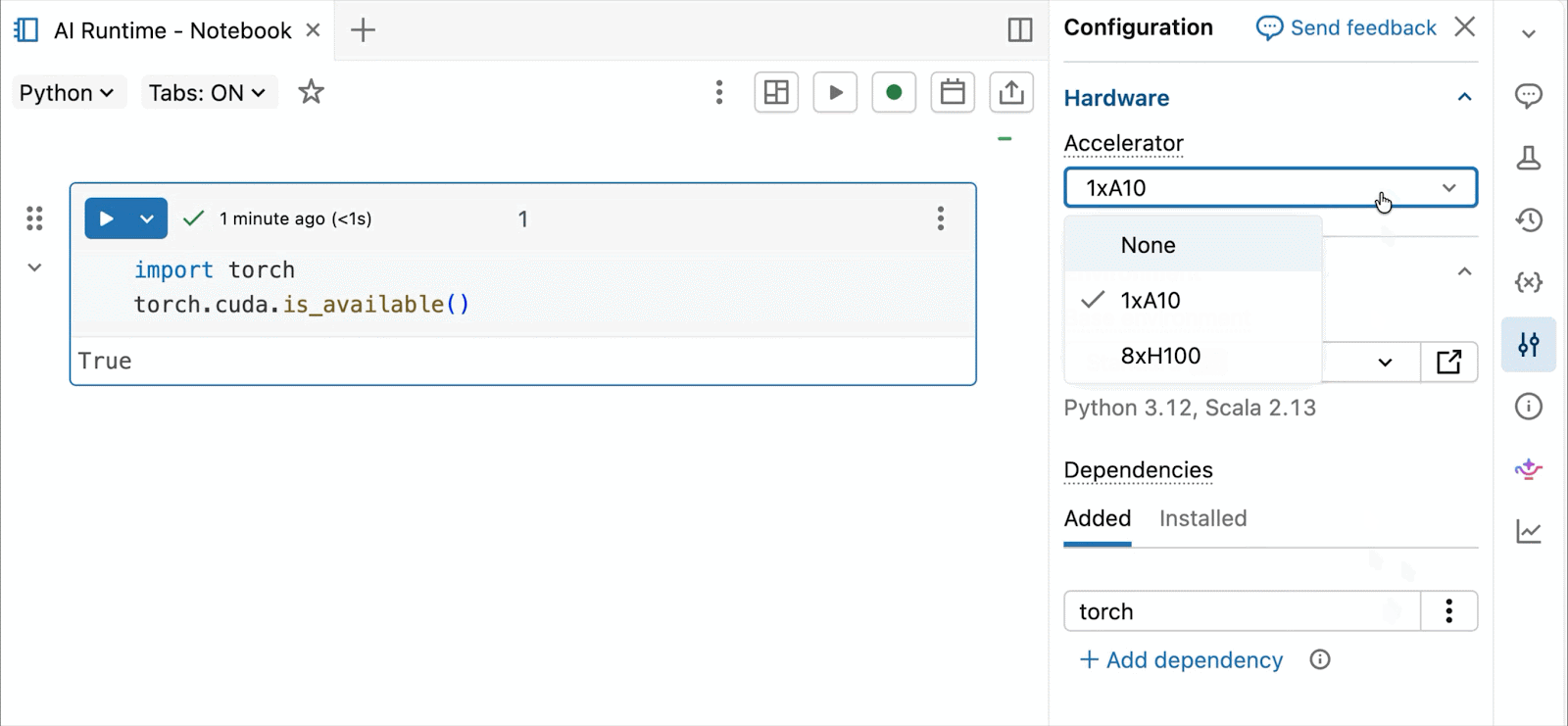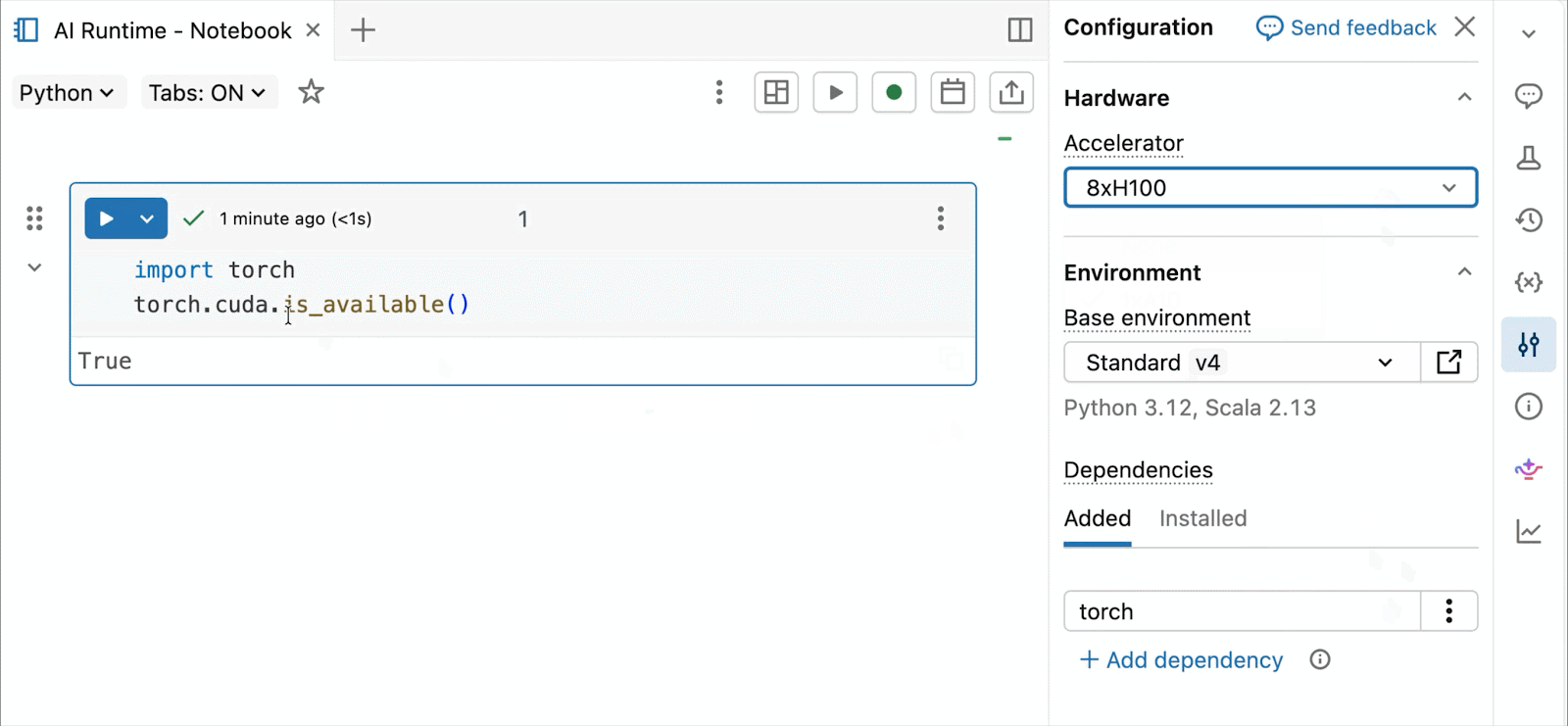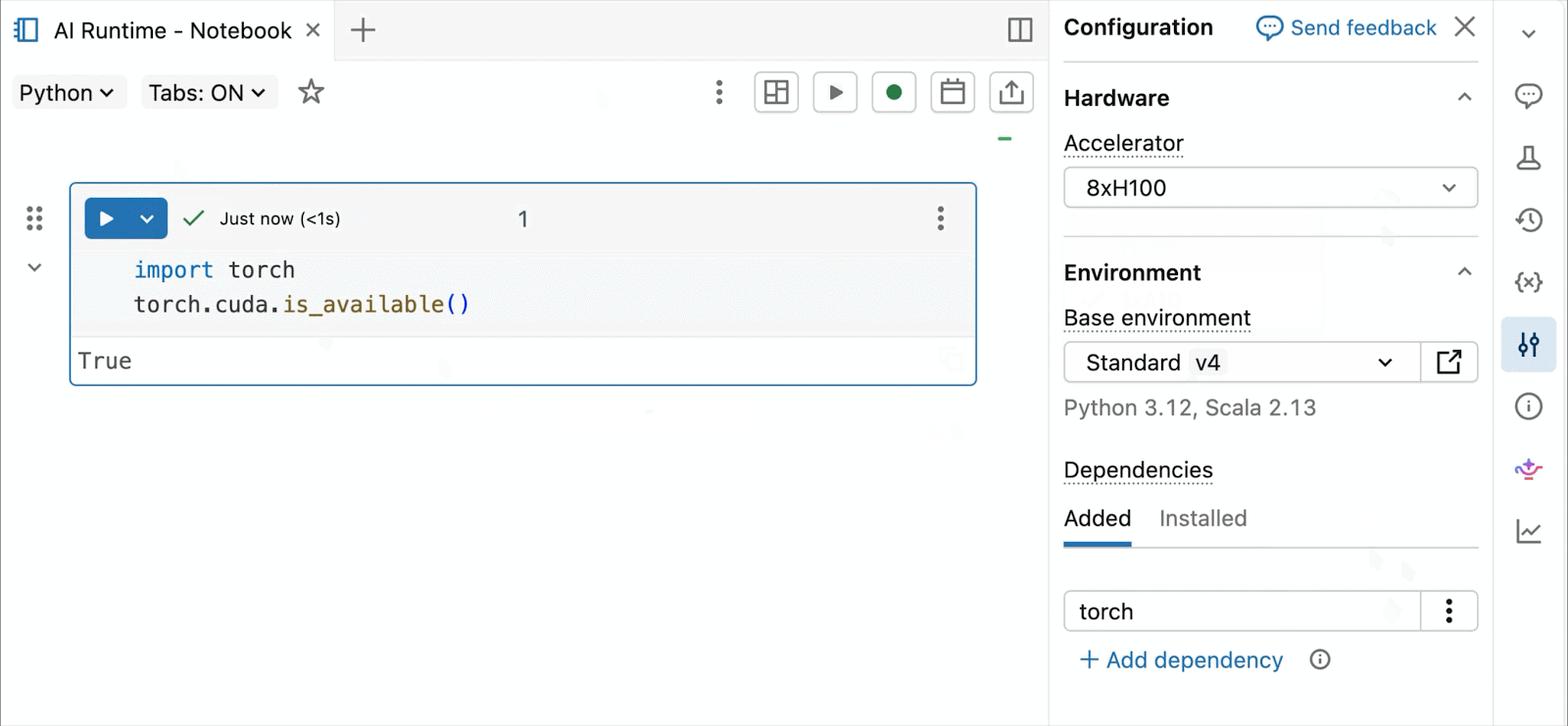
Pour le développement et le débogage interactifs, connectez-vous aux A10 et H100 à la demande dans les notebooks Databricks en quelques clics. À partir de là, tirez parti de toutes les ergonomies de développeur pour lesquelles Databricks est connu, de la gestion de l'environnement pour les packages Python courants à la création et au débogage assistés par agent avec Genie Code. Montez facilement des données du Lakehouse pour entraîner des modèles d'apprentissage profond, ou même invoquez une flotte de CPU distants pour des charges de travail de traitement de données Spark à partir de votre notebook alimenté par GPU pour préparer vos données.
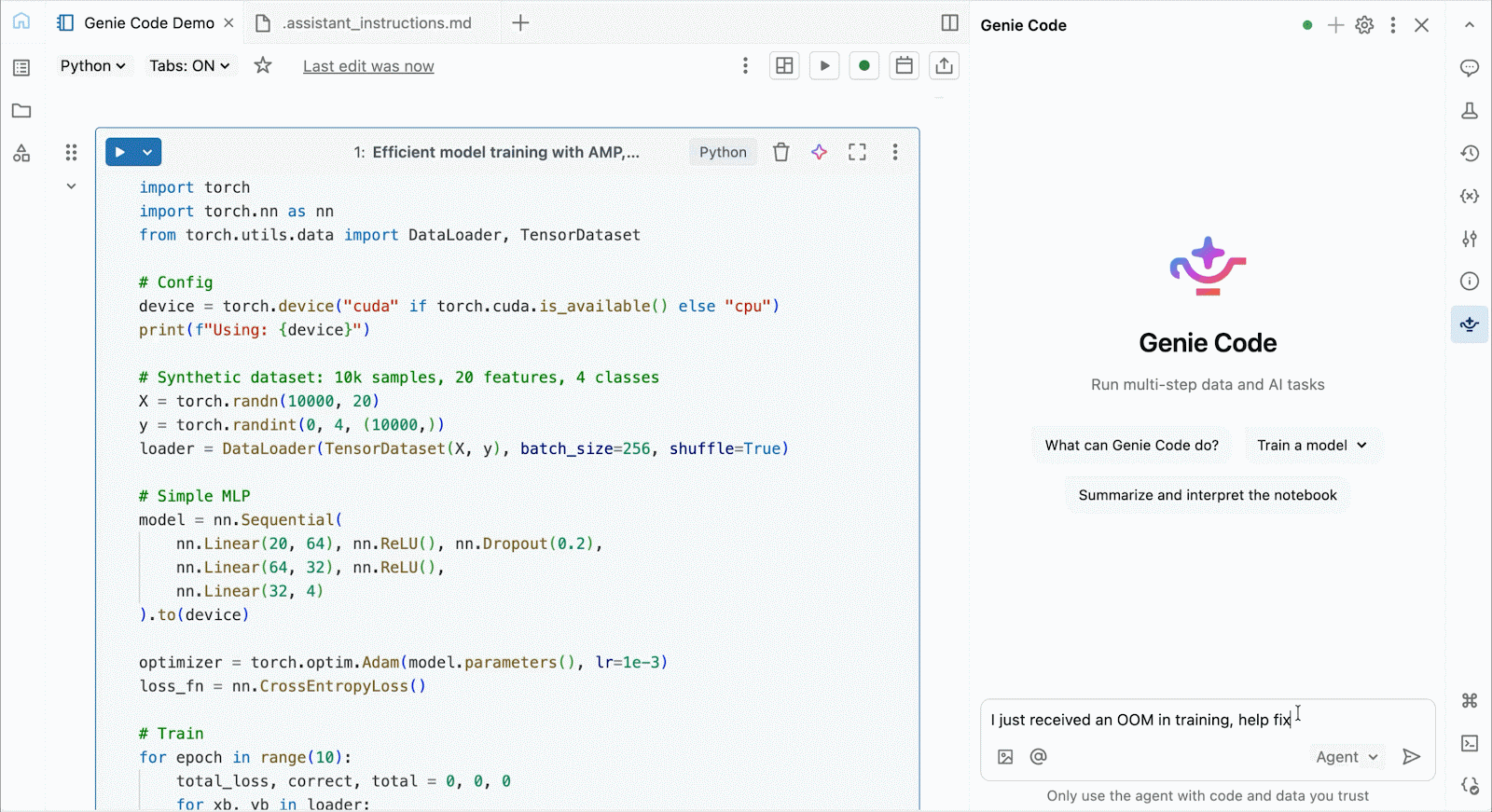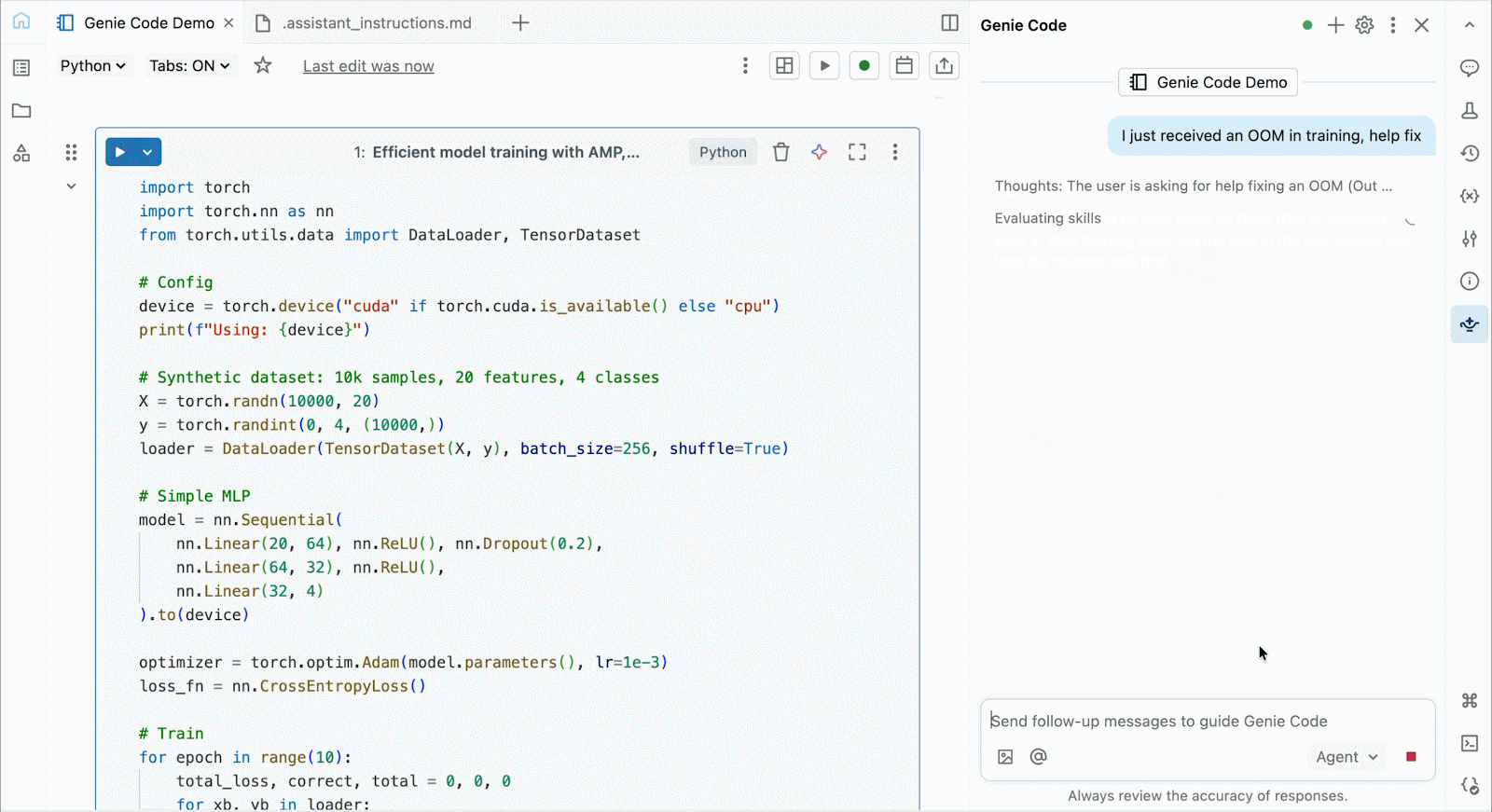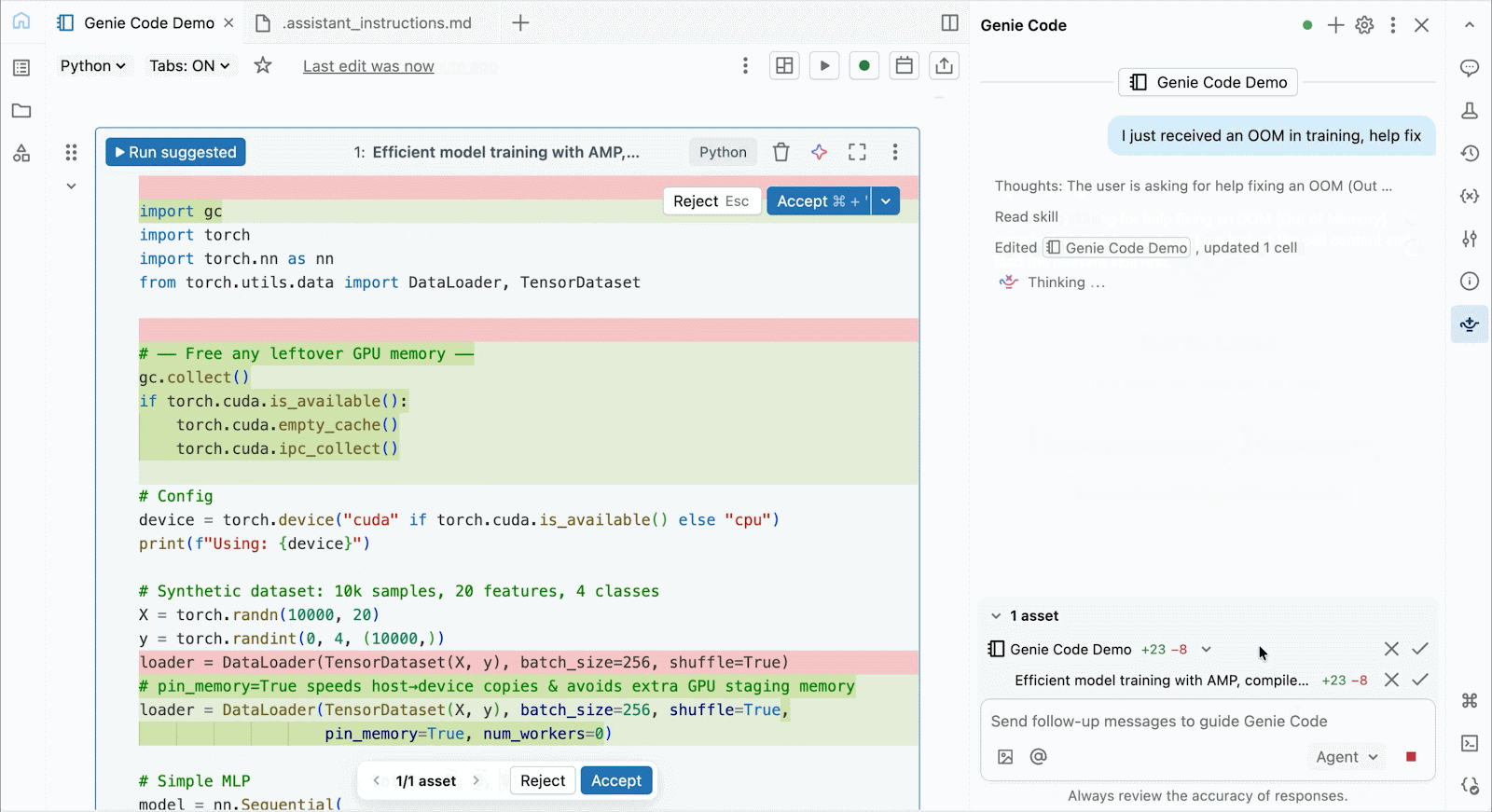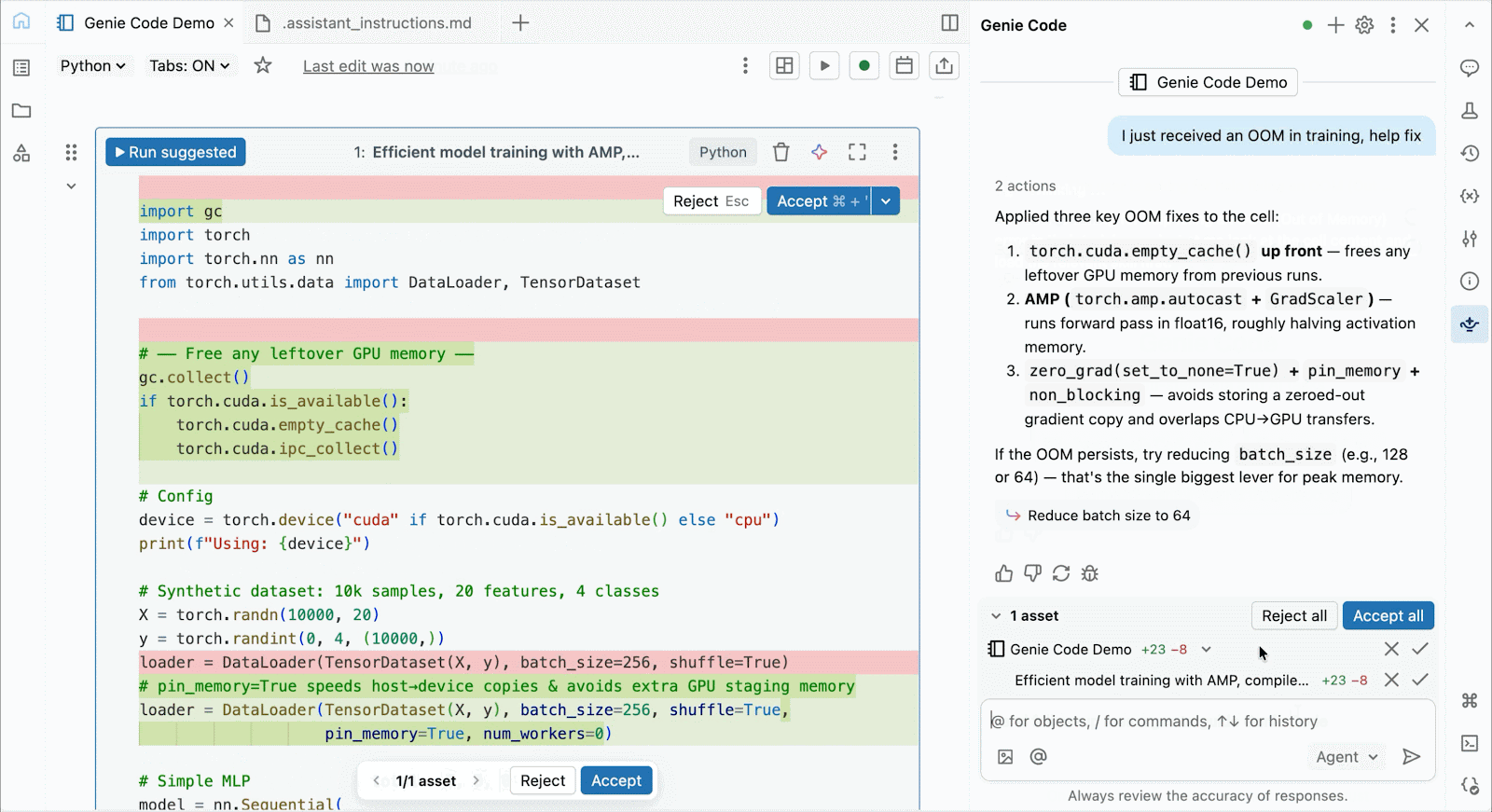
Utilisez Genie Code pour aider à résoudre les goulots d'étranglement de performance, expérimenter de nouvelles architectures, ou déboguer des bugs complexes autour de la convergence de modèles ou d'erreurs cryptiques de framework.
Lakeflow pour les charges de travail prêtes pour la production
AI Runtime est une plateforme de qualité production pour le calcul accéléré. Développez votre code d'apprentissage profond dans des notebooks interactifs, puis utilisez toute la puissance de Lakeflow pour soumettre et orchestrer des tâches sur des calculs GPU. Les notebooks et les dépôts de code personnalisés peuvent être exécutés par Lakeflow pour des tâches planifiées ou de longue durée. Pour les besoins de production tels que CI/CD (intégration continue et déploiement continu), AI Runtime est entièrement compatible avec nos Declarative Automation Bundles (DABs).
Avec notre intégration Lakeflow, les clients peuvent maintenir l'entraînement et le réglage fin des modèles étroitement synchronisés avec les pipelines de données en amont et les systèmes de production en aval.
« L'AI Runtime de Databricks a considérablement simplifié le processus d'entraînement d'un modèle personnalisé Text To Formula (TTF). Sans configuration d'infrastructure ni délais, il était facile de choisir le bon calcul en fonction de la taille de l'invite et de la génération de jetons de sortie. Cela nous a permis d'avancer rapidement, de maintenir nos flux de travail Lakehouse et de livrer un modèle de haute qualité avec une gouvernance complète, réduisant le temps de configuration, d'entraînement et de déploiement de notre modèle de jours à quelques heures. »—Nikhil Sunderraj Principal Machine Learning Engineer, FactSet Research Systems, Inc.
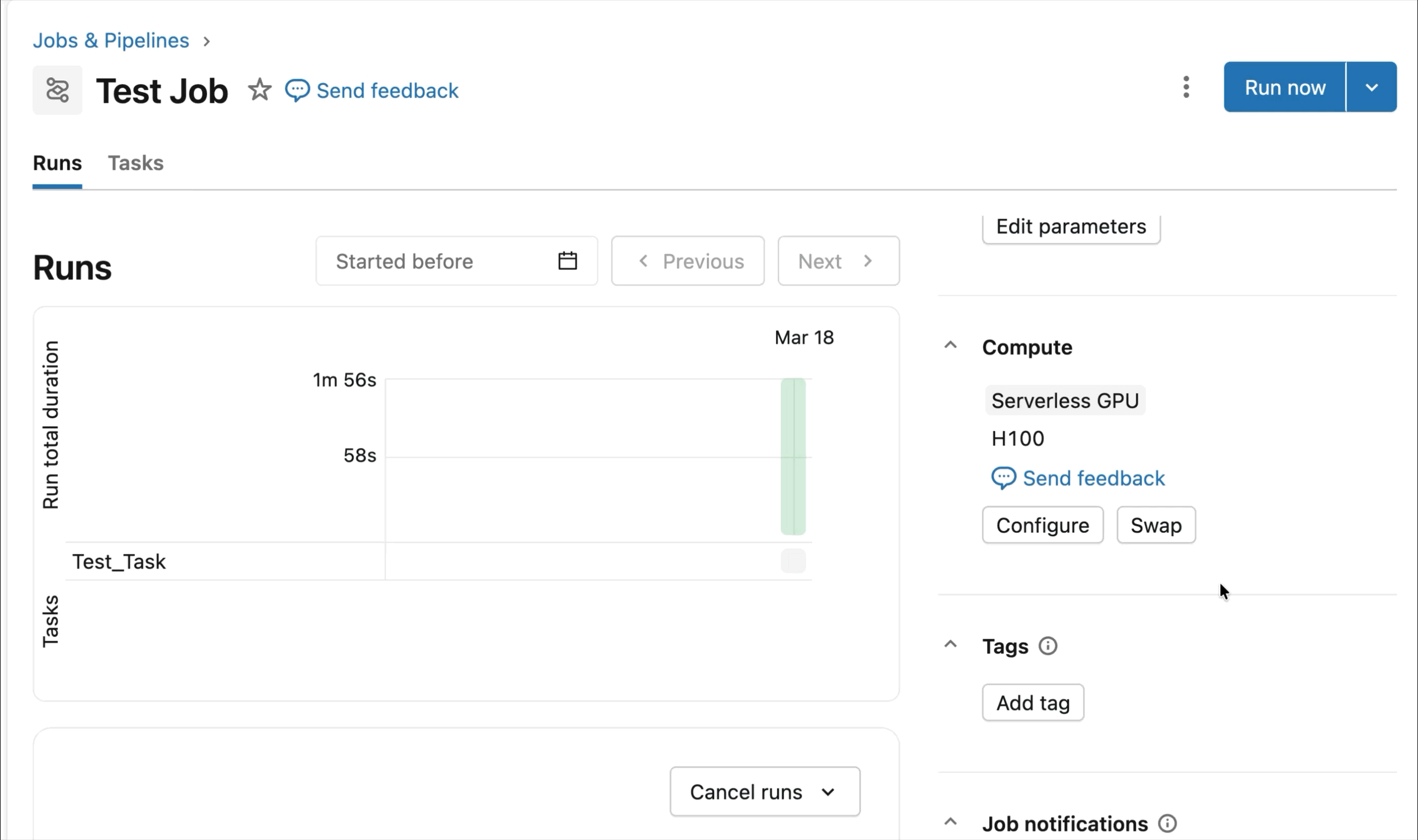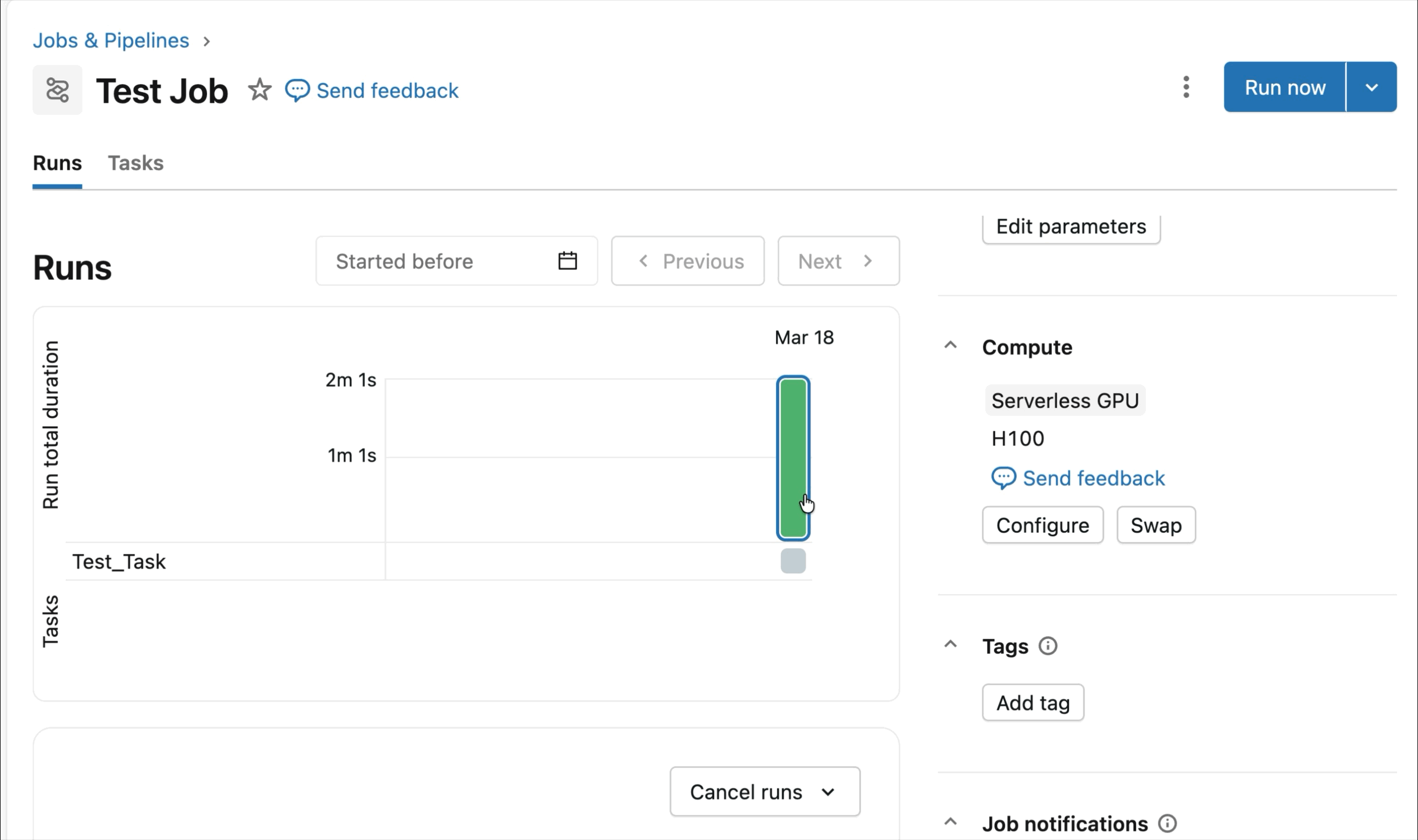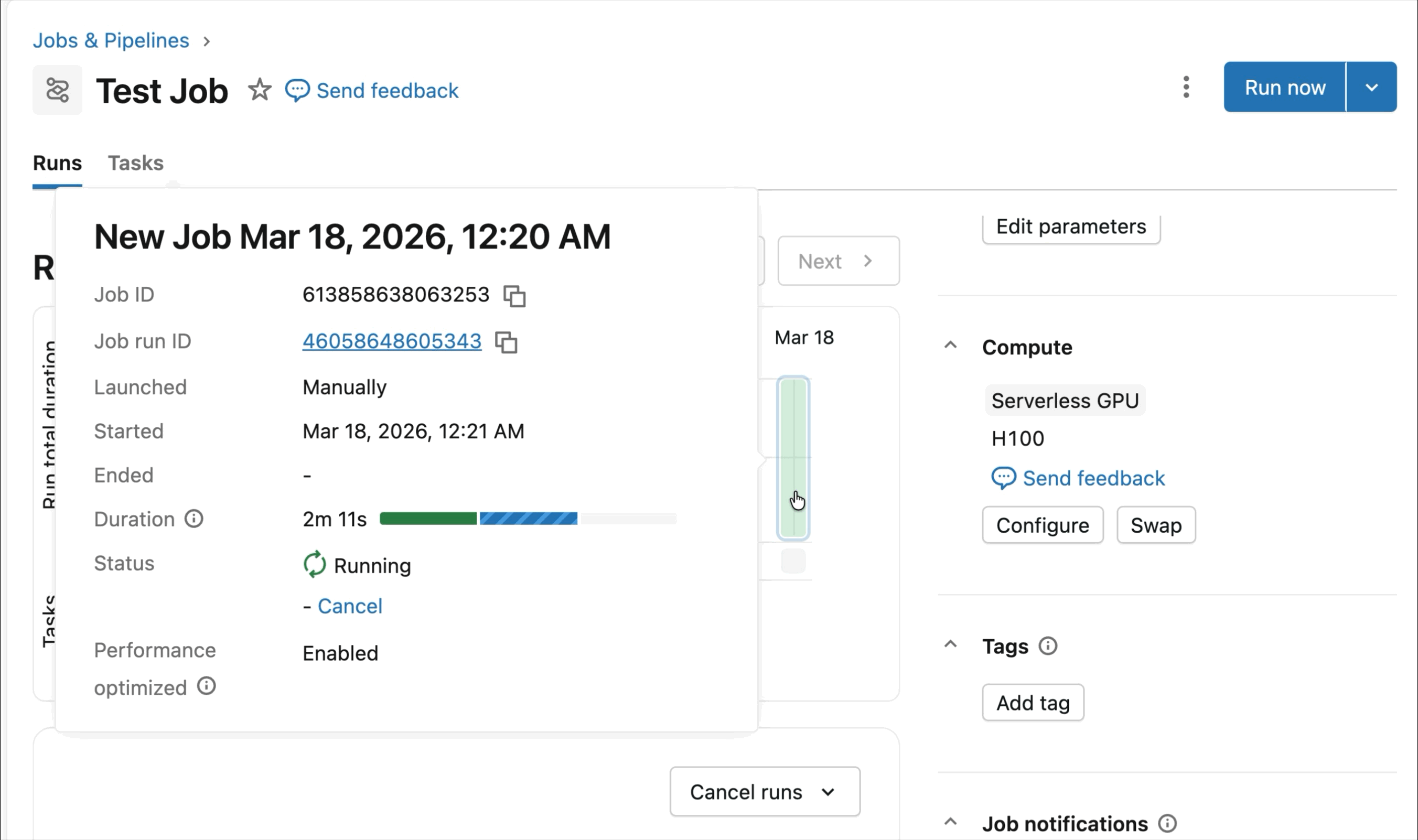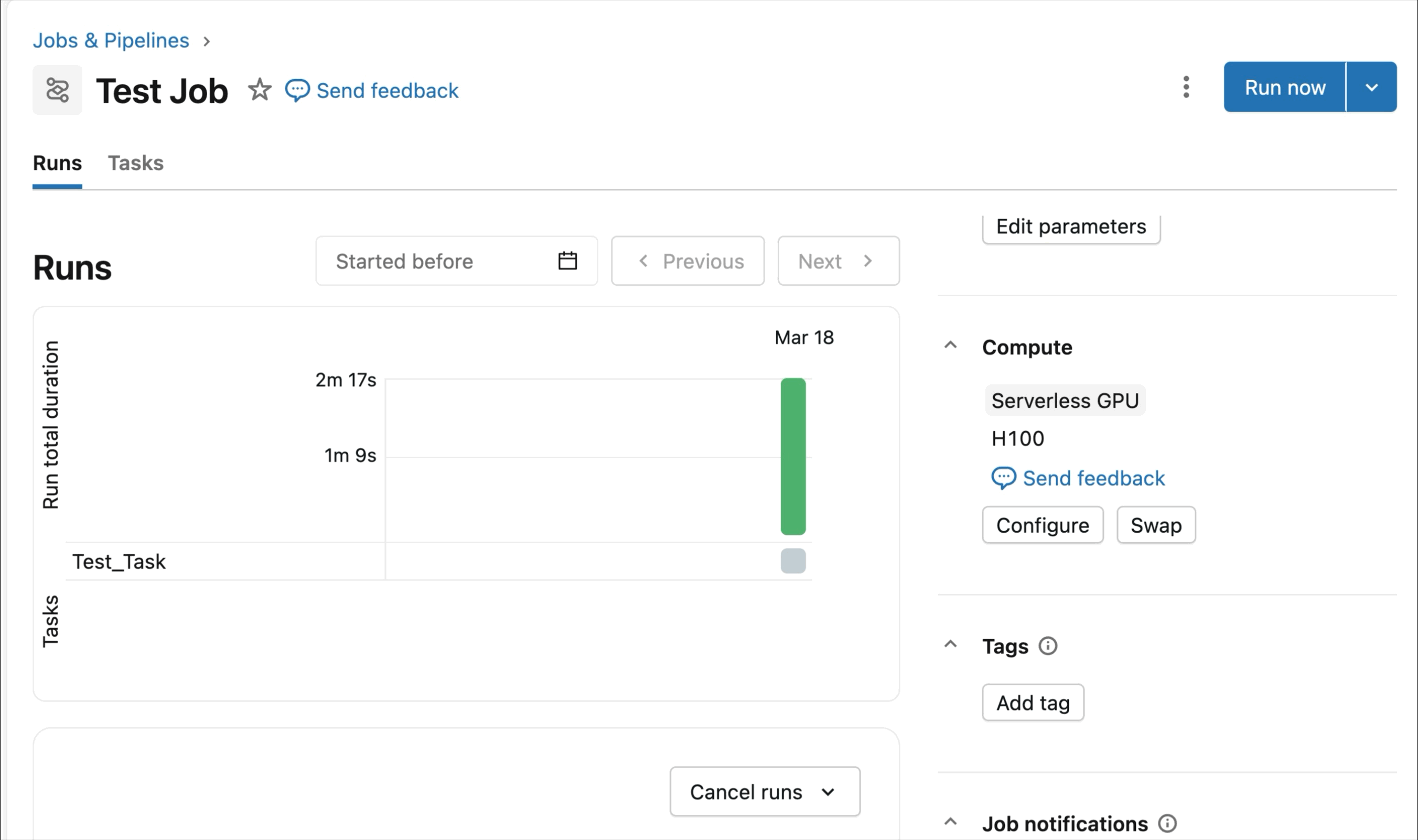
Runtime optimisé pour l'apprentissage profond distribué
Les charges de travail d'entraînement distribué peuvent être difficiles à préparer, à déboguer et à observer. Du dépannage des configurations RDMA au suivi de la télémétrie de plusieurs GPU en passant par la configuration logicielle appropriée, les utilisateurs peuvent facilement manquer des détails critiques qui ralentissent considérablement l'entraînement des modèles.
Au lieu de cela, AI Runtime est optimisé pour l'ensemble du cycle de vie de l'apprentissage profond et est conçu pour vous faire gagner du temps. Les dépendances clés comme PyTorch et CUDA sont préinstallées, avec une prise en charge optimisée des frameworks d'entraînement distribué tels que Ray, Hugging Face Transformers, Composer et d'autres bibliothèques, afin que vous puissiez commencer à entraîner immédiatement sans gérer les environnements. Les clients sont également invités à apporter leurs propres bibliothèques, d'Unsloth à TorchRec en passant par des boucles d'entraînement personnalisées.

Les SDK intégrés et les outils d'observabilité simplifient la gestion des charges de travail d'entraînement distribué. MLFlow permet une observation approfondie des charges de travail GPU, avec un suivi automatique de l'utilisation des GPU et des expériences d'entraînement. Que vous affiniez des modèles fondamentaux ou que vous entraîniez des modèles de prévision et de personnalisation, le runtime est optimisé pour accélérer les flux de travail d'entraînement avec une configuration minimale.
La préversion publique actuelle d'AI Runtime prend en charge l'entraînement distribué sur 8x H100 dans un seul nœud, avec une prise en charge multi-nœuds actuellement en préversion privée.
« L'AI Runtime de Databricks nous permet d'exécuter efficacement des charges de travail LLM (réglage fin et inférence) sans surcharge d'infrastructure, directement dans notre lakehouse. Cette intégration transparente simplifie nos pipelines et permet une utilisation efficace des GPU, nous permettant de fournir des informations d'IA de haute qualité à nos clients et de nous concentrer sur l'innovation, pas sur l'infrastructure. »—Lucas Froguel, Senior AI Platform Engineer, YipitData
Gouvernance et observabilité des données centralisées
AI Runtime s'intègre nativement au Databricks Lakehouse, vous permettant d'exécuter et de gouverner les charges de travail GPU là où résident vos données. Cela élimine les flux de travail fragmentés et simplifie le chemin de l'expérimentation à la production.
- Gouvernance centralisée avec Unity Catalog : Appliquez des contrôles d'accès cohérents, la lignée et des politiques de gouvernance sur les données et les charges de travail d'IA, permettant une utilisation sécurisée et conforme des ressources GPU.
- Observabilité unifiée : Suivez et surveillez toutes les charges de travail – CPU et GPU – en un seul endroit en utilisant les tables système natives pour l'audit unifié, le suivi de l'utilisation et les informations opérationnelles.
Vos charges de travail d'IA s'exécutent entièrement dans le périmètre de données de votre entreprise, offrant une gouvernance et une sécurité solides sans sacrifier la flexibilité pour l'expérimentation et l'échelle.
« Tirer parti du support GPU sans serveur de Databricks au sein de notre Lakehouse nous permet d'entraîner efficacement des modèles audio et multimodaux avancés sans surcharge d'infrastructure. Cette intégration transparente simplifie les flux de travail et permet une utilisation efficace des ressources GPU, garantissant que nous fournissons des systèmes haute performance et que nous nous concentrons sur l'innovation. »—Arjuna Siva, VP of Infotainment & Connectivity, Rivian and Volkswagen Group Technologies
Intégration de l'innovation GPU de nouvelle génération de NVIDIA
La demande de calcul accéléré continue de croître pour les charges de travail d'IA et les systèmes d'agents. AI Runtime permet à davantage de clients Databricks d'exploiter le matériel NVIDIA pour accélérer leurs charges de travail d'IA et faire progresser leurs activités. Nous sommes ravis de continuer à nous associer à NVIDIA pour apporter aux clients la dernière technologie NVIDIA, comme le RTX PRO 4500 Blackwell Server Edition, annoncé lors du GTC 2026.
"Alors que l'adoption de l'IA s'accélère dans tous les secteurs, les organisations ont besoin d'une infrastructure évolutive et haute performance pour alimenter leurs charges de travail de données et d'IA. Les technologies NVIDIA apportent des performances accélérées à l'offre AI Runtime pour la Databricks Lakehouse Platform."—Pat Lee, Vice-président, Partenariats stratégiques chez NVIDIA.
Commencez dès aujourd'hui avec AI Runtime
Pour vous aider à démarrer, nous avons rassemblé plusieurs notebooks modèles et guides de démarrage :
- Veuillez consulter notre documentation pour des instructions détaillées sur la configuration et l'utilisation quotidienne.
- Modèles de démarrage pour l'entraînement de systèmes de recommandation, de modèles ML classiques, le réglage fin des LLM et plus encore !
- Guide de migration des charges de travail GPU Classic Compute vers Serverless.
Veuillez contacter votre équipe commerciale pour en savoir plus ou si vous avez des questions !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.