Introduction à Apache Spark 4.0
Maintenant disponible dans Databricks Runtime 17.0
par Wenchen Fan, Serge Rielau, Herman van Hövell, Hyukjin Kwon, Allison Wang, Anish Shrigondekar, Daniel Tenedorio, Martin Grund, DB Tsai, Xiao Li et Reynold Xin
L’édition Gratuite remplace l’édition Communautaire, offrant des fonctionnalités améliorées sans frais. Commencez à utiliser l’édition Gratuite dès aujourd’hui.
Apache Spark 4.0 marque une étape majeure dans l’évolution du moteur d’analyse Spark. Cette version apporte des avancées significatives dans tous les domaines – des améliorations du langage SQL et une connectivité étendue, aux nouvelles fonctionnalités Python, aux améliorations du streaming et à une meilleure utilisabilité. Spark 4.0 est conçu pour être plus puissant, conforme ANSI et plus facile à utiliser que jamais, tout en maintenant la compatibilité avec les charges de travail Spark existantes. Dans cet article, nous expliquons les fonctionnalités et les améliorations clés introduites dans Spark 4.0 et comment elles améliorent votre expérience de traitement de données massives.
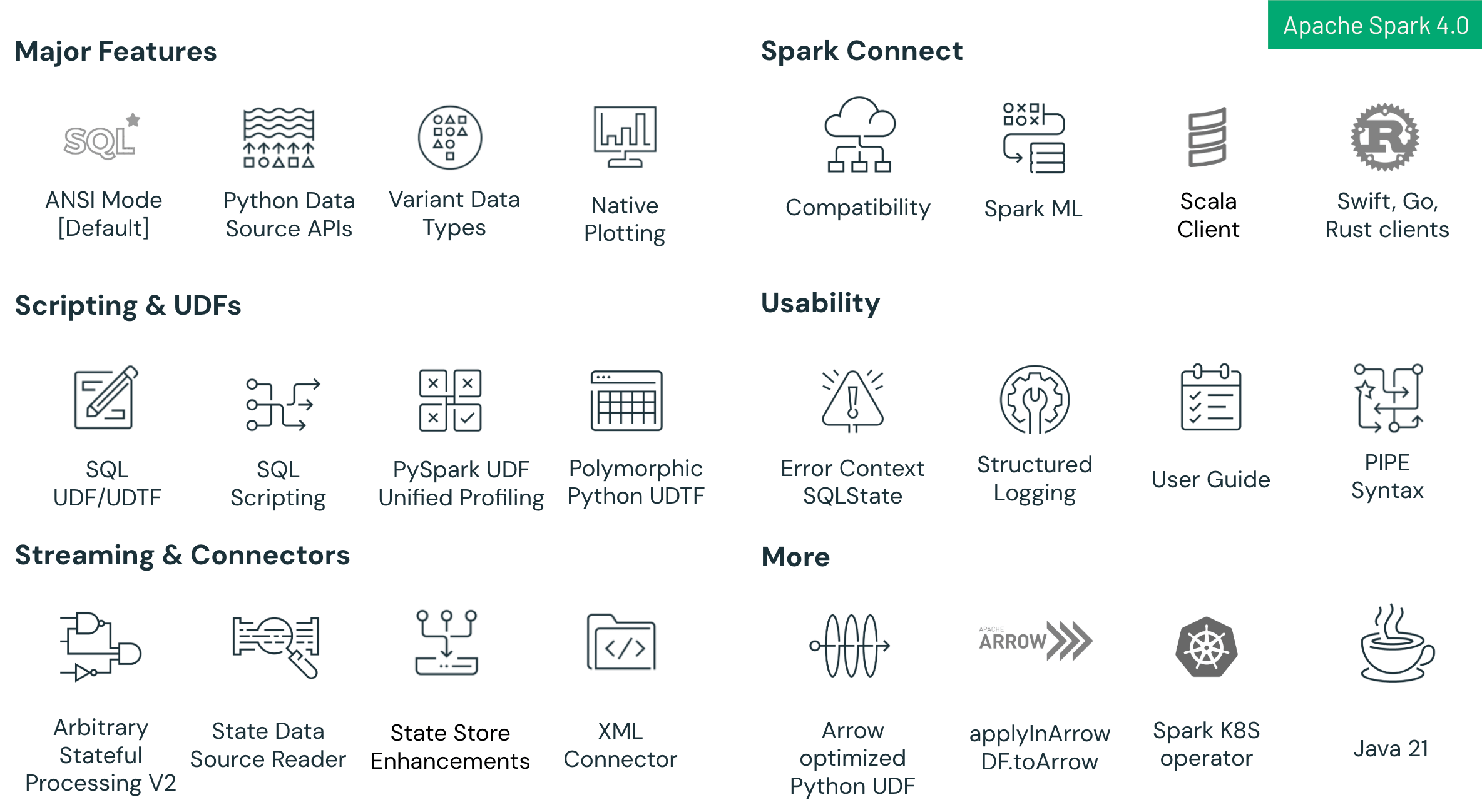
Points forts de Spark 4.0 :
- Améliorations du langage SQL : Nouvelles fonctionnalités incluant le scripting SQL avec variables de session et flux de contrôle, les fonctions définies par l’utilisateur (UDF) SQL réutilisables et la syntaxe PIPE intuitive pour rationaliser et simplifier les flux de travail analytiques complexes.
- Améliorations de Spark Connect : Spark Connect – la nouvelle architecture client-serveur de Spark – atteint désormais une parité de fonctionnalités élevée avec Spark Classic dans Spark 4.0. Cette version ajoute une compatibilité améliorée entre Python et Scala, la prise en charge de plusieurs langages (avec de nouveaux clients pour Go, Swift et Rust) et un chemin de migration plus simple via le nouveau paramètre spark.api.mode. Les développeurs peuvent passer sans problème de Spark Classic à Spark Connect pour bénéficier d’une architecture plus modulaire, évolutive et flexible.
- Améliorations de la fiabilité et de la productivité : Le mode SQL ANSI activé par défaut garantit une intégrité des données plus stricte et une meilleure interopérabilité, complété par le type de données VARIANT pour la gestion efficace des données JSON semi-structurées et la journalisation JSON structurée pour une meilleure observabilité et un dépannage plus facile.
- Avancées de l'API Python : Traçage natif basé sur Plotly directement sur les DataFrames PySpark, une API de source de données Python permettant des connecteurs batch et streaming Python personnalisés, et des UDTF Python polymorphes pour un support de schéma dynamique et une plus grande flexibilité.
- Avancées du streaming structuré : Nouvelle API de traitement à état arbitraire appelée transformWithState en Scala, Java et Python pour une logique personnalisée à état robuste et tolérante aux pannes, améliorations de l'utilisabilité du magasin d’états et une nouvelle source de données d’états pour une meilleure débogabilité et observabilité.
Dans les sections ci-dessous, nous partageons plus de détails sur ces fonctionnalités passionnantes, et à la fin, nous fournissons des liens vers les efforts JIRA pertinents et des articles de blog approfondis pour ceux qui souhaitent en savoir plus. Spark 4.0 représente une plateforme robuste et prête pour l’avenir pour le traitement de données à grande échelle, combinant la familiarité de Spark avec de nouvelles fonctionnalités qui répondent aux besoins modernes de l’ingénierie des données.
Améliorations majeures de Spark Connect
L’une des mises à jour les plus intéressantes de Spark 4.0 est l’amélioration générale de Spark Connect, en particulier le client Scala. Avec Spark 4, toutes les fonctionnalités de Spark SQL offrent une compatibilité quasi complète entre Spark Connect et le mode d’exécution Classic, avec seulement des différences mineures restantes. Spark Connect est la nouvelle architecture client-serveur pour Spark qui découple l’application utilisateur du cluster Spark, et dans 4.0, il est plus performant que jamais :
- Compatibilité améliorée : Une réalisation majeure pour Spark Connect dans Spark 4 est la compatibilité améliorée des API Python et Scala, ce qui rend le passage de l’utilisation de Spark Classic à Spark Connect transparente. Cela signifie que pour la plupart des cas d’utilisation, il vous suffit d’activer Spark Connect pour vos applications en définissant
spark.api.modesurconnect. Nous vous recommandons de commencer à développer de nouveaux jobs et applications avec Spark Connect activé afin de bénéficier pleinement du puissant moteur d’optimisation et d’exécution des requêtes de Spark. - Prise en charge multilingue : Spark Connect dans 4.0 prend en charge un large éventail de langages et d’environnements. Les clients Python et Scala sont entièrement pris en charge, et de nouveaux clients de connexion pris en charge par la communauté pour Go, Swift et Rust sont disponibles. Cette prise en charge polyglotte signifie que les développeurs peuvent utiliser Spark dans la langue de leur choix, même en dehors de l’écosystème JVM, via l’API Connect. Par exemple, une application d’ingénierie des données en Rust ou un service Go peuvent désormais se connecter directement à un cluster Spark et exécuter des requêtes DataFrame, étendant ainsi la portée de Spark au-delà de sa base d’utilisateurs traditionnelle.
Fonctionnalités du langage SQL
Spark 4.0 ajoute de nouvelles fonctionnalités pour simplifier l’analyse des données :
- Fonctions définies par l’utilisateur (UDF) SQL – Spark 4.0 introduit les UDF SQL, permettant aux utilisateurs de définir des fonctions personnalisées réutilisables directement en SQL. Ces fonctions simplifient la logique complexe, améliorent la maintenabilité et s’intègrent de manière transparente avec l’optimiseur de requêtes de Spark, améliorant les performances des requêtes par rapport aux UDF basées sur du code traditionnel. Les UDF SQL prennent en charge les définitions temporaires et permanentes, permettant aux équipes de partager facilement une logique commune entre plusieurs requêtes et applications. [Lire l’article de blog]
- Syntaxe PIPE SQL – Spark 4.0 introduit une nouvelle syntaxe PIPE, permettant aux utilisateurs de chaîner des opérations SQL à l’aide de l’opérateur |>. Cette approche de style fonctionnel améliore la lisibilité et la maintenabilité des requêtes en permettant un flux linéaire de transformations. La syntaxe PIPE est entièrement compatible avec le SQL existant, permettant une adoption progressive et une intégration dans les flux de travail actuels. [Lire l’article de blog]
- Collation sensible à la langue, aux accents et à la casse - Spark 4.0 introduit une nouvelle propriété COLLATE pour les types STRING. Vous pouvez choisir parmi de nombreuses collations tenant compte de la langue et de la région pour contrôler la façon dont Spark détermine l’ordre et les comparaisons. Vous pouvez également décider si les collations doivent être insensibles à la casse, aux accents et aux espaces de fin. [Lire l’article de blog]
- Variables de session - Spark 4.0 introduit des variables locales de session, qui peuvent être utilisées pour conserver et gérer l’état au sein d’une session sans utiliser de variables du langage hôte. [Lire l’article de blog]
- Marqueurs de paramètres - Spark 4.0 introduit des marqueurs de paramètres nommés (":var") et non nommés ("?"). Cette fonctionnalité vous permet de paramétrer les requêtes et de transmettre des valeurs en toute sécurité via l’API spark.sql(). Cela réduit le risque d’injection SQL. [Voir la documentation]
- Scripting SQL : L’écriture de flux de travail SQL en plusieurs étapes est plus facile dans Spark 4.0 grâce aux nouvelles fonctionnalités de scripting SQL. Vous pouvez désormais exécuter des scripts SQL multi-instructions avec des fonctionnalités telles que les variables locales et le flux de contrôle. Cette amélioration permet aux ingénieurs de données de déplacer des parties de la logique ETL vers du SQL pur, Spark 4.0 prenant en charge des constructions qui n’étaient auparavant possibles que via des langages externes ou des procédures stockées. Cette fonctionnalité sera bientôt améliorée par la gestion des conditions d’erreur. [Lire l’article de blog]
Intégrité des données et productivité des développeurs
Spark 4.0 introduit plusieurs mises à jour qui rendent la plateforme plus fiable, conforme aux normes et conviviale. Ces améliorations rationalisent les flux de travail de développement et de production, garantissant une qualité des données plus élevée et un dépannage plus rapide.
- Mode SQL ANSI : L’un des changements les plus importants dans Spark 4.0 est l’activation par défaut du mode SQL ANSI, alignant ainsi Spark plus étroitement sur la sémantique SQL standard. Ce changement garantit une gestion des données plus stricte en fournissant des messages d’erreur explicites pour les opérations qui résultaient auparavant de troncations silencieuses ou de valeurs nulles, telles que les dépassements numériques ou la division par zéro. De plus, le respect des normes SQL ANSI améliore considérablement l’interopérabilité, simplifiant la migration des charges de travail SQL à partir d’autres systèmes et réduisant le besoin de réécritures de requêtes et de réentraînements d’équipes. Dans l’ensemble, cette avancée favorise des flux de travail de données plus clairs, plus fiables et portables. [Voir la documentation]
- Nouveau type de données VARIANT : Apache Spark 4.0 introduit le nouveau type de données VARIANT, conçu spécifiquement pour les données semi-structurées. Il permet de stocker des structures JSON complexes ou de type map dans une seule colonne tout en conservant la capacité d'interroger efficacement les champs imbriqués. Cette fonctionnalité puissante offre une flexibilité de schéma significative, facilitant l'ingestion et la gestion des données qui ne respectent pas les schémas prédéfinis. De plus, l'indexation et l'analyse intégrées des champs JSON par Spark améliorent les performances des requêtes, facilitant les recherches et les transformations rapides. En minimisant le besoin d'étapes répétées d'évolution de schéma, VARIANT simplifie les pipelines ETL, ce qui se traduit par des flux de traitement de données plus rationalisés. [Lire l'article de blog]
- Journalisation structurée : Spark 4.0 introduit un nouveau framework de journalisation structurée qui simplifie le débogage et la surveillance. En activant
spark.log.structuredLogging.enabled=true,Spark écrit les journaux sous forme de lignes JSON — chaque entrée incluant des champs structurés tels que l'horodatage, le niveau de journal, le message et le contexte complet Mapped Diagnostic Context (MDC). Ce format moderne simplifie l'intégration avec les outils d'observabilité tels que Spark SQL, ELK et Splunk, rendant les journaux beaucoup plus faciles à analyser, rechercher et examiner. [En savoir plus]
Avancées de l'API Python
Les utilisateurs Python ont beaucoup à célébrer dans Spark 4.0. Cette version rend Spark plus Pythonique et améliore les performances des charges de travail PySpark :
- Prise en charge native des graphiques : L'exploration des données dans PySpark vient de devenir plus facile – Spark 4.0 ajoute des capacités de traçage natives aux DataFrames PySpark. Vous pouvez maintenant appeler une méthode .plot() ou utiliser une API associée sur un DataFrame pour générer des graphiques directement à partir des données Spark, sans avoir à collecter manuellement les données vers pandas. Sous le capot, Spark utilise Plotly comme backend de visualisation par défaut pour rendre les graphiques. Cela signifie que les types de graphiques courants comme les histogrammes et les nuages de points peuvent être créés avec une seule ligne de code sur un DataFrame PySpark, et Spark s'occupera de récupérer un échantillon ou un agrégat des données à tracer dans un notebook ou une interface graphique. En prenant en charge le traçage natif, Spark 4.0 rationalise l'analyse exploratoire des données – vous pouvez visualiser les distributions et les tendances de votre jeu de données sans quitter le contexte Spark ni écrire de code matplotlib/plotly séparé. Cette fonctionnalité est un atout majeur pour la productivité des data scientists utilisant PySpark pour l'EDA.
- API Python pour les sources de données : Spark 4.0 introduit une nouvelle API Python pour les sources de données qui permet aux développeurs d'implémenter des sources de données personnalisées pour le traitement par lots et en continu entièrement en Python. Auparavant, la rédaction d'un connecteur pour un nouveau format de fichier, une base de données ou un flux de données nécessitait souvent des connaissances en Java/Scala. Désormais, vous pouvez créer des lecteurs et des écrivains en Python, ce qui ouvre Spark à une communauté de développeurs plus large. Par exemple, si vous avez un format de données personnalisé ou une API qui n'a qu'un client Python, vous pouvez l'encapsuler en tant que source/puits de DataFrame Spark à l'aide de cette API. Cette fonctionnalité améliore considérablement l'extensibilité de PySpark dans les contextes de traitement par lots et de flux. Consultez l'article détaillé sur PySpark pour un exemple d'implémentation d'une source de données personnalisée simple en Python ou consultez un échantillon d'exemples ici. [Lire l'article de blog]
- UDTF Python polymorphes : En s'appuyant sur la capacité UDTF SQL, PySpark prend désormais en charge les Fonctions Définies par l'Utilisateur (UDTF) en Python, y compris les UDTF polymorphes qui peuvent retourner différentes formes de schéma en fonction de l'entrée. Vous pouvez créer une classe Python comme UDTF à l'aide d'un décorateur qui produit un itérateur de lignes de sortie, et l'enregistrer afin qu'elle puisse être appelée depuis Spark SQL ou l'API DataFrame. Un aspect puissant est les UDTF à schéma dynamique – votre UDTF peut définir une méthode analyze() pour produire un schéma à la volée en fonction des paramètres, comme la lecture d'un fichier de configuration pour déterminer les colonnes de sortie. Ce comportement polymorphe rend les UDTF extrêmement flexibles, permettant des scénarios tels que le traitement d'un schéma JSON variable ou la division d'une entrée en un ensemble variable de sorties. Les UDTF PySpark permettent efficacement à la logique Python de produire un résultat de table complet par invocation, le tout au sein du moteur d'exécution Spark. [Voir la documentation]
Améliorations du streaming
Apache Spark 4.0 continue d'affiner Structured Streaming pour améliorer les performances, la convivialité et l'observabilité :
- Traitement d'état arbitraire v2 : Spark 4.0 introduit un nouvel opérateur de traitement d'état arbitraire appelé transformWithState. TransformWithState permet de construire des pipelines opérationnels complexes avec la prise en charge de la définition de logique orientée objet, des types composites, la prise en charge des minuteurs et du TTL, la prise en charge de la gestion de l'état initial, l'évolution du schéma d'état et une multitude d'autres fonctionnalités. Cette nouvelle API est disponible en Scala, Java et Python et fournit des intégrations natives avec d'autres fonctionnalités importantes telles que le lecteur de source de données d'état, la gestion des métadonnées de l'opérateur, etc. [Lire l'article de blog]
- Lecteur de source de données d'état : Spark 4.0 ajoute la possibilité d'interroger l'état du flux en tant que table. Cette nouvelle source de données de stockage d'état expose l'état interne utilisé dans les agrégations de flux avec état (comme les compteurs, les fenêtres de session, etc.), les jointures, etc. sous forme de DataFrame lisible. Avec des options supplémentaires, cette fonctionnalité permet également aux utilisateurs de suivre les modifications d'état par mise à jour pour une visibilité granulaire. Cette fonctionnalité aide également à comprendre quel état votre tâche de streaming traite et peut aider davantage au dépannage et à la surveillance de la logique avec état de vos flux, ainsi qu'à la détection de toute corruption sous-jacente ou violation d'invariant. [Lire l'article de blog]
- Améliorations du stockage d'état : Spark 4.0 ajoute également de nombreuses améliorations au stockage d'état, telles qu'une meilleure gestion de la réutilisation des fichiers SST (Static Sorted Table), des améliorations de la gestion des instantanés et de la maintenance, un format de point de contrôle d'état remanié ainsi que des améliorations de performances supplémentaires. Parallèlement, de nombreux changements ont été apportés pour améliorer la journalisation et la classification des erreurs afin de faciliter la surveillance et le débogage.
Remerciements
Spark 4.0 représente une avancée majeure pour le projet Apache Spark, avec des optimisations et de nouvelles fonctionnalités touchant toutes les couches, des améliorations de base aux API plus riches. Dans cette version, la communauté a résolu plus de 5000 problèmes JIRA et environ 400 contributeurs individuels, des développeurs indépendants aux organisations comme Databricks, Apple, Linkedin, Intel, OpenAI, eBay, Netease, Baidu, ont mené ces améliorations.
Nous adressons nos sincères remerciements à chaque contributeur, que vous ayez signalé un ticket, examiné du code, amélioré la documentation ou partagé vos commentaires sur les listes de diffusion. Au-delà des améliorations phares en SQL, Python et streaming, Spark 4.0 offre également la prise en charge de Java 21, l'opérateur Spark K8S, les connecteurs XML, le support Spark ML sur Connect et le profilage unifié des UDF PySpark. Pour la liste complète des changements et toutes les autres améliorations au niveau du moteur, veuillez consulter les notes de version officielles de Spark 4.0.
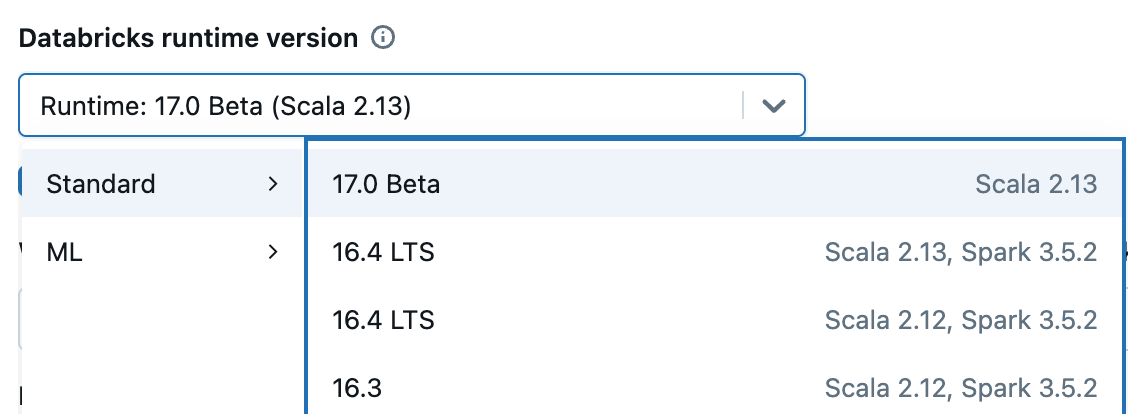
Obtenir Spark 4.0 : Il est entièrement open source — téléchargez-le depuis spark.apache.org. Bon nombre de ses fonctionnalités étaient déjà disponibles dans Databricks Runtime 15.x et 16.x, et elles sont maintenant incluses par défaut avec Runtime 17.0. Pour explorer Spark 4.0 dans un environnement géré, inscrivez-vous à l'édition communautaire ou démarrez un essai, choisissez « 17.0 » lorsque vous démarrez votre cluster, et vous exécuterez Spark 4.0 en quelques minutes.
Si vous avez manqué notre meetup Spark 4.0 où nous avons discuté de ces fonctionnalités, vous pouvez voir les enregistrements ici. Restez également à l'écoute pour de futurs meetups approfondis sur ces fonctionnalités de Spark 4.0.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.