Blog : Présentation des vues matérialisées et des tables de streaming pour Databricks SQL
Permettez aux analystes de données d'ingérer, de transformer et de fournir des données à jour entièrement en SQL
par Paul Lappas, Michael Armbrust, Yannis Papakonstantinou, Nitin Sharma et Andreas Neumann
Nous sommes ravis d'annoncer que les vues matérialisées et les tables de streaming sont désormais accessibles au public dans Databricks SQL sur AWS et Azure. Les tables de streaming permettent une ingestion incrémentielle depuis le stockage cloud et les files de messages. Les vues matérialisées sont mises à jour automatiquement et de manière incrémentielle à mesure que de nouvelles données arrivent. Ensemble, ces deux fonctionnalités permettent de créer des pipelines de données sans infrastructure, simples à configurer et qui fournissent des données à jour à l'entreprise. Dans ce billet de blog, nous allons explorer comment ces nouvelles fonctionnalités permettent aux analystes et aux ingénieurs analytiques de fournir plus efficacement des applications de données et d'analytique dans le data warehouse.
Arrière-plan
L'entreposage des données et le Data Engineering sont essentiels pour toute organisation data-driven. Les data warehouse constituent le lieu principal pour l'analytique et le reporting, tandis que l'ingénierie des données implique la création de pipelines de données pour ingérer et transformer les données.
Cependant, les data warehouse traditionnels ne sont pas conçus pour l'ingestion et la transformation en streaming. L'ingestion de grands volumes de données à faible latence dans un data warehouse traditionnel est coûteuse et complexe, car les data warehouse hérités ont été conçus pour le traitement par batch. Par conséquent, les équipes ont dû mettre en œuvre des solutions peu pratiques qui nécessitaient des configurations en dehors de l'entrepôt de données et l'utilisation du stockage cloud comme emplacement de transit intermédiaire. La gestion de ces systèmes est coûteuse, sujette aux erreurs et complexe à maintenir.
La Databricks Lakehouse Platform bouleverse ce paradigme traditionnel en fournissant une solution unifiée. Delta Live Tables (DLT) est la meilleure solution pour l'ingénierie et le streaming de données, et Databricks SQL offre un rapport prix/performance jusqu'à 12 fois supérieur pour les charges de travail analytiques sur les data lakes existants.
De plus, des partenaires comme dbt peuvent désormais s'intégrer à ces fonctionnalités natives que nous décrivons plus en détail plus loin dans cette annonce.
Défis courants rencontrés par les utilisateurs d'entrepôts de données
Les entrepôts de données servent de source principale pour l'analytique et la diffusion de données pour le reporting interne via des applications de Business Intelligence (BI). Les organisations sont confrontées à plusieurs défis dans l'adoption des data warehouses :
- Libre-service : les analystes SQL sont souvent confrontés au défi de dépendre d'autres ressources et outils pour résoudre les problèmes de données, ce qui ralentit le rythme auquel les besoins de l'entreprise peuvent être satisfaits.
- Tableaux de bord BI lents : les tableaux de bord BI conçus avec de grands volumes de données ont tendance à renvoyer les résultats lentement, ce qui nuit à l'interactivité et à la convivialité lors de la réponse à diverses questions.
- Données obsolètes : les tableaux de bord BI présentent souvent des données obsolètes, comme les données de la veille, en raison des jobs ETL qui ne s'exécutent que la nuit.
Utilisez SQL pour ingérer et transformer des données sans outils tiers
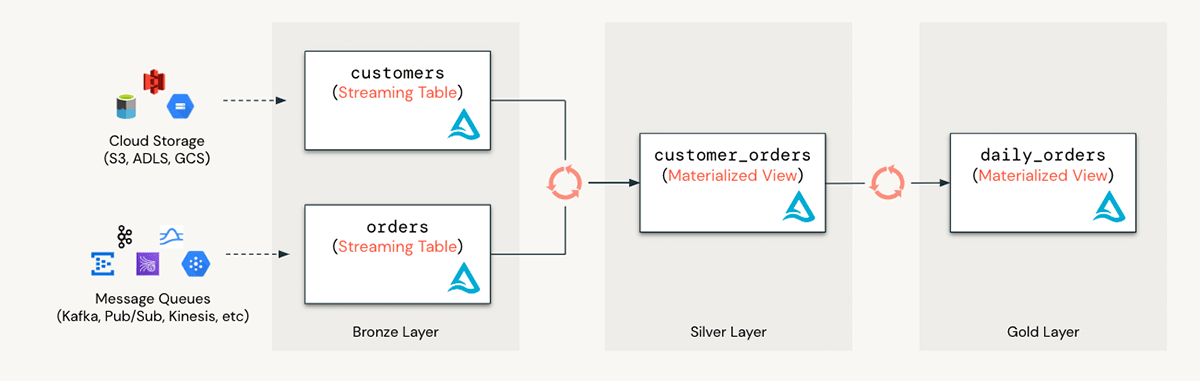
Les tables de streaming et les vues matérialisées permettent aux analystes SQL de bénéficier des meilleures pratiques en matière d'ingénierie des données. Prenons l'exemple de l'ingestion continue de fichiers nouvellement arrivés depuis un emplacement S3 et de la préparation d'une simple table de reporting. Avec Databricks SQL, l'analyste peut rapidement découvrir et prévisualiser les fichiers dans S3 et configurer un pipeline ETL simple en quelques minutes, en utilisant seulement quelques lignes de code comme dans l'exemple suivant :
1- Découvrir et prévisualiser les données dans S3
2- Ingérer des données en streaming
3- Agréger les données de manière incrémentielle à l'aide d'une vue matérialisée
Que sont les vues matérialisées ?
Les vues matérialisées réduisent les coûts et améliorent la latence des requêtes en pré-calculant les requêtes lentes et les calculs fréquemment utilisés. Dans un contexte d'ingénierie des données, elles sont utilisées pour transformer les données. Mais elles sont également précieuses pour les équipes d'analystes dans un contexte d'entreposage des données, car elles peuvent être utilisées pour (1) accélérer les requêtes des utilisateurs finaux et les tableaux de bord BI, et (2) partager des données en toute sécurité. Basées sur les Delta Live Tables, les MVs réduisent la latence des requêtes en précalculant les requêtes qui seraient autrement lentes et les calculs fréquemment utilisés.
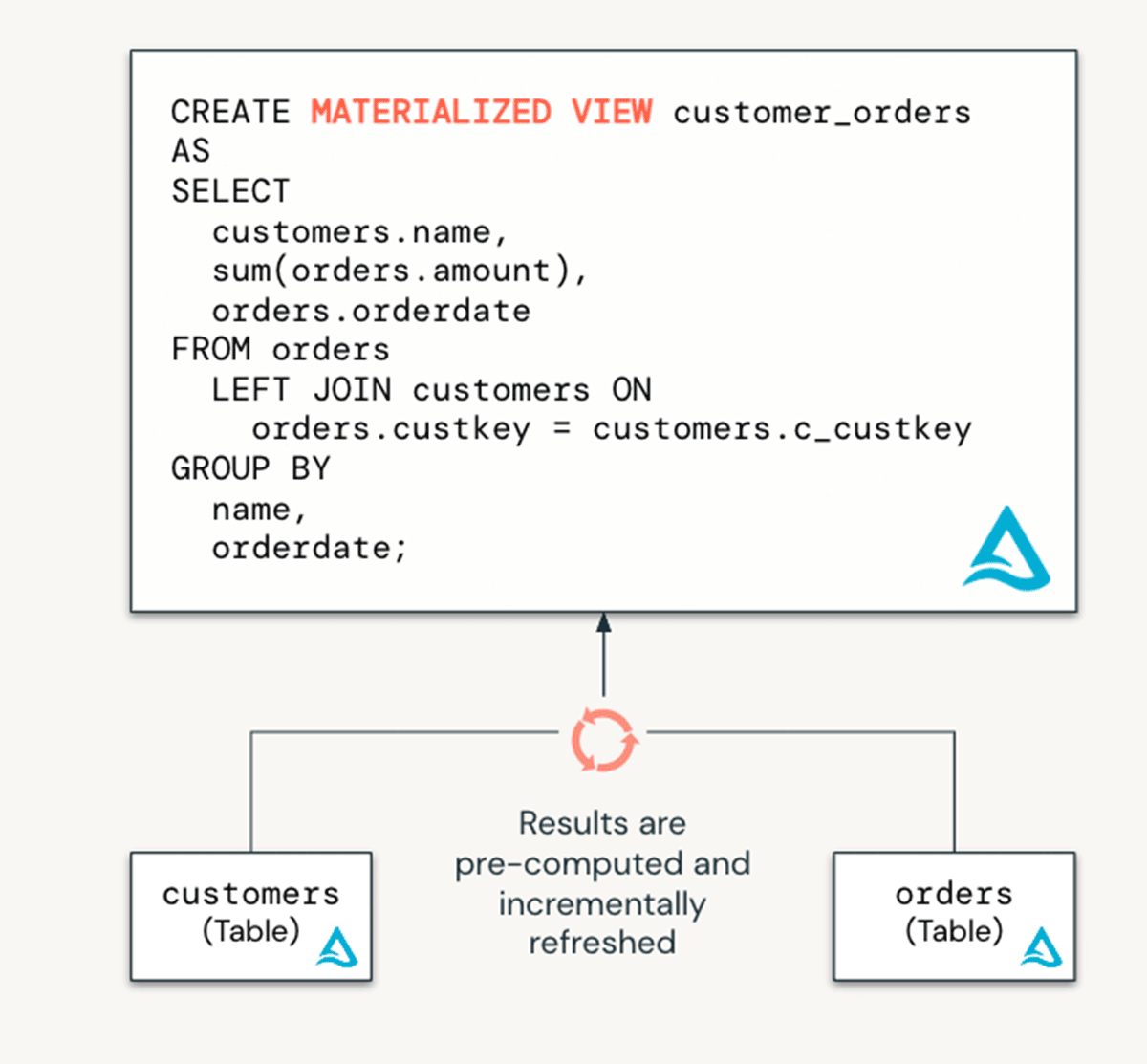
Avantages des vues matérialisées :
- Accélérer les tableaux de bord BI. Comme les MVs précalculent les données, les requêtes des utilisateurs finaux sont beaucoup plus rapides, car ils n'ont pas à retraiter les données en interrogeant directement les tables de base.
- Réduction des coûts de traitement des données. Les résultats des vues matérialisées sont actualisés de manière incrémentielle, ce qui évite d'avoir à reconstruire entièrement la vue lorsque de nouvelles données arrivent.
- Améliorer le contrôle d'accès aux données pour un partage sécurisé. Gouvernez plus étroitement les données qui peuvent être vues par les consommateurs en contrôlant l'accès aux tables de base.
Que sont les tables de streaming ?
L'ingestion dans DBSQL s'effectue avec des tables de streaming (STs). Vous pouvez considérer les STs comme idéales pour acheminer des données dans les tables « bronze ». Les STs permettent une ingestion continue et scalable à partir de n'importe quelle source de données, y compris le stockage cloud, les bus de messages (EventHub, Apache Kafka) et plus encore.
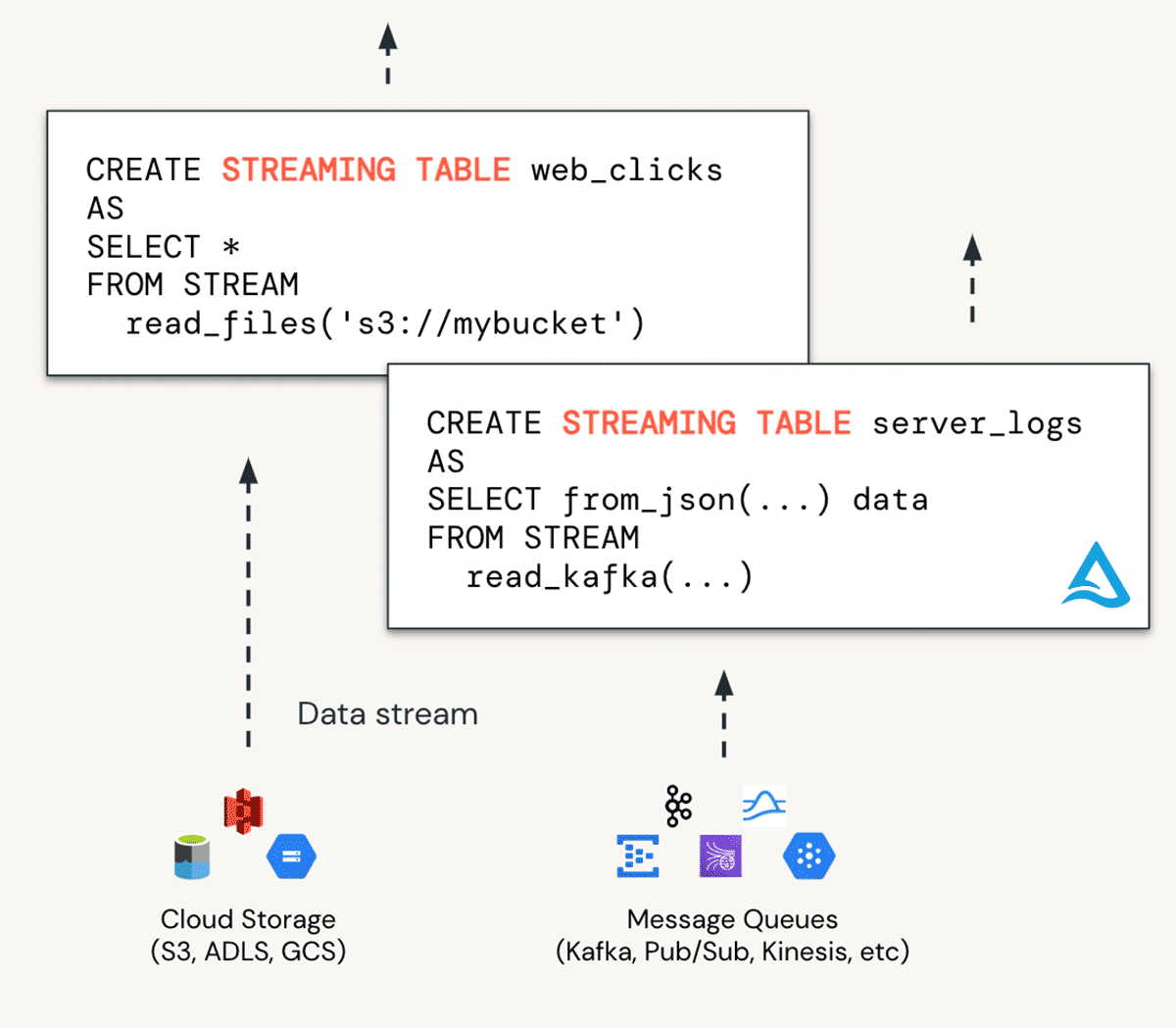
Avantages des tables de streaming :
- Débloquer des cas d'utilisation en temps réel. Capacité à prendre en charge l'analytique/la BI en temps réel, le machine learning et les cas d'utilisation opérationnels avec des données en streaming.
- Davantage d'évolutivité. Gérer plus efficacement de grands volumes de données via un traitement incrémentiel plutôt que par grands batches.
- Donnez les moyens à davantage de praticiens. La syntaxe SQL simple rend le streaming de données accessible à tous les ingénieurs de données et analystes.
Témoignage client : comment Adobe et Danske Spil accélèrent les requêtes de tableaux de bord avec les vues matérialisées
Databricks SQL permet aux analystes SQL et data analysts d'ingérer, de nettoyer et d'enrichir des données facilement pour répondre aux besoins de l'entreprise sans dépendre d'outils tiers. Tout peut être fait entièrement en SQL, ce qui simplifie le flux de travail.
En exploitant les vues matérialisées et les tables de streaming, vous pouvez :
- Donnez plus de moyens à vos analystes : les analystes SQL et de données peuvent facilement ingérer, nettoyer et enrichir des données pour répondre rapidement aux besoins de votre entreprise. Comme tout peut être fait entièrement en SQL, aucun outil tiers n'est nécessaire.
- Accélérez les tableaux de bord BI : créez des vues matérialisées pour accélérer les analytiques SQL et les rapports BI en précalculant les résultats à l'avance.
- Passez à l'analytique en temps réel : combinez les vues matérialisées avec les tables de streaming pour créer des pipelines de données incrémentiels pour les cas d'utilisation en temps réel. Vous pouvez configurer des pipelines de données en streaming pour effectuer l'ingestion et la transformation directement dans le warehouse SQL de Databricks.

Adobe a une approche avancée de l'IA, avec pour mission de rendre le monde plus créatif, productif et personnalisé grâce à l'intelligence artificielle en tant que copilote qui amplifie l'ingéniosité humaine. En tant que client de premier plan de la préversion des vues matérialisées sur Databricks SQL, ils ont constaté d'énormes avantages techniques et commerciaux qui les aident à remplir cette mission :
« La conversion en vues matérialisées a entraîné une amélioration spectaculaire des performances des requêtes, le temps d'exécution passant de 8 minutes à seulement 3 secondes. Cela permet à notre équipe de travailler plus efficacement et de prendre des décisions plus rapidement sur la base des insights tirés des données. De plus, les économies supplémentaires ont vraiment aidé. —Karthik Venkatesan, responsable principal de l'ingénierie des logiciels de sécurité, Adobe

Fondée en 1948, Danske Spil est la loterie nationale du Danemark et a été l'un de nos premiers clients en avant-première pour les vues matérialisées DB SQL. Søren Klein, responsable de l'équipe d'ingénierie des donn�ées, partage son point de vue sur ce qui rend les vues matérialisées si précieuses pour l'organisation :
« Chez Danske Spil, nous utilisons les vues matérialisées pour accélérer les performances de nos données de suivi de site Web. Avec cette fonctionnalité, nous évitons la création de tables inutiles et une complexité accrue, tout en bénéficiant de la vitesse d'une vue persistante qui accélère la solution de reporting pour l'utilisateur final. » —Søren Klein, Responsable de l'équipe d'ingénierie des données, Danske Spil
Ingestion et transformation faciles en streaming avec dbt
Databricks et dbt Labs collaborent pour simplifier l'ingénierie analytique en temps réel sur l'architecture lakehouse. La combinaison du framework d'ingénierie analytique très populaire de dbt avec la Databricks Lakehouse Platform offre de puissantes fonctionnalités :
- dbt + Tables de streaming : l'ingestion en streaming depuis n'importe quelle source est désormais intégrée aux projets dbt. À l'aide de SQL, les ingénieurs analytiques peuvent définir et ingérer des données cloud/en streaming directement dans leurs pipelines dbt.
- dbt + Vues matérialisées : La création de pipelines efficaces est simplifiée avec dbt, en tirant parti des puissantes capacités de refresh incrémentielle de Databricks. Les utilisateurs peuvent utiliser dbt pour créer et exécuter des pipelines basés sur des MVs, réduisant ainsi les coûts d'infrastructure grâce à des calculs incrémentiels efficaces.
Points à retenir
L'entreposage des données et le Data Engineering sont des composants essentiels de toute entreprise data-driven. Cependant, la gestion de solutions distinctes pour chaque aspect est coûteuse, sujette aux erreurs et difficile à maintenir. La Databricks Lakehouse Platform intègre en mode natif les meilleures fonctionnalités de Data Engineering dans Databricks SQL, offrant ainsi une solution unifiée aux utilisateurs SQL. De plus, notre intégration avec des Partenaires comme dbt permet à nos clients communs de tirer parti de ces fonctionnalités uniques pour fournir des insights plus rapides, de l'analytique en temps réel et des workflows de Data Engineering rationalisés.
Vous pouvez commencer dès aujourd'hui avec Databricks et Databricks SQL, ou consulter la documentation sur les vues matérialisées et les tables de streaming.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.